阻塞(Block)和非阻塞(Non-Block)
阻塞和非阻塞是进程在访问数据的时候,数据是否准备就绪的一种处理方式,当数据没有准备的时候。
**阻塞:**往往需要等待缓冲区中的数据准备好过后才处理其他的事情,否者一直等待在那里
**非阻塞:**当我们进程访问我们的数据缓冲区的时候,如果数据没有准备好则直接返回,不会等待。如果数据已经准备好,也直接返回。
同步(Synchronization)和异步(Asynchronous)
同步和异步都是基于应用程序和操作系统处理IO事件所采用的方式。比如同步:是应用程序要直接参与IO读写的操作。异步:所有的IO读写交给操作系统去处理,应用程序只需要等待通知。
同步方式在处理IO事件的时候,必须阻塞在某个方法上面等待我们的IO事件完成(阻塞IO事件或者通过轮询IO事件的方式),对于异步来说,所有的IO读写都交给了操作系统。这个时候,我们可以去做其他的事情,并不需要去完成真正的IO操作,当操作完成iO后,会给我们的应用程序一个通知。
**同步:**阻塞到IO事件,阻塞到read或者write。这个时候我们就完全不能做自己的事情。让读写方法加入到线程里面,然后阻塞线程来实现,对线程的性能开销比较大。
BIO与NIO对比
| IO模型 | BIO | NIO |
|---|---|---|
| 通信 | 面向流(乡村公路) | 面向缓冲(高速公路,多路复用技术) |
| 处理 | 阻塞IO(多线程) | 非阻塞IO(反应堆Reactor) |
| 触发 | 无 | 选择器 轮询机制 |
面向流与面向缓冲
java NIO和BIO之间第一个最大的区别是,BIO是面向流的,NIO是面向缓冲的。Java BIO面向流意味着每次从流中读一个或多个字节,直至读取所有的字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否缓冲区包含了所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
阻塞与非阻塞
Java BIO的各种流是阻塞的。这意味着,当一个线程调用read()和write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么多不会获取。而不是保持线程阻塞,所以直至数据变得可以读取之前,该线程可以继续做其他的事情。
非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。线程通常将非阻塞IO的空闲时间用于在其他通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道。
选择器的问世
java NIO的选择器(Selector)允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道,这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
Java NIO三件套
