- 实验目的
在matlab平台上,采用神经网络实现手写数字识别。在实验过程中:
1、初步探讨数据集预处理的作用。
2、增加对神经网络的理解,探讨隐含层层数,节点数和训练步长对识别成功率的影响,找到较佳的参数。
3、应用交叉验证法评估训练模型的优劣,建立多次实验取均值的严谨思维。
二、分类器原理阐述
1、前向传播:
输入样本从输入层传入,经隐层逐层处理后,传到输出层,计算实际输出和期望输出的误差。
2、误差反向传播:
运用链式法则,采用误差梯度下降法对权值进行修正。
- 重复上述过程,直到满足一定条件:
- 网络实际输出与期望输出的总误差 < 阈值。
- 最近一轮训练中所有权值变化最大值 < 阈值。
- 算法达到最大允许的总训练次数
- 实验方法
- 对所给图片进行读取和处理:
- 修改图片的命名方式,每个数字的不同样本依次命名为:‘1.png’,’2.png’...’55.png’。方便下面数据读取和处理。(这里自己写了一个程序自动修改图片名)
- 调用data=imread(picture_name)函数读取每张图片数据。
- 将得到的原始数据灰度化,数据类型转化以及二值化。(数据类型转化必不可少,要将uint8类型转化为double型才能保证接下来对数据运算是正确的。一开始没有做这一步使神经网络每次训练出来的输出都是无穷大。)
- 找到数字所在区域,去除多余的空白空间。(这一步可以有效提高学习正确率)
- 将图片数据由矩阵形式转化为列向量。
- 依次读取所有图片,并将图片读取顺序打散,间接实现打散样本。
- 将每个数字的样本5等份,每次取不同的一份作为测试集,其余作为训练集。
- 生成相应标签矩阵:
通过重复取单位矩阵不同列巧妙地构造出训练和测试标签。
- 使用5倍交叉验证法评估训练模型的优劣:
- 取好对应训练集和测试集。
- 初始化网络:隐含层层数,节点数,训练步长,训练最大迭代次数,训练精度等等。
- 调用net=train(net,train_data,train_label)函数训练神经网络。
- 调用test_output=sim(net,test_data)函数对测试集进行测试。
- 计算训练正确率。
- 以上重复5次。
- 以上重复3次。
- 实验结果
1、初步探讨数据集预处理对实验结果的影响:
(1)处理前和处理后的数字样本图片:


处理前 处理后
可以看到,处理后图片去掉了许多不必要的空白部分,增加了有用像素点比例。
- 同一网络结构:
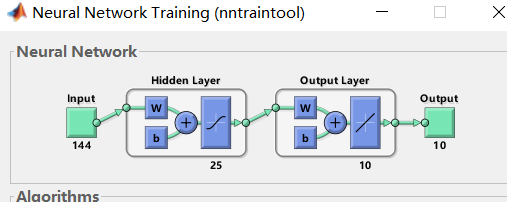
(3)处理前后训练正确率比较:


处理后 处理前
由上可知:在网络结构相同的情况下对图片处理前后正确率天差地别,在我看来,这或许是因为这些图像只有两种取值,一个是0,另一个是255。值255对网络中的权值影响比0大许多,如果没有将大量空白区域通过预处理删去,那么有效信息(即0)对网络权值的影响将更少,这会极大的影响网络的训练。
2、探讨隐含层节点数对识别成功率的影响:
| 隐含层层数 | 隐含层节点数 | 训练步长 | 识别成功率 |
| 1 | (20) | 0.1 | 0.7455 |
| 1 | (25) | 0.1 | 0.8 |
| 1 | (30) | 0.1 | 0.8455 |
| 1 | (35) | 0.1 | 0.8182 |
| 1 | (40) | 0.1 | 0.7 |
| 1 | (45) | 0.1 | 0.8273 |
| 1 | (50) | 0.1 | 0.8455 |
| 1 | (55) | 0.1 | 0.7455 |
| 1 | (60) | 0.1 | 0.8636 |
| 1 | (65) | 0.1 | 0.8182 |
| 1 | (70) | 0.1 | 0.8273 |
| 1 | (80) | 0.1 | 0.7727 |
将上表数据绘制成曲线图如下:
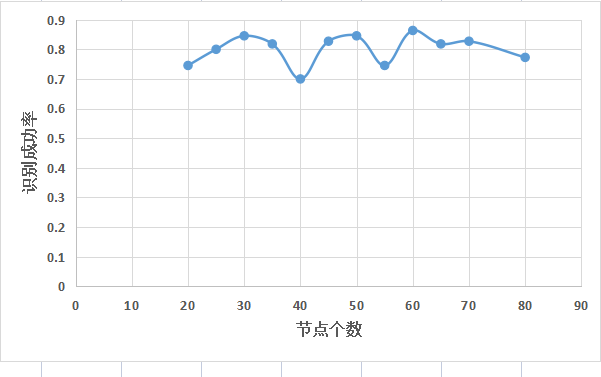
由上可知:一层隐含层时在节点数为30,50和60时有最优点,三个最优点的识别成功率相差并没有太大。综合网络复杂程度和训练时间的因素来看,相比于节点数为50和60,节点数为30个为更佳选择。
3、探讨隐含层层数对识别成功率的影响:
| 隐含层层数 | 隐含层节点数 | 训练步长 | 识别成功率 |
| 1 | (10) | 0.1 | 0.4727 |
| 2 | (10 ,10) | 0.1 | 0.8364 |
| 3 | (10 ,10 ,10) | 0.1 | 0.7727 |
| 4 | (10,10,10,10) | 0.1 | 0.7636 |
| 5 | (10,10,10,10,10) | 0.1 | 0.8182 |
| 6 | (10,10,10,10,10,10) | 0.1 | 0.7727 |
将上表数据绘制成曲线图如下:
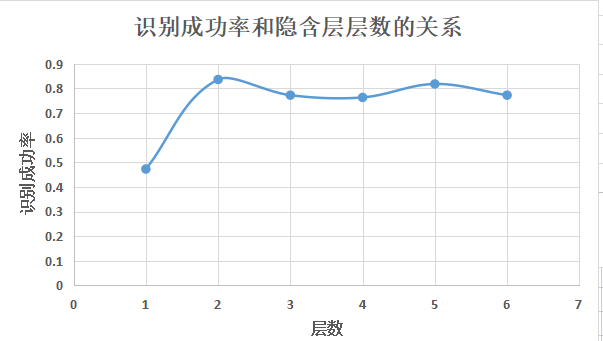
由上图可知,当隐含层>=2后识别成功率基本稳定在0.8左右,层数的增加使网络复杂性大幅增加但识别成功率并没有得到较大提高,所以,本问题下,隐含层层数选择2层即可。
4、探讨训练步长对识别成功率的影响:
