方式一:不显示设置读取N个epoch的数据,而是使用循环,每次从训练的文件中随机读取一个batch_size的数据,直至最后读取的数据量达到N个epoch。说明,这个方式来实现epoch的输入是不合理。不是说每个样本都会被读取到的。
对于这个的解释,从数学上解释,比如说有放回的抽样,每次抽取一个样本,抽取N次,总样本数为N个。那么,这样抽取过一轮之后,该样本也是会有1/e的概率没有被抽取到。所以,如果使用这种方式去训练的话,理论上是没有用到全部的数据集去训练的,很可能会造成过拟合的现象。

我做了个小实验验证:
import tensorflow as tf
import numpy as np
import datetime,sys
from tensorflow.contrib import learn
from model import CCPM
training_epochs = 5
train_num = 4
# 运行Graph
with tf.Session() as sess:
#定义模型
BATCH_SIZE = 2
# 构建训练数据输入的队列
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['a.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=True)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
# 编码后的数据字段有24,其中22维是特征字段,2维是lable字段,label是二分类经过one-hot编码后的字段
#更改了特征,使用不同的解析参数
record_defaults = [[1]]*5
col1,col2,col3,col4,col5 = tf.decode_csv(value,record_defaults=record_defaults)
features = tf.pack([col1,col2,col3,col4])
label = tf.pack([col5])
example_batch, label_batch = tf.train.shuffle_batch([features,label], batch_size=BATCH_SIZE, capacity=20000, min_after_dequeue=4000, num_threads=2)
sess.run(tf.initialize_all_variables())
coord = tf.train.Coordinator()#创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord)#启动QueueRunner, 此时文件名队列已经进队。
#开始一个epoch的训练
for epoch in range(training_epochs):
total_batch = int(train_num/BATCH_SIZE)
#开始一个epoch的训练
for i in range(total_batch):
X,Y = sess.run([example_batch, label_batch])
print X,':',Y
coord.request_stop()
coord.join(threads)
toy data a.csv:
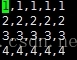
说明:输出如下,可以看出并不是每个样本都被遍历5次,其实这样的话,对于DL的训练会产生很大的影响,并不是每个样本都被使用同样的次数。
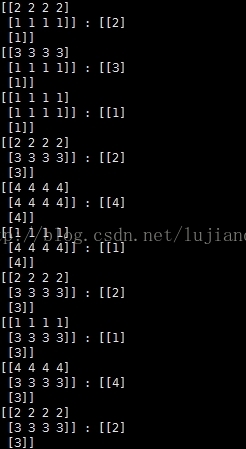
方式二:显示设置epoch的数目
#-*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np
import datetime,sys
from tensorflow.contrib import learn
from model import CCPM
training_epochs = 5
train_num = 4
# 运行Graph
with tf.Session() as sess:
#定义模型
BATCH_SIZE = 2
# 构建训练数据输入的队列
# 生成一个先入先出队列和一个QueueRunner,生成文件名队列
filenames = ['a.csv']
filename_queue = tf.train.string_input_producer(filenames, shuffle=True,num_epochs=training_epochs)
# 定义Reader
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 定义Decoder
# 编码后的数据字段有24,其中22维是特征字段,2维是lable字段,label是二分类经过one-hot编码后的字段
#更改了特征,使用不同的解析参数
record_defaults = [[1]]*5
col1,col2,col3,col4,col5 = tf.decode_csv(value,record_defaults=record_defaults)
features = tf.pack([col1,col2,col3,col4])
label = tf.pack([col5])
example_batch, label_batch = tf.train.shuffle_batch([features,label], batch_size=BATCH_SIZE, capacity=20000, min_after_dequeue=4000, num_threads=2)
sess.run(tf.initialize_local_variables())
sess.run(tf.initialize_all_variables())
coord = tf.train.Coordinator()#创建一个协调器,管理线程
threads = tf.train.start_queue_runners(coord=coord)#启动QueueRunner, 此时文件名队列已经进队。
try:
#开始一个epoch的训练
while not coord.should_stop():
total_batch = int(train_num/BATCH_SIZE)
#开始一个epoch的训练
for i in range(total_batch):
X,Y = sess.run([example_batch, label_batch])
print X,':',Y
except tf.errors.OutOfRangeError:
print('Done training')
finally:
coord.request_stop()
coord.join(threads)
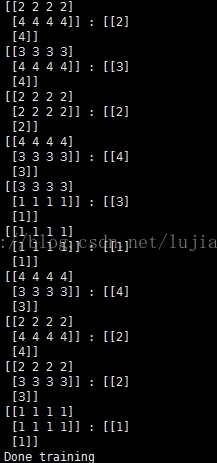
http://stats.stackexchange.com/questions/242004/why-do-neural-network-researchers-care-about-epochs
说明:这个博客也在探讨,为什么深度网络的训练中,要使用epoch,即要把训练样本全部过一遍.而不是随机有放回的从里面抽样batch_size个样本.在博客中,别人的实验结果是如果采用有放回抽样的这种方式来进行SGD的训练.其实网络见不到全部的数据集,推导过程如上所示.所以,网络的收敛速度比较慢.
最后
以上就是不安水池最近收集整理的关于tesnorflow实现N个epoch训练数据读取的办法的全部内容,更多相关tesnorflow实现N个epoch训练数据读取内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复