文章目录
- 一、决策树
- 1.简介
- 2.目的
- 3.相关概念
- 3.1信息熵
- 3.2信息增益
- 4.基本算法
- 4.1 离散数据算法
- 4.2 连续数据离散化算法(二分法)
- 二、数据集准备
- 三、代码实现
- 1.创建决策树
- 2.决策树绘画
- 3.完整代码
- 四、结果
- 五、代码获取
参考:https://blog.csdn.net/Atticus_zhang/article/details/121265168
一、决策树
1.简介
分类决策树模型是一种描述对实例进行分类的树形结构。决策树由结点和有向边组成。结点有两种类型:内部结点和叶节点。内部结点表示一个特征或属性,叶节点表示一个类。
2.目的
产生一棵泛化能力强的决策树。泛化能力强即为处理未见示例能力强。
决策树学习的关键在于如何选择最优划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的纯度越来越高。
3.相关概念
3.1信息熵
“信息熵”是度量样本集合纯度最常用的一种指标。
定义:
E
n
t
(
D
)
=
−
∑
k
=
1
∣
y
∣
p
k
l
o
g
2
p
k
Ent(D) = - sum_{k=1}^{|y|}p_k log_2p_k
Ent(D)=−k=1∑∣y∣pklog2pk
其中y为类别总数,
p
k
p_k
pk为第k类样本所占总样本的比例。
当Ent(D)的值越小时样本的纯度越高。
例如:只有两个类别时,第一个类别的概率为0,第二个类别的概率为1,那么该样本集的信息熵就为
−
1
l
o
g
2
1
−
0
l
o
g
2
0
=
0
-1log_21-0log_20=0
−1log21−0log20=0。Ent(D)的值小到0,样本也是100%为第二个类别。
3.2信息增益
在建立决策树当中,用不同的属性对原本的数据集进行划分会带来最终不同的分类结果。为了衡量使用某个属性带来的纯度提升,使用信息增益来作为创建决策树过程中的评判标准。
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。
定义:
G
a
i
n
(
D
,
a
)
=
E
n
t
(
D
)
−
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
E
n
t
(
D
v
)
Gain(D,a) = Ent(D) - sum_{v=1}^Vfrac{|D^v|}{|D|}Ent(D^v)
Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)
Ent(D)为原数据集的未经过任何属性划分的基本信息熵。当我们使用属性a将数据集划分为多个子集 D v D^v Dv,每个子集有自己的信息熵 E n t ( D v ) , Ent(D^v), Ent(Dv),划分后的总信息熵等于各个子集的加权信息熵之和,权重为上式中的 ∣ D v ∣ ∣ D ∣ frac{|D^v|}{|D|} ∣D∣∣Dv∣。
由于信息熵越小,纯度越高,我们希望划分后的总信息熵小一点。将原数据集的基本信息熵减去划分后的总信息熵即为此次划分的信息增益。
4.基本算法
4.1 离散数据算法
生成子节点方式:
在离散数据的决策树生成过程中,各个子集为在父集合中选取划分属性的各个取值进行划分,得到的子集。
例如:
现有一个西瓜数据集,当前父集合中共有4个样本。采用纹理属性进行划分,而纹理属性中包含3个离散值{清晰,稍糊,模糊}。4个样本对应的纹理属性分别是清晰、清晰、稍糊、模糊。那么我们就能从父集合中划分出3个子集,‘清晰’的子集中包含2个样本、‘稍糊’的子集中包含1个样本、‘模糊’的子集中也包含1个样本。
具体算法:
输入:
①训练集 D = { ( x 1 , y 1 ) , . . . , ( x m , y m ) } D = { (x_1,y_1),...,(x_m,y_m)} D={(x1,y1),...,(xm,ym)};
②属性集 A = { a 1 , . . . , a d } A = {a_1,...,a_d} A={a1,...,ad}.