| 隐含层层数 | 隐含层节点数 | 训练步长 | 识别成功率 |
| 2 | (30,30) | 0.1 | 0.8818 |
| 2 | (30,30) | 0.2 | 0.8364 |
| 2 | (30,30) | 0.3 | 0.8636 |
| 2 | (30,30) | 0.05 | 0.8636 |
| 2 | (30,30) | 0.02 | 0.9364 |
| 2 | (30,30) | 0.01 | 0.8636 |
将上表数据绘制成曲线图如下:
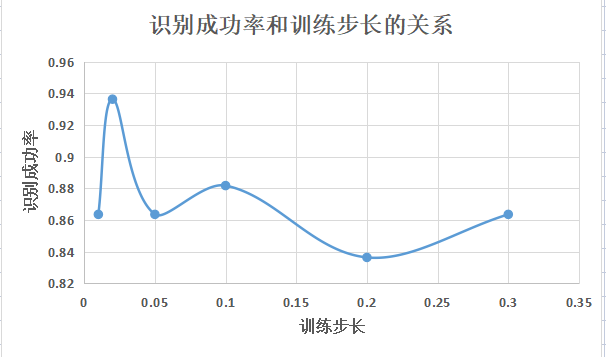
由上可见,当训练步长取0.02时,有一个最优点达到94%,识别成功率高过其它数据的平均值(86%)约8%。这一幅度可以说明在本次实验中,训练步长应该选择0.02。初步考虑应该是(1)相较于更大的步长,0.02可以更好的寻找到最优点,避免“跨越”最优点。(2)相较于更小的步长,0.02可以避免落入局部最优。
六、结果讨论
1、本实验充分说明了数据预处理的重要性。通过预处理,可以将大量的无益于分类的特征消除,一方面既减少了神经网络输入节点,降低了网络复杂度,减少了训练时间;另一方面,同时也提高了有用信息的比例,有利于提高神经网络的分类效果。
2、在调整神经网络的隐含层层数,节点数和训练步长这几个参数时,应该从简单到复杂,以表格的形式罗列。这不仅极大地增加了不同参数效果的可观性,便于较快的查找到较为适合的参数,同时也是一个正常的学习过程:由欠拟合渐渐可以较好地提取到样本特征再到过拟合。我们可以从这个过程清楚神经网络处于什么阶段:欠拟合,较好学习还是过拟合。这又方便了我们调参和分析。
3、本实验采用了5倍交叉验证法,这一方法虽然极大的增加了代码运行时间(大概花费十几分钟),但是这体现了实验的严谨性,这一点很重要。
代码和数据集可以在这里下载:matlab代码和数据集.zip-机器学习文档类资源-CSDN下载里面几个.m文件是相互调用关系,其中my_train是主函数更多下载资源、学习资料请访问CSDN下载频道.https://download.csdn.net/download/weixin_46579610/39154915
这里给出代码:
function [train,test] = read_picture(model,file_address)
%读取一种数字图片信息,返回训练集和测试集
picture_num=55;%图片数量
number=randperm(picture_num);%产生1到55随机整数,打散样本
train=[];
test=[];
%将55个样本分为5份,根据不同情况设置不同测试集和训练集
%最后一组作为测试集
if model==1
for i=1:44%训练集
pic_name=strcat(num2str(number(i)),'.png');
x=imread(strcat(file_address,pic_name));%读取一张图片
x=rgb2gray(x);%灰度化处理
x=im2double(x);%转化为double类型,不转化会出错
[a b]=find(x~=1);%二值化处理
x=x(min(a):max(a),min(b):max(b));%只选取数字所在区域
%imshow(x);%画图查看是否处理成功
x=imresize(x,[12,12]);%压缩图片
x=reshape(x,144,1);%将矩阵转化为列向量
train=[train x];
end
for i=45:55%测试集
pic_name=strcat(num2str(number(i)),'.png');
y=imread(strcat(file_address,pic_name));
y=rgb2gray(y);
y=im2double(y);
[c d]=find(y~=1);
y=y(min(c):max(c),min(d):max(d));
%imshow(y);
y=imresize(y,[12,12]);
y=reshape(y,144,1);
test=[test y];
end
end
%第四组作为测试集
if model==2
for i=1:33
pic_name=strcat(num2str(number(i)),'.png');
x=imread(strcat(file_address,pic_name));
x=rgb2gray(x);
x=im2double(x);
[a b]=find(x~=1);
x=x(min(a):max(a),min(b):max(b));
x=imresize(x,[12,12]);
x=reshape(x,144,1);
train=[train x];
end
for i=34:44
pic_name=strcat(num2str(number(i)),'.png');
y=imread(strcat(file_address,pic_name));
y=rgb2gray(y);
y=im2double(y);
[c d]=find(y~=1);
y=y(min(c):max(c),min(d):max(d));
