0x00 前言
决策树算法的三个步骤:特征选择、决策树生成、决策树剪枝。其中特征选择要解决的核心问题就是:
每个节点在哪个维度上做划分?
某个维度在哪个值上做划分?
划分的依据是: 要让数据划分成两部分之后,系统整体的信息熵降低。
具体方法是: 对所有的划分可行性进行搜索。下一篇我们模拟在一个节点上进行搜索,找到一个节点上信息熵的最优划分。
那么问题来了: 我们如何找到各个特征/节点上的最优划分呢?
0x01 信息熵的最优划分
1.1 模拟贷款申请
现在我们以银行贷款申请业务为例,模拟四个特征,分别是:年龄、有工作、有房子、信贷情况。
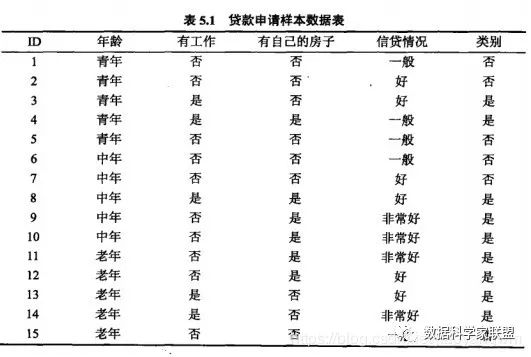
下面就通过代码实现,找到当前应该在哪个特征维度上的哪个值进行最优划分:
1.2 代码实现
import numpy as np
from collections import Counter
from math import log
# 每列:['年龄','有工作','有自己的房子','信贷情况','是否申请贷款']
dataSet=np.array([[0, 0, 0, 0, 0],
[0, 0, 0, 1, 0],
[0, 1, 0, 1, 1],
[0, 1, 1, 0, 1],
[0, 0, 0, 0, 0],
[1, 0, 0, 0, 0],
[1, 0, 0, 1, 0],
[1, 1, 1, 1, 1],
[1, 0, 1, 2, 1],
[1, 0, 1, 2, 1],
[2, 0, 1, 2, 1],
[2, 0, 1, 1, 1],
[2, 1, 0, 1, 1],
[2, 1, 0, 2, 1],
[2, 0, 0, 0, 0]])
featList = ['年龄','有工作','有自己的房子','信贷情况']
"""
函数说明:计算给定标签的经验熵(信息熵)
Parameters:
y:使用标签y计算信息熵,,此时传递y是多维数组
计算信息熵需要每种类别出现的概率p,因此传入包含分类信息的标签y
Returns:
entropy:经验熵
"""
def calEntropy(y):
# 计数器,统计y中所有类别出现的次数
# 扁平化,将嵌套的多维数组变成一维数组
counter = Counter(y.flatten())
entropy = 0
for num in counter.values():
p = num / len(y)
entropy += -p * log(p)
return entropy
"""
函数说明:根据传递进来的特征维度及值,将数据划分为2类
Parameters:
X,y,featVec,value:特征向量、标签、特征维度、值
Returns:
返回划分为两类的后的数据
"""
def split(X, y, featVec, value):
# 使用维度featVect上的value,将数据划分成左右两部分
# 得到的布尔向量,传入array中做索引,即可找出满足条件的相应数据(布尔屏蔽)
index_a = (X[:,featVec] <= value)
index_b = (X[:,featVec] > value)
return X[index_a], X[index_b], y[index_a], y[index_b]
"""
函数说明:寻找最优划分
Parameters:
X,y:特征向量、标签
Returns:
返回最优熵,以及在哪个维度、哪个值进行划分
"""
def try_split(X, y):
# 搞一个熵的初始值:正无穷
best_entropy = float('inf')
best_featVec = -1 # 特征向量
best_value = -1
# 遍历每一个特征维度(列)
for featVec in range(X.shape[1]):
# 然后需要找到每个特征维度上的划分点。
# 找出该维度上的每个两个样本点的中间值,作为候选划分点。
# 为了方便寻找候选划分点,可以对该维度上的数值进行排序,
# argsort函数返回的是数组值从小到大的索引值(不打乱原来的顺序)
sort_index = np.argsort(X[:,featVec])
for i in range(1, len(X)):
if X[sort_index[i-1], featVec] != X[sort_index[i], featVec]:
value = (X[sort_index[i-1], featVec] + X[sort_index[i], featVec]) / 2
X_l, X_r, y_l, y_r = split(X, y, featVec, value)
# 要求最优划分,需要看在此划分下得到的两个分类数据集的熵之和是否是最小的
entropy = calEntropy(y_l) + calEntropy(y_r)
if entropy < best_entropy:
best_entropy, best_featVec, best_value = entropy, featVec, value
return best_entropy, best_featVec, best_value
best_entropy, best_featVec, best_value = try_split(X, y)
print("最优熵:", best_featVec)
print("在哪个维度熵进行划分:", best_featVec)
print("在哪个值上进行划分:", best_value)
