Apollo代码学习—MPC与LQR比较
- 前言
- 研究对象
- 状态方程
- 工作时域
- 目标函数
- 求解方法
前言
Apollo中用到了PID、MPC和LQR三种控制器,其中,MPC和LQR控制器在状态方程的形式、状态变量的形式、目标函数的形式等有诸多相似之处,因此结合自己目前了解到的信息,将两者进行一定的比较。
MPC( Model predictive control, 模型预测控制 ) 和 LQR( Linear–quadratic regulator,线性二次调解器 ) 在状态方程、控制实现等方面,有很多相似之处,但也有很多不同之处,如工作时域、最优解等,基于各自的理论基础,从研究对象、状态方程、目标函数、求解方法等方面, 对MPC和LQR做简要对比分析。对MPC的详细讲解请参考我的上一篇博文:Apollo代码学习(六)—模型预测控制(MPC)
本文主要参考内容:
【1】龚建伟, 姜岩, 徐威. 无人驾驶车辆模型预测控制[M]. 北京理工大学出版社, 2014.
【2】Model predictive control-Wikipedia
【3】Linear–quadratic regulator-Wikipedia
【4】Inverted Pendulum: State-Space Methods for Controller Design
【5】王金城. 现代控制理论[M]. 化学工业出版社, 2007.
研究对象
LQR的研究对象是现代控制理论中以状态空间方程形式给出的线性系统。MPC的研究对象可以是线性系统,也可以是非线性系统,只不过为了某些需求,如时效性,计算的便捷,操控性等,一般会将非线性系统转换为线性系统进行计算。非线性系统的线性化可参考上一篇文章。
Apollo中,LQR和MPC控制器都选用的单车动力学模型作为研究对象,单车动力学模型为非线性系统,但LQR和MPC控制器的目的是为了求最优控制解,在具体的优化求解时,均通过线性化方法将状态方程转化为线性方程进行求解,所以,可以说apollo中LQR和MPC控制器的研究对象均为线性系统。
状态方程
LQR的状态方程多以微分方程的形式给出,如:
(1)
x
˙
=
A
x
+
B
u
dot{x}=Ax+Bu tag{1}
x˙=Ax+Bu(1)
是一个连续线性系统,在计算过程中需要转换为如公式3的离散线性系统。
MPC的状态方程可以为线性系统,可以为非线性系统,非线性系统形如下:
(2)
ξ
˙
=
f
(
ξ
,
u
)
dot{xi}=f(xi,u) tag{2}
ξ˙=f(ξ,u)(2)
线性系统如公式3所示:
(3)
x
(
t
+
1
)
=
A
x
(
t
)
+
B
u
(
t
)
x(t+1)=Ax(t)+Bu(t) tag{3}
x(t+1)=Ax(t)+Bu(t)(3)
但LQR和MPC在计算求解时基本都是基于离散线性方程计算的。公式1可以很方便的转化为公式2的形式。离散化的方法可参考上一篇文章:Apollo代码学习(六)—模型预测控制(MPC)
工作时域
按照维基百科的说法:
The main differences between MPC and LQR are that LQR optimizes in a fixed time window (horizon) whereas MPC optimizes in a receding time window, and that a new solution is computed often whereas LQR uses the single (optimal) solution for the whole time horizon.
LQR在一个固定的时域上求解,且一个时域内只有一个最优解,而MPC在一个逐渐消减的时域内( in a receding time window )求解最优解,且最优解经常更新。
可以结合MPC的滚动优化,以及图1进行理解:
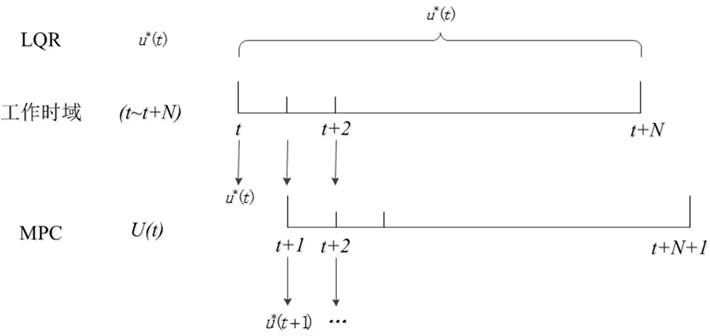
针对同一工作时域
[
t
,
t
+
N
]
[t, t+N]
[t,t+N],LQR在该时域中,有唯一最优控制解
u
∗
(
t
)
u^*(t)
u∗(t),而MPC仅在
t
t
t时刻有最优解
u
∗
(
t
)
u^*(t)
u∗(t),但它会计算出一个控制序列
U
(
