文章目录
- sigmoid
- Tanh
- Relu
- leaky relu
- PRelu
- ELU
- GLU/GTU
- gelu
- swish
- 激活函数使用原则
激活函数的主要作用是提供网络的非线性建模能力。
本文简要介绍一些常用的激活函数。
sigmoid
torch.nn.Sigmoid
f
(
x
)
=
1
1
+
e
−
x
f(x) = frac{1}{1+e^{-x}}
f(x)=1+e−x1
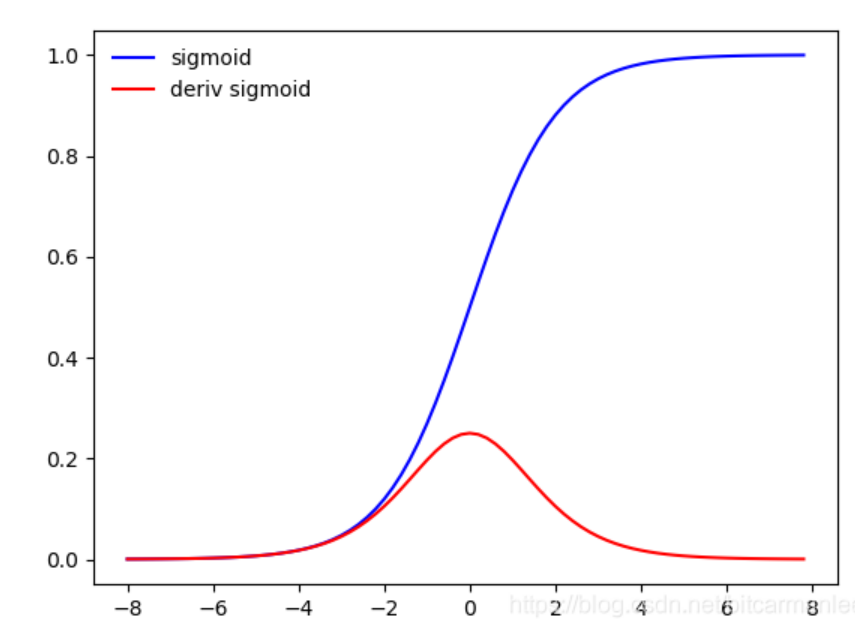
可以被表示做概率,或者用于输入的归一化。连续,光滑,严格单调,以(0,0.5)中心对称,是一个非常良好的阈值函数。
导数: f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x) = f(x)(1-f(x)) f′(x)=f(x)(1−f(x)), 计算方便
lim x → ∞ f ′ ( x ) = 0 lim _{x rightarrow infty} f^{prime}(x)=0 limx→∞f′(x)=0
具有这种性质的称为软包和激活函数,当|x|>c, 其中c为常数,f’(x)=0
一旦落入饱和区,导致了向底层传递的梯度值变得非常小,此时网络参数很难得到有效的训练,(梯度消失)
缺点:
- sigmoid函数在输入绝对值很大时会出现饱和现象,导致梯度消失
- sigmoid函数的输出不是0均值,会导致后层的神经元输入时非0均值的信号,会对梯度产生影响
- 计算复杂度高,因为时指数形式
Tanh
torch.nn.Tanh
成为双曲正切函数,取值范围[-1,1]
$tanh(x) = frac{e^x - e{-x}}{ex + e^{-x}} = 2*sigmoid(x) - 1 $
