KNN算法
一、KNN算法概述
1、kNN算法又称为k近邻分类(k-nearest neighbor classification)算法。
最简单平凡的分类器也许是那种死记硬背式的分类器,记住所有的训练数据,对于新的数据则直接和训练数据匹配,如果存在相同属性的训练数据,则直接用它的分类来作为新数据的分类。这种方式有一个明显的缺点,那就是很可能无法找到完全匹配的训练记录。
kNN算法则是从训练集中找到和新数据最接近的k条记录,然后根据他们的主要分类来决定新数据的类别。该算法涉及3个主要因素:训练集、距离或相似的衡量、k的大小。
二、KNN算法步骤
1)算距离:给定测试对象,计算它与训练集中的每个对象的距离
2)找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻归属的主要类别,来对测试对象分类
三、算法优缺点
1、优点
简单,易于理解,易于实现,无需估计参数,无需训练
适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型)
特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好
2、缺点
懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢
可解释性较差,无法给出决策树那样的规则。
四、KNN算法实现代码
实现最基本的KNN形式非常简单。给定训练样本集和对应的标记列表,下面的代码可以用来完成这一工作。 这些训练样本和标记可以在一一个 数组里成行摆放或者千脆摆放列表里,训练样本可能是数字、字符串等任何你喜欢的形状。将定义的类对象添加到名为knn.py的文件里:
class KnnClassifier(object):
def __init__(self,labels,samples):
""" Initialize classifier with training data.使用训练数据初始化分类器 """
self.labels = labels
self.samples = samples
def classify(self,point,k=3):
""" Classify a point against k nearest
in the training data, return label.
在训练数据上采用 k 近邻分类,并返回标记
"""
# compute distance to all training points 计算所有训练数据点的距离
dist = array([L2dist(point,s) for s in self.samples])
# sort them 对它们进行排序
ndx = dist.argsort()
# use dictionary to store the k nearest 用字典存储 k 近邻
votes = {}
for i in range(k):
label = self.labels[ndx[i]]
votes.setdefault(label,0)
votes[label] += 1
return max(votes, key=lambda x: votes.get(x))
定义一个类并用训练数据初始化非常简单;每次想对某些东西进行分类时,用KNN方法,我们就没有必要存储并将训练数据作为参数来传递。用一个字典来存储邻近标记,我们便可以用文本字符串或数字来表示标记。在这个例子中,我们用欧式距离(L2)进行度量,当然,如果你有其他的度量方式,只需要将其作为函数添加到上面代码的最后。
我们首先建立一些简单的二维示例数据集来说明并可视化分类器的工作原理,下面的脚本将创建两个不同的二维点集,每个点集有两个类,用pickle模块来保存创建的数据:
# -*- coding: utf-8 -*-
from numpy.random import randn
import pickle
from pylab import *
# create sample data of 2D points
n = 200
# two normal distributions
class_1 = 0.6 * randn(n,2)
class_2 = 1.2 * randn(n,2) + array([5,1])
labels = hstack((ones(n),-ones(n)))
# save with Pickle
#with open('points_normal.pkl', 'w') as f:
with open('points_normal_test.pkl', 'wb') as f:
pickle.dump(class_1,f)
pickle.dump(class_2,f)
pickle.dump(labels,f)
# normal distribution and ring around it
print ("save OK!")
class_1 = 0.6 * randn(n,2)
r = 0.8 * randn(n,1) + 5
angle = 2*pi * randn(n,1)
class_2 = hstack((r*cos(angle),r*sin(angle)))
labels = hstack((ones(n),-ones(n)))
# save with Pickle
#with open('points_ring.pkl', 'w') as f:
with open('points_ring_test.pkl', 'wb') as f:
pickle.dump(class_1,f)
pickle.dump(class_2,f)
pickle.dump(labels,f)
print ("save OK!")