输出:最优熵:0.6365141682948128在哪个维度熵进行划分:2在哪个值上进行划分:0.5
也就是说,根据穷举各个字段上的最优熵,可以得知,在第3个特征(有自己的房子)上,以0.5为阈值进行分类,可以得到最小熵。
0x02 信息增益&信息增益率最优划分
2.1 信息增益最优划分实现
PS:下面的代码是都是干货,多读读注释,看懂了就理解透彻了
import numpy as np
from collections import Counter
from math import log
# 每列:['年龄','有工作','有自己的房子','信贷情况','是否申请贷款'],其中'是否申请贷款'是label
dataSet=np.array([[0, 0, 0, 0, 0],
[0, 0, 0, 1, 0],
[0, 1, 0, 1, 1],
[0, 1, 1, 0, 1],
[0, 0, 0, 0, 0],
[1, 0, 0, 0, 0],
[1, 0, 0, 1, 0],
[1, 1, 1, 1, 1],
[1, 0, 1, 2, 1],
[1, 0, 1, 2, 1],
[2, 0, 1, 2, 1],
[2, 0, 1, 1, 1],
[2, 1, 0, 1, 1],
[2, 1, 0, 2, 1],
[2, 0, 0, 0, 0]])
X = dataSet[:,:4]
y = dataSet[:,-1:]
strs = ['年龄','有工作','有自己的房子','信贷情况','是否申请贷款']
"""
函数说明:计算经验熵
Parameters:
dataSet:样本数据集D
Returns:
entory:经验熵
"""
def calEntropy(dataSet):
#返回数据集行数
numEntries=len(dataSet)
#保存每个标签(label)出现次数的字典:<label:出现次数>
labelCounts={}
#对每组特征向量进行统计
for featVec in dataSet:
#提取标签信息
currentLabel=featVec[-1]
#如果标签没有放入统计次数的字典,添加进去
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
#label计数
labelCounts[currentLabel]+=1
entory=0.0
#计算经验熵
for key in labelCounts:
#选择该标签的概率
prob=float(labelCounts[key])/numEntries
#利用公式计算
entory-=prob*log(prob,2)
return entory
"""
函数说明:得到当前特征条件下的小类的所有样本集合(即不包含当前特征的特征样本集)
Parameters:
dataSet:样本数据集D
curtFeatIndex:当前用来划分数据集的特征A的位置
categories:特征A所有可能分类的集合
Returns:
otherFeatSets:不包含当前特征的特征样本集
"""
def currentConditionSet(dataSet, curtFeatIndex, categroy):
otherFeatSets = []
# 对于数据集中的所有特征向量,抛去当前特征后拼接好的集合
for featVec in dataSet:
if featVec[curtFeatIndex] == categroy:
otherFeatSet = np.append(featVec[:curtFeatIndex],featVec[curtFeatIndex+1:])
otherFeatSets.append(otherFeatSet)
return otherFeatSets
"""
函数说明:在选择当前特征的条件下,计算熵,即条件熵
Parameters:
dataSet:样本数据集D
curtFeatIndex:当前用来划分数据集的特征A的位置
categories:特征A所有可能分类的集合
Returns:
conditionalEnt:返回条件熵
"""
def calConditionalEnt(dataSet, curtFeatIndex, categories):
conditionalEnt = 0
# 对于每一个分类,计算选择当前特征的条件下条件熵
# 比如在选择“年龄”这一特征下,共有“老中青”三个小分类
for categroy in categories:
# 得到当前特征条件下的小类的所有样本集合,即不包含当前特征的特征样本集
# 如得到在选择“青年”这个小类下一共有5个样本,且不包含“年龄”这一特征
cdtSetCategroy = currentConditionSet(dataSet, curtFeatIndex, categroy)
# 计算当前特征条件下的小分类,占总分类的比例
prob = len(cdtSetCategroy) / float(dataSet.shape[0])
# 累加得到条件熵
conditionalEnt += prob * calEntropy(cdtSetCategroy)
return conditionalEnt
"""
函数说明:计算信息增益
Parameters:
baseEntropy:划分样本集合D的熵是为H(D),即基本熵
dataSet:样本数据集D
curtFeatIndex:当前用来划分数据集的特征A的位置
Returns:
infoGain:信息增益值