导数: f ′ ( x ) = 1 − ( tanh ( x ) ) 2 f'(x) = 1 - (tanh(x))^2 f′(x)=1−(tanh(x))2
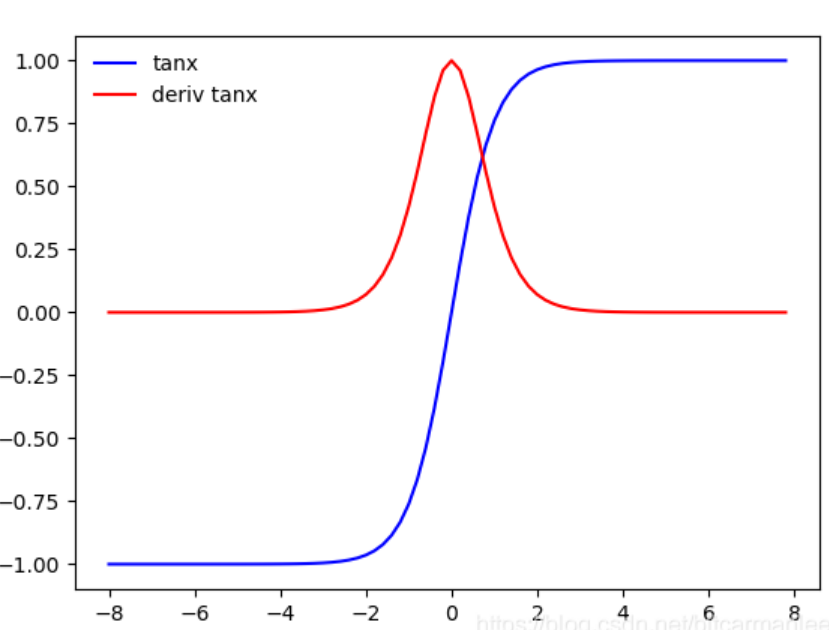
Tanh是0均值的,因此实际应用中tanh会比sigmoid更好,收敛更快。但是仍然存在梯度饱和和指数计算的问题。
Relu
torch.nn.ReLU(inplace=False)
整流线性单元(Rectified linear unit, Relu)比较常用
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
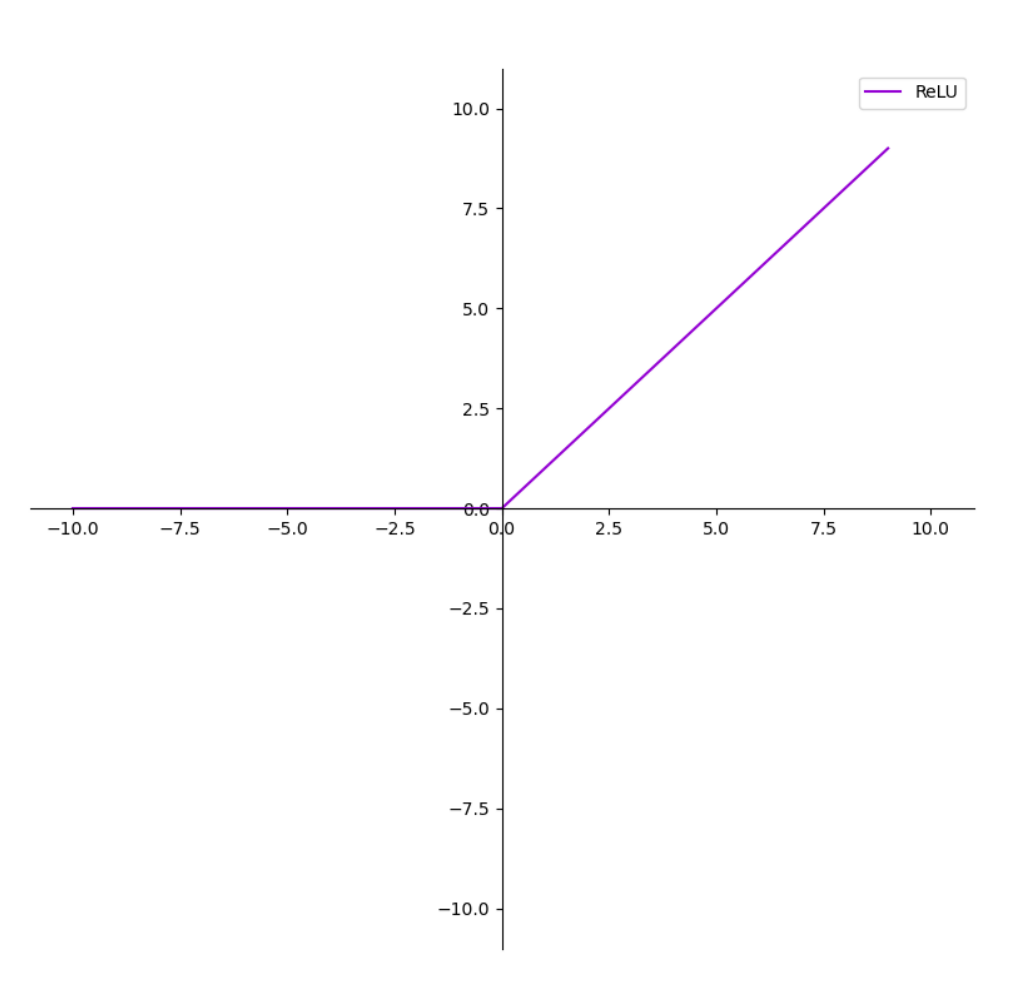
使用Relu的SGD算法的收敛速度比sigmoid和tanh块,在x>0区域上不会出现梯度饱和和梯度消失的问题。计算复杂度低,不需要指数运算。
缺点:
-
输出不是0均值
-
dead relu (神经元坏死现象): relu在负数区域被kill的现象叫做dead relu,当x<0,梯度为0,这个神经元及之后的神经元梯度永远为0,不再对任何数据有所响应,导致相应的参数不会更新
产生这种现象的两个原因:参数初始化问题;learning rate太高导致在训练过程中参数更新太大。
解决方法:采用Xavier初始化方法,以及避免将learning rate设置太大或者使用adagrad等自动调节learning rate
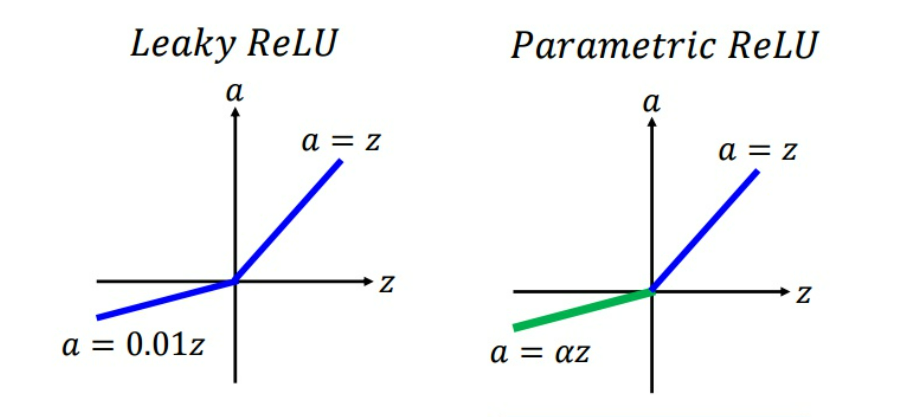
leaky relu
torch.nn.LeakyReLU(negative_slope=0.01, inplace=False)
为了解决dead relu现象,用一个类似0.01的小值来初始化神经元,从而使relu在负数区域更偏向于激活而不是死掉,这里的斜率是确定的。
