文章目录
- 决策树
- 决策树特点
- 决策树算法
- 决策树流程
- 数据:海洋生物数据
- 一、信息增益
- 使用python计算信息熵
- 测试数据
- 二、划分数据集
- 按照给定特征划分数据集
- 测试
- 选择最好的数据集划分方式
- 测试
- 三、递归构建决策树
- 多数表决
- 创建树的函数代码
- 测试:
决策树
决策树特点
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
- 缺点:可能会产生过度匹配问题。
- 适用数据类型:数值型和标称型。
决策树算法
在构造决策树时,我们需要解决的第一个问题就是,当前数据集上哪个特征在划分数据分类时起决定性作用。为了找到决定性的特征,划分出最好的结果,我们必须评估每个特征。完成测试之后,原始数据集就被划分为几个数据子集。这些数据子集会分布在第一个决策点的所有分支上。如果某个分支下的数据属于同一类型,则当前无需阅读的垃圾邮件已经正确地划分数据分类,无需进一步对数据集进行分割。如果数据子集内的数据不属于同一类型,则需要重复划分数据子集的过程。划分数据子集的算法和划分原始数据集的方法相同,直到所有具有相同类型的数据均在一个数据子集内。
创建分支的伪代码函数createBranch()如下所示:

决策树流程
- 收集数据:可以使用任何方法。
- 准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。
- 分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期。
- 训练算法:构造树的数据结构。
- 测试算法:使用经验树计算错误率。
- 使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义。
数据:海洋生物数据
表3-1的数据包含5个海洋动物,特征包括:不浮出水面是否可以生存,以及是否有脚蹼。我们可以将这些动物分成两类:鱼类和非鱼类。现在我们想要决定依据第一个特征还是第二个特征划分数据。在回答这个问题之前,我们必须采用量化的方法判断如何划分数据。

一、信息增益
划分数据集的大原则是:将无序的数据变得更加有序。我们可以使用多种方法划分数据集,但是每种方法都有各自的优缺点。组织杂乱无章数据的一种方法就是使用信息论度量信息,信息论是量化处理信息的分支科学。我们可以在划分数据之前或之后使用信息论量化度量信息的内容。
在划分数据集之前之后信息发生的变化称为信息增益,知道如何计算信息增益,我们就可以计算每个特征值划分数据集获得的信息增益,获得信息增益最高的特征就是最好的选择。
集合信息的度量方式称为香农熵或者简称为熵,这个名字来源于信息论之父克劳德·香农。
熵定义为信息的期望值,在明晰这个概念之前,我们必须知道信息的定义。如果待分类的事务可能划分在多个分类之中,则符号xi的信息定义为
I
(
x
i
)
=
−
l
o
g
2
p
(
x
i
)
I(x_i)=-log_2p(x_i)
I(xi)=−log2p(xi)
其中
p
(
x
i
)
p(x_i)
p(xi)是选择该分类的概率。
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值,通过下面的公式得到:其中n是分类的数目。
H
=
−
∑
i
=
1
n
p
(
x
i
)
l
o
g
2
p
(
x
i
)
H = -sum^n_{i=1}p(x_i)log_2p(x_i)
H=−i=1∑np(xi)log2p(xi)
使用python计算信息熵
tree.py
from math import log
## 计算香农熵###########################
def calcShannoEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
# 为所有可能分类创建字典
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannoEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key]) / numEntries
# 求log2
shannoEnt -= prob * log(prob, 2)
return shannoEnt
首先,计算数据集中实例的总数。我们也可以在需要时再计算这个值,但是由于代码中多次用到这个值,为了提高代码效率,我们显式地声明一个变量保存实例总数。然后,创建一个数据字典,它的键值是最后一列的数值1。如果当前键值不存在,则扩展字典并将当前键值加入字典。每个键值都记录了当前类别出现的次数。最后,使用所有类标签的发生频率计算类别出现的概率。我们将用这个概率计算香农熵2,统计所有类标签发生的次数。
