RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation
原文:https://arxiv.org/pdf/2011.06294
摘要
提出了RIFE,一种用于视频插帧(Video Frame Interpolation, VFI)的实时中间流估计算法(Real-time Intermediate Flow Estimation)。近期的很多基于流的VFI方法,会先估算双向光流,然后通过拉伸和反转去近似中间流。在运动的边界容易产生失真。RIFE提出的IFNet神经网络可以由粗到精(coarse-to-fine)直接估算中间流,速度也更快。设计了一种特权蒸馏机制来训练中间流模型,可以大大提高性能。RIFE不依赖预训练的光流模型,可以支持任意时间步的插帧。实验表明RIFE在几个公开的测试基准上达到了最好。https://github.com/hzwer/arXiv2020-RIFE
1. 介绍
实时视频插帧由很多潜在的应用。比如:在计算资源不足的情况下,提高视频游戏或者视频播放的帧率;在播放设备上实时的观看高帧率视频。
近年来,基于流的VFI算法为解决复杂场景(如非线性大运动、亮度突变)的挑战提供了一种可行的框架,并表现较好。这种方法通常分为两步:
- 根据估算的光流对输入帧扭曲(warp)
- 用CNN对扭曲的帧融合与改善
给定两个输入帧,想要合成中间帧。需要先估算中间帧相对于输入帧的中间流。这是一个先有鸡还是先有蛋的难题,因为中间帧是未知的,而估算中间流又需要用到它。有很多人尝试用先进的光流模型先计算双向光流,然后逆转和精炼得到中间流。但是结果在运动边界容易导致失真。DVF提出了体素流(voxel flow),用CNN网络同时估算中间流和遮挡掩模(occlusion mask)。AdaCoF将中间流发展为自适应协作流(adaptive collaboration of flows)。BMBC设计了双侧损失体(bilateral cost volume)操作来获取更精确的中间流。
近年VFI相关的模型变的越来越复杂,这带来了两个问题:
- 增加了额外的组件:图像深度模型,流精炼模型和流逆转层等用来补偿中间流估算的错误。这些方法需要用到预训练的光流模型(不是专门用于VFI)。
- 缺乏对中间流的直接监督。
为了解决上述问题,采用了由粗到精策略,逐步增加精度:通过连续的IFBlocks迭代更新中间流和软融合掩模(soft fusion mask)。根据迭代更新的流场,可以将两个输入帧的像素点移动到同一个位置的隐中间帧,然后使用融合掩模合成像素。因为计算量小,IFNet可以部署到移动设备。
认为使用中间监督是很重要的。在使用最后的重建损失(reconstruction loss)端到端的训练IFNet时,结果比较差,因为光流估的不准。在使用了特权蒸馏机制之后有了很大的改善。这种机制使用一个可以获取中间帧的教师模型来指导学生学习。
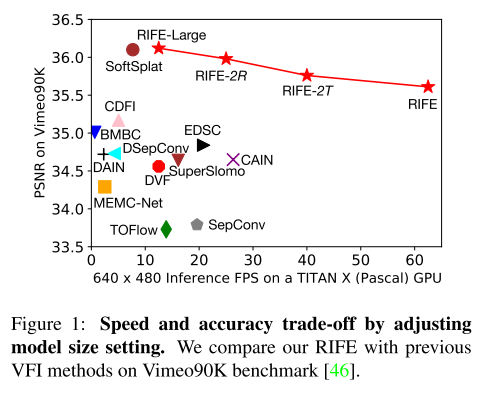
总结一下,我们的贡献有三个:
- 设计了一个有效的由粗到细的网络IFNet,使用简单的操作直接估算中间光流。通过使用模型缩放和测试时增强可以得到不同质量和速度权衡的RIFE模型,比较灵活。
- 使用特权蒸馏机制训练IFNet,大大提升了性能。
- 实验结果证明RIFE在几个公开测试基准上达到了最高水准。
2. 相关工作
光流估算
光流估算是一个比较老的视觉任务,用来估算每个像素点的运动,应用于很多下游任务。里程碑的工作FlowNet基于U-net自动编码。近年不断得到进化,比如:FlowNet2, PWC-Net, LiteFlowNet, RAFT. 无监督光流估算也是一个重要方向。
