本系列博客配备github代码,本小节代码见:https://github.com/qixuxiang/cuda_zero_to_one/blob/master/thread_print.cu
这里继续讲上一节cuda从入门到精通(二)之函数关键字的一个遗留问题:__global__修饰函数中的<<<1,1>>>到底是什么。
CUDA程序的执行流程中,最重要的一步是调用CUDA的核函数来执行并行计算,kernel是CUDA中一个重要的概念,kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用<<<grid_size, block_size>>>来指定kernel要执行的线程数量,在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
利用<< >>执行配置可以指定线程在GPU上调度运行的方式。执行配置的第一个值是网格维度,也就是启动块的数目。第二个值是块维度,也就是每个块中线程的数目。通过指定网格和块的维度,你可以进行以下配置:
- 内核中线程的数目
- 内核中使用的线程布局
同一个块中的线程之间可以相互协作,不同块内的线程不能协作。对于一个给定的问题,可以使用不同的网格和块布局来组织你的线程。例如,假设你有32个数据元素用于计算,每8个元素一个块,需要启动4个块:
kernel_name <<4, 8>>(arg list);

对于kernel中每一线程,都有各自的唯一的索引id号或者标识符。在上面,我们用了两个参数grid size 和block size,但这两个参数如何构建出唯一线程id呢?
在kernel函数中,grid size 和block size都被存储在内置预定义变量gridDim.x 和 blockDim.x中。相应地,线程唯一id被以下两个内置预定义变量所制定:
- blockIdx.x: 指定了线程在几个网格(grid)的第几个块(block),值在0到
gridDim.x - 1之间。 - threadIdx.x:指定了线程在第几个块(block)中的第几个线程,值在0到
blockDim.x - 1之间。
例如,我们需要起16个线程来计算,四个线程块,每个块内四个线程的图示例子:
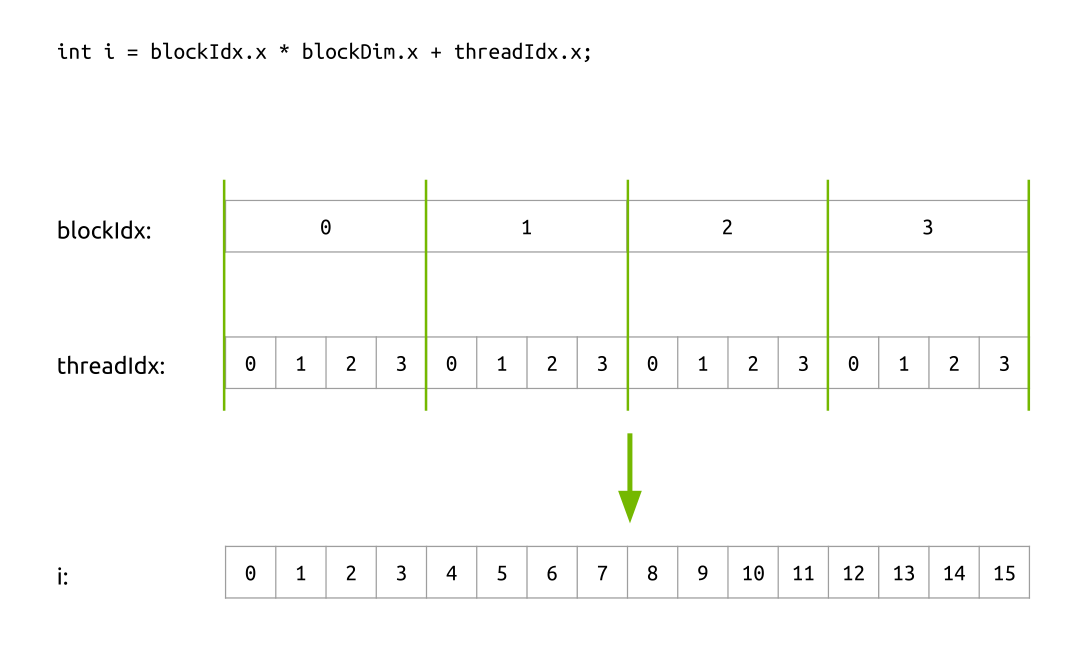
对上面的图示的代码可视化如下:
#include "cuda.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void hello_from_gpu()
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
printf("Hello World from block %d and thread %d!n", bid, tid);
}
int main(void)
{
hello_from_gpu<<<4, 4>>>();
cudaDeviceSynchronize();
return 0;
}
因为每个网格(grid)互相独立,所以上述输出并不确定。
网格和线程块
要深刻理解kernel,必须要对kernel的线程层次结构有一个清晰的认识。首先GPU上很多并行化的轻量级线程。kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格grid,同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块block,一个线程块里面包含很多线程,这是第二个层次。
dim3 grid(3, 2);