用不同的保存文件名运行该脚本两次,例如第一次用代码中的文件名进行保存,第二次将代码中的points_ normal_ t.pkl 和points_ ring pkl 分别改为points .normal test.pkl和points. ring. _test,pkl 进行保存。你将得到4个二维数据集文件,每个分布都有两个文件,我们可以将一个用来训练,另一个用来做测试。
# -*- coding: utf-8 -*-
import pickle
from pylab import *
from PCV.classifiers import knn
from PCV.tools import imtools
pklist=['points_normal.pkl','points_ring.pkl']
figure()
# load 2D points using Pickle
for i, pklfile in enumerate(pklist):
with open(pklfile, 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# load test data using Pickle
with open(pklfile[:-4]+'_test.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
model = knn.KnnClassifier(labels,vstack((class_1,class_2)))
# test on the first point
print (model.classify(class_1[0]))
#define function for plotting
def classify(x,y,model=model):
return array([model.classify([xx,yy]) for (xx,yy) in zip(x,y)])
# lot the classification boundary
subplot(1,2,i+1)
imtools.plot_2D_boundary([-6,6,-6,6],[class_1,class_2],classify,[1,-1])
titlename=pklfile[:-4]
title(titlename)
show()
四、实验结果
我们将k=3时,n=200时得到的实验结果如下图
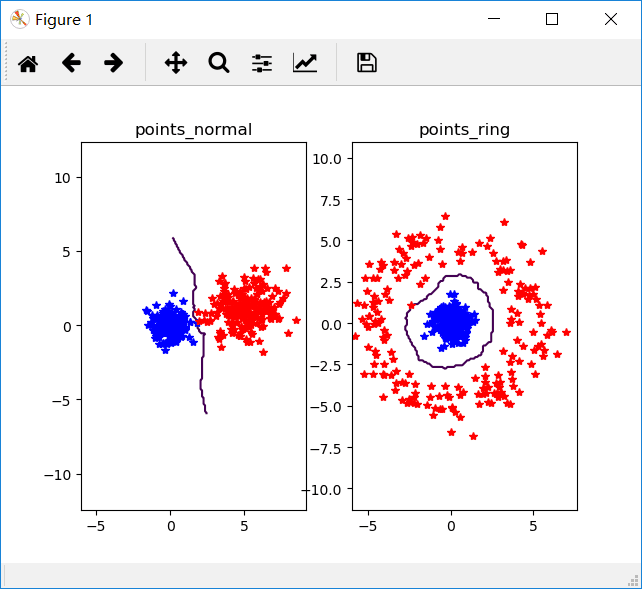
我们将k=5时,n=200时得到的实验结果如下图
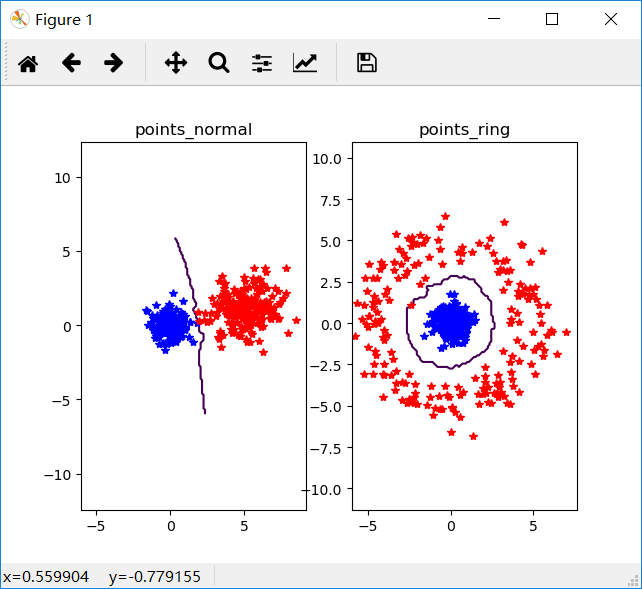
发现以上两个图并没有多大的区别,可以看出k在达到一定范围以后所获得打结果图没多大改变。
当我们将k=5时,n=400时得到的实验结果如下图
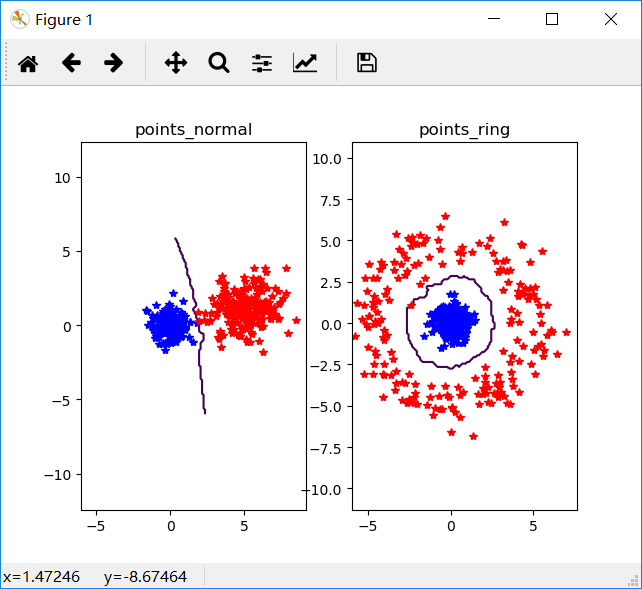
发现没什么改变。
稠密SIFT(Dense-sift)作为图像特征
from numpy import *
import os
from PCV.localdescriptors import sift
def process_image_dsift(imagename,resultname,size=20,steps=10,force_orientation=False,resize=None):
""" Process an image with densely sampled SIFT descriptors
and save the results in a file. Optional input: size of features,