过程:函数 T r e e G e n e r a t e ( D , A ) TreeGenerate(D,A) TreeGenerate(D,A)
1.生成node;
2.如果D中样本类别全为C,将node标记为类别为C的叶结点,返回;
3.如果当前属性集A为空,或当前所有样本在所有属性上取值都相同,将node标记为D中出现最多的类别,返回;
4.从A中选择最优划分属性 a ∗ a_* a∗;
5.对 a ∗ a_* a∗中的每一个值 a ∗ v a^v_* a∗v做以下操作:
5.1为node生成一个分支,令 D v D_v Dv表示 D D D在 a ∗ a_* a∗上取值为 a ∗ v a_*^v a∗v的样本子集;
5.2如果样本子集 D v D_v Dv为空,将分支节点标记为叶结点,类别为D中出现最多的类别;
否则以 T r e e G e n e r a t e ( D v , A − { a ∗ } ) TreeGenerate(D_v, A - {a_*}) TreeGenerate(Dv,A−{a∗})为分支节点;
4.2 连续数据离散化算法(二分法)
生成子节点方式:
由于连续属性的取值不是有限的,无法取各个属性的取值进行划分,与上述离散数据具体算法从第四步开始有一些不同。由于此处采用的是二分法,采用连续属性进行划分的父集合只能划分为两个子集。
选取一个划分点t,将父集划分为 D t + D_t^+ Dt+与 D t − D_t^- Dt−, D t + D_t^+ Dt+为父集中该连续属性大于划分点t的样本集合,与 D t − D_t^- Dt−则为父集中该连续属性小于划分点t的样本集合。
划分点t的选取采用以下方式:
1.将连续属性中的取值从小到大排序,记为从
a
1
,
a
2
,
.
.
.
,
a
n
a^1,a^2,...,a^n
a1,a2,...,an;
2.取候选值集合
T
a
=
{
(
a
i
+
a
i
+
1
)
/
2
∣
1
<
=
i
<
=
n
−
1
}
T_a = {(a^i+a^{i+1})/2 | 1<=i<=n-1}
Ta={(ai+ai+1)/2∣1<=i<=n−1};
3.每次选取
T
a
T_a
Ta当中的其中一个t对父集进行划分,得到
D
t
+
D_t^+
Dt+与
D
t
−
D_t^-
Dt−,并计算对应的信息增益;
4.选取信息增益最大的t为最终用于划分的t。
具体算法:
输入:
①训练集 D = { ( x 1 , y 1 ) , . . . , ( x m , y m ) } D = { (x_1,y_1),...,(x_m,y_m)} D={(x1,y1),...,(xm,ym)};
②属性集 A = { a 1 , . . . , a d } A = {a_1,...,a_d} A={a1,...,ad}.
过程:函数 T r e e G e n e r a t e ( D , A ) TreeGenerate(D,A) TreeGenerate(D,A)
1.生成node;
2.如果D中样本类别全为C,将node标记为类别为C的叶结点,返回;
3.如果当前属性集A为空,或当前所有样本在所有属性上取值都相同,将node标记为D中出现最多的类别,返回;
4.从A中选择最优划分属性 a ∗ a_* a∗与找到属性 a ∗ a_* a∗内的最优划分点t;
5.为node生成两个分支,左分支为 D t − D_t^- Dt−,令 D t − D_t^- Dt−表示 D D D在 a ∗ a_* a∗上取值小于t的样本子集、右分支为 D t + D_t^+ Dt+,令 D t + D_t^+ Dt+表示 D D D在 a ∗ a_* a∗上取值大于t的样本子集;
6.如果样本子集为空,将分支节点标记为叶结点,类别为D中出现最多的类别;
否则以 T r e e G e n e r a t e ( D t − , A − { a ∗ } ) TreeGenerate(D_t^-, A - {a_*}) TreeGenerate(Dt−,A−{a∗})为左分支节点,以 T r e e G e n e r a t e ( D t + , A − { a ∗ } ) TreeGenerate(D_t^+, A - {a_*}) TreeGenerate(Dt+,A−{a∗})为右分支节点;
二、数据集准备
数据集以集美大学为背景,数据集中的前四列代表从宿舍至该楼的时间,单位为分钟,最后一列为对应的交通方式,共有14个数据以csv文件方式存储。
| 禹州楼 | 建发楼 | 美玲楼 | 陆大楼 | 交通方式 |
|---|---|---|---|---|
| 4 | 3.5 | 3.5 | 5.5 | 电动车 |
| 8 | 7 | 6.8 | 11 | 步行 |
| 5 | 4 | 4 | 6 | 自行车 |
| 5.5 | 4.5 | 4.5 | 7 | 自行车 |
| 3 | 2.5 | 2.5 | 4 | 自行车 |
| 7 | 6 | 6 | 11 | 步行 |
| 5.2 | 4.7 | 4.6 | 6.2 | 自行车 |
| 4 | 3.8 | 3.8 | 5 | 电动车 |
| 8 | 7 | 7 | 12 | 步行 |
| 6 | 5.5 | 5.2 | 9 | 步行 |
| 5 | 4.3 | 4.2 | 6.3 | 电动车 |
| 7 | 6 | 6 | 12 | 步行 |
| 3.5 | 3.2 | 3.1 | 5 | 自行车 |
| 4.5 | 4.1 | 4.1 | 5.5 | 电动车 |
三、代码实现
1.创建决策树
由于本数据的特征都为连续属性,采取上述的二分法对数据集进行划分。
1.1 读取数据集
注意:由于本数据集中包含中文字符,读取csv文件时需使用gbk方式。否则报错UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xd3 in position 0: invalid continuation byte。
def readDataset():
'''
读取csv格式的数据集,返回dataset与labels的list形式