dim3 block(5, 3);
kernel_fun<<< grid, block >>>(prams...);
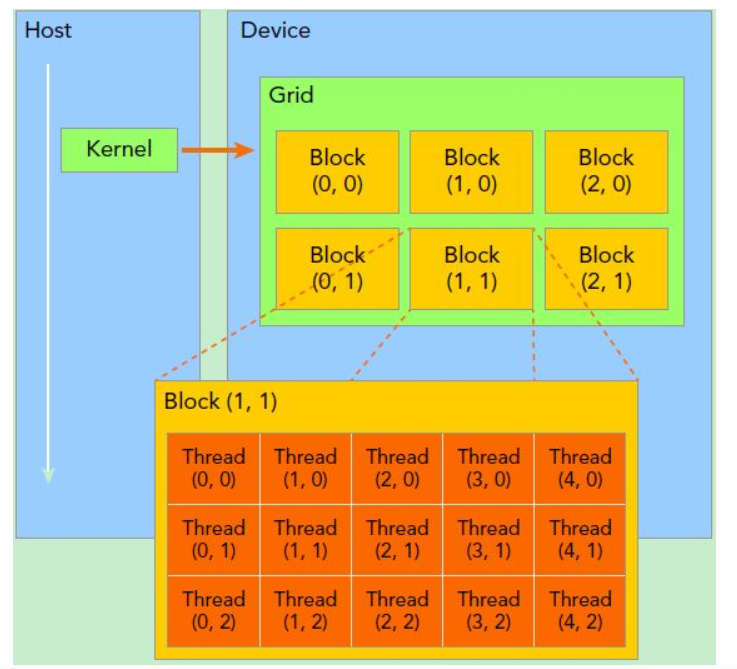 线程两层组织结构如上图所示,这是一个
线程两层组织结构如上图所示,这是一个gird和block均为2-dim的线程组织。grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数x,y,z成员的结构体变量,在定义时,缺省值初始化为1。因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构,对于图中结构(主要水平方向为x轴),定义的grid和block如下所示,kernel在调用时也必须通过执行配置<<<grid, block>>>来指定kernel所使用的线程数及结构。
CUDA运行时为每个线程分配坐标变量blockIdx和threadIdx,基于这些坐标,你可以将部分数据分配给不同的线程。该坐标变量是基于uint3定义的CUDA内置的向量类型,是一个包含3个无符号整数的结构,可以通过x、y、z三个字段来指定。
所以,一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,它们都是dim3类型变量,其中blockIdx指明线程所在grid中的位置,而threaIdx指明线程所在block中的位置,如上图中的Thread (1,1)满足:
threadIdx.x = 1
threadIdx.y = 1
blockIdx.x = 1
blockIdx.y = 1
在同一时刻,一个CUDA核只能运行一个线程,而线程作为逻辑的运行载体有其自己的ID。这个ID和我们在linux或windows系统上CPU相关的线程ID有着不同的表达方式。比如在Linux系统上可以使用gettid方法获取一个pid_t值,比如3075。但是cuda的表达方式是一个三维空间,表达这个空间的是一个叫block的概念。比如单个block定义其有Dx, Dy, 0个线程,则每个线程ID为x+yDx;再比如有Dx, Dy, Dz个线程,则每个线程ID为x+yDx+zDxDy。
#include "cuda.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void run_on_gpu() {
printf("GPU thread info X:%d Y:%d Z:%dt block info X:%d Y:%d Z:%dn",
threadIdx.x, threadIdx.y, threadIdx.z, blockIdx.x, blockIdx.y, blockIdx.z);
}
int main() {
dim3 threadsPerBlock(2, 3, 4);
int blocksPerGrid = 1;
run_on_gpu<<<blocksPerGrid, threadsPerBlock>>>();
cudaDeviceReset();
return 0;
}
上面程序输出为:
GPU thread info X:0 Y:0 Z:0 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:0 Z:0 block info X:0 Y:0 Z:0
GPU thread info X:0 Y:1 Z:0 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:1 Z:0 block info X:0 Y:0 Z:0
