原文地址:http://blog.csdn.net/gumpeng/article/details/51397737
注:本篇文章也是多个博客的综合整理。
1、决策树基本问题
1.1 定义

我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款?
一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
决策过程:

决策树是一种描述对样本实例(男人)进行分类(见或不见)的树形结构。
决策树由结点和有向边组成。最上部是根节点,此时所有样本都在一起,经过该节点后样本被划分到各子节点中。每个子节点再用新的特征来进一步决策,直到最后的叶节点。叶节点上只包含单纯一类样本(见或不见),不需要在进行划分。
结点两种类型:内部结点和叶结点。
内部结点表示一个特征或属性,叶节点表示一个类。
1.2 熵
首先,我们该选择什么标准(属性、特征)作为我们的首要条件(根节点)对样本(男人)进行划分,决定见或不见呢?——特征选择
母亲希望女儿能最快速的有一个明确的态度,决定见或不见,这样好给男方一个明确的答复。
母亲需要获得尽可能多的信息,减少不确定性。
信息的如何度量?——熵
母亲得到信息越多,女儿的态度越明确,与男方见与不见的不确定性越低。因此,信息量与不确定性相对应。使用熵来表示不确定性的度量。
熵定义:如果一件事有k种可的结果,每种结果的概率为

则我们对此事件的结果进行观察后得到的信息量为:
![]()
熵越大,随机变量(见与不见)的不确定性越大。
1.3 条件熵(局部,现象发生的前提下的熵)
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。例如,知道男生年龄的前提条件下,根据女儿见与不见的不确定性。
![]()
熵与条件熵中概率由数据估计得到时,所对应的熵和条件熵称为经验熵和经验条件熵。若概率为0,令0log0=0
1.4 信息增益
信息增益表示得知特征X(年龄)的信息使得类Y(见与不见)的信息的不确定性减少程度。
特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下的经验条件熵H(D|A)之差
![]()
熵H(Y)与条件熵H(Y|X)之差称为互信息,即g(D,A)。
信息增益大表明信息增多,信息增多,则不确定性就越小,母亲应该选择使得信息增益增大的条件询问女儿。
1.5 信息增益准则的特征选择方法
对数据集D,计算每个特征的信息增益,并比较他们的大小,选择信息增益最大的特征。
1.6 信息增益率
信息增益率定义:特征A对训练数据集D的信息增益比定义为其信息增益与训练数据D关于特征A的值的熵HA(D)之比

其中,![]() ,n是特征A取值个数。如A代表年龄。
,n是特征A取值个数。如A代表年龄。
![]()
2 ID3
2.1 ID3 的定义
ID3算法的核心是在决策树各个子节点上应用信息增益准则选择特征,递归的构建决策树,具体方法是:从根节点开始,对节点计算所有可能的特征的信息增益,选择信息增益最大的特征作为节点的特征,由该特征的不同取值建立子节点;再对子节点递归调用以上方法,构建决策树。
直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一个决策树。
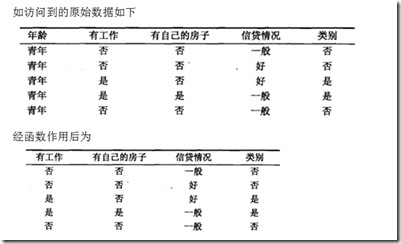
例子:贷款申请样本数据表

根据贷款申请样本数据表,我们有15条样本记录,则样本容量为15。最终分为是否贷款2个类,其中是有9条记录,否有6条记录。有年龄、有工作、有自己的房子和信贷情况4个不同特征。每个特征有不同的取值,如年龄有老、中、青3种取值。
由熵的定义:
![]()

然后计算各特征对数据集D的信息增益。分别以A1,A2,A3,A4表示年龄、有工作、有自己的房子和信贷情况4个特征。
根据年龄有取值青年、中年、老年。
青年贷款是2条记录,否3条记录,共5条记录
中年贷款是3条记录,否2条记录,共5条记录
老年贷款是4条记录,否1条记录,共5条记录
由条件熵公式