在NIO中有几个核心对象需要掌握:缓冲器(Buffer)、选择器(Selector)、通道(Channel)
缓冲区Buffer
缓冲区实际上是一个容器对象,更直接的说,其实就是一个数组,在NIO库中,所有数据都是用缓冲区出来的。在读取数据时,它是直接读到缓冲区的;在写入数据时,它也是写入到缓冲区的;任何时候访问NIO中的数据,都是将它放到缓冲区中。而在面向流I/O系统中,所有数据都是直接写入或者直接将数据读取到Stream对象中。
在NIO中,所有的缓冲区类型都继承于抽象类Buffer,最常用的就是ByteBuffer,对于java中的基本类型,基本都有一个具体Buffer类型与之相对于,他们之间的extend关系如下图所示。

eg:
public static void main(String[] args) {
//new NIOServerDemo(8080).listen();
// 分配新的 int 缓冲区,参数为缓冲区容量
// 新缓冲区的当前位置将为零,其界限(限制位置)将为其容量。它将具有一个底层实现数组,其数组偏移量将为零。
IntBuffer buffer = IntBuffer.allocate(8);
for (int i = 0; i < buffer.capacity(); ++i) {
int j = 2 * (i + 1);
// 将给定整数写入此缓冲区的当前位置,当前位置递增
buffer.put(j);
}
// 重设此缓冲区,将限制设置为当前位置,然后将当前位置设置为 0
buffer.flip();
// 查看在当前位置和限制位置之间是否有元素
while (buffer.hasRemaining()) {
// 读取此缓冲区当前位置的整数,然后当前位置递增
int j = buffer.get();
System.out.print(j + " ");
}
}
2 4 6 8 10 12 14 16
Process finished with exit code 0
Buffer的基本的原理
在谈到缓冲区时,我们说缓冲区对象本质上是一个数组,但它其实是一个特殊的数组,缓冲区对象内置了一些机制,能够跟踪和记录缓冲区的状态变化情况。如果我们使用get()方法从缓冲区获取数据或者使用put()方法把数据写入缓冲区,都会引起缓冲区状态的变化。
在缓冲区中,最重要的属性有下面三个,它们一起合作完成对缓冲区内部的状态的变化跟踪。
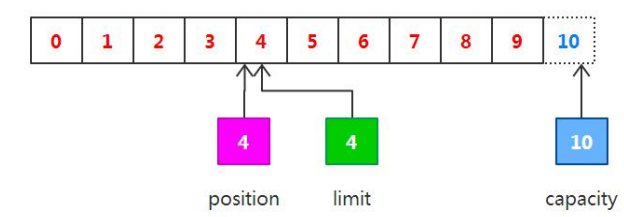
position: 指定下一个将要被写入或者读取的元素索引,它的值由get()/put()方法自动更新,在新创建一个Buffer对象时,position被初始化为0.
limit:指定还有多少数据需要取出(在从缓冲区写入通道时),或者还有多少空间可以放入数据(在从通道读入缓冲区时)
