相机标定(Camera calibration)
摄像机标定简单来说是从世界坐标系转换为相机坐标系,再由相机坐标系转换为图像坐标系的过程,也就是求最终的投影矩阵P的过程。
世界坐标系:用户定义的三维世界的坐标系,为了描述目标物在真实世界里的位置而被引入。单位为m。
相机坐标系:在相机上建立的坐标系,为了从相机的角度描述物体位置而定义,作为沟通世界坐标系和图像/像素坐标系的中间一环。单位为m。
图像坐标系:为了描述成像过程中物体从相机坐标系到图像坐标系的投影透射关系而引入,方便进一步得到像素坐标系下的坐标。 单位为m。
接下来是简单的标定方法:
1.测量选定矩形标定物体的边长dX和dY;
2.将照相机和标定物体放置在平面上,使得照相机的背面和标定物体平行,同时物体位于照相机图像视图的中心,可能需要调整照相机或者物体来获得良好的对齐效果;
3.测量标定物体到照相机的距离dZ;
4.拍摄一副图像来检验该设置是否正确,即标定物体的边要和图像的行和列对齐;
5.使用像素数来测量标定物体图像的宽度和高度dX和dY。
import cv2
import numpy as np
import glob
# 找棋盘格角点
# 阈值
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
#棋盘格模板规格
w = 9 #内角点个数,内角点是和其他格子连着的点
h = 14
# 世界坐标系中的棋盘格点,例如(0,0,0), (1,0,0), (2,0,0) ....,(8,5,0),去掉Z坐标,记为二维矩阵
objp = np.zeros((w*h,3), np.float32)
objp[:,:2] = np.mgrid[0:w,0:h].T.reshape(-1,2)
# 储存棋盘格角点的世界坐标和图像坐标对
objpoints = [] # 在世界坐标系中的三维点
imgpoints = [] # 在图像平面的二维点
images = glob.glob('p/*.jpg')
for fname in images:
img = cv2.imread(fname)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 找到棋盘格角点
# 棋盘图像(8位灰度或彩色图像) 棋盘尺寸 存放角点的位置
ret, corners = cv2.findChessboardCorners(gray, (w,h),None)
# 如果找到足够点对,将其存储起来
if ret == True:
# 角点精确检测
# 输入图像 角点初始坐标 搜索窗口为2*winsize+1 死区 求角点的迭代终止条件
cv2.cornerSubPix(gray,corners,(11,11),(-1,-1),criteria)
objpoints.append(objp)
imgpoints.append(corners)
# 将角点在图像上显示
cv2.drawChessboardCorners(img, (w,h), corners, ret)
cv2.namedWindow('findCorners', cv2.WINDOW_NORMAL)
cv2.resizeWindow('findCorners', 640, 480) # 调整分辨率
cv2.imshow('findCorners',img)
cv2.waitKey(1000)
cv2.destroyAllWindows()
#标定、去畸变
# 输入:世界坐标系里的位置 像素坐标 图像的像素尺寸大小 3*3矩阵,相机内参数矩阵 畸变矩阵
# 输出:标定结果 相机的内参数矩阵 畸变系数 旋转矩阵 平移向量
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