测试数据
在trees.py文件中,我们可以利用createDataSet()函数得到表3-1所示的简单鱼鉴定数据集,你可以输入自己的createDataSet()函数:
## 测试数据——海洋生物数据 #######################
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing', 'flippers']
return dataSet, labels
进行测试:
## 测试:
myDat, labels = createDataSet()
print(myDat)
print(calcShannoEnt(myDat))
=======================================
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
0.9709505944546686
熵越高,则混合的数据也越多,我们可以在数据集中添加更多的分类,观察熵是如何变化的。这里我们增加第三个名为maybe的分类,测试熵的变化:
## 测试:
myDat, labels = createDataSet()
myDat[0][-1] = 'maybe'
print(myDat)
print(calcShannoEnt(myDat))
==============================
[[1, 1, 'maybe'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
1.3709505944546687
得到熵之后,我们就可以按照获取最大信息增益的方法划分数据集
二、划分数据集
分类算法除了需要测量信息熵,还需要划分数据集,度量划分数据集的熵,以便判断当前是否正确地划分了数据集。我们将对每个特征划分数据集的结果计算一次信息熵,然后判断按照哪个特征划分数据集是最好的划分方式。想象一个分布在二维空间的数据散点图,需要在数据之间划条线,将它们分成两部分,我们应该按照x轴还是y轴划线呢?
按照给定特征划分数据集
## 按照给定特征划分数据集######################
def splitDataSet(dataSet, axis, value):
retDataSet = []
# 抽取
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis + 1:])
retDataSet.append(reducedFeatVec)
return retDataSet
代码使用了三个输入参数:待划分的数据集、划分数据集的特征、需要返回的特征的值。
我们要遍历数据集中的每个元素,一旦发现符合要求的值,则将其添加到新创建的列表中。在if语句中,程序将符合特征的数据抽取出来。后面讲述得更简单,这里我们可以这样理解这段代码:当我们按照某个特征划分数据集时,就需要将所有符合要求的元素抽取出来。代码中使用了Python语言列表类型自带的extend()和append()方法。这两个方法功能类似,但是在处理多个列表时,这两个方法的处理结果是完全不同的。
测试
## 测试2:
myDat, labels = createDataSet()
print(myDat)
print(splitDataSet(myDat, 0, 1))
print(splitDataSet(myDat, 0, 0))
==================================
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
[[1, 'yes'], [1, 'yes'], [0, 'no']]
[[1, 'no'], [1, 'no']]
接下来我们将遍历整个数据集,循环计算香农熵和splitDataSet()函数,找到最好的特征划分方式。熵计算将会告诉我们如何划分数据集是最好的数据组织方式。
选择最好的数据集划分方式
## 选择最好的数据集划分方式#########################
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannoEnt(dataSet)
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