f ( x ) = m a x ( α x , x ) f(x) = max(alpha x, x) f(x)=max(αx,x)
其中 α alpha α为确定值,一般设为较小的值
优点:缓解了dead relu问题
缺点:实际中不太稳定,有些近似线性,导致在复杂分类中效果不好。
PRelu
torch.nn.PReLU(num_parameters=1, init=0.25)
参数整流线性单元,用来解决Relu带来的神经元坏死问题。
f ( x ) = m a x ( α x , x ) f(x) = max(alpha x, x) f(x)=max(αx,x)
其中 α alpha α是可学习参数,一般初始化为0.25。(和leaky relu的区别)
ELU
torch.nn.ELU(alpha=1.0, inplace=False)
指数线性单元,具有Relu的优势,没有dead relu的问题,输出均值接近于0.有负数饱和区,从而对噪声有一些鲁棒性。
f ( x ) = { x if x > 0 α ( exp ( x ) − 1 ) if x ≤ 0 f(x)= begin{cases}x & text { if } x>0 \ alpha(exp (x)-1) & text { if } x leq 0end{cases} f(x)={xα(exp(x)−1) if x>0 if x≤0
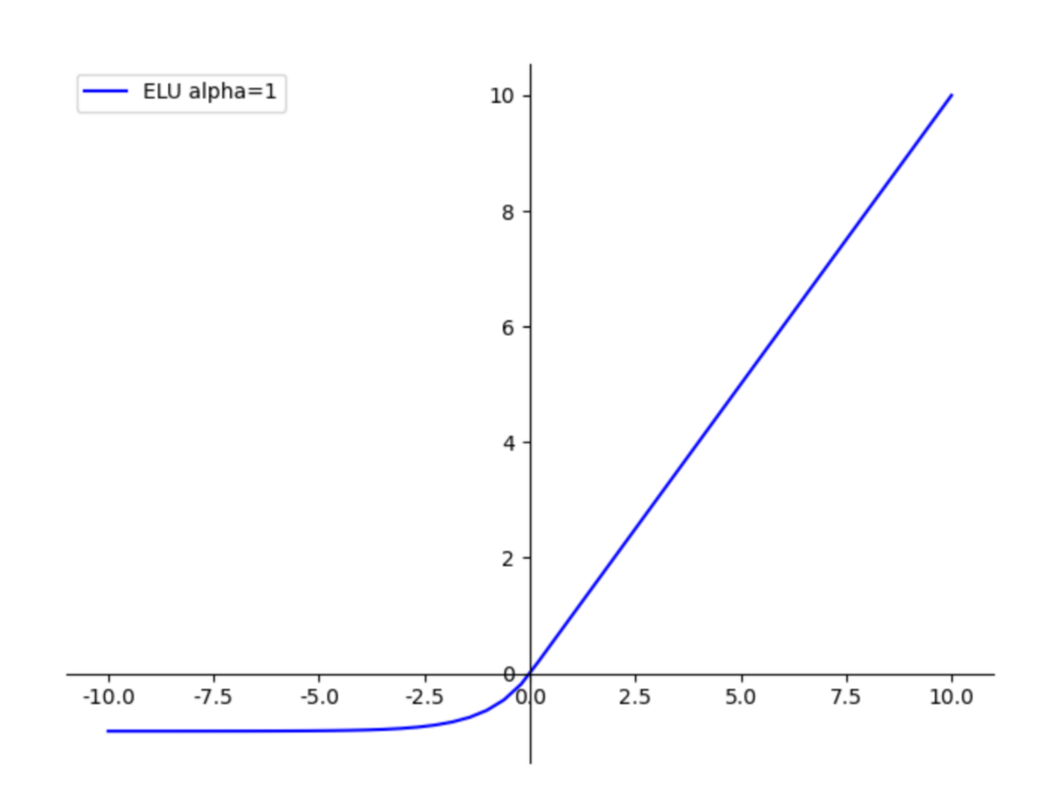
其中 α alpha α是超参数,默认为1.0
缺点:计算量稍大,原点不可导
GLU/GTU
门控机制激活函数。
glu: f ( x ) = ( x ∗ w + b ) ⊗ ( x ∗ v + c ) f(x) = (x*w +b) otimes (x*v + c) f(x)=(x∗w+b)⊗(x∗v+c)
