Matlab 并行计算学习
1. 简介
高性能计算(High Performance Computing,HPC)是计算机科学的一个分支,研究并行算法和开发相关软件,致力于开发高性能计算机。可见并行计算是高性能计算的不可或缺的重要组成部分。
1.1 并行计算
并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。它的基本思想是用多个处理器来协同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算。并行计算系统既可以是专门设计的、含有多个处理器的超级计算机,也可以是以某种方式互连的若干台的独立计算机构成的集群。通过并行计算集群完成数据的处理,再将处理的结果返回给用户[1]。
1.2 并行计算平台
平台是并行计算的载体,它决定着你可以用或只能用什么样的技术来实现并行计算。
多核和集群技术的发展,使得并行程序的设计成为提高数值计算效率的主流技术之一。常用的小型计算平台大致分为:由多核和多处理器构建的单计算机平台;由多个计算机组成的集群(Cluster)。前者通过共享内存进行数据交互,后者通过网络进行数据通信。
计算正在从 CPU(中央处理)向 CPU 与 GPU(协同处理)的方向发展。
GPU最早主要应用在图形计算机领域,近年来,它在通用计算机领域得到了迅猛的发展,使用GPU做并行计算已经变得越来越重要和高效。
常用的并行计算技术包括多线程技术、基于共享内存的OpenMP技术,基于集群的MPI技术等。但它们都需要用户处理大量与并行计算算法无关的技术细节,且不提供高效的算法库,与数值计算的关联较为松散。
1.3 Matlab与并行计算
Matlab即是一款数值计算软件,又是一门语言,它已经成为数值计算领域的主流工具。Matlab提供了大量高效的数值计算模块和丰富的数据显示模式,便于用户进行快速算法的研究和科学建模仿真。自Matlab 2009 之后,Matlab推出了并行计算工具箱(Parallel ComputingToolbox,PCT)和并行计算服务(Distributed ComputingServer,DCS),通过PCT和DCS用户可以实现基于多核平台、多处理器平台和集群平台的多种并行计算任务。利用PCT和DCS,用户无需关心多核、多处理器以及集群之间的底层数据通信,而是将主要精力集中于并行算法的设计。此外,PCT还增加了对GPU(Graphics ProcessingUnit)的支持。
2. Matlab并行计算初探
Matlab 并行计算工具箱,使用多核处理器,GPU和计算机集群,解决计算和数据密集型问题。高层次的结构并行for循环,特殊阵列类型和并行数值算法,让你在没有而CUDA或MPI编程基础的条件下并行MATLAB应用程序。您可以使用带有Simulink的工具箱并行运行一个模型的多个仿真。
该工具箱,通过在本地workers(MATLAB计算引擎)上执行应用程序,来使用多核台式机的全部处理能力。不用改变代码,就可以在计算机集群或网格计算服务(使用MATLAB分布式计算服务器™)上运行相同的应用程序。可以交互地或批处理地运行并行应用程序。
包含以下特性:
- 并行for循环 (parfor),可以在多个处理器上运行任务并行算法。
- 支持CUDA的NVIDIA GPU。
- 通过本地workers,充分利用台式机的多核处理器。
- 计算机集群和网格计算支持(通过MATLAB分布式计算服务)。
- 以交互方式和批量方式执行并行应用程序。
- 分布式阵列和SPMD(single-program-multiple-data),用于大型数据集的处理和数据并行算法。
本文仅介绍循环的并行,批处理和GPU并行计算。
2.1 并行池
2.1.1 开启和配置并行池
在使用parfor和spmd之前,首先要配置和开启并行计算池。parpool函数[1]提供并行池的配置和开启功能,其用法如下表 2‑1:
表 2‑1 parpool函数用法

此外,还可以给上述命令指定输出参数,如输入:p = parpool,输出如下图:
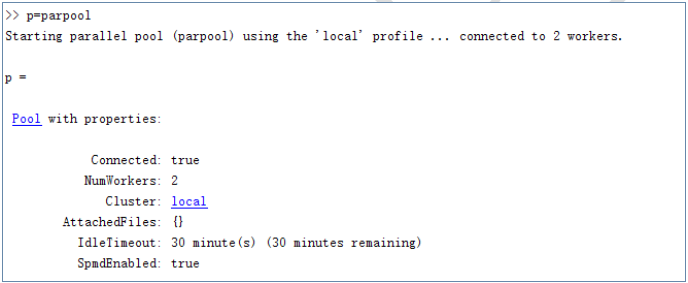
图2‑1 输入命令p=parpool时的运行结果
输出参数p为并行池对象,一个池对象有7中属性,上图显示了6种属性。其中,“NumWorkers” 代表worker的个数,也就是说开启了两个并行池;“IdleTimeout”指定了池定时关闭的时长,单位为分钟,图中为30分钟;“SpmdEnabled”指定池是否可以运行SPMD代码,其它属性相见Matlab 并行工具箱手册[2]。