steps between locations, forcing computation of descriptor orientation
(False means all are oriented upwards), tuple for resizing the image."""
im = Image.open(imagename).convert('L')
if resize!=None:
im = im.resize(resize)
m,n = im.size
if imagename[-3:] != 'pgm':
#create a pgm file
im.save('tmp.pgm')
imagename = 'tmp.pgm'
# create frames and save to temporary file
scale = size/3.0
x,y = meshgrid(range(steps,m,steps),range(steps,n,steps))
xx,yy = x.flatten(),y.flatten()
frame = array([xx,yy,scale*ones(xx.shape[0]),zeros(xx.shape[0])])
savetxt('tmp.frame',frame.T,fmt='%03.3f')
path = os.path.abspath(os.path.join(os.path.dirname("__file__"),os.path.pardir))
path = path + "\ch8\win32vlfeat\sift.exe "
print(path)
if force_orientation:
cmmd = str("sift " + imagename + " --output=" + resultname + " --read-frames=tmp.frame --orientations")
else:
cmmd = str("sift " + imagename + " --output=" + resultname + " --read-frames=tmp.frame")
os.system(cmmd)
os.system(cmmd)
print(cmmd)
print ('@ processed', imagename, 'to', resultname)
利用下面代码可以计算稠密SIFT描述子,并可视化他们的位置
-- coding: utf-8 --
from pylab import *
from PIL import Image
dsift.process_image_dsift('gesture/HH.jpg','HH.dsift',90,40,True)
l,d = sift.read_features_from_file('HH.dsift')
im = array(Image.open('gesture/HH.jpg'))
sift.plot_features(im,l,True)
title('dense SIFT')
show()
输出结果
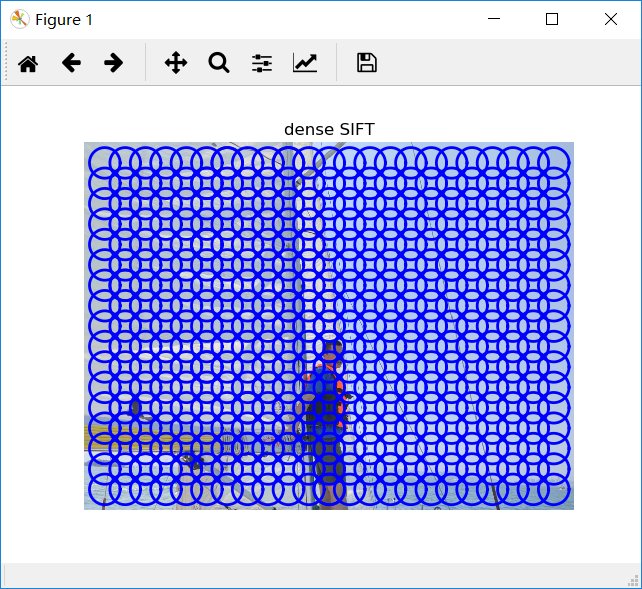
改变数据dsift.process_image_dsift(‘gesture/HH.jpg’,‘HH.dsift’,50,40,True)后,得到如图
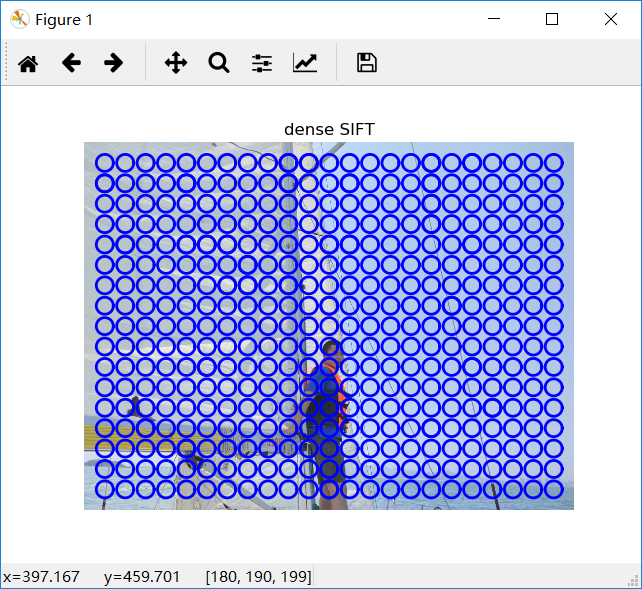
图像手势识别
图片像素均为100×100,且都为jpg格式
# -*- coding: utf-8 -*-
from PCV.localdescriptors import dsift
import os
