又到了deadline ,文远又得冲起来了。
本文的重点很明显,就是模型调参。
模型调参:
三个方法如下:
-
贪心调参方法;
-
网格调参方法;
-
贝叶斯调参方法
介绍说明
三个方法,具体来说。最建议的是贝叶斯调参,相对来说,耗时短,而且效果不错。然后是,贪心相对来说容易局部最优,这也挺好解释的,毕竟贪心算法就是比较容易局部最优,而网格搜索可以看作是暴力搜索的一种(dfs,bfs),最后的贝叶斯搜索则是,有点启发式算法的意味。
个人实践
当然,这些都只是文档的信息,文远还是,不怎么原因信的。先说结果,贝叶斯调参后,文员反向上分了150分。但是我还是得说一些具体过程:
代码直接用的是这里: DataWhale
但是具体运行时,有一些注意的地方才能调通:
f1 = make_scorer(f1_score, average='micro')
val = cross_val_score(model_lgb, X_train_split, y_train_split, cv=5, scoring=f1).mean()
此处的make_score函数,没有导包:
from sklearn.model_selection import cross_val_score
from sklearn.metrics import make_scorer
除此之外:
需要回忆一下f1的定义:
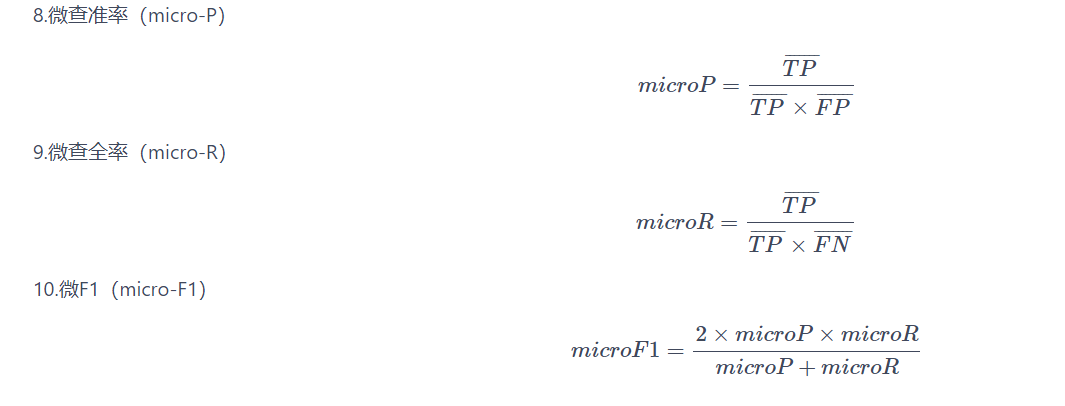