视频插帧
视频插帧可应用于慢动作合成,视频压缩和新视角合成。光流是近年流行的方法。除了一些直接合成光流的方法,SuperSlomo使用两个双向光流的线性组合作为中间流的初始近似,然后用U-Net求精。Reda 等.和Liu 等.提出使用循环一致性(cycle consistency)来改善中间帧。DAIN将中间流作为双向流的加权组合来估算。SoftSplat使用softmax splatting技术对帧和特征图forward-warp。QVI探索了使用四个连续帧和流逆转过滤器得到中间流。EQVI使用整流二次流(rectified quadratic flow)预测来改善QVI。
其他不是基于流的方法也取得了不错的成果。Meyer 等.使用相位信息(phase information)学习运动关系用于多视频帧插值。Niklaus 等.将VFI问题形式化为空间自适应卷积,卷积核通过输入帧的CNN得到。DSepConv在核方法基础上使用可变形分离卷积(deformable separable convolution),进一步提出了EDSC来做插帧。CAIN使用PixelShuffle操作和通道注视(channel attention)捕捉运动信息。此外,也有工作将视频插帧和超分放在一起去解决。
特权知识蒸馏
我们提出的特权蒸馏属于知识蒸馏范畴。知识蒸馏是用来将一个大模型的知识转移到小模型。在特权蒸馏时,老师模型比学生模型得到更多的输入,比如场景深度,其他相机视角的图片,甚至是图像注解。因此,老师模型可以提供更精确的表示来指导学生学习。这种方法也被用到其他计算机视觉任务中,比如图像超分,手姿态估计,重识别和视频风格转换。我们的工作和协同蒸馏也相关,就是老师和学生的架构一样,输入不同。
3. 方法
3.1 管线概览
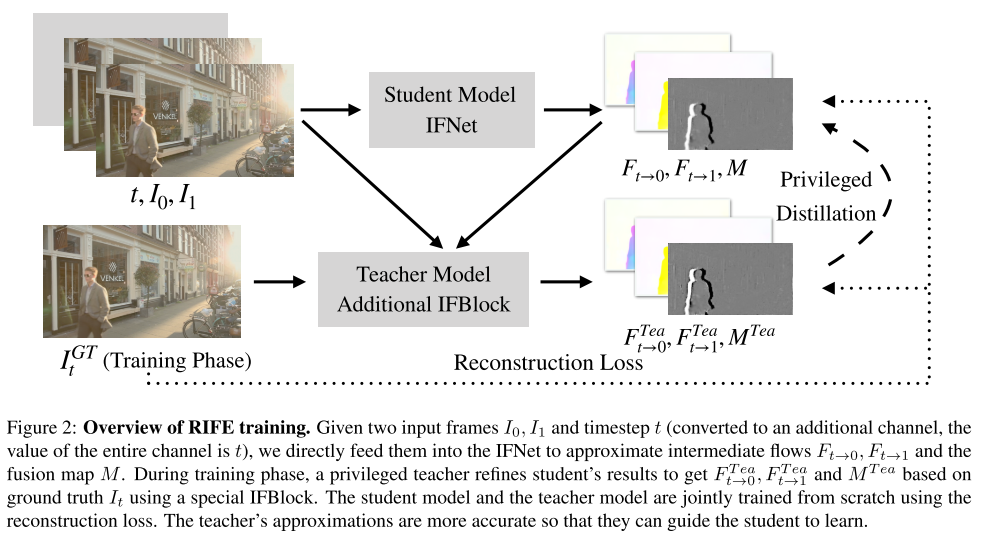
给定一对连续的RGB帧
I
0
,
I
1
I_0, I_1
I0,I1,和目标时间步
t
(
0
≤
t
≤
1
)
t(0leq tleq 1)
t(0≤t≤1),目标是合成中间帧
I
t
^
hat{I_t}
It^。为了估算中间流
F
t
→
0
,
F
t
→
1
F_{trightarrow 0},F_{trightarrow 1}
Ft→0,Ft→1和融合图
M
M
M,需要将输入帧和通道
t
t
t输入IFNet。然后根据下面的公式重建目标帧:
I
t
^
=
M
⊙
I
^
t
←
0
+
(
1
−
M
)
⊙
I
^
t
←
1
,
(
1
)
I
^
t
←
0
=
W
←
(
I
0
,
F
t
→
0
)
,
I
^
t
←
1
=
W
←
(
I
1
,
F
t
→
1
)
.
(
2
)
hat{I_t}=Modothat{I}_{tleftarrow 0}+(1-M)odothat{I}_{tleftarrow 1},quad(1)\ hat{I}_{tleftarrow 0}=overleftarrow{W}(I_0,F_{trightarrow 0}),quadhat{I}_{tleftarrow 1}=overleftarrow{W}(I_1,F_{trightarrow 1}).quad(2)
It^=M⊙I^t←0+(1−M)⊙I^t←1,(1)I^t←0=W(I0,Ft→0),I^t←1=W(I1,Ft→1).(2)
其中
W
←
overleftarrow{W}
W是图像向后warp,
⊙
odot
⊙是逐元素乘法符号,
(
0
≤
M
≤
1
)
(0leq M leq 1)