条件熵公式

年龄为已知条件的条件熵为

D1,D2,D3分别是年龄取值为青年、中年、老年的样本子集。
以年龄为条件的信息增益为

有工作的信息增益

有房子的信息增益

信贷情况的信息增益

由于特征A3(有自己房子)的信息增益值最大,所以选择特征A3作为根节点的特征。它将训练数据集划分为两个子集D1(A3取值为是)和D2(A3取值为否)。由于D1只有同一类样本点,可以明确要贷款给D1,所以它成为一个叶节点,节点类标记为“是”。
对于D2则需要从特征A1(年龄),A2(有工作)和A4(信贷情况)中选择新的特征。计算各个特征的信息增益:
![]()
![]()
![]()
选择信息增益最大的特征A2(有工作)作为节点特征。A2有2个取值,一个对应“是”(有工作)的子节点,包含3个样本,他们属于同一类,所以这是一个叶节点,类标记为“是”;另一个对应“否”(无工作)的子节点,包含6个样本,属于同一类,这也是一个叶节点,类标记为“否”。
换句话有15个贷款人,经过是否有房这一筛选条件,有房子的6个人能够贷款。剩余9个人需要进一步筛选,以是否有工作为筛选条件,有工作的3个人可以贷款,无工作的6个人不能够贷款。

该决策树只用了两个特征(有两个内部结点),以有自己的房子作为首要判决条件,然后以有工作作为判决条件是否可以贷款。
ID3算法只有树的生成,所以该算法生成的树容易产生过拟合,分得太细,考虑条件太多。
2.2 ID3 的缺点
1.用信息增益选择属性时偏向于选择分枝比较多的属性值,即取值 多的属性。
2.不能处理连续属性。
2.3 ID3 的代码实现
1)准备训练数据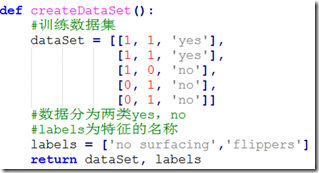

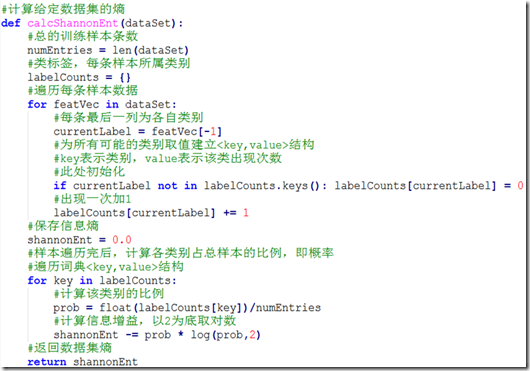




 下边计算
下边计算


创建树



![]()






构造决策树是一个很耗时的任务。为了节省计算时间,最好能够在每次执行分类时调用已经构造好的决策树。为了解决这个问题,需要使用Python模块pickle序列化对象,序列化对象可以在磁盘上保存对象,并在需要的时候读取出来。


运行测试:







3、C4.5
C4.5算法是数据挖掘十大算法之一,它是对ID3算法的改进,相对于ID3算法主要有以下几个改进
(1)用信息增益比来选择属性
(2)在决策树的构造过程中对树进行剪枝
(3)对非离散数据也能处理
(4)能够对不完整数据进行处理
客户ID 故障原因 故障类型 修障时长 满意度
001 1 5 10.2 1
002 1 5 12 0
003 1 5 14 1
004 2 5 16 0
005 2 5 18 1
006 2 6 20 0
007 3 6 22 1
008 3 6 23 0
009 3 6 24 1
010 3 6 25 0
故障原因和故障类型都为离散型变量,数字代表原因ID和类型ID。修障时长为连续型变量,单位为小时。满意度中1为不满意、0为满意。
下面沿着分裂属性的选择和树剪枝两条主线,去描述三种决策树算法构造满意度预警模型:
分裂属性的选择:即该选择故障原因、故障类型、修障时长三个变量中的哪个作为决策树的第一个分支。
ID3算法是采用信息增益来选择树叉,c4.5算法采用增益率,CART算法采用Gini指标。此外离散型变量和连续型变量在计算信息增益、增益率、Gini指标时会有些区别。详细描述如下:
1.ID3算法的信息增益:
信息增益的思想来源于信息论的香农定理,ID3算法选择具有最高信息增益的自变量作为当前的树叉(树的分支),以满意度预警模型为例,模型有三个自变量:故障原因、故障类型、修障时长。分别计算三个自变量的信息增益,选取其中最大的信息增益作为树叉。信息增益=原信息需求-要按某个自变量划分所需要的信息。
如以自变量故障原因举例,故障原因的信息增益=原信息需求(即仅仅基于满意度类别比例的信息需求,记为a)-按照故障原因划分所需要的信息需求(记为a1)。
其中原信息需求a的计算方式为:
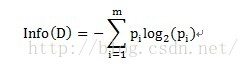
其中D为目标变量,此例中为满意度。m=2,即满意和不满意两种情况。Pi为满意度中属于分别属于满意和不满意的概率。此例中共计10条数据,满意5条,不满意5条。概率都为1/2。Info(满意度)即为仅仅基于满意和满意的类别比例进行划分所需要的信息需求,计算方式为:
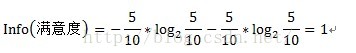
按照故障原因划分所需要的信息需求(记为a1)可以表示为:
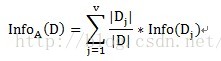
其中A表示目标变量D(即满意度)中按自变量A划分所需要的信息,即按故障类型进行划分所需要的信息。V表示在目标变量D(即满意度)中,按照自变量A(此处为故障原因)进行划分,即故障原因分别为1、2、3进行划分,将目标变量分别划分为3个子集,{D1、D2、D3},因此V=3。即故障原因为1的划分中,有2个不满意和1个满意。D1即指2个不满意和1个满意。故障原因为2的划分中,有1个不满意和2个满意。D2即指1个不满意和2个满意。故障原因为3的划分中,有2个不满意和2个满意。D3即指2个不满意和2个满意。具体公式如下:
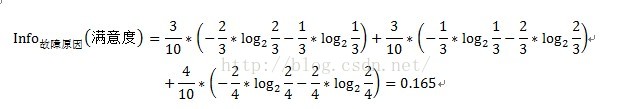
注:此处的计算结果即0.165不准确,没有真正去算,结果仅供参考。
因此变量故障原因的信息增益Gain(故障原因)=Info(满意度)- Info故障原因(满意度)=1-0.165=0.835
同样的道理,变量故障类型的信息增益计算方式如下:
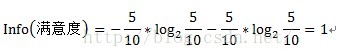