y=imresize(y,[12,12]);
y=reshape(y,144,1);
test=[test y];
end
for i=45:55
pic_name=strcat(num2str(number(i)),'.png');
x=imread(strcat(file_address,pic_name));
x=rgb2gray(x);
x=im2double(x);
[a b]=find(x~=1);
x=x(min(a):max(a),min(b):max(b));
x=imresize(x,[12,12]);
x=reshape(x,144,1);
train=[train x];
end
end
%第三组作为测试集
if model==3
for i=1:22
pic_name=strcat(num2str(number(i)),'.png');
x=imread(strcat(file_address,pic_name));
x=rgb2gray(x);
x=im2double(x);
[a b]=find(x~=1);
x=x(min(a):max(a),min(b):max(b));
x=imresize(x,[12,12]);
x=reshape(x,144,1);
train=[train x];
end
for i=23:33
pic_name=strcat(num2str(number(i)),'.png');
y=imread(strcat(file_address,pic_name));
y=rgb2gray(y);
y=im2double(y);
[c d]=find(y~=1);
y=y(min(c):max(c),min(d):max(d));
y=imresize(y,[12,12]);
y=reshape(y,144,1);
test=[test y];
end
for i=34:55
pic_name=strcat(num2str(number(i)),'.png');
x=imread(strcat(file_address,pic_name));
x=rgb2gray(x);
x=im2double(x);
[a b]=find(x~=1);
x=x(min(a):max(a),min(b):max(b));
x=imresize(x,[12,12]);
x=reshape(x,144,1);
train=[train x];
end
end
%第二组作为测试集
if model==4
for i=1:11
pic_name=strcat(num2str(number(i)),'.png');
x=imread(strcat(file_address,pic_name));
x=rgb2gray(x);
x=im2double(x);
[a b]=find(x~=1);
x=x(min(a):max(a),min(b):max(b));
x=imresize(x,[12,12]);
x=reshape(x,144,1);
train=[train x];
end
for i=12:22
pic_name=strcat(num2str(number(i)),'.png');
y=imread(strcat(file_address,pic_name));
y=rgb2gray(y);
y=im2double(y);
[c d]=find(y~=1);
y=y(min(c):max(c),min(d):max(d));
y=imresize(y,[12,12]);
y=reshape(y,144,1);
test=[test y];
end
for i=23:55
pic_name=strcat(num2str(number(i)),'.png');
x=imread(strcat(file_address,pic_name));
x=rgb2gray(x);
x=im2double(x);
[a b]=find(x~=1);
x=x(min(a):max(a),min(b):max(b));
x=imresize(x,[12,12]);
x=reshape(x,144,1);
train=[train x];
end
end
%第一组作为测试集
if model==5
for i=1:11
pic_name=strcat(num2str(number(i)),'.png');
y=imread(strcat(file_address,pic_name));
y=rgb2gray(y);
y=im2double(y);
[c d]=find(y~=1);
y=y(min(c):max(c),min(d):max(d));
y=imresize(y,[12,12]);
y=reshape(y,144,1);
test=[test y];
end
for i=12:55
pic_name=strcat(num2str(number(i)),'.png');
x=imread(strcat(file_address,pic_name));
x=rgb2gray(x);
x=im2double(x);