from PCV.localdescriptors import sift
from pylab import *
from PCV.classifiers import knn
def get_imagelist(path):
""" Returns a list of filenames for
all jpg images in a directory. """
return [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.jpg')]
def read_gesture_features_labels(path):
# create list of all files ending in .dsift
featlist = [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.dsift')]
# read the features
features = []
for featfile in featlist:
l,d = sift.read_features_from_file(featfile)
features.append(d.flatten())
features = array(features)
# create labels
labels = [featfile.split('/')[-1][0] for featfile in featlist]
return features,array(labels)
def print_confusion(res,labels,classnames):
n = len(classnames)
# confusion matrix
class_ind = dict([(classnames[i],i) for i in range(n)])
confuse = zeros((n,n))
for i in range(len(test_labels)):
confuse[class_ind[res[i]],class_ind[test_labels[i]]] += 1
print ('Confusion matrix for')
print (classnames)
print (confuse)
filelist_train = get_imagelist('gesture/train2')
filelist_test = get_imagelist('gesture/test2')
imlist=filelist_train+filelist_test
# process images at fixed size (50,50)
for filename in imlist:
featfile = filename[:-3]+'dsift'
dsift.process_image_dsift(filename,featfile,10,5,resize=(50,50))
features,labels = read_gesture_features_labels('gesture/train2/')
test_features,test_labels = read_gesture_features_labels('gesture/test2/')
classnames = unique(labels)
# test kNN
k = 1
knn_classifier = knn.KnnClassifier(labels,features)
res = array([knn_classifier.classify(test_features[i],k) for i in
range(len(test_labels))])