'''
#数据集内有中文字符,读取csv文件时需要使用gbk方式读取
df = pd.read_csv('time.csv',encoding="gbk")
#labels为该dataframe的列
labels = df.columns.tolist()
#dataset为该dataframe的值
dataset = df.values.tolist()
return dataset,labels
1.2 信息熵
def Entropy(dataset):
'''
计算信息熵并返回
'''
# 样本个数
numExamples = len(dataset)
# 类别计数器
classCount = {}
# 每个样本的最后一列为刚样本所属的类别,循环每个样本,以每个类别为key,对应的value
# 就是该类别拥有的样本数
for example in dataset:
# example[-1]就为样本的类别
# 如果类别对应的key不存在就创建对应的key,样本数(value)置0
if example[-1] not in classCount.keys():
classCount[example[-1]] = 0
# 将类别计数器当中的对应类别的样本数(value) + 1
classCount[example[-1]] += 1
# 熵的计算公式为: entropy = pi * log2(pi)
entropy = 0.0
for num in classCount.values():
# 样本出现概率 = 样本出现次数 / 样本总数
p = num / numExamples
entropy -= p * math.log(p,2)
return entropy
1.3 统计当前样本集中出现次数最多的类别
def majorityCnt(classList):
'''
统计每个类别的个数,返回出现次数多的类别
'''
# 类别计数器
classCount={}
for c in classList:
if c not in classCount.keys():
classCount[c] = 0
classCount[c] += 1
# reverse = True 从大到小排列,key x[1]指比较key、value中的value
sortedClassCount = sorted(classCount.items(),key=lambda x:x[1],reverse=True)
return sortedClassCount[0][0]
1.4 使用划分属性与划分点对数据集进行二分
def splitDataset(dataset, index, splitValue):
'''
划分数据集
index : 该特征的索引
splitValue : 每次取第i个样本与第i+1个样本的第index个特征的平均值splitValue
作为数据集划分点,返回子集1与子集2
'''
subDataset1 = []
subDataset2 = []
# 遍历每个样本,当样本中的第index列的值<splitValue时,归为子集1
# 当样本中的第index列的值>splitValue时,归为子集2
for example in dataset:
if example[index] <= splitValue:
# 取出分裂特征前的数据集
splitFeature = example[:index]
# 取出分裂特征后的数据集,并合并
splitFeature.extend(example[index+1:])
# 本行取得的去除example中index列的列表,加入总列表
subDataset1.append(splitFeature)
else:
# 取出分裂特征前的数据集
splitFeature = example[:index]
# 取出分裂特征后的数据集,并合并
splitFeature.extend(example[index+1:])
# 本行取得的去除example中index列的列表,加入总列表
subDataset2.append(splitFeature)
return subDataset1, subDataset2
1.5 寻找最优划分属性与最佳划分点
def chooseBestFeatureToSplit(dataset):
'''
返回最优特征索引,并返回最佳划分点值
'''
# 特征数,由于最后一列是类别不是特征,将最后一列去掉
numFeatures = len(dataset[0]) - 1
# 计算原始信息熵
baseEntropy = Entropy(dataset)
# 信息增益
bestInfoGain = 0
# 最优特征下标
bestIndex = -1
# 最佳划分点
bestSplitValue = 0
for column in range(0, numFeatures):
# 取出第i列特征值
featureList = [example[column] for example in dataset]
# 排序
featureList = sorted(featureList)
# 使用第column列特征值的第row行和第row+1行的平均值作为划分点,进行划分
# 得到左右两个子集
for row in range(0,len(featureList)-1):
newEntropy = 0
splitValue = (featureList[row] + featureList[row + 1]) / 2.0
subDataset1, subDataset2 = splitDataset(dataset,column,splitValue)
# 权重 = 子集样本数 / 全集样本数
weight1 = len(subDataset1) / float(len(dataset))
weight2 = len(subDataset2) / float(len(dataset))
# 按某个特征分类后的熵 = (子集的熵 * 子集占全集的比重) 的总和
newEntropy += weight1 * Entropy(subDataset1)