(0≤M≤1)。我们使用了另一个编解码CNN网络RefineNet改善高频区域和减少学生模型的失真。计算量和IFNet差不多。
3.2 中间流估算
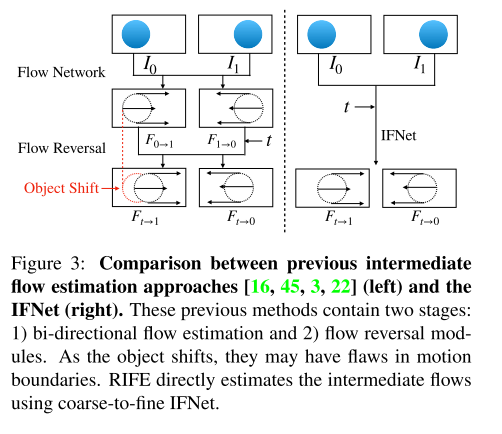
流逆转过程通常很麻烦,因为处理物体位置的改变很困难。IFNet可以直接估算中间光流,我们认为这是有效的。直观的说,以前的流逆转方法希望在光流场上做空间插值,这并不比对RGB图像做空间插帧简单。而IFNet可以直接高效的预测
F
t
→
0
,
F
t
→
1
F_{trightarrow 0,}F_{trightarrow 1}
Ft→0,Ft→1和融合图
M
M
M,当
t
=
0
,
或
t
=
1
t=0,或t=1
t=0,或t=1时,IFNet就是一个经典的双向光流模型。
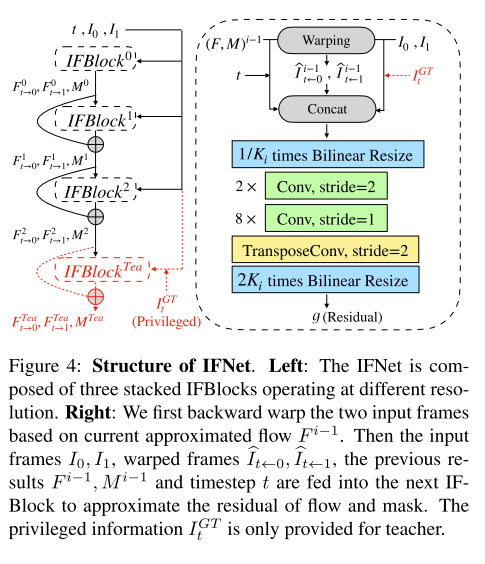
为了处理大运动场景,我们使用了由粗到精逐步增加分辨率的策略,见图四。具体的说,我们首先在低分辨率下计算一个比较粗的流预测结果,这使得更容易捕捉大运动,然后逐步增加分辨率来迭代求精流场(flow filed)。
(
F
,
M
)
i
=
(
F
,
M
)
i
−
1
+
g
i
(
F
i
−
1
,
M
i
−
1
,
t
,
I
^
i
−
1
)
,
(
3
)
(F,M)^i=(F,M)^{i-1}+g^i(F^{i-1},M^{i-1},t,hat{I}^{i-1}),quad(3)
(F,M)i=(F,M)i−1+gi(Fi−1,Mi−1,t,I^i−1),(3)
(
F
,
M
)
i
−
1
(F,M)^{i-1}
(F,M)i−1表示从第
(
i
−
1
)
(i-1)
(i−1)个IFBlock得到的当前中间流估算和融合图。我们一共使用了3个IFBlock,每个的分辨率参数时
K
i
,
K
=
(
4
,
2
,
1
)
K_i,K=(4,2,1)
Ki,K=(4,2,1)。在推理时,最终的估算结果是
(
F
,
M
)
2
(F,M)^2
(F,M)2。为了设计的简洁,每个IFBlock是由几个卷积层和一个上采样操作组成的前馈(feed-forward)结构。除了输出光流残差和融合图的层,都采用了PReLU激活函数。

RIFE中间流估算的运行时间比传统方法快6-15倍,见表一。虽然这些光流模型估算中间帧运动更精确,但并不一定适合直接移植到VFI任务。
3.3 IFNet特权蒸馏
直接逼近中间流是有挑战性的,因为拿不到中间帧,同时缺少监督。为了解决这个问题,我们为IFNet设计了特权蒸馏损失(privileged distillation loss)。在最后面又增加了一个IFBlock(老师模型
g
T
e
a
,
K
T
e
a
=
1
g^{Tea},K_{Tea}=1
gTea,KTea=1)来根据原始图片
I
t
G
T
I_t^{GT}
ItGT改善IFNet的结果。
(
F
,
M
)
T
e
a
=
(
F
,
M
)
2
+
g
T
e
a
(
F
2
,
M
2
,
t
,
I
2
^
,
I
t
G
T
)
.
(
4
)
(F,M)^{Tea}=(F,M)^2+g^{Tea}(F^2,M^2,t,hat{I^2},I_t^{GT}).quad(4)
(F,M)Tea=(F,M)2+gTea(F2,M2,t,I2^,ItGT).(4)
通过获取
I
t
G
T
I_t^{GT}
ItGT的特权信息,老师模型可以生成更精确的流。我们将蒸馏损失定义为:
L
d
i
s
=
∑
i
∈
{
0
,
1
}
∥
F
t
→
i
−
F
t
→
i
T
e
a
∥
.