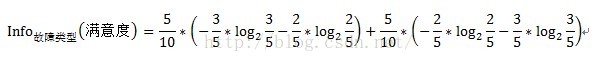
变量故障类型的信息增益Gain(故障类型)=1-0.205=0.795
故障原因和故障类型两个变量都是离散型变量,按上述方式即可求得信息增益,但修障时长为连续型变量,对于连续型变量该怎样计算信息增益呢?
(此处的方法来自于C4.5)
只需将连续型变量由小到大递增排序,取相邻两个值的中点作为分裂点,然后按照离散型变量计算信息增益的方法计算信息增益,取其中最大的信息增益作为最终的分裂点。如求修障时长的信息增益,首先将修障时长递增排序,即10.2、12、14、16、18、20、22、23、24、25,取相邻两个值的中点,如10.2和12,中点即为(10.2+12)/2=11.1,同理可得其他中点,分别为11.1、13、15、17、19、21、22.5、23.5、24.5。对每个中点都离散化成两个子集,如中点11.1,可以离散化为两个<=11.1和>11.1两个子集,然后按照离散型变量的信息增益计算方式计算其信息增益,如中点11.1的信息增益计算过程如下:
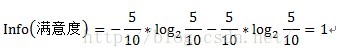
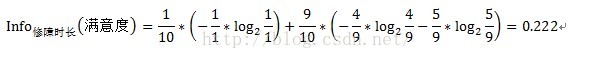
中点13的信息增益计算过程如下:
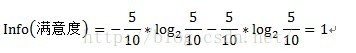
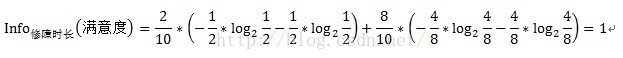
中点11.1的信息增益Gain(修障时长)=1-1=0
同理分别求得各个中点的信息增益,选取其中最大的信息增益作为分裂点,如取中点11.1。然后与故障原因和故障类型的信息增益相比较,取最大的信息增益作为第一个树叉的分支,此例中选取了故障原因作为第一个分叉。按照同样的方式继续构造树的分支。
总之,信息增益的直观解释为选取按某个自变量划分所需要的期望信息,该期望信息越小,划分的纯度越高。因为对于某个分类问题而言,Info(D)都是固定的,而信息增益Gain(A)=Info(D)-InfoA(D) 影响信息增益的关键因素为:-InfoA(D),即按自变量A进行划分,所需要的期望信息越小,整体的信息增益越大,越能将分类变量区分出来。
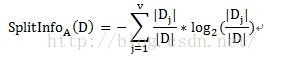
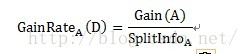
其中Gain(A)的计算方式与ID3算法中的信息增益计算方式相同。
以故障原因为例:
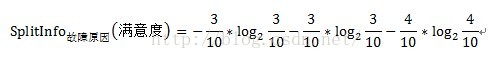
=1.201
Gain(故障原因)=0.835(前文已求得)
GainRate故障原因(满意度)=1.201/0.835=1.438
同理可以求得其他自变量的增益率。
选取最大的信息增益率作为分裂属性。
4、CART
不纯度的计算方式为:
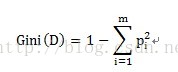
pi表示按某个变量划分中,目标变量不同类别的概率。
某个自变量的Gini指标的计算方式如下:
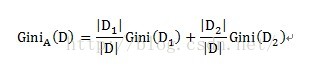
对应到满意度模型中,A为自变量,即故障原因、故障类型、修障时长。D代表满意度,D1和D2分别为按变量A的子集所划分出的两个不同元组,如按子集{1,2}划分,D1即为故障原因属于{1,2}的满意度评价,共有6条数据,D2即故障原因不属于{1,2}的满意度评价,共有3条数据。计算子集{1,2}的不纯度时,即Gini(D1),在故障原因属于{1,2}的样本数据中,分别有3条不满意和3条满意的数据,因此不纯度为1-(3/6)^2-(3/6)^2=0.5。