newEntropy += weight2 * Entropy(subDataset2)
# 信息增益 = 原始熵 - 按某个特征分类后的熵
infoGain = baseEntropy - newEntropy
# 更新信息增益与对应最佳特征的索引
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestIndex = column
bestSplitValue = splitValue
return bestIndex, bestSplitValue
1.6 创建决策树
def createTree(dataset, labels):
'''
递归建树
1.获取最佳特征索引bestIndex以及最佳划分点bestSplitValue
2.根据bestIndex和bestSplitValue将原数据集划分为左右两个子集subDataset1和subDataset2
3.对两个子集分别调用createTree递归生成子树
'''
# 获取数据集当中的所有类别
classList = [example[-1] for example in dataset]
# 若只有一个类,直接返回该类别
if classList.count(classList[0]) == len(classList):
return classList[0]
# 若最后只剩下类别
if len(dataset[0]) == 1:
return majorityCnt(classList)
# 找到当前情况下使信息增益最大的特征的索引,以及最佳的划分点值
bestIndex, bestSplitValue = chooseBestFeatureToSplit(dataset)
# 最优特征的名字
bestFeature = labels[bestIndex]
# 决策树
myTree={bestFeature:{}}
# 从labels中删除最优特征
del(labels[bestIndex])
#取出最优特征一列的值
featureList = [example[bestIndex] for example in dataset]
# 排序
featureList = sorted(featureList)
# 遍历最优特征中的每一个值,如果是划分点值=最佳划分点值,则进行划分
for row in range(0, len(featureList)-1):
splitValue = (featureList[row] + featureList[row + 1]) / 2.0
if splitValue == bestSplitValue:
subDataset1, subDataset2 = splitDataset(dataset,bestIndex,splitValue)
myTree[bestFeature]["<="+str(splitValue)] = createTree(subDataset1, labels)
myTree[bestFeature][">"+str(splitValue)] = createTree(subDataset2, labels)
return myTree
2.决策树绘画
2.1 节点
# 节点
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
2.2 获取叶结点的数目
# 获取叶节点的数目
def getNumLeafs(my_tree):
num_leafs = 0
first_str = list(my_tree.keys())[0]
second_dict = my_tree[first_str]
for key in second_dict.keys():
if type(second_dict[key]).__name__ == 'dict':
num_leafs += getNumLeafs(second_dict[key])
else:
num_leafs += 1
return num_leafs
2.3 获取树的深度
# 获取树的深度
def getTreeDepth(my_tree):
max_depth = 0
first_str = list(my_tree.keys())[0]
second_dict = my_tree[first_str]
for key in second_dict.keys():
if type(second_dict[key]).__name__ == 'dict':
this_depth = 1 + getTreeDepth(second_dict[key])
else:
this_depth = 1
if this_depth > max_depth:
max_depth = this_depth
return max_depth
2.4 绘制树中文本
# 绘制树中文本
def plotMidText(cntr_pt, parent_pt, txt_string):
x_mid = (parent_pt[0] - cntr_pt[0]) / 2.0 + cntr_pt[0]
y_mid = (parent_pt[1] - cntr_pt[1]) / 2.0 + cntr_pt[1]
createPlot.ax1.text(x_mid, y_mid, txt_string)
2.5 绘制树
# 绘制树
def plotTree(my_tree, parent_pt, node_txt):
num_leafs = getNumLeafs(my_tree)
depth = getTreeDepth(my_tree)
first_str = list(my_tree.keys())[0]
cntr_pt = (plotTree.x_off + (1.0 + float(num_leafs)) / 2.0 /plotTree.total_w, plotTree.y_off)
plotMidText(cntr_pt, parent_pt, node_txt)