(
5
)
L_{dis}=sum_{iin{{0,1}}}|F_{trightarrow i}-F_{trightarrow i}^{Tea}|.quad(5)
Ldis=i∈{0,1}∑∥Ft→i−Ft→iTea∥.(5)
蒸馏损失会应用于学生模型的整个迭代过程,而梯度损失不会反向传播给老师模型。老师模块会在训练结束后去掉。
3.4 实现细节
监督
损失函数定义:
L
=
L
r
e
c
+
L
r
e
c
T
e
a
+
λ
d
L
d
i
s
,
(
6
)
L
r
e
c
=
d
(
I
t
^
,
I
t
G
T
)
,
L
r
e
c
T
e
a
=
d
(
I
^
t
T
e
a
,
I
t
G
T
)
,
(
7
)
L=L_{rec}+L_{rec}^{Tea}+lambda_dL_{dis},quad(6)\ L_{rec}=d(hat{I_t},I_t^{GT}),L_{rec}^{Tea}=d(hat{I}_t^{Tea},I_t^{GT}),quad(7)
L=Lrec+LrecTea+λdLdis,(6)Lrec=d(It^,ItGT),LrecTea=d(I^tTea,ItGT),(7)
其中
λ
d
=
0.01
lambda_d=0.01
λd=0.01来平衡损失的尺度。重建损失
L
r
e
c
L_{rec}
Lrec代表中间帧重建的质量,定义为真实中间帧和生成的中间帧的
L
1
L_1
L1损失,用
d
d
d表示。我们还根据前人的工作,实验了用真实帧和重建帧的拉普拉斯金字塔表示的
L
1
L_1
L1损失代替普通的
L
1
L_1
L1损失,表示为
L
L
a
p
L_{Lap}
LLap。结果会稍微提升一点点。
训练数据集
使用Vimeo90K数据集训练RIFE。这个数据集有51,312个三元组,每个里面包含三张连续的大小为256 x 448的帧。我们对训练数据做了随机加强:水平或垂直翻转,时间序反转,旋转90度。
训练策略
固定时间 t = 0.5 t=0.5 t=0.5,优化算法AdamW(decay 1 0 − 4 10^{-4} 10−4),300 epochs,224 x 224 面片大小,批次大小64。学习率会用余弦退火(cosine annealing)从 3 × 1 0 − 4 3times10^{-4} 3×10−4降到 3 × 1 0 − 5 3times10^{-5} 3×10−5。使用四个TITAN X(pascal)GPU训练了15小时。
受前人工作启发,使用Vimeo90K-Septuple数据集对RIFE扩展支持任意时间步插值。这个数据集有91,701个序列,每个由大小256 x 448的7个连续帧组成。对每个训练样本,我们随机选取三帧 ( I n 0 , I n 1 , I n 2 ) (I_{n_0},I_{n_1},I_{n_2}) (In0,In1,In2)并计算目标时间步 t = ( n 1 − n 0 ) / ( n 2 − n 0 ) , 其 中 0 ≤ n 0 < n 1 < n 2 < 7 t=(n_1-n_0)/(n_2-n_0),其中0leq n_0<n_1<n_2<7 t=(n1−n0)/(n2−n0),其中0≤n0<n1<n2<7。其他训练设置不变,我们将这个模型记作 R I F E m RIFE_m RIFEm.
4. 实验
4.1 测试基准和度量标准
测试基准:
- Middlebury.这个数据集被广泛用于评价VFI方法。图像尺寸是640 x 480。在Middlebury-OTHER数据集上计算平均IE。
- Vimeo90K.有3,782个大小为448 x 256的三元组。
- UCF101.这个数据集大部分是人物运动。379个三元组,大小为256 x 256
- HD. Bao等人收集的11个高分辨率视频。包含四个1080p,三个720p和四个1280 x 544的视频。我们使用每个视频的前100帧测试。