# 创建唯一的分类标签列表
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
# 计算每种划分方式的信息熵
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannoEnt(subDataSet)
infoGain = baseEntropy - newEntropy
# 计算最好的信息熵
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
该函数实现选取特征,划分数据集,计算得出最好的划分数据集的特征。
在函数中调用的数据需要满足一定的要求:第一个要求是,数据必须是一种由列表元素组成的列表,而且所有的列表元素都要具有相同的数据长度;第二个要求是,数据的最后一列或者每个实例的最后一个元素是当前实例的类别标签。数据集一旦满足上述要求,我们就可以在函数的第一行判定当前数据集包含多少特征属性。我们无需限定list中的数据类型,它们既可以是数字也可以是字符串,并不影响实际计算。
在开始划分数据集之前,代码计算了整个数据集的原始香农熵,我们保存最初的无序度量值,用于与划分完之后的数据集计算的熵值进行比较。第1个for循环遍历数据集中的所有特征。使用列表推导(ListComprehension)来创建新的列表,将数据集中所有第i个特征值或者所有可能存在的值写入这个新list中。然后使用Python语言原生的集合(set)数据类型。集合数据类型与列表类型相似,不同之处仅在于集合类型中的每个值互不相同。从列表中创建集合是Python语言得到列表中唯一元素值的最快方法。
遍历当前特征中的所有唯一属性值,对每个唯一属性值划分一次数据集,然后计算数据集的新熵值,并对所有唯一特征值得到的熵求和。信息增益是熵的减少或者是数据无序度的减少,大家肯定对于将熵用于度量数据无序度的减少更容易理解。最后,比较所有特征中的信息增益,返回最好特征划分的索引值。
测试
## 测试3:
myDat, labels = createDataSet()
print(chooseBestFeatureToSplit(myDat))
print(myDat)
===================================
0
[[1, 1, 'yes'], [1, 1, 'yes'], [1, 0, 'no'], [0, 1, 'no'], [0, 1, 'no']]
代码运行结果告诉我们,第0个特征是最好的用于划分数据集的特征。结果是否正确呢?这个结果又有什么实际意义呢?数据集中的数据来源于表3-1,让我们回头再看一下表3-1或者变量myDat中的数据。如果我们按照第一个特征属性划分数据,也就是说第一个特征是1的放在一个组,第一个特征是0的放在另一个组,数据一致性如何?按照上述的方法划分数据集,第一个特征为1的海洋生物分组将有两个属于鱼类,一个属于非鱼类;另一个分组则全部属于非鱼类。如果按照第二个特征分组,结果又是怎么样呢?第一个海洋动物分组将有两个属于鱼类,两个属于非鱼类;另一个分组则只有一个非鱼类。第一种划分很好地处理了相关数据。如果不相信目测结果,读者可以使用程序清单3-1的calcShannonEntropy()函数测试不同特征分组的输出结果。
三、递归构建决策树
目前我们已经学习了从数据集构造决策树算法所需要的子功能模块,其工作原理如下:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分之后,数据将被向下传递到树分支的下一个节点,在这个节点上,我们可以再次划分数据。因此我们可以采用递归的原则处理数据集。
递归结束的条件是:程序遍历完所有划分数据集的属性,或者每个分支下的所有实例都具有相同的分类。如果所有实例具有相同的分类,则得到一个叶子节点或者终止块。任何到达叶子节点的数据必然属于叶子节点的分类,参见图3-2所示。
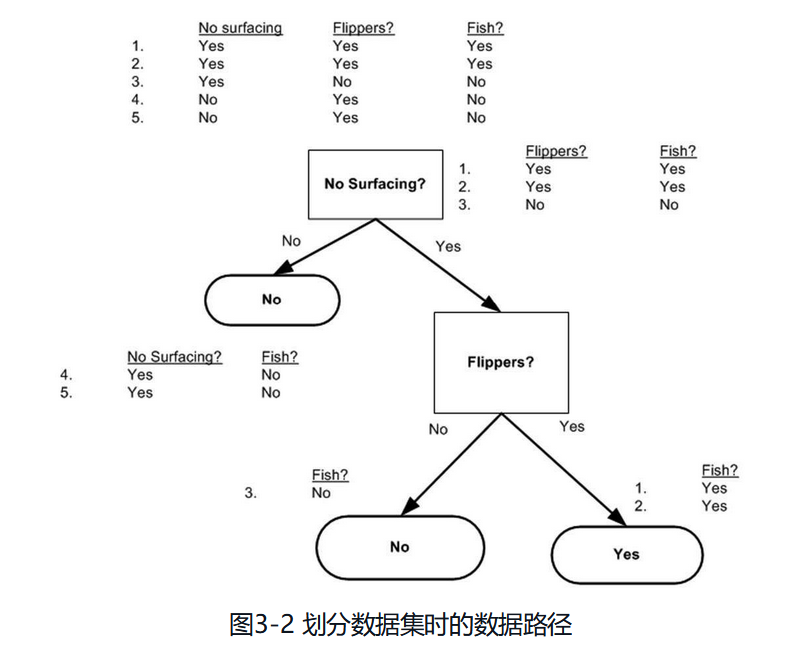 第一个结束条件使得算法可以终止,我们甚至可以设置算法可以划分的最大分组数目。后续章节还会介绍其他决策树算法,如C4.5和CART,这些算法在运行时并不总是在每次划分分组时都会消耗特征。由于特征数目并不是在每次划分数据分组时都减少,因此这些算法在实际使用时可能引起一定的问题。目前我们并不需要考虑这个问题,只需要在算法开始运行前计算列的数目,查看算法是否使用了所有属性即可。如果数据集已经处理了所有属性,但是类标签依然不是唯一的,此时我们需要决定如何定义该叶子节点,在这种情况下,我们通常会采用多数表决的方法决定该叶子节点的分类。