# mtx:内参数矩阵
# dist:畸变系数
# rvecs:旋转向量 (外参数)
# tvecs :平移向量 (外参数)
print (("ret:"),ret)
print (("mtx:n"),mtx) # 内参数矩阵
print (("dist:n"),dist) # 畸变系数 distortion cofficients = (k_1,k_2,p_1,p_2,k_3)
print (("rvecs:n"),rvecs) # 旋转向量 # 外参数
print (("tvecs:n"),tvecs) # 平移向量 # 外参数
# 去畸变
img2 = cv2.imread('p/5_d.jpg')
h,w = img2.shape[:2]
# 我们已经得到了相机内参和畸变系数,在将图像去畸变之前,
# 我们还可以使用cv.getOptimalNewCameraMatrix()优化内参数和畸变系数,
# 通过设定自由自由比例因子alpha。当alpha设为0的时候,
# 将会返回一个剪裁过的将去畸变后不想要的像素去掉的内参数和畸变系数;
# 当alpha设为1的时候,将会返回一个包含额外黑色像素点的内参数和畸变系数,并返回一个ROI用于将 其剪裁掉
newcameramtx, roi=cv2.getOptimalNewCameraMatrix(mtx,dist,(w,h),0,(w,h)) # 自由比例参数
dst = cv2.undistort(img2, mtx, dist, None, newcameramtx)
# 根据前面ROI区域裁剪图片
x,y,w,h = roi
dst = dst[y:y+h, x:x+w]
cv2.imwrite('calibresult.jpg',dst)
# 反投影误差
# 通过反投影误差,我们可以来评估结果的好坏。越接近0,说明结果越理想。
# 通过之前计算的内参数矩阵、畸变系数、旋转矩阵和平移向量,使用cv2.projectPoints()计算三维点到二维图像的投影,
# 然后计算反投影得到的点与图像上检测到的点的误差,最后计算一个对于所有标定图像的平均误差,这个值就是反投影误差。
total_error = 0
for i in range(len(objpoints)):
imgpoints2, _ = cv2.projectPoints(objpoints[i], rvecs[i], tvecs[i], mtx, dist)
error = cv2.norm(imgpoints[i],imgpoints2, cv2.NORM_L2)/len(imgpoints2)
total_error += error
print (("total error: "), total_error/len(objpoints))
以下是我的5张黑白格图:





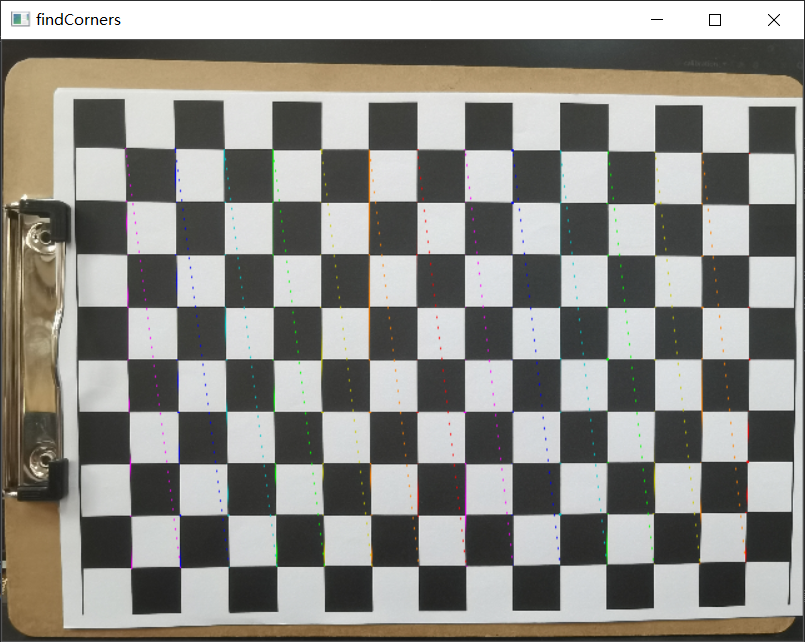
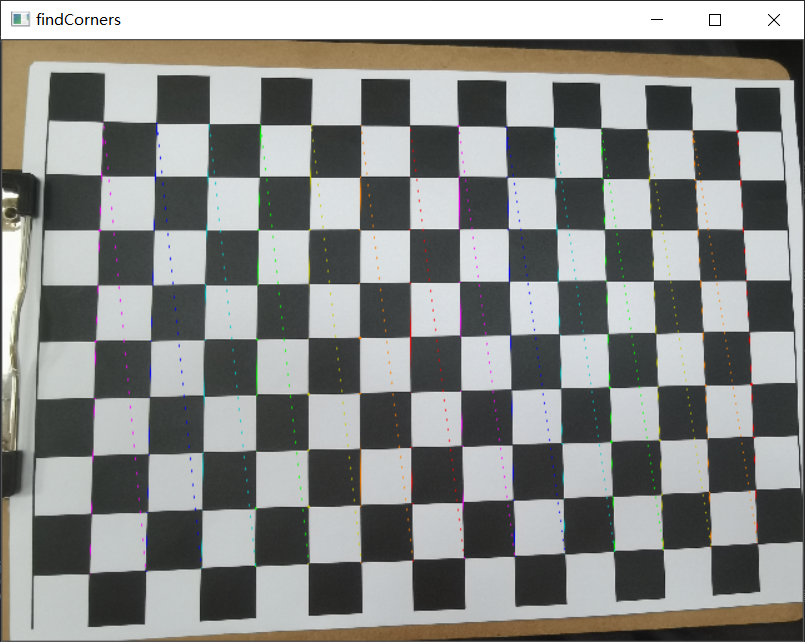
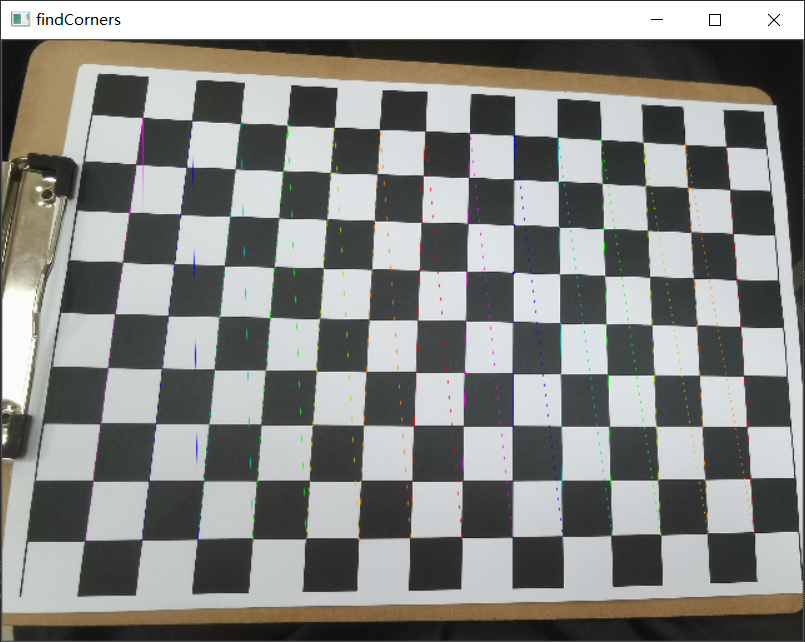
但是这里只有前三张照片才能跑出结果,后面两张是没有结果的,并且最后的反投影误差为0.18而学长的图片跑出来的误差却只有0.03。可能是因为后面两张照片不大平整造成的,这个跟拍照的角度也有一定的关系,也有可能是棋盘上面有一些黑店导致识别出现错误,从而导致角点检测不出来,所以自然也就没办法得出标定的图片,所以拍照这块一定要仔细,棋盘纸也要放置平整。
最后
以上就是高贵山水最近收集整理的关于python计算机视觉第五次实验的全部内容,更多相关python计算机视觉第五次实验内容请搜索靠谱客的其他文章。








发表评论 取消回复