GPU thread info X:0 Y:2 Z:0 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:2 Z:0 block info X:0 Y:0 Z:0
GPU thread info X:0 Y:0 Z:1 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:0 Z:1 block info X:0 Y:0 Z:0
GPU thread info X:0 Y:1 Z:1 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:1 Z:1 block info X:0 Y:0 Z:0
GPU thread info X:0 Y:2 Z:1 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:2 Z:1 block info X:0 Y:0 Z:0
GPU thread info X:0 Y:0 Z:2 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:0 Z:2 block info X:0 Y:0 Z:0
GPU thread info X:0 Y:1 Z:2 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:1 Z:2 block info X:0 Y:0 Z:0
GPU thread info X:0 Y:2 Z:2 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:2 Z:2 block info X:0 Y:0 Z:0
GPU thread info X:0 Y:0 Z:3 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:0 Z:3 block info X:0 Y:0 Z:0
GPU thread info X:0 Y:1 Z:3 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:1 Z:3 block info X:0 Y:0 Z:0
GPU thread info X:0 Y:2 Z:3 block info X:0 Y:0 Z:0
GPU thread info X:1 Y:2 Z:3 block info X:0 Y:0 Z:0
承载block的是一个叫做grid的概念。block在grid中的位置也是通过一个三维结构来表达,比如下面代码标识的是一个一个Grid包含(3,3,3)结构的Block,一个Block包含(3,3,3)结构的Thread:
dim3 blocksPerGrid(3, 3, 3);
dim3 threadsPerBlock(3, 3, 3);
run_on_gpu<<<blocksPerGrid, threadsPerBlock>>>();
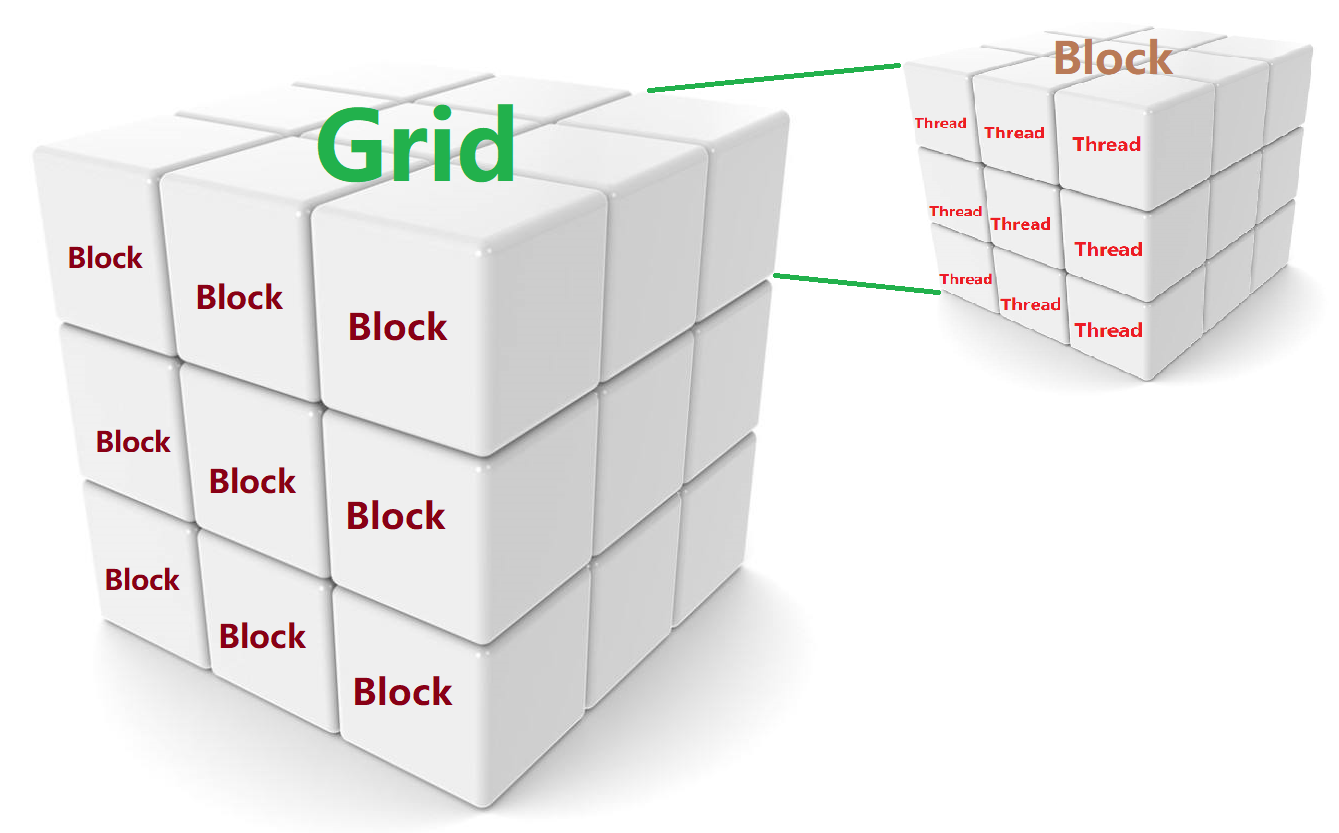
网格和线程块的维度
网格和块的维度由下列两个内置变量指定。
- blockDim(线程块的维度,用每个线程块中的线程数来表示)
- gridDim(线程格的维度,用每个线程格中的线程数来表示)
它们是dim3类型的变量,是基于uint3定义的整数型向量,用来表示维度。当定义一个dim3类型的变量时,所有未指定的元素都被初始化为1。dim3类型变量中的每个组件可以通过它的x、y、z字段获得,例如:
blockDim.x
blockDim.y
blockDim.z
