在忙忙碌碌许久之后,终于有时间写 "CUDA随笔" 系列的第二集了!
这次给大家带来了一个图像处理的应用例子:计算图片的直方图. 虽然使用CUDA可以很轻松地在性能上超越CPU,如能恰当地使用CUDA优化小技巧,那运算效率便可更上一层楼。为了记录我优化这段代码的历程,这篇短文会介绍三个版本的直方图计算实现,每一个版本均比前一个版本有些许提高,望能给大家带去一些CUDA优化的思路。
所有代码均可在我的github repo上找到:
https://github.com/YifanJiangPolyU/cuda_playground/tree/master/cuda_histgithub.com图像直方图
图像直方图是统计图片像素值分布的直方图。这一直方图在图像处理中有许多重要应用,比如直方图均衡化提升对比度(histogram equalization),边缘检测,确定二值化阈值等。维基百科给出了很好的介绍:
https://zh.wikipedia.org/wiki/%E5%BD%B1%E5%83%8F%E7%9B%B4%E6%96%B9%E5%9C%96zh.wikipedia.org基本思路
GPU做图像处理的一个基本套路是“分而治之”:先将图片切分称许多小块,每一个小块会被分配到CUDA的一个block,由block计算这一小块的直方图(sub histogram)。运算结束后,再将所有的sub histogram相加,得到整张图片的直方图。
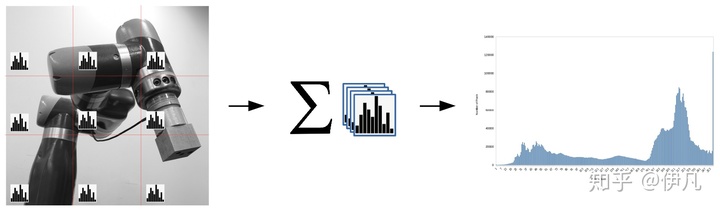
关于实验
实验平台搭载NVidia Quadro M2200,4G显存。
V0 最直接的实现
第一个版本最简单直接地实现了直方图计算:用一维blocks在x方向覆盖整张图片,在thread中以循环遍历y方向。刀法如下图所示:

每一个block的dimension均为 512x1x1。至于为什么是512:一般block里thread的数量最好为32的整数倍(由于N卡CUDA核定义一个warp为32thread),而对于大部分应用,128~1024都能有不错的效果。至于具体用哪个,就需要实验测试了。
第一个重要函数 subhist 计算每个图片小块的 sub histogram。第二个函数 sumSubHistograms 将所有小块的 sub histogram相加,得到全局直方图。又有subhist耗时最多且较为复杂,在这里只优化 subhist 函数,对 sumSubHistograms 则不多赘述。
__global__ void subhist(
uint8_t *image, // input image (8bit gray scale)
size_t w, // input image width
size_t h, // input image height
size_t memPitch, // input memory pitch (see cudaMallocPitch)
uint32_t *subHistogram, // stores sub-histograms
size_t nbins, // number of possible pixel values (256 for 8-bit)
size_t nsubhist, // number of sub-histograms
size_t subHistogramPitch) // sub-histogram memory pitch (see cudaMallocPitch)
{
uint32_t idx = blockIdx.x * blockDim.x + threadIdx.x;
uint32_t subHistId = blockIdx.x;
if(idx<w)
{
for(int i=0; i<h; i++)
{
uint8_t pv = image[i*memPitch + idx];
atomicAdd(&subHistogram[subHistId*subHistogramPitch + pv], 1);
}
}
}
__global__ void sumSubHistograms(
uint32_t *subHistogram,
size_t nbins,
size_t nsubhist,
size_t subHistogramPitch,
uint32_t *histogram)
{
uint32_t sid = blockIdx.x * blockDim.x + threadIdx.x;
uint32_t step = blockDim.x * gridDim.x;
for(int i=sid; i<nbins; i+=step)
{
uint32_t sum = 0;
for(int j=0; j<nsubhist; j++)
{
sum += subHistogram[j*subHistogramPitch + i];
}
histogram[i] = sum;
}
}
运行表现如下:

V1 Shared Memory
注意到在V1中,我们对 subHistogram 这个存在于device memory中的数组进行了大量随机位置的 atomicAdd 操作。由于随机读写device memory会产生很大的延迟,我们可以考虑先将 sub-histogram 缓存在 shared memory 之中,利用shared memory的低延时来提升读写性能。当 sub-histogram 的计算结束之后,再将结果由shared memory写入device memory (此时写入为顺序写入,相邻thread写入device memory的相邻地址,效率很高)。
__global__ void subhist(
uint8_t *image,
size_t w,
size_t h,
size_t memPitch,
uint32_t *subHistogram,
size_t nbins,
size_t nsubhist,
size_t subHistogramPitch)
{
// shared memory (smem) 被同一个block中的所有thread共享。
// 每个block的smem大小在kernel launch 的时候确定。
// kernel<<<GridDim, BlockDim, smem_size>>>(...)
extern __shared__ uint32_t localHist[];
uint32_t idx = blockIdx.x * blockDim.x + threadIdx.x;
uint32_t sid = threadIdx.x;
for(int i=sid; i<nbins; i+=blockDim.x)
{
// 先清空smem
localHist[i] = 0;
}
__syncthreads();
if(idx<w)
{
for(int i=0; i<h; i++)
{
// 计算图片小块的直方图(sub-histogram),缓存在smem
uint8_t pv = image[i*memPitch + idx];
atomicAdd(&localHist[pv], 1);
}
}
__syncthreads();
uint32_t subHistId = blockIdx.x;
for(int i=sid; i<nbins; i+=blockDim.x)
{
// 将sub-histogram写入device memory
subHistogram[subHistId*subHistogramPitch + i] = localHist[i];
}
}
运行表现如下:

V2 优化Block和Grid的尺寸
合理选取Block和Grid的尺寸,可以很有效地加速CUDA kernel。除了在V0中提到的将thread/block 设为 32 的整数倍,我们还可以通过平衡每个thread的工作量和block与thread的总数来提升效能。这一提升在CUDA术语里称为 Occupancy (占用率),即每个Stream Multiprocessor (SM)上实际运行的thread数量与理论SM最高可运行thread数量的比值。高占用率意味着更高的硬件使用效率,但不一定会带来更高的throughput。具体怎么平衡,还得用实验检验真理。
SM是N卡上实际负责运算的硬件单元。根于规格不同,每款卡的SM数量会有所差异,而不同compute capabiilty的卡, SM的规格配置也有所差异,详见这个链接:
CUDA Toolkit Documentationdocs.nvidia.com
每个SM均有自己的寄存器(register)和共享内存(shared memory),且支持的最大block数量,最大warp数量和最大thread数量均是固定的。实际占用率由launch configuration和kernel所需的资源共同决定。例如,若实际launch的block数量小于SM支持的最大block数量,则SM没有被喂饱,占用率永远到不了100%。如果launch的block或thread太多了,则一个SM装不下两个又装不满,也会导致占用率不高。由此可见,调整launch configuration 对于提升占用率十分重要。
鉴于我的kernel瓶颈并不在shared memory或register,我便从launch configuration下手。首先定下block size (512或256),然后计算我的整块GPU能够放下的thread数量,最后构建一个grid,其thread总数刚好等于最大thread数。完成之后检查下每个SM的block数量和warp数量有无超标,再适量调整block size。计算过程如下:
// 读取GPU的参数
// 主要关心SM总数,和每个SM的最高thread数
int device;
cudaDeviceProp properties = {};
CUDA_CHECK(cudaGetDevice(&device));
CUDA_CHECK(cudaGetDeviceProperties(&properties, device));
size_t bsx = 512; // block size (1D block)
size_t gsx = 1;
// 令grid中thread总数等于GPU最大支持thread数
size_t gsy = properties.multiProcessorCount *
properties.maxThreadsPerMultiProcessor /
bsx;
dim3 subHistGridDim(gsx, gsy, 1);
dim3 subHistBlockDim(bsx, 1, 1);
由于这样算出的Grid可能不足以覆盖整张图片,我们在X和Y放下移动这个Grid来计算图片的不同位置。具体刀法如下:
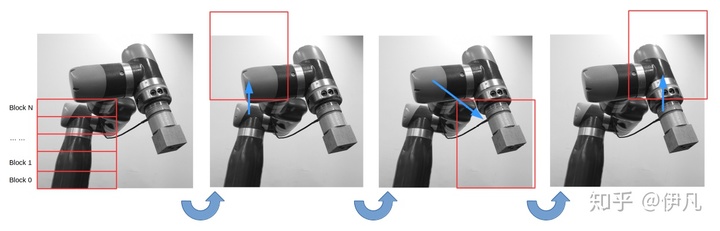
代码如下:
const size_t kYFactor = 8;
__global__ void subhist(
uint8_t *image,
size_t w,
size_t h,
size_t memPitch,
uint32_t *subHistogram,
size_t nbins,
size_t nsubhist,
size_t subHistogramPitch)
{
extern __shared__ uint32_t localHist[];
uint32_t idx = blockIdx.x * blockDim.x + threadIdx.x;
uint32_t idy = blockIdx.y * blockDim.y + threadIdx.y;
uint32_t xstride = gridDim.x*blockDim.x;
uint32_t ystride = gridDim.y*blockDim.y*kYFactor;
uint32_t sid = threadIdx.x;
for(int i=sid; i<nbins; i+=blockDim.x)
{
localHist[i] = 0;
}
__syncthreads();
// 在x方向移动grid
for(int j=idx; j<w; j+=xstride)
{
// 在y方向移动grid
for(int i=idy*kYFactor; i<h; i+=ystride)
{
// 在y方向上,每个thread处理8个像素(kYFactor=8)
for(int k=0; k<min(kYFactor, h-i); k++)
{
uint8_t pv = image[(i+k)*memPitch + j];
atomicAdd(&localHist[pv], 1);
}
}
}
__syncthreads();
uint32_t subHistId = idy * gridDim.x + blockIdx.x;
for(int i=sid; i<nbins; i+=blockDim.x)
{
subHistogram[subHistId*subHistogramPitch + i] = localHist[i];
}
}
运行表现为:

优化总结
- 当需要对memory进行反复或随机读写时,考虑用shared memory减少内存延时
- 最佳 Launch configuration 需要反复试验才能找到
程序优化永无止境,山外有山人外有人。本文中讨论的实现,可能离最优尚有距离。这也是我不断学习,不断提高的源动力。希望能给大家带来点灵感,如有高人也望多多指点。
参考资料
CUDA Programming Guide: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
CUDA Runtime API: https://docs.nvidia.com/cuda/cuda-runtime-api/index.html
CUDA Achieved Occupancy: https://docs.nvidia.com/gameworks/content/developertools/desktop/analysis/report/cudaexperiments/kernellevel/achievedoccupancy.htm
最后
以上就是沉静云朵最近收集整理的关于cuda图像处理_CUDA随笔之图像直方图(优化历程)的全部内容,更多相关cuda图像处理_CUDA随笔之图像直方图(优化历程)内容请搜索靠谱客的其他文章。








发表评论 取消回复