gtu: f ( x ) = t a n h ( x ∗ w + b ) ⊗ ( x ∗ v + c ) f(x) = tanh(x*w +b) otimes (x*v + c) f(x)=tanh(x∗w+b)⊗(x∗v+c)
其中,w,v,b,c都是可学习参数。
gelu
高斯误差线性单元,这种激活函数在激活中加入了随机正则的思想,是一种对神经元输入的概率描述。
x
P
(
X
≤
x
)
=
x
Φ
(
x
)
x P(X leq x)=x Phi(x)
xP(X≤x)=xΦ(x)
其中
Φ
(
x
)
Phi(x)
Φ(x) 指的是
x
x
x 的高斯正态分布的累计分布,完整形式如下:
x
P
(
X
≤
x
)
=
x
∫
−
∞
x
e
−
(
X
−
μ
)
2
2
σ
2
2
π
σ
d
X
x P(X leq x)=x int_{-infty}^{x} frac{e^{-frac{(X-mu)^{2}}{2 sigma^{2}}}}{sqrt{2 pi} sigma} mathrm{d} X
xP(X≤x)=x∫−∞x2πσe−2σ2(X−μ)2dX
计算结果约为:
0.5
x
(
1
+
tanh
[
2
π
(
x
+
0.044715
x
3
)
]
)
0.5 xleft(1+tanh left[sqrt{frac{2}{pi}}left(x+0.044715 x^{3}right)right]right)
0.5x(1+tanh[π2(x+0.044715x3)])
或者可以表示为:
x
∗
s
i
g
m
o
i
d
(
1.702
x
)
x * sigmoid(1.702 x)
x∗sigmoid(1.702x)
x作为神经元输入,x越大,激活输出x约有可能保留,x越小,越有可能激活结果为0.