用于定量评测的指标有三个:PSNR(peak signal-to-noise ratio) ,SSIM(structural similarity),IE(interpolation error)。测试机为TITAN X GPU。计算处理时间时,我们先跑100次预热,然后再跑100次求平均。
4.2 测试时间增强和模型缩放
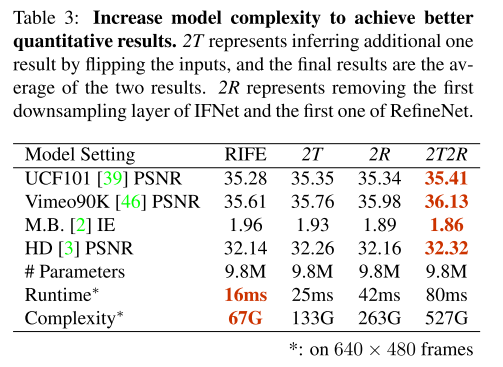
有两种修改模型的方法提供不同的计算量和满足不同需求:
- 水平和垂直翻转输入图片获取增强测试数据,推理得到结果后再反向翻转得到结果,再对结果求平均。效果类似于训练了一个通过增加卷积通道数使计算量增加为两倍的模型。表示RIFE-2T
- 去掉IFNet的第一个下采样层,然后在输出后面增加一个下采样层。对RefineNet也做了同样的修改。这样增大了特征图的处理分辨率。表示为RIFE-2R
- 前两个和在一起。表示为RIFE-Large(2T2R)
4.3 与前人工作比较
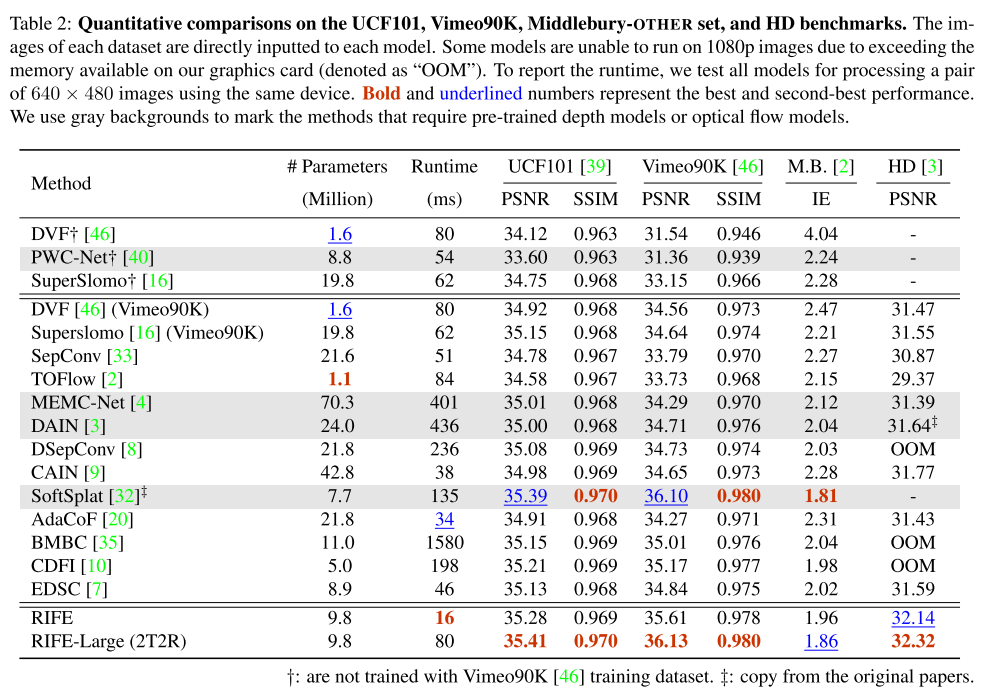
比较对象有:DVF, SuperSlomo, TOFlow, SepConv, MEMC-Net, DAIN, CAIN, SoftSplat, BMBC, DSepConv, AdaCoF, CDFI, EDSC, PWC-Net.除了SoftSplat没有开源直接引用原文的结果,其他都有官方开源代码。此外,使用我们的训练管线在Vimeo90K上训练了DVF和SuperSlomo。结果在表二。
未增强版的RIFE比其他模型都快,占用显存也小,1080p占用3.1GB,而有些方法要超过12GB。四个( b a t c h s i z e = 4 batchsize=4 batchsize=4)并行处理时时间减半。增强版的RIFE-Large比SoftSplat快0.7倍,得到的结果旗鼓相当,但是RIFE不需要特别设计的前warp操作或者依赖预训练的光流模型。

总体上,我们得到的结果更可靠。
4.4 模型简化测试( ablation studies)
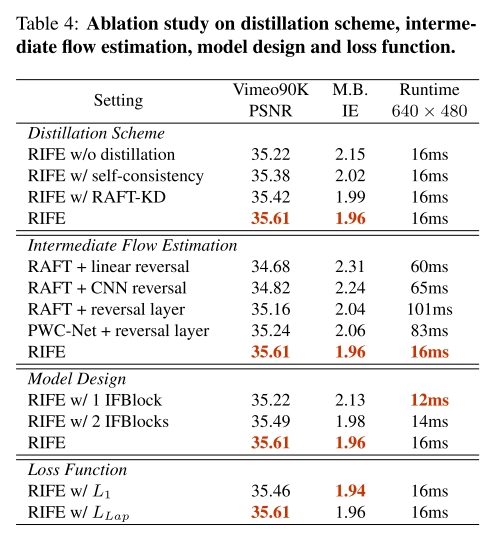
测试蒸馏策略
- 去除蒸馏后训练结果不稳定,性能下降。
- 去除特权老师模块,使用最后一个IFBlock的结果指导前两个IFBlock,性能下降。
- 使用预训练的RAFT和真实图片来估算中间流,性能下降。
IFNet vs. flow reversal
使用RAFT和PWC-Net官方预训练参数估算双向流。实现了三种流逆转方法,包括:线性逆转,使用有128通道的隐卷积层的CNN逆转,和EQVI里借鉴的方法。光流模型+流逆转模块,一起替换掉IFNet,然后和RefineNet一起训练。
RIFE的架构
分别去掉一个和两个IFBlock做实验。
损失函数
比较了 L 1 和 L L a p L_1和L_{Lap} L1和LLap
4.5 生成任意时间步帧

t
=
0.125
t=0.125
t=0.125没有在训练数据里,但是
R
I
F
E
m
RIFE_m
RIFEm也能很好处理。
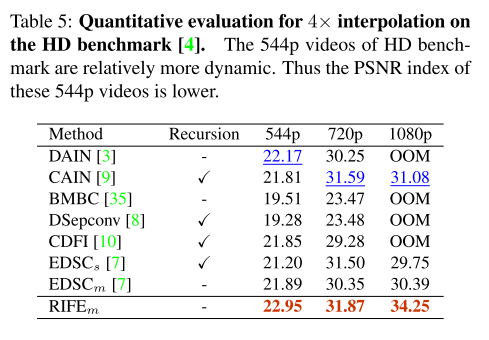
DAIN,BMBC和 E D S C m EDSC_m EDSCm可以直接生成任意时间步的帧,但是很多方法只能生成 t = 0.5 t=0.5 t=0.5的帧,需要递归生成4X结果。而 R I F E m RIFE_m RIFEm可以支持直接生成任意时间步的插帧。速度快,效果也好。
4.6 局限
可能没有覆盖实际应用的需求。
- RIFE只能处理输入两帧的情况,但是有工作称多帧输入是有用的。
- 有工作称PSNR和SSIM和人的视觉感受不一致。一种常用的方法是使用视觉上的损失LPIPS。
5. 总结
分析对比了当前基于流的VFI方法。开发了一种有效的灵活的VFI算法,称为RIFE。通过更精确的中间流估算,RIFE可以有效处理不同分辨率视频。将RIFE扩展到 R I F E m RIFE_m RIFEm来处理多帧插入。RIFE照亮了未来基于流的插帧方法研究的道路。
6. 附录