**capacity:**制定了可以存储在缓冲区中的最大数据容量,实际上,它制定了底层数组的大小,或者至少是指定了准许我们使用的底层数组的容量。
以上三个属性值之间有一些相对大小的关系: 0<=positon<=limit<=capacity。如果我们创建一个新的容量大小为10的ByteBuffer对象,在初始化的时候,positon设置为0,limit和capacity被设置为10,在以后使用ByteBuffer对象过程中,capacity的值不会再发生变化,而其他两个将会随着使用而变化。
eg:
package com.evan.netty.nio.demo;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.nio.Buffer;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* @author evanYang
* @version 1.0
* @date 2021/7/26 11:29
*/
public class BufferDemo {
public static void main(String[] args) throws IOException {
FileInputStream fin = new FileInputStream("D://evan.txt");
FileChannel fc = fin.getChannel();
//先分配一个10大小的缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
outPut("初始化",buffer);
fc.read(buffer);
outPut("调用read()方法",buffer);
buffer.flip();
outPut("调用flip()",buffer);
//判断有没有可读数据
while (buffer.remaining()>0){
byte b = buffer.get();
}
outPut("调用get()",buffer);
//可以理解为解锁
buffer.clear();
outPut("调用clear()",buffer);
fin.close();
}
/**
* 打印缓存实时状况
* @param step
* @param buffer
*/
public static void outPut(String step, Buffer buffer){
System.out.println(step+":");
System.out.println("capacity: "+buffer.capacity()+",");
System.out.println("position: "+buffer.position()+",");
System.out.println("limit: "+buffer.limit());
System.out.println();
}
}
文件中的数据

输出结果:
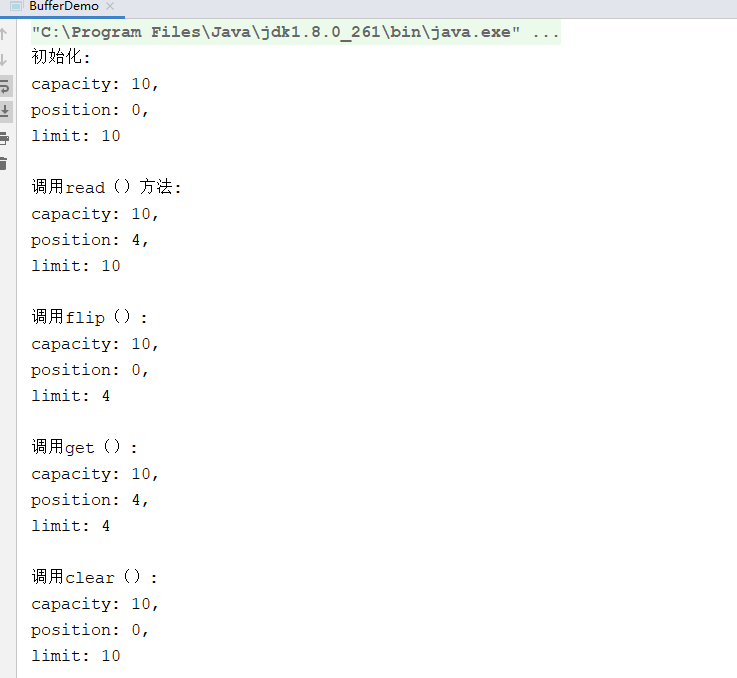
运行结果我们已经可以知道,四个属性值分别如图所示:
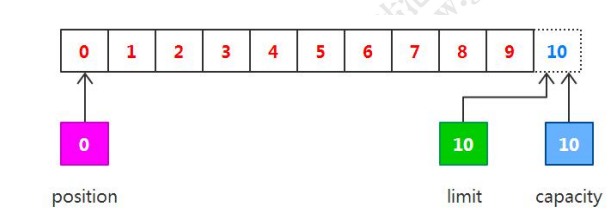
我们可以从管道中读取一些数据到缓冲区,注意从通道读取数据,相当于往缓冲区写入数据。如果读取4个自己的数据,则此时position的值为4,即下一个将要被下入的字节索引是4,而limit仍然是10,如下图所示:
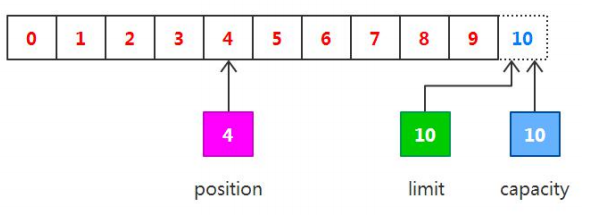
下一步把读取的数据写入到输出管道中,相当于从缓冲区中读取数据,在此之前,必须调用flip()方法,该方法将会完成两件事:
1,把limit设置为当前的positon值
2,把position设置为0
由于position被设置为0,所以可以保证在下一步输出时读取到的是缓冲区中的第一个字节,而limit被设置为当前的position,可以保证读取的数据正好是之前写入到缓冲区的数据,如下图所示。
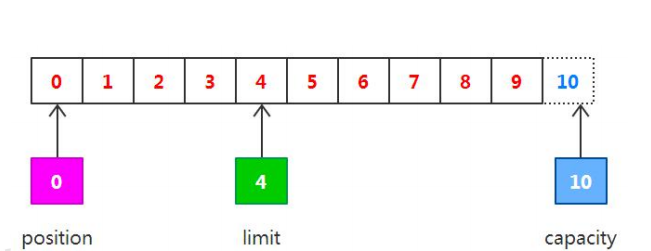
现在调用get()方法从缓冲区读取数据写入到输出通道,这会导致position的增加而limit保持不变,单position不会超过limit的值,所以在读取我们之前写入到缓冲区中的4个自己之后,position和limit的值都为4.如下图所示。
在从缓冲区读取数据完毕后,limit的值仍然保持在我们调用flip()方法时的值,调用clean()方法能够把所有的状态设置为初始值。
缓冲区分配
在前面的几个例子中,我们已经看过了,在创建一个缓冲对象时,会调用静态方法allocate()来指定缓冲区的容量,其实调用allocate()相当于创建一个指定大小的数组,并把它包装为缓冲区对象。或者我们也可以直接将一个现有的数组,包装为缓冲区对对象
选择器Selector
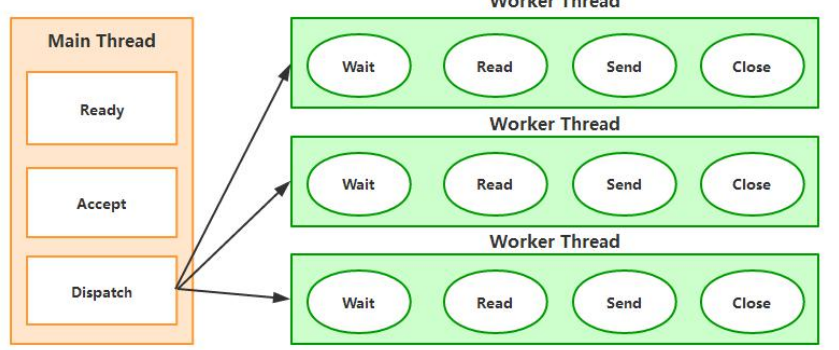
传统的Server/Client 模式会基于TPR(Thread per Request),服务器会为每个客户端请求建立一个线程,由该线程单独负责处理一个客户请求。这种模式带来的一个问题就是线程数量的剧增,大量的线程会增大服务器的开销。大多数的实现为了避免这个问题,都采用了线程池模型,并设置线程池模型的最大数量,这又带来了新的问题,如果线程池中有200个线程,而有200个用户都在进行大文件下载,会导致第201个用户的请求无法及时处理,即便第201个用户只想请求一个几kb大小的页面。传统的Server/Client模式如下图所示。
NIO 中非阻塞I/O采用了基于Reactor模式的工作模式,I/O调用不会被阻塞,相反是注册感兴趣的特定I/O事件,如可读数据到达,新的套接字连接等等,在发生特定事件时,系统在通知我们。NIO中实现非阻塞I/O的核心对象就是Selector,Selector就是注册各种I/O事件地方,而且当那些事件发生时,就是这个对象告诉我们所发生的事件。如下图所示。
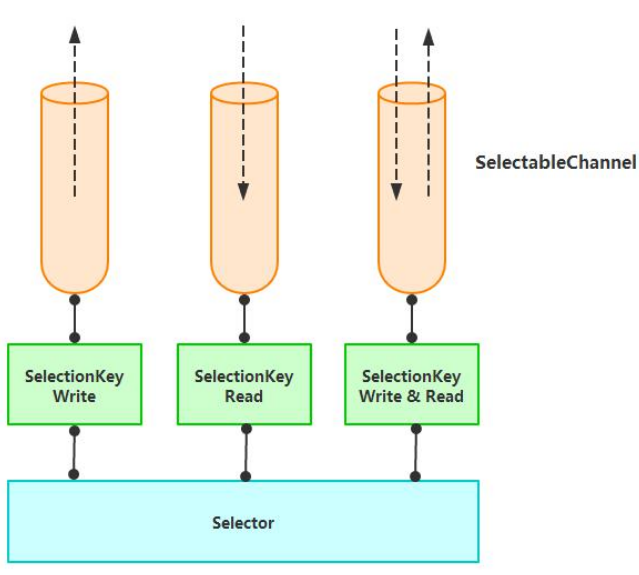