gelu作为激活函数训练时,建议使用一个带动量的优化器
pytorch实现:
def gelu(x):
"""Implementation of the gelu activation function.
For information: OpenAI GPT's gelu is slightly different (and gives slightly different results):
0.5 * x * (1 + torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3))))
Also see https://arxiv.org/abs/1606.08415
"""
return x * 0.5 * (1.0 + torch.erf(x / math.sqrt(2.0)))
swish
f ( x ) = x ∗ s i g m o i d ( β x ) f(x) = x * sigmoid(beta x) f(x)=x∗sigmoid(βx)
β beta β是超参或者可学习的参数。
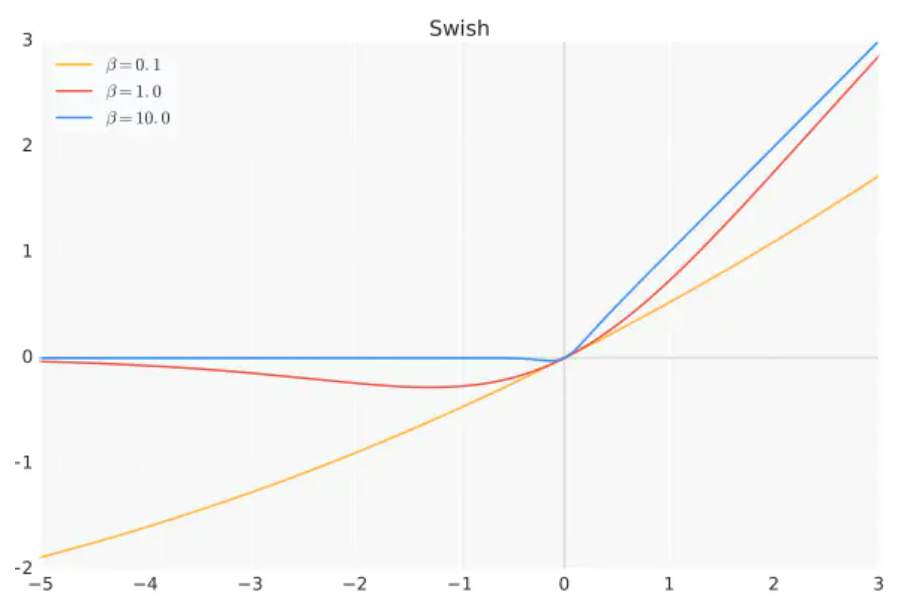
叫做自门控激活函数,从图像上看,swish函数和relu差不多,唯一区别较大的是接近于0的负半轴区域。swish在深层模型上的效果由于Relu
pytorch实现:
class Swish(torch.nn.Module):
"""Construct an Swish object."""
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Return Swish activation function."""
return x * torch.sigmoid(x)
激活函数使用原则
- 优先使用Relu,同时谨慎设置初值和学习率(实际中,如果learning rate很大,那么很可能网络中出现大量的dead relu,如果设置合适的较小的学习率,这个问题发生的情况不会太频繁。)
- 尝试使用leaky Relu / PRelu / Elu等激活函数
- 可以试下tanh,但一般不会有太好的结果
- 最后考虑使用sigmoid
各位读者老爷,求个赞,点个关注????
欢迎交流深度学习,语音识别,声纹识别等相关知识
最后
以上就是活泼香水最近收集整理的关于常用激活函数(relu,glu,gelu,swish等)的全部内容,更多相关常用激活函数(relu内容请搜索靠谱客的其他文章。

![[OPENGL]windows平台下使用OpenGL](https://www.shuijiaxian.com/files_image/reation/bcimg9.png)






发表评论 取消回复