以故障原因为例,计算过程如下:
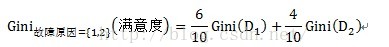
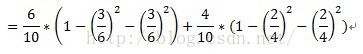
计算子集故障原因={1,3}的子集的Gini指标时,D1和D2分别为故障原因={1,3}的元组共计7条数据,故障原因不属于{1,3}的元组即故障原因为2的数据,共计3条数据。详细计算过程如下:
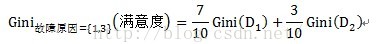
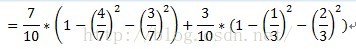
=0.52
5、树的剪枝
2)后剪枝:
其中c4.5使用悲观剪枝方法,CART则为代价复杂度剪枝算法(后剪枝)。
悲观剪枝法的基本思路是:设训练集生成的决策树是T,用T来分类训练集中的N的元组,设K为到达某个叶子节点的元组个数,其中分类错误地个数为J。由于树T是由训练集生成的,是适合训练集的,因此J/K不能可信地估计错误率。所以用(J+0.5)/K来表示。设S为T的子树,其叶节点个数为L(s),![]() 为到达此子树的叶节点的元组个数总和,
为到达此子树的叶节点的元组个数总和,![]() 为此子树中被错误分类的元组个数之和。在分类新的元组时,则其错误分类个数为
为此子树中被错误分类的元组个数之和。在分类新的元组时,则其错误分类个数为![]() ,其标准错误表示为:
,其标准错误表示为: 。当用此树分类训练集时,设E为分类错误个数,当下面的式子成立时,则删掉子树S,用叶节点代替,且S的子树不必再计算。
。当用此树分类训练集时,设E为分类错误个数,当下面的式子成立时,则删掉子树S,用叶节点代替,且S的子树不必再计算。
![]() 。
。
6、随机森林
在机器学习中,随机森林由许多的决策树组成,因为这些决策树的形成采用了随机的方法,因此也叫做随机决策树。随机森林中的树之间是没有关联的。当测试数据进入随机森林时,其实就是让每一颗决策树进行分类,最后取所有决策树中分类结果最多的那类为最终的结果。因此随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。随机森林可以既可以处理属性为离散值的量,如ID3算法,也可以处理属性为连续值的量,比如C4.5算法。另外,随机森林还可以用来进行无监督学习聚类和异常点检测。
6.1 理论描述
随机森林由决策树组成,决策树实际上是将空间用超平面进行划分的一种方法,每次分割的时候,都将当前的空间一分为二,如说下面的决策树,其属性的值都是连续的实数,如图1所示。将空间划分为成的样子如图2所示(注:所使用图片来自于网络)。
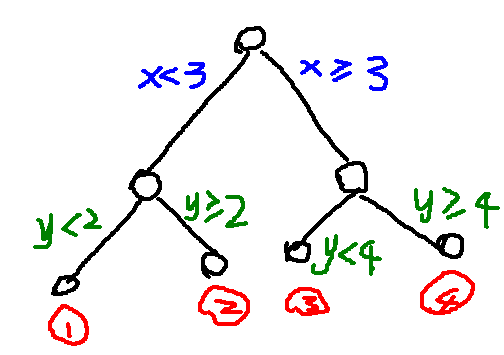
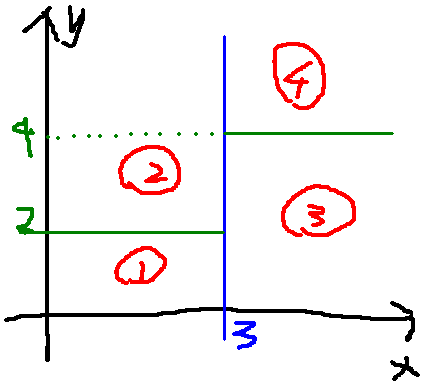
随机森林比较适合做多分类问题,训练和预测速度快;同时,对训练数据的容错能力,是一种有效地估计缺失数据的一种方法,当数据集中有大比例的数据缺失时仍然可以保持精度不变和能够有效地处理大的数据集;可以处理没有删减的成千上万的变量;能够在分类的过程中可以生成一个泛化误差的内部无偏估计;能够检测到特征之间的相互影响以及重要性程度;不过出现过度拟合;实现简单容易并行化。
6.2 RF生成过程
具体决策树的生成过程如下所示:

