目录
尝试1--唯一运行成功的
尝试2
尝试3
尝试4--希望最大
尝试5
后续成功!
前提:虽然成功训练完了,但是想到以后万一训练轮数太少没收敛,怎么在已经训练好的模型基础上继续进行多轮epoch的训练。或者训练着突然中断,之前训练的岂不是功亏一篑。
起因:在kaggle上训练完150轮之后查看结果,mAP值和recall值感觉不是特别高,思考是不是再多训练几轮网络会更收敛。寻找继续训练的方法。
找了好多解决办法,都没解决问题,一下午没了,已经没有动力debug了,记录一下,方便下次有同样的问题拿来再尝试。
继续训练包括两种方式:
- 训练过程中中断了,继续训练
- 训练完了,但是未收敛,在这个基础上,还想用这个权重、学习率等参数继续训练多一些批次
尝试1--唯一运行成功的
思路:
直接用last.pt权重,epoch=要继续训练的轮数,比如想在训练100轮,epoch=100
!python train.py --weights /kaggle/input/face-mask/last.pt --epochs 100 --device 0 思考:
相当于重新在原来基础上重新训练,并不是继续训练,结果也并没有很好,有一种不连贯的感觉。
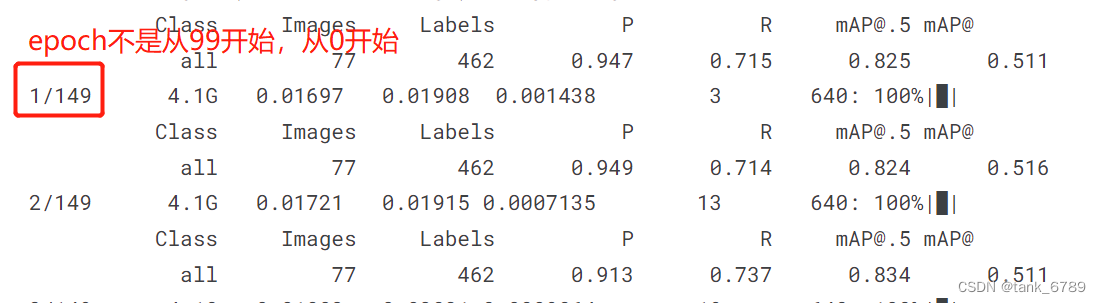
- 原来训练的结果150轮:
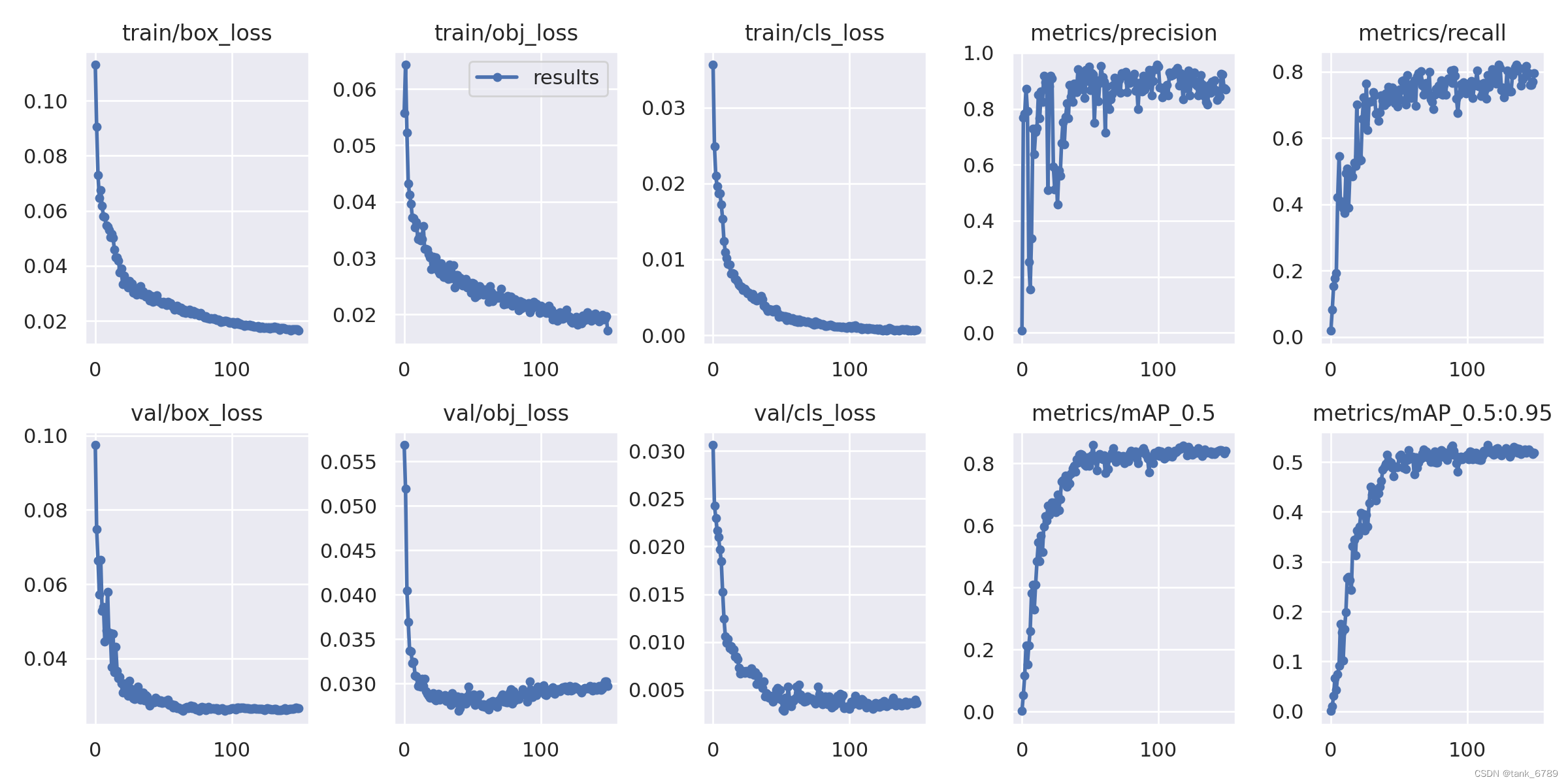
- 重新用last.pt训练150轮的结果:(以为再训练150轮就能更好,结果并没有,糟糕糟糕OMG)
尝试2
参考博客:Kaggle平台持续运行项目最多9小时的解决方法
- 思路:
- 把要训练的轮次分两次训练,比如100+100,第一次训练epoch=100,第二次训练epoch=200
- 记得save version,方便查看日志文件。
- 把训练好100轮的权重文件下载下来,再上传到kaggle和训练文件放在一起。
- 前100轮跑完之后,更改代码中的epoch值,更改模型读取保存模型的路径。
!python tarin.py --epoch 200 --weights last.pt路径 # 根据理解写出更改部分- 思考:
博主提到的什么“代码里加上一句,把之前训练好的模型加入到现在的日志文件中。”然后对代码的修改,怀疑该方法不适用于yolov5,因为看其他博主都会提到resume参数的设置。
尝试3
参考博客:yolov5 显示每个类别的mAP以及如何继续训练
思路:
1、将resume参数设置为Ture
2、设置weights参数中的default = ''填入想要继续训练的生成的exp中的last.pt的路径
思考:
这位博主并没有提到他的继续训练是针对于哪种情况,暂时归到第二种情况下,他本来在源代码上修改,我觉得没有必要,可以直接在终端输入指令:
!python train.py --weights last.pt路径 --resume True后来又看到一篇博文说要在源代码上改才行,虽然心里不理解,后来在源代码上更改之后还是报错。
AssertionError: ERROR: --resume checkpoint does not exist
解决过程:一步解决:AssertionError: ERROR: --resume checkpoint does not exist