此外,可以通过p.Property 访问和设置属性,如p.IdleTimeout = 10; 可以设置定时关闭池的时长为10分钟。
1.1.1. 获取当前池(gcp)
如果在启动池时没有设置输出参数p,可以使用gcp函数获取当前池的对象,gcp的用法如下表2-2:
表 2‑2 gcp用法
| 语法和参数 | 功能 |
| p = gcp | 获取当前池对象,如果未开启,则使用默认配置文件创建池。 |
| p = gcp('nocreate') | 获取当前池对象,如果未开启,返回空。 |
1.1.2. 关闭池(delete)
Matlab中,使用delete函数关闭或删除池,用法:delete(poolobj),其中poolobj为要关闭的池对象。
1.2. 循环并行parfor
1.2.1. Matlab client和Matlab worker
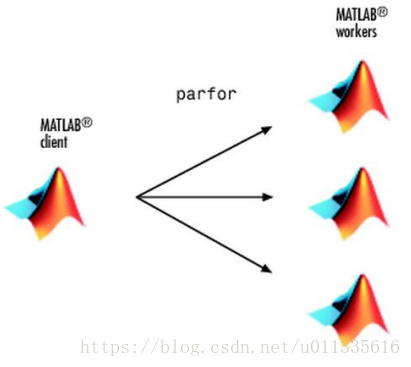
| 图 2‑2 Matlab client 分配parfor并行任务到多个Matlab |
Matlab并行执行parfor循环时,采用client和worker模式。其中client指编写和启动并行代码的Matlab段,worker指并行运行代码的Matlab端。用户可以将Matlab软件理解为一个进程,在同一计算机或网络上的多个计算机上可以运行多个Matlab进程,每个Matlab进程之间通过某种方式进行数据传输,用户首先在client端编写代码,然后再client端运行编写的代码,在运行代码的过程中,如果某个程序需要并行执行,Matlabclient端根据并行代码的关键字及类型将并行代码分配到本机或网络上的其它Matlab进程执行,那些最终执行并行代码的Matlab进程即为worker[3]。右图显示了,Matlab client 对parfor关键字的处理,它将任务分配到多个Matlab workers 上并行执行程序。假设m为Matlab worker的数量,循环次数为n,若n/m为整数的话,则循环将被均匀划分到Matlab worker;否则,循环被非均匀划分,有些Matlab worker的负载会大些。
1.2.2. 并行程序中的循环迭代parfor
应用parfor的一个基本前提是循环可以被等效分解,即分解后的循环的执行顺序不会影响最终结果。parfor的用法与for类似,其语法如下表 2‑3:
表2‑3 parfor的用法
| 语法和参数 | 功能 |
| parfor loopvar = initval:endval,statements,end | 在并行池中执行循环。其中initval和endval必须为正整数,或者是一个包含连续递增的整数行矢量。parfor i = range; <loop body>; end ,这样单行书写也是可以的,其中的“;”可以是“,”。 |
| parfor (loopvar = initval:endval, M), statements, end | 使用M指定执行循环体的Matlab worker的最大数量,M为非负整数,如果M=0,则在client上串行执行。 |
并行计算间的数据转移大小极限受Java虚拟机(JVM)内存分配的限制。在MJS集群上执行job的client和worker间的单次数据转移量也受此限制。具体大小限制取决于系统结构。如下表所示:
表 2‑4 每次转移数据的最大量与系统结构的关系
| 系统结构(System Architecture) | 每次转移数据的最大数(近似值.) |
| 64-bit | 2.0 GB |
| 32-bit | 600 MB |
1.2.3. 利用parfor并行for循环的步奏
使用parfor并行for循环的基本步骤为:
1) 使用parpool函数配置和开启并行计算池。
2) 将串行循环中的for关键字改为parfor,并注意是否要修改循环体,以满足特定要求,如循环变量的类型要求(参见参考手册)
3) 执行完毕后若不再进行并行计算,使用delete关闭并行池。
1.3. 批处理(batch)
batch函数完成函数或脚本在集群或台式机上的分载执行,也就是实现函数或脚本的并行。这里不再说明语法(详见Matlab 并行工具箱参考手册),而是举两个例子说明它的使用方法(此例子亦来自参考手册)。