[a b]=find(x~=1);
x=x(min(a):max(a),min(b):max(b));
x=imresize(x,[12,12]);
x=reshape(x,144,1);
train=[train x];
end
end
end
function [net] = init_net(input,output)
T=[30 30];
net=newff(input,output,T);
net.trainParam.goal=0.00001;
net.trainParam.lr=0.02;
net.trainParam.min_grad = 1e-6;
net.trainParam.epochs=100;
end
function [success_rate] = my_train()
%存储数据的文件地址,在运行前要根据自己的数据文件所在地址修改并且设置好路径
%图片数据就使用我附带的文件夹
file_address={'D:Desktophomeworkbig_homeworkimgsample0';
'D:Desktophomeworkbig_homeworkimgsample1';
'D:Desktophomeworkbig_homeworkimgsample2';
'D:Desktophomeworkbig_homeworkimgsample3';
'D:Desktophomeworkbig_homeworkimgsample4';
'D:Desktophomeworkbig_homeworkimgsample5';
'D:Desktophomeworkbig_homeworkimgsample6';
'D:Desktophomeworkbig_homeworkimgsample7';
'D:Desktophomeworkbig_homeworkimgsample8';
'D:Desktophomeworkbig_homeworkimgsample9'};
%生成训练标签
a=eye(10,10);
total_tag=[];
for i=1 :10
tag=[];
for j=1 :44
tag=[tag a(:,i)];
end
total_tag=[total_tag tag];
end
%生成测试标签
test_tag=[];
for i=1 :10
tag=[];
for j=1 :11
tag=[tag i];
end
test_tag=[test_tag tag];
end
%5倍交叉验证
total_error_rate=0;
for i=1:3%重复3次
error=0;
for model= 1:5%随机划分5等份
model=1;
%读取数据
total_train=[];
total_test=[];
for i=1: 10
[one_train,one_test] = read_picture(model,file_address{i});
total_train=[total_train one_train];
total_test=[total_test one_test];
end
%初始化网络
net = init_net(total_train,total_tag);
%训练网络
net=train(net,total_train,total_tag);
%测试网络
test_output=sim(net,total_test);
label_train=[];
%将测试集的到的输出转化为元素是0或1的向量
for i=1:110
label_one=find(test_output(:,i)==max(test_output(:,i)));
label_train=[label_train label_one];
end
error_matrix=test_tag-label_train;
error_num=sum(any(error_matrix,1));%统计非零列的个数,即分类错误个数
error=error+error_num;
end
error_rate= error/550;%统计一次交叉验证的错误率
total_error_rate=total_error_rate+error_rate;
end
total_error_rate=total_error_rate/3;
success_rate=1-total_error_rate;%计算正确率
end最后
以上就是糊涂玉米最近收集整理的关于基于神经网络实现手写数字识别(matlab)的全部内容,更多相关基于神经网络实现手写数字识别(matlab)内容请搜索靠谱客的其他文章。


![手写数字识别代码函数解读(MATLAB实现)1、tf = strcmp(s1,s2)2、out_files=dir(xxx)3、图像预处理4、粗网格特征提取5、[B,I] = sort(A)6、fullfile(filepart1,filepart2,…,filepartN)错误](https://www.shuijiaxian.com/files_image/reation/bcimg14.png)





发表评论 取消回复