结果:并没有解决,开始报其他错。唉!
Traceback (most recent call last):
File "train.py", line 621, in <module>
main(opt)
File "train.py", line 492, in main
with open(Path(ckpt).parent.parent / 'opt.yaml', errors='ignore') as f:
FileNotFoundError: [Errno 2] No such file or directory: '/kaggle/input/opt.yaml'尝试4--希望最大
参考博客:yolov5 继续训练
思路:
第一种情况:
断电、或者什么原因中断了,比如设定epoch为200,但是在90这里中断了,想从断点这里继续训练到200 epoch。
直接在train.py设置resume参数为True即可
parser.add_argument('--resume', default=True, help='resume most recent training') # 感觉很靠谱,还没有遇到过这个情况,如果遇到就参考这个
第二种情况:
思路:
1、说是把resume改为ture,epoch改为300,然而下面的提示代码确实更改weights的,不理解为什么,到底改不改weights??
2、在train代码中#epoch部分下添加:
ckpt['epoch'] = 200 # 我认为应该是199,虽然训练了200轮,但是其实是0-199
思考:
不知道要不要改权重文件,理解resume和epoch确实要改,weights要不要改不确定,但是两种都试也报错:
AssertionError: ERROR: --resume checkpoint does not exist # 醉了
尝试5
参考博文:yolov5——断点训练/继续训练【解决方法、使用教程】
思路:适用情况1
1、改resume参数为True
2、更改权重为last.pt
3、开始训练
python train.py --weights last.pt路径
思考:
该方法针对于情况1,我没遇到过,遇到后可尝试。我的情况使用后好像还是报了一样的错误,resume checkpoint does not exist
后续成功!
- 前提:在colab上训练一边看数据,一开始设置的epoch为150,觉得有点多,100就够了,去搜了之后,发现很简单就解决了。
- 适用:正在训练过程中可以终止的程序。变大变小epoch都可以。
1、首先终止程序,也适用于正在训练之后突然断电终止。(一个主动终止,一个被动终止)
2、修改train.py→resume参数default为True。
![]()
3、修改runs→train→exp11中opt.yaml中epoch数目为你想要的数字。
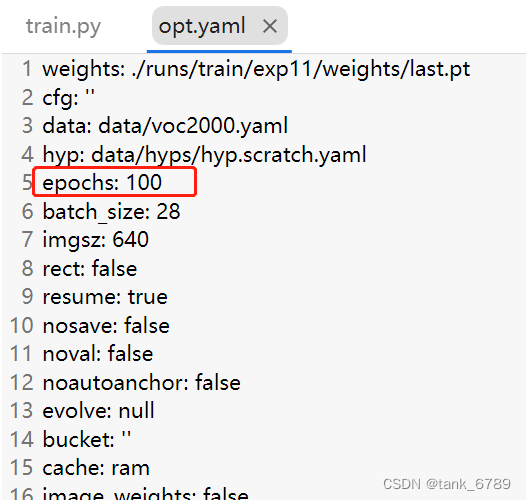
4、重新开始运行train.py文件即可。
最后
以上就是谦让小笼包最近收集整理的关于yolov5继续训练的方法,没解决sad尝试1--唯一运行成功的尝试2尝试3尝试4--希望最大尝试5的全部内容,更多相关yolov5继续训练内容请搜索靠谱客的其他文章。








发表评论 取消回复