1.3.1. 运行批处理任务
创建mywave.m脚本文件,输入如下代码并保存:
| for i=1:1024 A(i) = sin(i*2*pi/1024); end |
在命令行窗口输入:job = batch('mywave'),Matlab以下图所示方式并行运行:
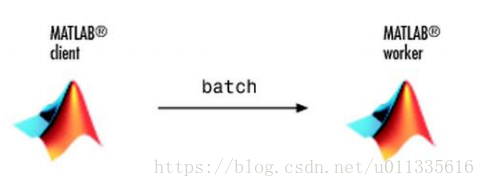
图 2‑3 批处理for循环
然后等待作业完成:wait(job),使用load命令将数据从Matlabworker 转移到Matlabclient的workspace,即load(job,’A’)。任务完成后,使用delete(job)永久删除它的数据。
1.3.2. 运行批处理并行循环
打开mywave.m脚本文件,修改for为parfor,保存,代码如下:
| parfor i=1:1024 A(i) = sin(i*2*pi/1024); end |
输入:job =batch('mywave','Pool',2),以两个worker来执行parfor并行循环任务,所以此例总共使用3个本地worker,如下图所示:
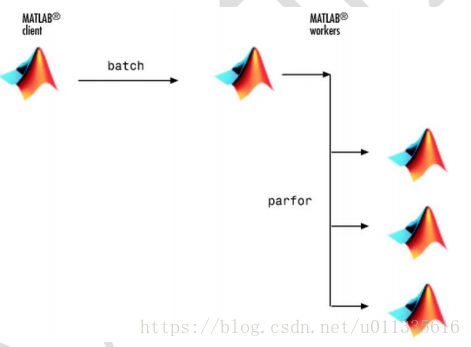
图2‑4 批处理并行循环
同样的,依次使用wait(job)、load(job,'A'),将数据从worker的workspace转移到client的workspace。最后,使用delet(job)删除数据。
批处理命令还有其它的运行方式,在此不再介绍。
1.4. MATLAB的GPU计算
Matlab 的GPU计算实现MATLABworkspace和图形处理器(GPU)间的数据传递;在GPU上执行代码。
用户可以使用计算机的GPU处理矩阵运算,在大多数情况下,在GPU上执行要比在CPU上快。
Matlab的GPU计算提供了下表 2‑5所列的14种MATLAB函数和1种C语言函数,表中仅简要介绍函数功能,具体参见Matlab并行工具箱参考手册。
表2‑5 GPU计算函数列表
| 函数 | 功能 |
| gpuArray | 在GPU上创建阵列。 |
| gather | 把分布式阵列或gpuArray转移到Matlab的workspace。 |
| existsOnGPU | 确定gpuArray或CUDAKernel在GPU上可用。 |
| gpuDevice | 查询或选择GPU设备。 |
| gpuDeviceCount | 目前GPU的设备数量。 |
| gputimeit | 在GPU上运行函数所需时间。 |
| reset | 重置GPU设备并清空它的内存。 |
| wait(GPUDevice) | 等待GPU计算完成。 |
| arrayfun | 对GPU阵列上的每个元素应用函数。 |
| bsxfun | 用于GPU阵列的二元但扩展函数。 |
| pagefun | 对GPU阵列的每一页应用函数。 |
| parallel.gpu.CUDAKernel | 从PTX和CU代码创建 GPU CUDA kernel 对象。 |
| feval | 评估GPU的核。 |
| setConstantMemory | 设置GPU的一些常量内存。 |
| mxInitGPU | 这是一个C语言函数,在当前选择的设备上初始化Matlab GPU计算库。 |
Matlab的GPU计算提供了三种Matlab类和一种C类,如下表 2‑6
表2‑6 Matlab GPU计算提供的类
| 类 | 描述 |
| gpuArray | 存储在GPU上的阵列 |
| GPUDevice | 图形处理单元Graphics processing unit (GPU) |
| CUDAKernel | 执行在GPU上的核 |
| mxGPUArray | 它是一个C类,MEX函数可以访问Matlab的gpuArray |
关于各类的具体含义和各函数的详细用法请参见MATLAB并行工具箱手册。
下面主要从:GPU设备查询、在GPU上创建数组、在GPU上运行内置函数、在GPU上运行自定义函数四个方面说明Matlab GPU计算支持的技术,此外,用户还可以在GPU上运行CUDA或PTX代码、运行包含CUDA代码的MEX-函数等等,详见MATLAB并行工具箱手册和文献[3]的第10章。
1.4.1. GPU 设备查询与选择
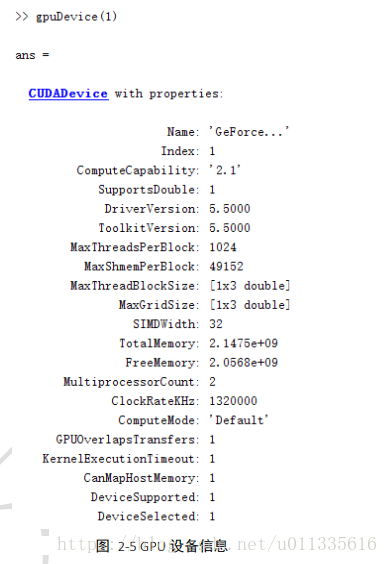