6.1 RefineNet架构
根据前人工作设计的RefineNet是一个类似于U-Net和上下文提取器(context extractor)的编解码框架。上下文提取和编码部分有类似的架构,包含四个卷积块,每个由两个3 x 3卷积层组成。FusionNet中的解码部分由四个转置卷积层。
具体说,上下文提取器首先从输入帧中提取金字塔上下文特征。金字塔上下文特征记作
C
0
:
{
C
0
0
,
C
0
1
,
C
0
2
,
C
0
3
}
,
C
1
:
{
C
1
0
,
C
1
1
,
C
1
2
,
C
1
3
}
C_0:{C_0^0,C_0^1,C_0^2,C_0^3},C_1:{C_1^0,C_1^1,C_1^2,C_1^3}
C0:{C00,C01,C02,C03},C1:{C10,C11,C12,C13}。然后使用估算的中间流对这些特征做后向warp操作,生成对齐的金字塔特征
C
t
←
0
,
C
t
←
1
C_{tleftarrow 0}, C_{tleftarrow 1}
Ct←0,Ct←1。将输入帧
I
0
,
I
1
I_0,I_1
I0,I1,warp过的帧
I
^
t
←
0
,
I
^
t
←
1
hat{I}_{tleftarrow 0},hat{I}_{tleftarrow1}
I^t←0,I^t←1,中间流
F
t
→
0
,
F
t
→
1
F_{trightarrow 0},F_{trightarrow 1}
Ft→0,Ft→1和融合掩模M喂给编码器。第
i
i
i个编码块的输出和
C
t
←
0
i
,
C
t
←
1
i
C_{tleftarrow 0}^i,C_{tleftarrow 1}^i
Ct←0i,Ct←1i结合在一起喂给下个块。编码部分最后生成一个重建残差
Δ
Delta
Δ。最后得到改进后的重建图片
c
l
a
m
p
(
I
t
^
+
Δ
,
0
,
1
)
clamp(hat{I_t}+Delta,0,1)
clamp(It^+Δ,0,1),其中
I
t
^
hat{I_t}
It^是RefineNet之前重建的图片。RefineNet貌似会使某些不确定的区域更糊来提升结果。
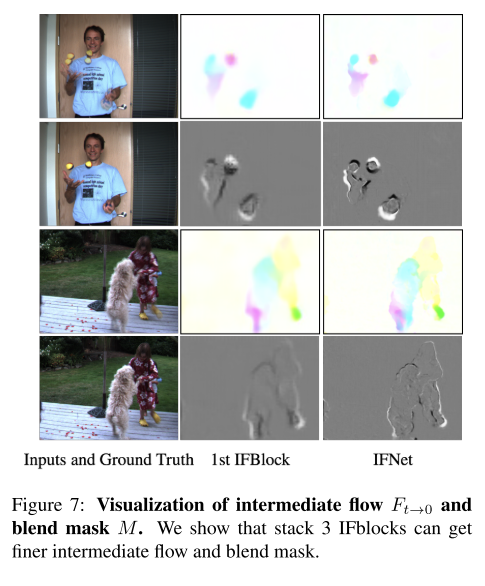
图七:中间流
F
t
→
0
F_{trightarrow 0}
Ft→0和混合掩模
M
M
M的可视化效果

6.2 中间流可视化

IFNet可以生成清晰的运动边界。
6.3 训练动态
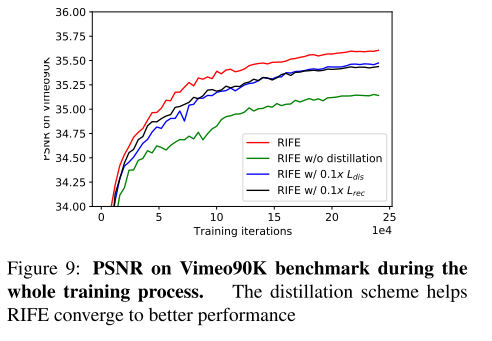
特权蒸馏机制可以帮助RIFE收敛到更好的结果。比较大的权重(10x)可能导致不收敛,比较小的权重(0.1x)可能导致更差的结果。
6.4 模型效率比较
遗憾的是现在大部分论文都没测试性能和模型复杂度,或者就算测了也没说机器配置。我们开了个好头,汇报一下在NVIDIA TITAN X 上做的测试。
参考文献
根据参考文献在文章中的引用进行了简单的分类,并加上文章下载链接和被引用次数(截止到11/11/2021)。比较值得关注的几篇论文:
- Distilling the knowledge in a neural network。关于知识蒸馏的7K+引用。
- Flownet:Learning optical flow with convolutional networks,Flownet 2.0: Evolution of optical flow estimation with deep networks。关于光流估算的两篇都是2K+引用。
基于流的插帧方法
- Ziwei Liu, Raymond A Yeh, Xiaoou Tang, Yiming Liu, andAseem Agarwala. Video frame synthesis using deep voxelflow. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. Cited by 487.