plotNode(first_str, cntr_pt, parent_pt, decision_node)
second_dict = my_tree[first_str]
plotTree.y_off = plotTree.y_off - 1.0 / plotTree.total_d
for key in second_dict.keys():
if type(second_dict[key]).__name__ == 'dict':
plotTree(second_dict[key], cntr_pt, str(key))
else:
plotTree.x_off = plotTree.x_off + 1.0 / plotTree.total_w
plotNode(second_dict[key], (plotTree.x_off, plotTree.y_off), cntr_pt, leaf_node)
plotMidText((plotTree.x_off, plotTree.y_off), cntr_pt, str(key))
plotTree.y_off = plotTree.y_off + 1.0 / plotTree.total_d
def createPlot(in_tree):
# 新建一个窗口
fig = plt.figure(1, facecolor='white')
# 清除图形
fig.clf()
axprops = dict(xticks=[], yticks=[])
# 创建子图
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
# w为决策树叶子个数
plotTree.total_w = float(getNumLeafs(in_tree))
# d为决策树深度
plotTree.total_d = float(getTreeDepth(in_tree))
plotTree.x_off = -0.5 / plotTree.total_w
plotTree.y_off = 1.0
plotTree(in_tree, (0.5, 1.0), '')
# 显示
plt.show()
3.完整代码
import math
import pandas as pd
import matplotlib.pyplot as plt
# 设置中文显示字体
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
# 使用文本注释绘制树节点
decision_node = dict(boxstyle='sawtooth', fc='0.8')
leaf_node = dict(boxstyle='round4', fc='0.8')
arrow_args = dict(arrowstyle='<-')
# 节点
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
# 获取叶节点的数目
def getNumLeafs(my_tree):
num_leafs = 0
first_str = list(my_tree.keys())[0]
second_dict = my_tree[first_str]
for key in second_dict.keys():
if type(second_dict[key]).__name__ == 'dict':
num_leafs += getNumLeafs(second_dict[key])
else:
num_leafs += 1
return num_leafs
# 获取树的深度
def getTreeDepth(my_tree):
max_depth = 0
first_str = list(my_tree.keys())[0]
second_dict = my_tree[first_str]
for key in second_dict.keys():
if type(second_dict[key]).__name__ == 'dict':
this_depth = 1 + getTreeDepth(second_dict[key])
else:
this_depth = 1
if this_depth > max_depth:
max_depth = this_depth
return max_depth
# 绘制树中文本
def plotMidText(cntr_pt, parent_pt, txt_string):
x_mid = (parent_pt[0] - cntr_pt[0]) / 2.0 + cntr_pt[0]
y_mid = (parent_pt[1] - cntr_pt[1]) / 2.0 + cntr_pt[1]
createPlot.ax1.text(x_mid, y_mid, txt_string)
# 绘制树
def plotTree(my_tree, parent_pt, node_txt):
num_leafs = getNumLeafs(my_tree)
depth = getTreeDepth(my_tree)
first_str = list(my_tree.keys())[0]
cntr_pt = (plotTree.x_off + (1.0 + float(num_leafs)) / 2.0 /plotTree.total_w, plotTree.y_off)
plotMidText(cntr_pt, parent_pt, node_txt)
plotNode(first_str, cntr_pt, parent_pt, decision_node)
second_dict = my_tree[first_str]
plotTree.y_off = plotTree.y_off - 1.0 / plotTree.total_d
for key in second_dict.keys():
if type(second_dict[key]).__name__ == 'dict':