然后是发现,调参过慢。而且中途容易报错,看了一下,发现是显存太小,于是换到了baidu paddle 里跑。(百度飞浆的显存是16G,但是上传文件不够,建议还收用google的colab啊)
其中,我发现,验证的时候居然还是用f1_score,不够直观,于是我换成了原先自定义的Loss函数。结果如下:
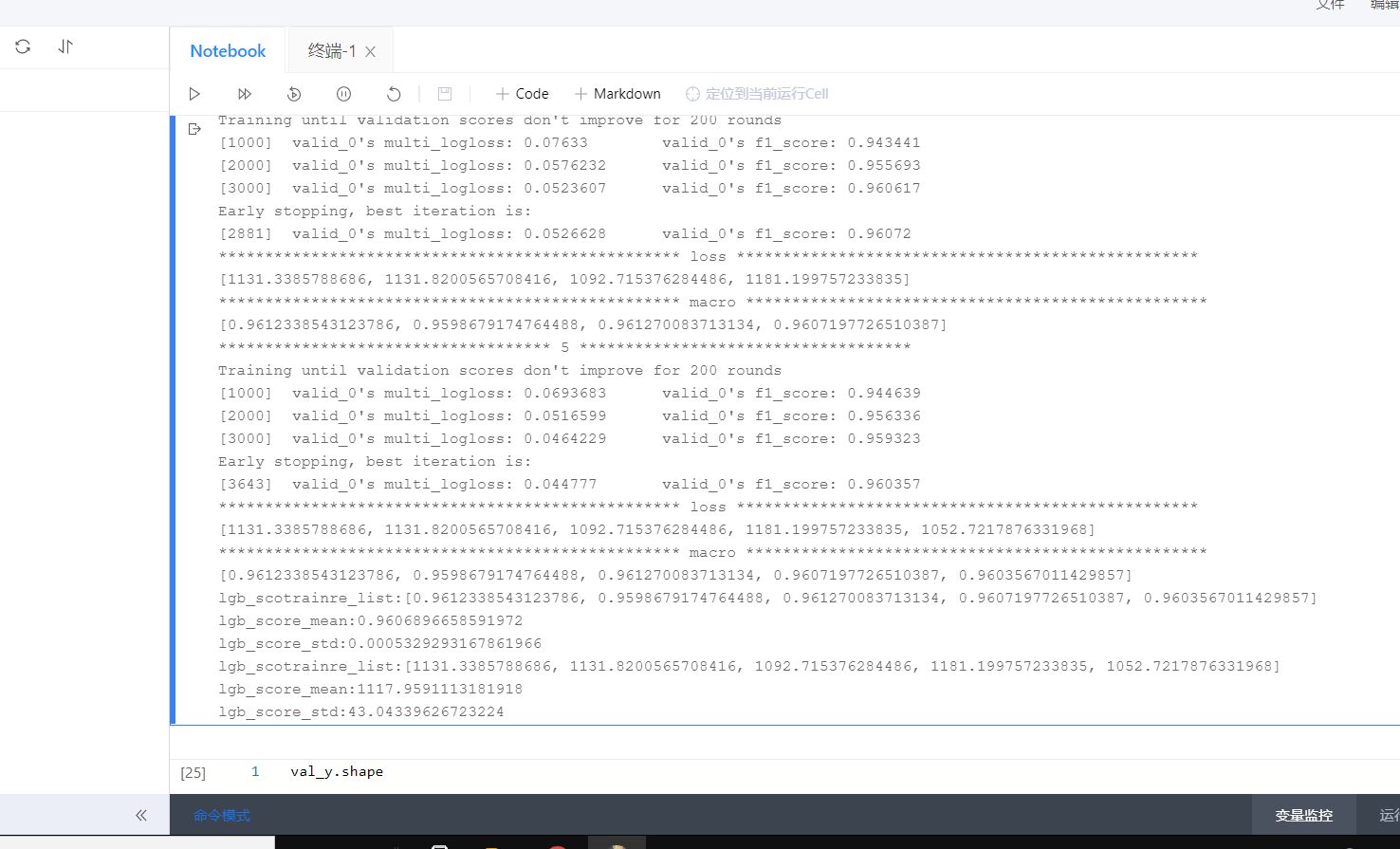
效果很差loss_mean=1117,调参,不如没调参。但是因为对调参函数不熟悉,我也没有继续尝试,但是必须得说一下,我的思考和思路。虽然目前我实现不了。
思考与改进
-
首先,最大的问题,调参的时候,得到的最优参数,训练出来了。数据集是cv=5的交叉验证。但是,中间有一个参数搬运的过程,也就是说两次数据集可能会不一致,但是第二次训练,用了第一次的超参数。
-
除此之外,经过多出搜集资料,发现应该将num_round(树数量)参数,事先能凭借先验知识给确定个大概。最重要的三个参数就是:
num_round
num_leaves
learning_rate
- 根据西瓜书上集成模型的好而不同的概念,可以尝试一下:'boosting_type’为
'gbdt' , 'dart' , 'goss'
这样模型的的区别就变大了。貌似在模型的后期可以使用贪心,这样比较节省时间,因为有之前调参的基础,也不容易陷入局部最优。
最后
以上就是不安乐曲最近收集整理的关于心跳信号分类 ---参数调整的全部内容,更多相关心跳信号分类内容请搜索靠谱客的其他文章。








发表评论 取消回复