第一个结束条件使得算法可以终止,我们甚至可以设置算法可以划分的最大分组数目。后续章节还会介绍其他决策树算法,如C4.5和CART,这些算法在运行时并不总是在每次划分分组时都会消耗特征。由于特征数目并不是在每次划分数据分组时都减少,因此这些算法在实际使用时可能引起一定的问题。目前我们并不需要考虑这个问题,只需要在算法开始运行前计算列的数目,查看算法是否使用了所有属性即可。如果数据集已经处理了所有属性,但是类标签依然不是唯一的,此时我们需要决定如何定义该叶子节点,在这种情况下,我们通常会采用多数表决的方法决定该叶子节点的分类。
多数表决
## 多数表决#########################
import operator
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
该函数使用分类名称的列表,然后创建键值为classList中唯一值的数据字典,字典对象存储了classList中每个类标签出现的频率,最后利用operator操作键值排序字典,并返回出现次数最多的分类名称。
创建树的函数代码
## 创建树的函数代码######################
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
# 类别完全相同则停止继续划分
if classList.count(classList[0]) == len(classList):
return classList[0]
# 遍历完所有特征时返回出现次数最多的类别
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
# 得到列表包含的所有属性值
del (labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
代码使用两个输入参数:数据集和标签列表。标签列表包含了数据集中所有特征的标签,算法本身并不需要这个变量,但是为了给出数据明确的含义,我们将它作为一个输入参数提供。此外,前面提到的对数据集的要求这里依然需要满足。上述代码首先创建了名为classList的列表变量,其中包含了数据集的所有类标签。递归函数的第一个停止条件是所有的类标签完全相同,则直接返回该类标签。递归函数的第二个停止条件是使用完了所有特征,仍然不能将数据集划分成仅包含唯一类别的分组。由于第二个条件无法简单地返回唯一的类标签,这里使用前面介绍的majorityCnt函数挑选出现次数最多的类别作为返回值。
最后代码遍历当前选择特征包含的所有属性值,在每个数据集划分上递归调用函数createTree(),得到的返回值将被插入到字典变量myTree中,因此函数终止执行时,字典中将会嵌套很多代表叶子节点信息的字典数据。在解释这个嵌套数据之前,我们先看一下循环的第一行subLabels=labels[:],这行代码复制了类标签,并将其存储在新列表变量subLabels中。之所以这样做,是因为在Python语言中函数参数是列表类型时,参数是按照引用方式传递的。为了保证每次调用函数createTree()时不改变原始列表的内容,使用新变量subLabels代替原始列表。
测试:
## 测试4:
myDat, labels = createDataSet()
myTree = createTree(myDat, labels)
print(myTree)
======================================
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
变量myTree包含了很多代表树结构信息的嵌套字典,从左边开始,第一个关键字no surfacing是第一个划分数据集的特征名称,该关键字的值也是另一个数据字典。第二个关键字是no surfacing特征划分的数据集,这些关键字的值是nosurfacing节点的子节点。这些值可能是类标签,也可能是另一个数据字典。如果值是类标签,则该子节点是叶子节点;如果值是另一个数据字典,则子节点是一个判断节点,这种格式结构不断重复就构成了整棵树。本节的例子中,这棵树包含了3个叶子节点以及2个判断节点。
最后
以上就是轻松飞机最近收集整理的关于【机器学习实战】决策树——构造决策树决策树一、信息增益二、划分数据集三、递归构建决策树的全部内容,更多相关【机器学习实战】决策树——构造决策树决策树一、信息增益二、划分数据集三、递归构建决策树内容请搜索靠谱客的其他文章。








发表评论 取消回复