t
)
U(t)
U(t),并仅将序列的第一个值
u
∗
(
t
)
u^*(t)
u∗(t)作为控制量输出给控制系统,然后在下一采样时间结合车辆当前状况求取下一个最优控制解
u
∗
(
t
+
1
)
u^*(t+1)
u∗(t+1),这就是MPC所谓的滚动优化。这么做的目的是为了使控制效果在一定时间内可期,并且能根据控制效果尽早调整控制变量,使实际状态更切合期望状态。
此外,LQR的工作时域可以拓展到无限大,即可以求取无限时域的最优控制解,当然,一般并不会这么用。而MPC只针对有限时域。
目标函数
优化求解问题一般离不开目标函数的设计。
LQR的目标函数的一般形式为:
(4)
J
=
1
2
x
T
(
t
f
)
Q
0
(
t
)
x
(
t
f
)
+
1
2
∫
t
0
t
f
[
x
T
Q
x
+
u
t
R
u
]
d
t
J=frac{1}{2}x^T(t_f)Q_0(t)x(t_f)+frac{1}{2}int_{t0}^{tf}[x^TQx+u^tRu]dt tag{4}
J=21xT(tf)Q0(t)x(tf)+21∫t0tf[xTQx+utRu]dt(4)
其中,
x
(
t
f
)
x(t_f)
x(tf)为终端状态,
Q
0
(
t
)
Q_0(t)
Q0(t)为正定的终端加权矩阵,
x
x
x为状态变量,多为各种误差,
u
u
u为控制变量,
Q
Q
Q为半正定的状态加权矩阵,
R
R
R为正定的控制加权矩阵,实际应用中,
Q
、
R
Q、R
Q、R多为对角矩阵。
MPC的目标函数的一般形式为:
(5)
J
=
x
(
t
+
N
)
Q
0
x
(
t
+
N
)
+
∑
i
=
1
N
(
x
(
t
+
i
∣
t
)
T
Q
x
(
t
+
i
∣
t
)
+
u
(
t
+
i
−
1
)
T
R
u
(
t
+
i
−
1
)
)
J=x(t+N)Q_0x(t+N)+sum_{i=1}^N(x(t+i|t)^TQx(t+i|t)+u(t+i-1)^TRu(t+i-1)) tag{5}
J=x(t+N)Q0x(t+N)+i=1∑N(x(t+i∣t)TQx(t+i∣t)+u(t+i−1)TRu(t+i−1))(5)
其中,
x
、
u
、
Q
0
、
Q
、
R
x、u、Q_0、Q、R
x、u、Q0、Q、R的定义同上。
从形式上可以看出,LQR的目标函数为积分形式,MPC的目标函数为求和形式,但其实都是对代价的累计。两者第一部分均为终端代价函数,当系统对终端状态要求极严的情况下才添加,一般情况下可省略。
x
T
Q
x
x^TQx
xTQx项代表跟踪代价,表示跟踪过程中误差的大小,
u
T
R
u
u^TRu
uTRu项代表控制代价,表示对控制的约束或要求等。
求解方法
正如工作时域所述,针对同一工作时域,LQR有唯一最优控制解,也就是在该控制周期内,LQR只进行一次计算。而MPC滚动优化的思想,使其给出该时域内的一组控制序列对应不同的采样时刻(采样周期和控制周期不一定相同),但是只将该序列的第一个值输出给被控系统,作为该时刻的最优控制解。因此,对于工作时域 [ t , t + N ] [t, t+N] [t,t+N],LQR只有唯一解,MPC可能有 N N N个解。
最优控制解的求取多基于目标函数进行,取线性约束下的目标函数的极值为最优控制解。对于系统为线性,目标函数为状态变量和控制变量的二次型函数的线性二次性问题,一般线性二次性问题的最优解具有统一的解析表达式。apollo中的MPC将优化问题转化为二次规划问题,利用二次规划求解器进行求解。横向控制中用的是LQR调节器,它通过假设控制量 u ( t ) u(t) u(t)不受约束,利用变分法求解。
此外,LQR对整个时域进行优化求解,且求解过程中假设控制量不受约束,但是实际情况下,控制量是有约束的。而MPC通常在比整个时域更小的时间窗口中解决优化问题,因此可能获得次优解,且对线性不作任何假设,它能够处理硬约束以及非线性系统偏离其线性化工作点的迁移,这两者都是LQR的缺点。
最后
以上就是心灵美洋葱最近收集整理的关于Apollo代码学习(七)—MPC与LQR比较前言研究对象状态方程工作时域目标函数求解方法的全部内容,更多相关Apollo代码学习(七)—MPC与LQR比较前言研究对象状态方程工作时域目标函数求解方法内容请搜索靠谱客的其他文章。








发表评论 取消回复