通常,一个线程格会被组织成线程块的二维数组形式,一个线程块会被组织成线程的三维数组形式。线程格和线程块均使用3个dim3类型的无符号整型字段,而未使用的字段将被初始化为1且忽略不计。
在CUDA程序中有两组不同的网格和块变量:手动定义的dim3数据类型和预定义的uint3数据类型。
在主机端,作为内核调用的一部分,你可以使用dim3数据类型定义一个网格和块的维度。当执行核函数时,CUDA运行时会生成相应的内置预初始化的网格、块和线程变量,它们在核函数内均可被访问到且为unit3类型。手动定义的dim3类型的网格和块变量仅在主机端可见,而unit3类型的内置预初始化的网格和块变量仅在设备端可见。
需要强调的是:主机端上的用来检查网格和线程块维度的代码和在核函数中,每个线程输出自己的线程索引、块索引、块维度和网格维度差异挺大的,下面的代码展示了二者的区别:
#include "cuda.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
__global__ void checkIndex(void)
{
printf("threadIdx:(%d, %d, %d)n", threadIdx.x, threadIdx.y, threadIdx.z);
printf("blockIdx:(%d, %d, %d)n", blockIdx.x, blockIdx.y, blockIdx.z);
printf("blockDim:(%d, %d, %d)n", blockDim.x, blockDim.y, blockDim.z);
printf("gridDim:(%d, %d, %d)n", gridDim.x, gridDim.y, gridDim.z);
}
int main(int argc, char **argv)
{
// define total data element
int nElem = 6;
// define grid and block structure
dim3 block(3);
dim3 grid((nElem + block.x - 1) / block.x);
// check grid and block dimension from host side
printf("grid.x %d grid.y %d grid.z %dn", grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %dn", block.x, block.y, block.z);
// check grid and block dimension from device side
checkIndex<<<grid, block>>>();
// reset device before you leave
CHECK(cudaDeviceReset());
return 0;
}
为什么cuda的线程要设计的这么复杂?我想其可能和GPU设计的初始目的有关——图像运算。而我们肉眼的感官就是三维的,所以GPU有大量三维计算的需求。
个人觉得大家不要拘泥于threadID的计算,而要学会如何利用blockIdx、threadIdx的三维坐标来进行并行计算。kernel的这种线程组织结构天然适合vector/matrix等运算,我们将在下一节实现一个简单的并行计算双矩阵求和的CUDA程序。
最后
以上就是朴实棒棒糖最近收集整理的关于cuda从入门到精通(三)之核函数和参数配置的全部内容,更多相关cuda从入门到精通(三)之核函数和参数配置内容请搜索靠谱客的其他文章。








发表评论 取消回复