plotTree(second_dict[key], cntr_pt, str(key))
else:
plotTree.x_off = plotTree.x_off + 1.0 / plotTree.total_w
plotNode(second_dict[key], (plotTree.x_off, plotTree.y_off), cntr_pt, leaf_node)
plotMidText((plotTree.x_off, plotTree.y_off), cntr_pt, str(key))
plotTree.y_off = plotTree.y_off + 1.0 / plotTree.total_d
def createPlot(in_tree):
# 新建一个窗口
fig = plt.figure(1, facecolor='white')
# 清除图形
fig.clf()
axprops = dict(xticks=[], yticks=[])
# 创建子图
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
# w为决策树叶子个数
plotTree.total_w = float(getNumLeafs(in_tree))
# d为决策树深度
plotTree.total_d = float(getTreeDepth(in_tree))
plotTree.x_off = -0.5 / plotTree.total_w
plotTree.y_off = 1.0
plotTree(in_tree, (0.5, 1.0), '')
# 显示
plt.show()
def readDataset():
'''
读取csv格式的数据集,返回dataset与labels的list形式
'''
#数据集内有中文字符,读取csv文件时需要使用gbk方式读取
df = pd.read_csv('time.csv',encoding="gbk")
#labels为该dataframe的列
labels = df.columns.tolist()
#dataset为该dataframe的值
dataset = df.values.tolist()
return dataset,labels
def Entropy(dataset):
'''
计算信息熵并返回
'''
# 样本个数
numExamples = len(dataset)
# 类别计数器
classCount = {}
# 每个样本的最后一列为刚样本所属的类别,循环每个样本,以每个类别为key,对应的value
# 就是该类别拥有的样本数
for example in dataset:
# example[-1]就为样本的类别
# 如果类别对应的key不存在就创建对应的key,样本数(value)置0
if example[-1] not in classCount.keys():
classCount[example[-1]] = 0
# 将类别计数器当中的对应类别的样本数(value) + 1
classCount[example[-1]] += 1
# 熵的计算公式为: entropy = pi * log2(pi)
entropy = 0.0
for num in classCount.values():
# 样本出现概率 = 样本出现次数 / 样本总数
p = num / numExamples
entropy -= p * math.log(p,2)
return entropy
def majorityCnt(classList):
'''
统计每个类别的个数,返回出现次数多的类别
'''
# 类别计数器
classCount={}
for c in classList:
if c not in classCount.keys():
classCount[c] = 0
classCount[c] += 1
# reverse = True 从大到小排列,key x[1]指比较key、value中的value
sortedClassCount = sorted(classCount.items(),key=lambda x:x[1],reverse=True)
return sortedClassCount[0][0]
def splitDataset(dataset, index, splitValue):
'''
划分数据集
index : 该特征的索引
splitValue : 每次取第i个样本与第i+1个样本的第index个特征的平均值splitValue
作为数据集划分点,返回子集1与子集2
'''
subDataset1 = []
subDataset2 = []
# 遍历每个样本,当样本中的第index列的值<splitValue时,归为子集1
# 当样本中的第index列的值>splitValue时,归为子集2
for example in dataset:
if example[index] <= splitValue:
# 取出分裂特征前的数据集
splitFeature = example[:index]
# 取出分裂特征后的数据集,并合并
splitFeature.extend(example[index+1:])
# 本行取得的去除example中index列的列表,加入总列表
subDataset1.append(splitFeature)
else:
# 取出分裂特征前的数据集
splitFeature = example[:index]
# 取出分裂特征后的数据集,并合并
splitFeature.extend(example[index+1:])
# 本行取得的去除example中index列的列表,加入总列表
subDataset2.append(splitFeature)
return subDataset1, subDataset2
def chooseBestFeatureToSplit(dataset):
'''
返回最优特征索引,并返回最佳划分点值
'''