从图中可以看出,当有读或写等任何注册的时间发生时,可以从Selector中获得相应的SelectionKey,同时从SelectionKey中可以找到发生的事件和该事件所发生的具体SelectableChannel,以获得客户端发送过来的数据。
使用NIO中非阻塞I/O编写服务器处理程序,大体上可以分为下面三个步骤:
1,向Selector对象注册感兴趣的事件。
2,从Selector中获取感兴趣的事件。
3,根据不同的事件进行相应的处理。
通道Channel
通道是一个对象,通过它可以读取和写入数据,当然了所有数据都通过Buffer对象来处理。我们永远不会将字节直接写入通道中,相反是将数据写入包含一个或者多个字节的缓存区。同样不会直接从通道中读取字节,而是将数据从通道读入缓存区,再从缓冲区获取这个字节,而是将数据从通道读入缓冲区,再从缓冲区获取这个字节。
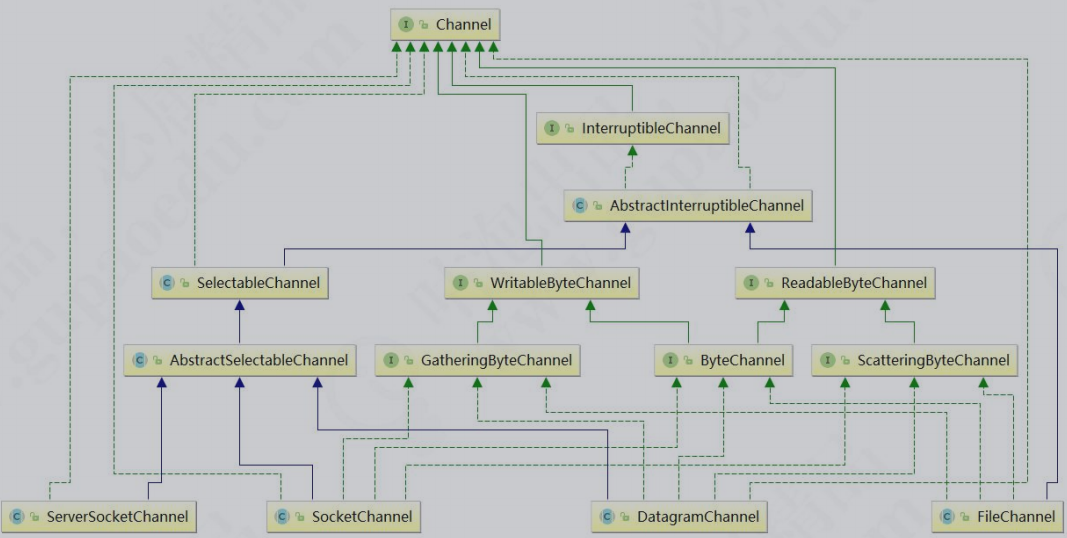
在NIO中,提供了多种通道对象,而所有的通道对象都实现了Channel接口。它们之间的继承关系如下图所示:
使用NIO读取数据
在前面我们说过,任何时候读取数据,都不是直接从通道读取,而是从通道读取到缓冲区。所以使用NIO读取数据可以分为下面三个步骤:
1,从FileInputStream获取Channel
2,创建Buffer
3,将数据从Channel读取到Buffer中
package com.evan.netty.nio.demo;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.nio.Buffer;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* @author evanYang
* @version 1.0
* @date 2021/7/26 16:15
*/
public class FileInputDemo {
public static void main(String[] args) throws IOException {
FileInputStream fin=new FileInputStream("D://evan.txt");
FileChannel channel = fin.getChannel();
ByteBuffer allocate = ByteBuffer.allocate(1024);
//读取数据到缓冲区
channel.read(allocate);
allocate.flip();
while (allocate.remaining()>0){
byte b = allocate.get();
System.out.println(b);
}
fin.close();
}
}
使用NIO写入数据
使用NIO写入数据与读取数据的过程类似,同样数据不是直接写入通道,而是写入缓冲区,可以分为下面三个步骤:
1,从FileputStream获取channel。
2,创建Buffer
3,将数据从Channel写入到Buffer中,