- Huaizu Jiang, Deqing Sun, Varun Jampani, Ming-HsuanYang, Erik Learned-Miller, and Jan Kautz. Super slomo:High quality estimation of multiple intermediate frames forvideo interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. Cited by 335.
- Simon Niklaus and Feng Liu. Context-aware synthesis forvideo frame interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2018. Cited by 208.
- Tianfan Xue, Baian Chen, Jiajun Wu, Donglai Wei, and William T Freeman. Video enhancement with task-oriented flow. In International Journal of Computer Vision (IJCV),2019. Cited by 372.
- Wenbo Bao, Wei-Sheng Lai, Chao Ma, Xiaoyun Zhang, Zhiyong Gao, and Ming-Hsuan Yang. Depth-aware video frame interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019. Cited by 187.
- Xiangyu Xu, Li Siyao, Wenxiu Sun, Qian Yin, and Ming-Hsuan Yang. Quadratic video interpolation. In Advances in Neural Information Processing Systems (NIPS), 2019. Cited by 46.
- Wonkyung Lee, Junghyup Lee, Dohyung Kim, and BumsubHam. Learning with privileged information for efficient image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), 2020. Cited by 27.
- Junheum Park, Keunsoo Ko, Chul Lee, and Chang-Su Kim.Bmbc: Bilateral motion estimation with bilateral cost vol-ume for video interpolation. In Proceedings of the European Conference on Computer Vision (ECCV), 2020. Cited by 25.
- Hyeongmin Lee, Taeoh Kim, Tae-young Chung, DaehyunPak, Yuseok Ban, and Sangyoun Lee. Adacof: Adaptive collaboration of flows for video frame interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020. Cited by 39.
- Junheum Park, Keunsoo Ko, Chul Lee, and Chang-Su Kim. Bmbc: Bilateral motion estimation with bilateral cost vol-ume for video interpolation. In Proceedings of the European Conference on Computer Vision (ECCV), 2020. Cited by 25.
- Fitsum A Reda, Deqing Sun, Aysegul Dundar, MohammadShoeybi, Guilin Liu, Kevin J Shih, Andrew Tao, Jan Kautz,and Bryan Catanzaro. Unsupervised video interpolation using cycle consistency. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019. Cited by 27.
- Yu-Lun Liu, Yi-Tung Liao, Yen-Yu Lin, and Yung-YuChuang. Deep video frame interpolation using cyclic frame generation. In AAAI Conference on Artificial Intelligence,2019. Cited by 88.
- Tarun Kalluri, Deepak Pathak, Manmohan Chandraker, and Du Tran. Flavr: Flow-agnostic video representations for fast frame interpolation. arXiv preprint arXiv:2012.08512, 2020. Cited by 4.
非流插帧方法
- Simone Meyer, Oliver Wang, Henning Zimmer, Max Grosse,and Alexander Sorkine-Hornung. Phase-based frame interpolation for video. In Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR), 2015. Cited by 198.
- Simone Meyer, Abdelaziz Djelouah, Brian McWilliams,Alexander Sorkine-Hornung, Markus Gross, and Christo-pher Schroers. Phasenet for video frame interpolation. In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition (CVPR), 2018. Cited by 93.
- Simon Niklaus, Long Mai, and Feng Liu. Video frame interpolation via adaptive convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. Cited by 288.
- Simon Niklaus, Long Mai, and Feng Liu. Video frame interpolation via adaptive separable convolution. In Proceedings of the IEEE International Conference on Computer Vision(ICCV), 2017. Cited by 404.
- Xianhang Cheng and Zhenzhong Chen. Multiple video frame interpolation via enhanced deformable separable convolution. arXiv preprint arXiv:2006.08070, 2020. Cited by 7.
- Xianhang Cheng and Zhenzhong Chen. Video frame interpolation via deformable separable convolution. In AAAI Conference on Artificial Intelligence, 2020. Cited by 17.
- Myungsub Choi, Heewon Kim, Bohyung Han, Ning Xu, and Kyoung Mu Lee. Channel attention is all you need for video frame interpolation. In AAAI Conference on Artificial Intelligence, 2020. Cited by 37.
- Wenbo Bao, Wei-Sheng Lai, Xiaoyun Zhang, Zhiyong Gao,and Ming-Hsuan Yang. Memc-net: Motion estimation and motion compensation driven neural network for video interpolation and enhancement. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2018. Cited by 121.
- Tianyu Ding, Luming Liang, Zhihui Zhu, and Ilya Zharkov. Cdfi: Compression-driven network design for frame interpolation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. Cited by 5.