# accuracy
acc = sum(1.0*(res==test_labels)) / len(test_labels)
print ('Accuracy:', acc)
print_confusion(res,test_labels,classnames)
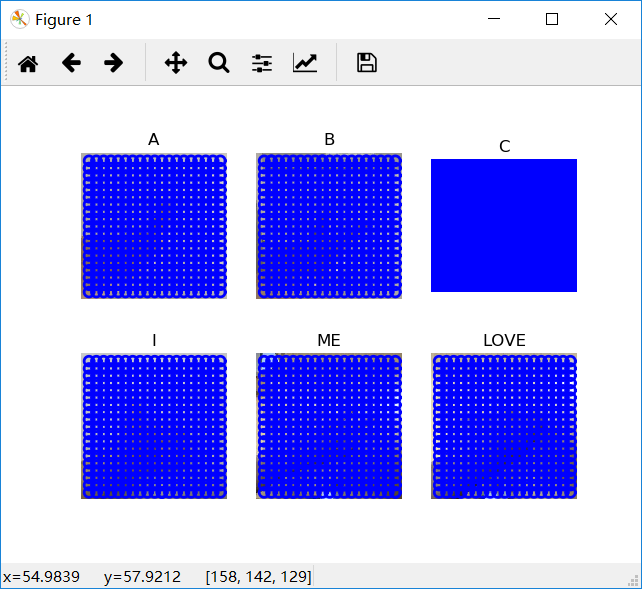
初始训练集一共有6种手势(记为A~F)
利用代码输出6个类别的参考手势
# -*- coding: utf-8 -*-
import os
from PCV.localdescriptors import sift, dsift
from pylab import *
from PIL import Image
# imlist=['gesture/train/C-uniform02.ppm','gesture/train/B-uniform01.ppm',
# 'gesture/train/A-uniform01.ppm','gesture/train/Five-uniform01.ppm',
# 'gesture/train/Point-uniform01.ppm','gesture/train/V-uniform01.ppm']
imlist=['gesture/train2/A-uniform01.jpg','gesture/train2/B-uniform01.jpg',
'gesture/train2/C-uniform01.jpg','gesture/train2/D-uniform01.jpg',
'gesture/train2/E-uniform01.jpg','gesture/train2/F-uniform01.jpg']
figure()
for i, im in enumerate(imlist):
print (im)
dsift.process_image_dsift(im,im[:-3]+'dsift',10,5,True)
l,d = sift.read_features_from_file(im[:-3]+'dsift')
dirpath, filename=os.path.split(im)
im = array(Image.open(im))
#显示手势含义title
titlename=filename[:-14]
subplot(2,3,i+1)
sift.plot_features(im,l,True)
title(titlename)
show()
图像分类
我们如果直接用训练的图片来作为模板,可以看到成功率是100%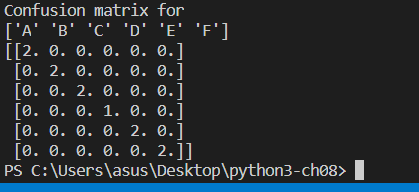
我们重新拍照来进行图片识别

得到如下结果
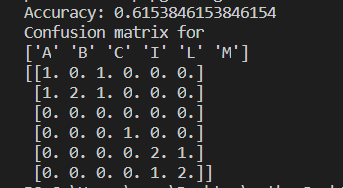
正确率有61%
当我们手势与训练集姿势相反


正确率只有10%
我们重新调整手势,得到的准确率有81%,当然数越和训练集图片接近,得到的准确率越高。在这里插入图片描述
实验结论
1.KNN算法简单,易于理解,易于实现,无需估计参数,无需训练,适合对稀有事件进行分类。
2.训练集越大,识别的准确率就越高
3.容易计算出正确的分类数
最后
以上就是彩色水池最近收集整理的关于python计算机视觉KNN算法、稠密Dense-sift及图像手势识别KNN算法稠密SIFT(Dense-sift)作为图像特征-- coding: utf-8 --图像手势识别的全部内容,更多相关python计算机视觉KNN算法、稠密Dense-sift及图像手势识别KNN算法稠密SIFT(Dense-sift)作为图像特征--内容请搜索靠谱客的其他文章。








发表评论 取消回复