其中关于信息增益这里就不作具体的介绍,反正信息增益越大,就说明那个属性相对来说越重要。流程图中的identical values 可以理解为是分类值,离散值,就是它本身不具备数值的意义,比如说颜色分为红,绿,蓝等,是人为给它标定的一个离散值而已。流程图中的real values可以理解为连续的实数,也就是说属性本身是具有数值的,比如说物体的长度,这就是一个real value,在进行这种连续值属性构造决策数时,需要按照属性值的范围进行生成子节点。
6.3 RF构造过程
当可以生成好决策树后,就比较容易生成随机森林了。接下来是随机森林的构造过程,如下所示:
第一、假如有N个样本,则有放回的随机选择N个样本(每次随机选择一个样本,然后返回继续选择)。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
第二、当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
第三、决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
最后、按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
从上面的步骤可以看出,随机森林的随机性体现在每颗数的训练样本是随机的,树中每个节点的分类属性也是随机选择的。有了这2个随机的保证,随机森林就不会产生过拟合的现象了。
随机森林有2个参数需要人为控制,一个是森林中树的数量,一般建议取很大。另一个是m的大小,推荐m的值为M的均方根。
7、GBDT
一、 DT:回归树 Regression Decision Tree
提起决策树(DT, Decision Tree) 绝大部分人首先想到的就是C4.5分类决策树。但如果一开始就把GBDT中的树想成分类树,那就是一条歪路走到黑,一路各种坑,最终摔得都要咯血了还是一头雾水说的就是LZ自己啊有木有。咳嗯,所以说千万不要以为GBDT是很多棵分类树。决策树分为两大类,回归树和分类树。前者用于预测实数值,如明天的温度、用户的年龄、网页的相关程度;后者用于分类标签值,如晴天/阴天/雾/雨、用户性别、网页是否是垃圾页面。这里要强调的是,前者的结果加减是有意义的,如10岁+5岁-3岁=12岁,后者则无意义,如男+男+女=到底是男是女? GBDT的核心在于累加所有树的结果作为最终结果,就像前面对年龄的累加(-3是加负3),而分类树的结果显然是没办法累加的,所以GBDT中的树都是回归树,不是分类树,这点对理解GBDT相当重要(尽管GBDT调整后也可用于分类但不代表GBDT的树是分类树)。那么回归树是如何工作的呢?
下面我们以对人的性别判别/年龄预测为例来说明,每个instance都是一个我们已知性别/年龄的人,而feature则包括这个人上网的时长、上网的时段、网购所花的金额等。
作为对比,先说分类树,我们知道C4.5分类树在每次分枝时,是穷举每一个feature的每一个阈值,找到使得按照feature<=阈值,和feature>阈值分成的两个分枝的熵最大的feature和阈值(熵最大的概念可理解成尽可能每个分枝的男女比例都远离1:1),按照该标准分枝得到两个新节点,用同样方法继续分枝直到所有人都被分入性别唯一的叶子节点,或达到预设的终止条件,若最终叶子节点中的性别不唯一,则以多数人的性别作为该叶子节点的性别。
回归树总体流程也是类似,不过在每个节点(不一定是叶子节点)都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化均方差--即(每个人的年龄-预测年龄)^2 的总和 / N,或者说是每个人的预测误差平方和 除以 N。这很好理解,被预测出错的人数越多,错的越离谱,均方差就越大,通过最小化均方差能够找到最靠谱的分枝依据。分枝直到每个叶子节点上人的年龄都唯一(这太难了)或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。若还不明白可以Google "Regression Tree",或阅读本文的第一篇论文中Regression Tree部分。
二、 GB:梯度迭代 Gradient Boosting