光流估算
- Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper,Alexey Dosovitskiy, and Thomas Brox. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017. Cited by 2035.
- Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, PhilipHausser, Caner Hazirbas, Vladimir Golkov, Patrick VanDer Smagt, Daniel Cremers, and Thomas Brox. Flownet:Learning optical flow with convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2015. Cited by 2412.
- Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz. Pwc-net: Cnns for optical flow using pyramid, warping, andcost volume. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. Cited by 1119.
- Tak-Wai Hui, Xiaoou Tang, and Chen Change Loy. Lite-flownet: A lightweight convolutional neural network for optical flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. Cited by 376.
- Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In Proceedings of the European Conference on Computer Vision (ECCV), 2020. Cited by 213.
无监督光流
- Simon Meister, Junhwa Hur, and Stefan Roth. UnFlow: Unsupervised learning of optical flow with a bidirectional census loss. In AAAI Conference on Artificial Intelligence, 2018. Cited by 306.
- Rico Jonschkowski, Austin Stone, Jonathan T Barron, ArielGordon, Kurt Konolige, and Anelia Angelova. What matters in unsupervised optical flow. In Proceedings of the European Conference on Computer Vision (ECCV), 2020. Cited by 33.
- Kunming Luo, Chuan Wang, Shuaicheng Liu, Haoqiang Fan,Jue Wang, and Jian Sun. Upflow: Upsampling pyramid for unsupervised optical flow learning. In Proceedings of theIEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. Cited by 2.
视频压缩应用
- Chao-Yuan Wu, Nayan Singhal, and Philipp Krahenbuhl. Video compression through image interpolation. In Proceedings of the European Conference on Computer Vision(ECCV), 2018. Cited by 149.
插帧+超分
- Xiaoyu Xiang, Yapeng Tian, Yulun Zhang, Yun Fu, Jan PAllebach, and Chenliang Xu. Zooming slow-mo: Fast and accurate one-stage space-time video super-resolution.In Proceedings of the IEEE Conference on Computer Visionand Pattern Recognition (CVPR), 2020. Cited by 43.
- Gang Xu, Jun Xu, Zhen Li, Liang Wang, Xing Sun, andMing-Ming Cheng. Temporal modulation network for controllable space-time video super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. Cited by 1.
特权知识蒸馏
- David Lopez-Paz, L ́eon Bottou, Bernhard Sch ̈olkopf, and Vladimir Vapnik. Unifying distillation and privileged information. In Proceedings of the International Conference on Learning Representations (ICLR), 2016. Cited by 310.
- Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. Cited by 7865.
- Wonkyung Lee, Junghyup Lee, Dohyung Kim, and BumsubHam. Learning with privileged information for efficient image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV), 2020. Cited by 27.
- Shanxin Yuan, Bjorn Stenger, and Tae-Kyun Kim. Rgb-based 3d hand pose estimation via privileged learning with depth images. In Proceedings of the IEEE International Conference on Computer Vision Workshop (ICCVW), 2019. Cited by 13.
- Angelo Porrello, Luca Bergamini, and Simone Calderara. Robust reidentification by multiple views knowledge distillation. In Proceedings of the European Conference on Computer Vision (ECCV), 2020. Cited by 17.
- Xinghao Chen, Yiman Zhang, Yunhe Wang, Han Shu, Chun-jing Xu, and Chang Xu. Optical flow distillation: Towards efficient and stable video style transfer. In Proceedings of the European Conference on Computer Vision (ECCV), 2020. Cited by 14.
- Rohan Anil, Gabriel Pereyra, Alexandre Passos, Robert Or-mandi, George E Dahl, and Geoffrey E Hinton. Large scale distributed neural network training through online distillation. In Proceedings of the International Conference on Learning Representations (ICLR), 2018. Cited by 225.
激活函数: PReLU
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV),2015. Cited by 13624.
优化器: AdamW
- Ilya Loshchilov and F. Hutter. Fixing weight decay regularization in adam. arXiv preprint arXiv:1711.05101, 2017. Cited by 440.
数据集
- 【HD】 Wenbo Bao, Wei-Sheng Lai, Chao Ma, Xiaoyun Zhang,Zhiyong Gao, and Ming-Hsuan Yang. Depth-aware video frame interpolation. In Proceedings of the IEEE Conferenceon Computer Vision and Pattern Recognition (CVPR), 2019。
- 【UCF101】Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah.Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012。
- 【Vimeo90K】Tianfan Xue, Baian Chen, Jiajun Wu, Donglai Wei, and William T Freeman. Video enhancement with task-oriented flow. In International Journal of Computer Vision (IJCV),2019
- 【M.B】Simon Baker, Daniel Scharstein, JP Lewis, Stefan Roth,Michael J Black, and Richard Szeliski. A database and evaluation methodology for optical flow. In International Journalof Computer Vision (IJCV), 2011
最后
以上就是独特柠檬最近收集整理的关于RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation——精读笔记RIFE: Real-Time Intermediate Flow Estimation for Video Frame Interpolation的全部内容,更多相关RIFE:内容请搜索靠谱客的其他文章。








发表评论 取消回复