# 特征数,由于最后一列是类别不是特征,将最后一列去掉
numFeatures = len(dataset[0]) - 1
# 计算原始信息熵
baseEntropy = Entropy(dataset)
# 信息增益
bestInfoGain = 0
# 最优特征下标
bestIndex = -1
# 最佳划分点
bestSplitValue = 0
for column in range(0, numFeatures):
# 取出第i列特征值
featureList = [example[column] for example in dataset]
# 排序
featureList = sorted(featureList)
# 使用第column列特征值的第row行和第row+1行的平均值作为划分点,进行划分
# 得到左右两个子集
for row in range(0,len(featureList)-1):
newEntropy = 0
splitValue = (featureList[row] + featureList[row + 1]) / 2.0
subDataset1, subDataset2 = splitDataset(dataset,column,splitValue)
# 权重 = 子集样本数 / 全集样本数
weight1 = len(subDataset1) / float(len(dataset))
weight2 = len(subDataset2) / float(len(dataset))
# 按某个特征分类后的熵 = (子集的熵 * 子集占全集的比重) 的总和
newEntropy += weight1 * Entropy(subDataset1)
newEntropy += weight2 * Entropy(subDataset2)
# 信息增益 = 原始熵 - 按某个特征分类后的熵
infoGain = baseEntropy - newEntropy
# 更新信息增益与对应最佳特征的索引
if infoGain > bestInfoGain:
bestInfoGain = infoGain
bestIndex = column
bestSplitValue = splitValue
return bestIndex, bestSplitValue
def createTree(dataset, labels):
'''
递归建树
1.获取最佳特征索引bestIndex以及最佳划分点bestSplitValue
2.根据bestIndex和bestSplitValue将原数据集划分为左右两个子集subDataset1和subDataset2
3.对两个子集分别调用createTree递归生成子树
'''
# 获取数据集当中的所有类别
classList = [example[-1] for example in dataset]
# 若只有一个类,直接返回该类别
if classList.count(classList[0]) == len(classList):
return classList[0]
# 若最后只剩下类别
if len(dataset[0]) == 1:
return majorityCnt(classList)
# 找到当前情况下使信息增益最大的特征的索引,以及最佳的划分点值
bestIndex, bestSplitValue = chooseBestFeatureToSplit(dataset)
# 最优特征的名字
bestFeature = labels[bestIndex]
# 决策树
myTree={bestFeature:{}}
# 从labels中删除最优特征
del(labels[bestIndex])
#取出最优特征一列的值
featureList = [example[bestIndex] for example in dataset]
# 排序
featureList = sorted(featureList)
# 遍历最优特征中的每一个值,如果是划分点值=最佳划分点值,则进行划分
for row in range(0, len(featureList)-1):
splitValue = (featureList[row] + featureList[row + 1]) / 2.0
if splitValue == bestSplitValue:
subDataset1, subDataset2 = splitDataset(dataset,bestIndex,splitValue)
myTree[bestFeature]["<="+str(splitValue)] = createTree(subDataset1, labels)
myTree[bestFeature][">"+str(splitValue)] = createTree(subDataset2, labels)
return myTree
if __name__=='__main__':
dataset, labels = readDataset()
myTree = createTree(dataset, labels)
createPlot(myTree)
四、结果
问题:图中中文无法显示
解决办法:
在代码中加入以下两行:
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
最终结果展示:
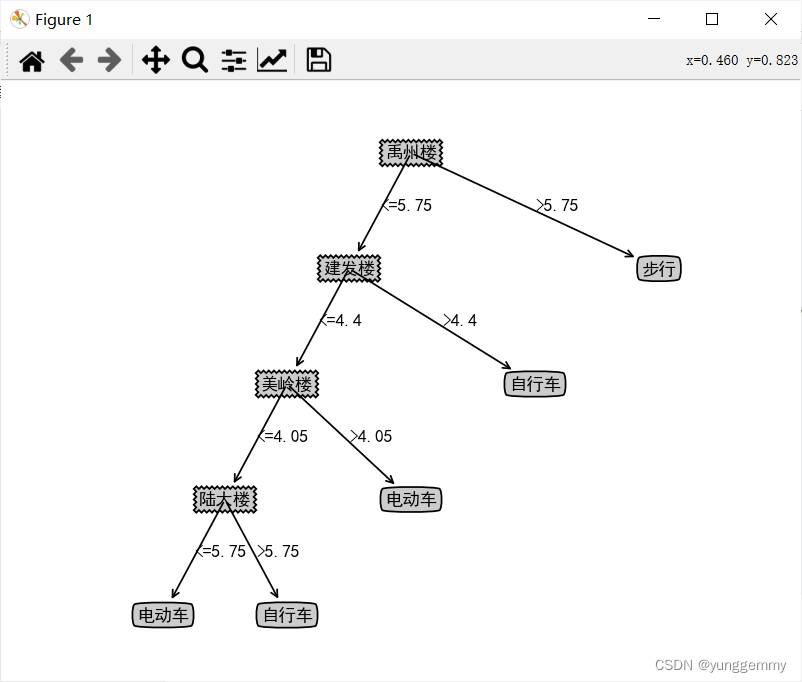
结果分析:
在本数据集当中,第一次进行数据集划分的最优属性是到禹州楼的时间,最佳划分点为5.75。
不足:如果能增加一些验证集用于验证该决策树的泛化性能会更好。
五、代码获取
链接:https://pan.baidu.com/s/14hkpAz3NygK7vEM2Mm25tQ?pwd=es40
提取码:es40
最后
以上就是欣喜歌曲最近收集整理的关于机器学习(二) 使用决策树进行分类一、决策树二、数据集准备三、代码实现四、结果五、代码获取的全部内容,更多相关机器学习(二)内容请搜索靠谱客的其他文章。








发表评论 取消回复