| 图 2‑5 GPU设备信息 |
GPU设备查询与选择
在使用GPU设备之前,可以利用gpuDeviceCount函数查看计算机当前可用GPU设备数量,若存在可用的GPU设备,则输出大于等于1的数。
在Matlab中使用gpuDevice(IDX)来选择第IDX个GPU设备,起始编号为1,如输入gpuDevice(1),输出右图所示结果:
其中,“MaxThreadsPerBlock”表示每个Block的最大线程数;“MaxShmemPerBlock”表示每个Block可用的最大共享内存大小;“TotalMemory”表示GPU拥有的所有内存,图中为2.1475e+09Byte,即2GB;“FreeMemory”代表可用内存;“MultiprocessorCount”表示GPU设备处理器个数;“DeviceSupported”表示本机Matlab支持的GPU设备数。
1.4.2. 在GPU上创建阵列
有两种方式在GPU上创建阵列:从Workspace转移和直接创建。
1) 从Workspace转移到GPU
使用gpuArray函数来把数据从Workspace转移到GPU,如下面的代码所示,将Workspace中的阵列A转移到GPU中,并存为G,原Workspace中的A阵列并不消失。
| A = [1 2 3;4 5 6]; G = gpuArray(A); |
该函数支持对非稀疏阵列且可以是:'single','double','int8','int16','int32','int64','uint8','uint16','uint32','uint64',or 'logical'类型。
2) 直接创建GPU阵列
gpuArray类提供了一些方法来在GPU上直接创建阵列,这样就不需要从Workspace进行转移。可用的有:
表 2‑7 gpuArray类提供的创建GPU阵列的方法
| 方法 | 方法 |
| eye(___,'gpuArray') | rand(___,'gpuArray') |
| false(___,'gpuArray') | randi(___,'gpuArray') |
| Inf(___,'gpuArray') | randn(___,'gpuArray') |
| NaN(___,'gpuArray') | |
| ones(___,'gpuArray') | gpuArray.linspace |
| true(___,'gpuArray') | gpuArray.logspace |
| zeros(___,'gpuArray') | gpuArray.colon |
如:G = ones(100,100,50,'gpuArray');在GPU上创建一个100-by-100-by-50的阵列。
此外,支持gpuArray阵列的方法还有abs,cos,fft,conv,plot等等共369个方法。若要查看,输入如下命令即可查看:
| methods('gpuArray') |
如果,要查看某个方法的帮助,输入如下命令查看:
| help gpuArray/functionname |
其中,functionname为函数名,如:helpgpuArray/dot。
3) 从GPU上回收数据
从GPU上回收数据,即把数据从GPU转移到MatlabWorkspace。在Matlab中使用gather函数来取回GPU上的数据并存在Matlab的 Workspace中。可以使用isequal函数来验证转移前后,值是否相同。如下代码将GPU中的阵列G传回到Workspace生成D。
| G = gpuArray(ones(100,'uint32')); D = gather(G); OK = isequal(D,G)
|
1.4.3. 在GPU上运行内置函数
如 2)直接创建GPU阵列 所述,Matlab的369个函数都支持对GPU阵列的操作,下面是手册上的一个示例代码:
| Ga = rand(1000,'single','gpuArray'); Gfft = fft(Ga); Gb = (real(Gfft) + Ga) * 6; G = gather(Gb); |
代码主要实现对GPU上的阵列Ga进行FFT变换,并将结果回收到Workspace。可见内置函数的调用与普通串行程序没有大的区别,只是输入阵列的类型为gpuArray。
1.4.4. 在GPU上运行自定义函数
Matlab中使用arrayfun或bsxfun来执行自定义的函数,即:
| result = arrayfun(@myFunction,arg1,arg2); |
下面举例来说明,创建myfun.m文件,打开输入如下代码:
| function [ absga1,absga2,maxga ] = myfun( ga1,ga2 ) absga1 = abs(ga1); absga2 = abs(ga2); maxga = max(absga1,absga2); |
该代码实现对输入阵列ga1,ga2的每个元素取绝对值,然后取出两者中对应最大的。为了运行并查看结果,创建一个脚本,输入如下代码:
| ga1 = [-1 5 -3] ga2 = gpuArray([4 -6 -2]) [absga1,absga2,maxga] = arrayfun(@myfun,ga1,ga2) absda1 = gather(absga1) absda2 = gather(absga2) maxda = gather(maxga) |
通过上述程序,可以看出,在自定义函数myfun中,只要有一个输入参数的类型为gpuArray,则整个函数myfun都将运行在GPU中,对于非gpuArray类型的阵列,Matlab自动进行转换。
除了可以调用Matlab自身支持的函数外,可以自己编写支持GPU的Matlab函数。自定义的函数中可以调用的函数和操作如下表 2 8:
表2‑8 自定义函数中支持gpuArray的函数和操作
| abs and acos acosh acot acoth acsc acsch asec asech asin asinh atan atan2 atanh beta betaln bitand bitcmp bitget bitor bitset bitshift bitxor ceil complex conj cos cosh cot coth csc csch | double eps eq erf erfc erfcinv erfcx erfinv exp expm1 false fix floor gamma gammaln ge gt hypot imag Inf int8 int16 int32 int64 intmax intmin isfinite isinf isnan ldivide le log log2 | log10 log1p logical lt max min minus mod NaN ne not or pi plus pow2 power rand randi randn rdivide real reallog realmax realmin realpow realsqrt rem round sec sech sign sin single | sinh sqrt tan tanh times true uint8 uint16 uint32 uint64 xor
+ - .* ./ . .^ == ~= < <= > >= & | ~ && || | 以下的标量扩展版: * / ^ 分支指令: break continue else elseif for if return while |
2. 总结
本文简要介绍了Matlab并行工具箱及其用法,包括多处理器的并行和GPU的并行,具体包括:并行计算池的开启,查询与关闭;for循环的并行;批处理;GPU计算。由于时间关系并未介绍分布式阵列和SPMD。
尝试并行化自己改进的Hough变换算法和FCM,可是并行后的效果很差(这和使用的电脑的配置有关),本文中并未给出,将来会进一步研究。
之所以选择高性能计算这门课,是因为在研究学习中,发现程序的运行速度是一个很重要和亟待解决的问题。已经尽量采用矢量化编程实现,可是它的本质是牺牲空间换时间,仍不能满足需求。高性能计算让我找到了突破点,将来会继续开展相关的工作。
[1] http://baike.baidu.com/view/1666.htm?fr=aladdin
[2] 并行工具箱在线手册:http://cn.mathworks.com/help/distcomp/index.html
[3] 实战 Matlab之并行程序设计[J]. 2012.
最后
以上就是缓慢皮带最近收集整理的关于Matlab 并行计算学习初步1. 简介2. Matlab并行计算初探2. 总结的全部内容,更多相关Matlab内容请搜索靠谱客的其他文章。








发表评论 取消回复