好吧,我起了一个很大的标题,但事实上我并不想多讲Gradient Boosting的原理,因为不明白原理并无碍于理解GBDT中的Gradient Boosting。喜欢打破砂锅问到底的同学可以阅读这篇英文wikihttp://en.wikipedia.org/wiki/Gradient_boosted_trees#Gradient_tree_boosting
Boosting,迭代,即通过迭代多棵树来共同决策。这怎么实现呢?难道是每棵树独立训练一遍,比如A这个人,第一棵树认为是10岁,第二棵树认为是0岁,第三棵树认为是20岁,我们就取平均值10岁做最终结论?--当然不是!且不说这是投票方法并不是GBDT,只要训练集不变,独立训练三次的三棵树必定完全相同,这样做完全没有意义。之前说过,GBDT是把所有树的结论累加起来做最终结论的,所以可以想到每棵树的结论并不是年龄本身,而是年龄的一个累加量。GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。这就是Gradient Boosting在GBDT中的意义,简单吧。
三、 GBDT工作过程实例。
还是年龄预测,简单起见训练集只有4个人,A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。如果是用一棵传统的回归决策树来训练,会得到如下图1所示结果:
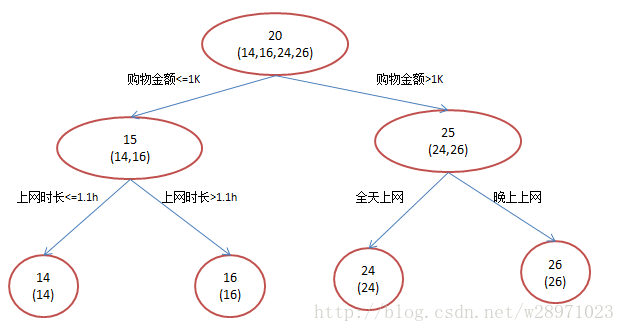
现在我们使用GBDT来做这件事,由于数据太少,我们限定叶子节点做多有两个,即每棵树都只有一个分枝,并且限定只学两棵树。我们会得到如下图2所示结果:
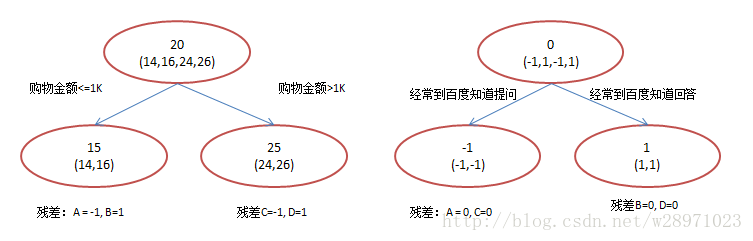
在第一棵树分枝和图1一样,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为两拨,每拨用平均年龄作为预测值。此时计算残差(残差的意思就是: A的预测值 + A的残差 = A的实际值),所以A的残差就是16-15=1(注意,A的预测值是指前面所有树累加的和,这里前面只有一棵树所以直接是15,如果还有树则需要都累加起来作为A的预测值)。进而得到A,B,C,D的残差分别为-1,1,-1,1。然后我们拿残差替代A,B,C,D的原值,到第二棵树去学习,如果我们的预测值和它们的残差相等,则只需把第二棵树的结论累加到第一棵树上就能得到真实年龄了。这里的数据显然是我可以做的,第二棵树只有两个值1和-1,直接分成两个节点。此时所有人的残差都是0,即每个人都得到了真实的预测值。
换句话说,现在A,B,C,D的预测值都和真实年龄一致了。Perfect!:
A: 14岁高一学生,购物较少,经常问学长问题;预测年龄A = 15 – 1 = 14
B: 16岁高三学生;购物较少,经常被学弟问问题;预测年龄B = 15 + 1 = 16
C: 24岁应届毕业生;购物较多,经常问师兄问题;预测年龄C = 25 – 1 = 24
D: 26岁工作两年员工;购物较多,经常被师弟问问题;预测年龄D = 25 + 1 = 26
那么哪里体现了Gradient呢?其实回到第一棵树结束时想一想,无论此时的cost function是什么,是均方差还是均差,只要它以误差作为衡量标准,残差向量(-1, 1, -1, 1)都是它的全局最优方向,这就是Gradient。
参考文献:
http://www.cnblogs.com/superhuake/archive/2012/07/25/2609124.html
http://blog.csdn.net/ljp812184246/article/details/47402639
http://www.cnblogs.com/chaoren399/p/4847462.html
http://blog.csdn.net/songzitea/article/details/10035757
最后
以上就是动听冰棍最近收集整理的关于决策树(ID3、C4.5、CART、随机森林) 1、决策树基本问题 2 ID33、C4.5 4、CART5、树的剪枝 6、随机森林7、GBDT 参考文献:的全部内容,更多相关决策树(ID3、C4.5、CART、随机森林)内容请搜索靠谱客的其他文章。








发表评论 取消回复