package com.evan.netty.nio.demo;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
/**
* @author evanYang
* @version 1.0
* @date 2021/7/26 16:33
*/
public class FileOutPutDemo {
static private final byte message[] ={83, 111, 109, 101, 32, 98, 121, 116, 101, 115, 46 };
public static void main(String[] args) throws IOException {
FileOutputStream fout=new FileOutputStream("D://evan.txt");
FileChannel channel = fout.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
for (int i = 0; i < message.length; i++) {
buffer.put(message[i]);
}
buffer.flip();
channel.write(buffer);
fout.close();
}
}
IO多路复用
我们试想一下这样的现实场景。
100桌客人到店点菜
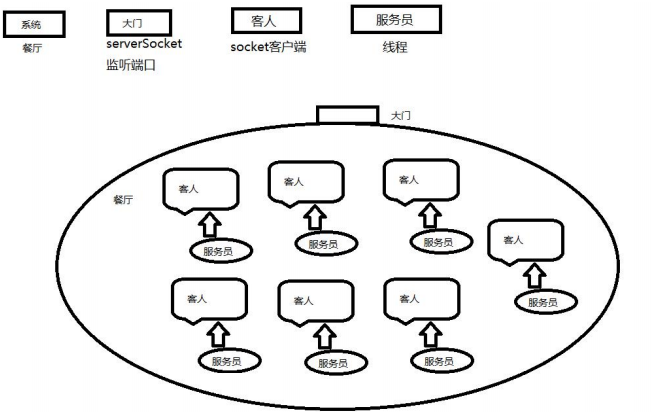
方法A:
服务员都把仅有的一份菜单递给其中一桌客人,然后站在这个客人身旁等待客人完成点菜过程。。。。。
方法B:
老板马上新雇佣99名服务员,同时印制99本新的菜单。没人服务一桌客人。
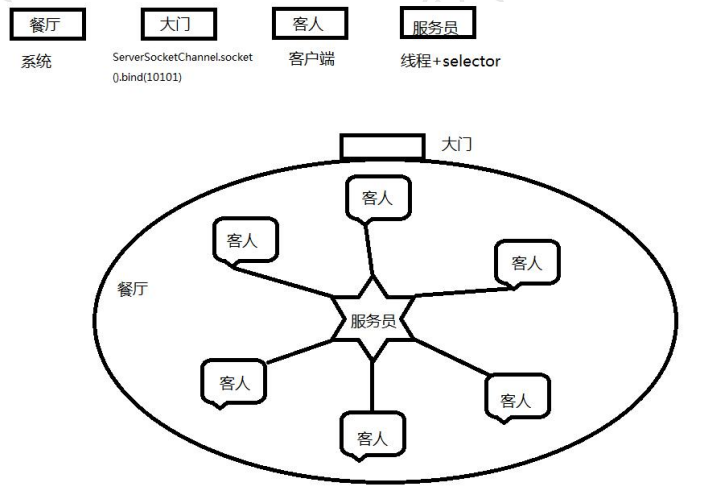
方法C:
改进点菜的方式,当客人到店后,自己申请一本菜单。想好自己要点的菜,然后呼叫服务员。服务员站在自己身边记录客人点的菜的内容。
- 到店情况 :并发量
到店情况不理想时,一个服务员一本菜单,就足够了 - 客人:服务端请求
- 点餐内容:客服端发送的实际数据
- 老板:操作系统
- 人力成本:系统资源
- 菜单:文件状态描述符(FD)。操作系统对于一个进程能够同时持有的文件状态描述符的个数是有限制的,在linux系统中,$Ulimit -n 查看这个限制值,当然也是可以(并且应该)进行内核参数调整的
- 服务员:操作系统内核用于IO操作的线程(内核线程)
- 厨师:应用程序线程(当然厨房就是应用程序进程)
方法A:同步IO
方法B:同步IO
方法C:多路复用IO
最后
以上就是朴实太阳最近收集整理的关于Java IO演进之路阻塞(Block)和非阻塞(Non-Block)同步(Synchronization)和异步(Asynchronous)BIO与NIO对比Java NIO三件套选择器Selector通道ChannelIO多路复用的全部内容,更多相关Java内容请搜索靠谱客的其他文章。








发表评论 取消回复