"""
def calInfoGain(baseEntropy,dataSet,curtFeatIndex):
conditionalEnt = 0.0
# categories是所有特征向量中当前特征的对应值的set集合(去重复)
# 相当于该特征一共有几种分类,如“年龄”这一特征,分为“老中青”三类
categories = set(dataSet[:,curtFeatIndex])
# 计算划分后的数据子集(给定特征A的情况下,数据集D)的条件熵(经验条件熵)H(D|A)
conditionalEnt = calConditionalEnt(dataSet,curtFeatIndex,categories)
# 计算信息增益:g(D,A)=H(D)−H(D|A)
infoGain = baseEntropy - conditionalEnt
#打印每个特征的信息增益
print("第%d个特征的增益为%.3f" % (curtFeatIndex, infoGain))
return infoGain
"""
函数说明:寻找最优划分
Parameters:
dataSet:数据集
Returns:
打印最优划分结果
"""
def optimalPartition(dataSet):
bestInfoGain = -1 # 最佳信息增益初始值
bestFeatVec = -1 # 最佳划分的特征向量
# 划分前样本集合D的熵H(D),即基本熵
baseEntropy = calEntropy(dataSet)
# 遍历每一个特征维度(列),得到基于当前特征划分的信息增益
for curtFeatIndex in range(dataSet.shape[1]-1):
# 计算信息增益
infoGain = calInfoGain(baseEntropy, dataSet, curtFeatIndex)
# 选取最优信息增益的划分
if (infoGain > bestInfoGain):
#更新信息增益,找到最大的信息增益
bestInfoGain = infoGain
#记录信息增益最大的特征的索引值
bestFeatVec = curtFeatIndex
print("最佳的划分为第%d个特征,是”%s“,信息增益为%.3f" % (bestFeatVec,featList[bestFeatVec],bestInfoGain))
return bestFeatVec
optimalPartition(dataSet)
输出:
第0个特征的增益为0.083第1个特征的增益为0.324第2个特征的增益为0.420第3个特征的增益为0.363最佳的划分为第2个特征,是”有自己的房子“,信息增益为0.420
2.2 信息增益率最优划分实现
根据信息增益率的定义,对上面的代码进行改造,可以得到信息增益率的最优选择实现
"""
函数说明:计算惩罚参数,信息增益g(D,A)与训练数据集D关于特征A的值的熵HA(D)之比
Parameters:
dataSet:样本数据集D
curtFeatIndex:当前用来划分数据集的特征A的位置
categories:特征A所有可能分类的集合
Returns:
conditionalEnt:惩罚参数
"""
def calPenaltyPara(dataSet, curtFeatIndex, categories):
penaltyItem = 1
# 对于每一个分类,计算选择当前特征的条件下条件熵
# 比如在选择“年龄”这一特征下,共有“老中青”三个小分类
for categroy in categories:
# 得到当前特征条件下的小类的所有样本集合,即不包含当前特征的特征样本集
# 如得到在选择“青年”这个小类下一共有5个样本,且不包含“年龄”这一特征
cdtSetCategroy = currentConditionSet(dataSet, curtFeatIndex, categroy)
# 计算当前特征条件下的小分类,占总分类的比例
prob = len(cdtSetCategroy) / float(dataSet.shape[0])
# 累加得到惩罚项
penaltyItem += -prob * log(prob,2)
return penaltyItem
"""
函数说明:计算信息增益率(惩罚参数 * 信息增益)
Parameters:
baseEntropy:划分样本集合D的熵是为H(D),即基本熵
dataSet:样本数据集D
curtFeatIndex:当前用来划分数据集的特征A的位置
Returns:
infoGain:信息增益值
"""
def calInfoGainRate(baseEntropy,dataSet,curtFeatIndex):
infoGainRate = 0.0
# 计算信息增益
infoGain = calInfoGain(baseEntropy,dataSet,curtFeatIndex)
# 得到该特征的所有分类
categories = set(dataSet[:,curtFeatIndex])
# 计算惩罚项
penaltyItem = calPenaltyPara(dataSet, curtFeatIndex, categories)
# 计算信息增益率
infoGainRatio = infoGain / penaltyItem
#打印每个特征的信息增益率
print("第%d个特征的增益率为%.3f" % (curtFeatIndex, infoGainRatio))
