我是靠谱客的博主 动听黑夜,这篇文章主要介绍使用vectorizer.fit_transform时出现AttributeError: 'file' object has no attribute 'lower'问题解决方法,现在分享给大家,希望可以做个参考。
问题
最近在读书《Building Machine Learning Systems with Python》1第一版,发现其中的一个代码错误,
AttributeError: ‘file’ object has no attribute ‘lower’
产生该错误的代码为:
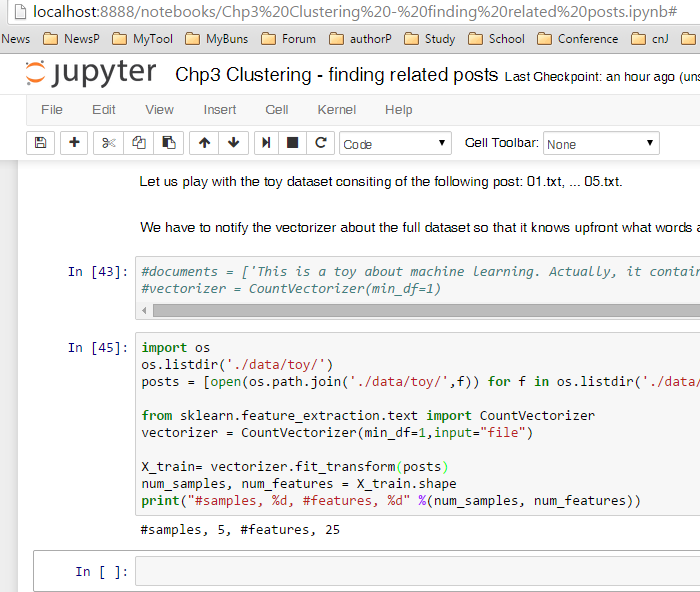
import os
os.listdir('./data/toy/')
posts = [open(os.path.join('./data/toy/',f)) for f in os.listdir('./data/toy/')]
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1)
X_train= vectorizer.fit_transform(posts)
num_samples, num_features = X_train.shape
print("#samples, %d, #features, %d" %(num_samples, num_features))解决方法
感谢网站提供的解决方法,即将vectorizer = CountVectorizer(min_df=1)改为
vectorizer = CountVectorizer(min_df=1,input="file")即可解决上面的错误。
由于我使用的是Ipython notebook运行环境,在同一个cell里面将代码改变了以后,重新运行,则出现了新的错误:
ValueError: empty vocabulary; perhaps the documents only contain stop words尝试了半天也没有找到合适的解决办法。最后,我找到了解决办法:删除所有含有之前代码的cell,新建一个cell,在里面写入更新的代码,即可解决 “empty vocabularty”错误。这个错误与代码本身无关,而与使用的Ipython notebook环境有关。希望大家在以后使用Ipython notebook时,注意这类的问题。
运行成功的界面为:
- Building Machine Learning Systems with Python. 2013. Willi Ricchert, Luis Pedro Coelho. Packt publishing. ↩
最后
以上就是动听黑夜最近收集整理的关于使用vectorizer.fit_transform时出现AttributeError: 'file' object has no attribute 'lower'问题解决方法的全部内容,更多相关使用vectorizer.fit_transform时出现AttributeError:内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复