return infoGainRatio
"""
函数说明:寻找最优划分
Parameters:
dataSet:数据集
Returns:
打印最优划分结果
"""
def optimalPartition(dataSet):
bestInfoGainRatio = 0.0 # 最佳信息增益率初始值
bestFeatVec = -1 # 最佳划分的特征向量
# 划分前样本集合D的熵H(D),即基本熵
baseEntropy = calEntropy(dataSet)
# 遍历每一个特征维度(列),得到基于当前特征划分的信息增益
for curtFeatIndex in range(dataSet.shape[1]-1):
# categories是所有特征向量中当前特征的对应值的set集合(去重复)
# 相当于该特征一共有几种分类,如“年龄”这一特征,分为“老中青”三类
#categories = set(dataSet[:,curtFeatIndex])
# 计算信息增益率
infoGainRatio = calInfoGainRate(baseEntropy, dataSet, curtFeatIndex)
# 选取最优信息增益率的划分
if (infoGainRatio > bestInfoGainRatio):
#更新信息增益率,找到最大的信息增益率
bestInfoGainRatio = infoGainRatio
#记录信息增益率最大的特征的索引值
bestFeatVec = curtFeatIndex
print("最佳的划分为第%d个特征,是”%s“,信息增益率为%.3f" % (bestFeatVec,strs[bestFeatVec],bestInfoGainRatio))
return
optimalPartition(dataSet)
输出:
第0个特征的增益率为0.032第1个特征的增益率为0.169第2个特征的增益率为0.213第3个特征的增益率为0.141最佳的划分为第2个特征,是”有自己的房子“,信息增益率为0.213
0x03 基尼系数最优划分
3.1 基尼系数最优划分实现
"""
函数说明:计算基尼系数
Parameters:
y:使用标签y计算信息熵,此时传递y是多维数组
Returns:
entropy:经验熵
"""
def calGini(y):
# 计数器,统计y中所有类别出现的次数
# 扁平化,将嵌套的多维数组变成一维数组
counter = Counter(y.flatten())
gini = 1
for num in counter.values():
p = num / len(y)
gini -= p ** 2
return gini
"""
函数说明:寻找最优划分
Parameters:
X,y:特征向量、标签
Returns:
返回最优熵,以及在哪个维度、哪个值进行划分
"""
def try_split(X, y):
# 搞一个基尼系数的初始值:正无穷
bestGini = float('inf')
bestFeatVec = -1 # 特征向量
bestValue = -1
# 遍历每一个特征维度(列)
for featVec in range(X.shape[1]):
# 然后需要找到每个特征维度上的划分点。
# 找出该维度上的每个两个样本点的中间值,作为候选划分点。
# 为了方便寻找候选划分点,可以对该维度上的数值进行排序,
# argsort函数返回的是数组值从小到大的索引值(不打乱原来的顺序)
sort_index = np.argsort(X[:,featVec])
for i in range(1, len(X)):
if X[sort_index[i-1], featVec] != X[sort_index[i], featVec]:
value = (X[sort_index[i-1], featVec] + X[sort_index[i], featVec]) / 2
X_l, X_r, y_l, y_r = split(X, y, featVec, value)
# 要求最优划分,需要看在此划分下得到的两个分类数据集的熵之和是否是最小的
gini = calGini(y_l) + calGini(y_r)
if gini < bestGini:
bestGini, bestFeatVec, bestValue = gini, featVec, value
return bestGini, bestFeatVec, bestValue
bestGini, bestFeatVec, bestValue = try_split(X, y)
print("最优基尼系数:", bestGini)
print("在哪个维度上进行划分:", bestFeatVec)
print("在哪个值上进行划分:", bestValue)
输出:
最优基尼系数:0.4444444444444445在哪个维度上进行划分:2在哪个值上进行划分:0.5
0xFF 总结
结合概念,好好看代码。代码研究明白,你就悟了!加油吧少年!
热门文章
直戳泪点!数据从业者权威嘲讽指南!
AI研发工程师成长指南
数据分析师做成了提数工程师,该如何破局?
算法工程师应该具备哪些工程能力
数据团队思考:如何优雅地启动一个数据项目!
数据团队思考:数据驱动业务,比技术更重要的是思维的转变

最后
以上就是炙热小蘑菇最近收集整理的关于决策树3: 特征选择之寻找最优划分的全部内容,更多相关决策树3:内容请搜索靠谱客的其他文章。








发表评论 取消回复