问题背景
工程造价属于工程行业的一个分支,主要确定一个工程的造价构成,通过算量和计价软件,生成一个工程的详细造价构成。
造价清单,是构成造价的最小元素。一条清单的重要文本包含清单名称、清单特征、套用的N条定额。N条定额中包含详细材料列表。名称(简称A)、特征(简称B)、材料(简称C)被称为清单的三个要素,简称为清单三要素。
一个总造价几个亿的工程,通常由几千条清单构成,造价工程师需要很长的时间来完成这份造价。由于清单数量众多,经常发生清单三要素不一致的人为错误。例如A中写的是“商品混凝土C30”,B中写的却是“砼C25”,C中用的却是“预制混凝土C20”。
下面是一个实际的例子:
清单名称:120066020仿爵士白大理石光面干挂
清单特征:(多行文本)
1.墙体类型:混凝土墙体
2.安装方式:干挂
3.面层材料品种、规格、颜色:1200X550X20仿爵士白大理石光面干挂
4.干挂龙骨材料、规格:M6,316不锈钢石材背栓、4mm厚铝合金石材挂件、50X50X5镀锌角钢、80X60X5镀锌钢方管
5.缝宽、嵌缝材料种类:满足设计及规范要求
6.防护材料种类:满足设计及规范要求
7.磨光、酸洗、打蜡要求:满足设计及规范要求 [工作内容]1.基层清理 2.砂浆制作、运输 3.粘结层铺贴 4.龙骨安装 5.面层安装 6.嵌缝 7.刷防护材料 8.磨光、酸洗、打蜡
可以看到名称中的120066020和特征中的1200X550X20是不一致的!
这样的不一致性错误,往往会导致总造价出错,或者投标时废标,因此该行业非常重视清单三要素的复核检查,目前是通过项目经理、加总工、甚至要加上总经理来层层review以确保最终清单的正确性。(有木有感觉像是初级工程师写的code让高级工程师review,再让leader来review,再让CTO来review的感脚?)
看上去,这是一个典型的自然语言问题,于是我们开始尝试,是否可以用NLP技术来解决该行业的这个问题。相信最终研究出的这套解决方案,对于其它行业的文本问题,也会有极大意义的参考价值。
我们的想法
我们希望通过csdn详细记录攻克这项难题的完整过程,包含犯下的错误和走过的弯路,可以为其他行业正在进行NLP工程研究的同行提供有价值的参考。
商业化NLP工程与科研项目不同,需要找到并形成正确的方法论、最佳的技术、合理的工作流程、快速有效的验证方式、可靠的自动化测试方案、健壮稳定的产品化结果、持续高效的机器学习方案等多方面、系统性的成果。整体系统工程的过程和每个环节的成果,都对类似问题的其它行业有很大的启示。
该项目的推进过程中,我们明显感觉到技术问题有大量参考资料,但工程性问题却少有文章,这导致了NLP技术虽然丰富,但要在专业领域开展NLP工程却困难重重。这也是我们想把整个系统工程放到csdn来分享的一个原因。
当然,这其中有价值的代码我们也会放到github上分享,热烈欢迎对NLP感兴趣的小伙伴加入我们一起攻克难题、持续优化。(可以回帖、站内消息、或加我微信cleanbing)
启动:文本特点探索(1)
进行NLP系统工程,第一步需要对目标文本的特点做一个相对全面的了解,所谓知己知彼,才能针对性的选择对应的NLP武器。我们之前就犯了错,一上来就搜索各种NLP技术,看到哪个牛逼就马上弄下来搞一搞试一试,结果就是东拼西凑的系统,完全无法商业化应用。
通过我们积累的清单样本,进行大规模文本探索,可以得到造价行业清单三要文本的一些典型特点。
这里的技巧是通过文本探索从样本中获得规律,同时请行业专家配合来解释这个规律存在的原因,做到对每个规律的知其然和知其所以然,可以避免不常见的规律带来的干扰。
清单名称文本特点
清单名称是单行文本,计价软件自带国家标准清单名称,通常是一些抽象的概念性表达,如砖砌体、回填方(基础回填)、雨水管等等,造价工程师根据清单实际内容,人工修改为带有具体含义的文本,如 电力电缆WDZBN-YJY 4x185+1x95、浅灰色花岗岩石材台阶面、C20(40)现浇碎石钢筋砼圈梁(现浇混凝土带)等等。
此时的文本均为人工输入的文本,由中文字词、英文、数字、标点符号、特殊符号等组成(清单名称的字符集规律探索将在后续介绍)
我们从1959个造价工程中,提取了2721202条清单的清单名称,去除噪声文本后,形成有效的原始文本 497080行,进行去重后得到有效唯一的文本行数: 220499。
工程文件数量: 1959 清单总计数量: 2721202 原始文本数量: 497080 去重后文本数量: 220499
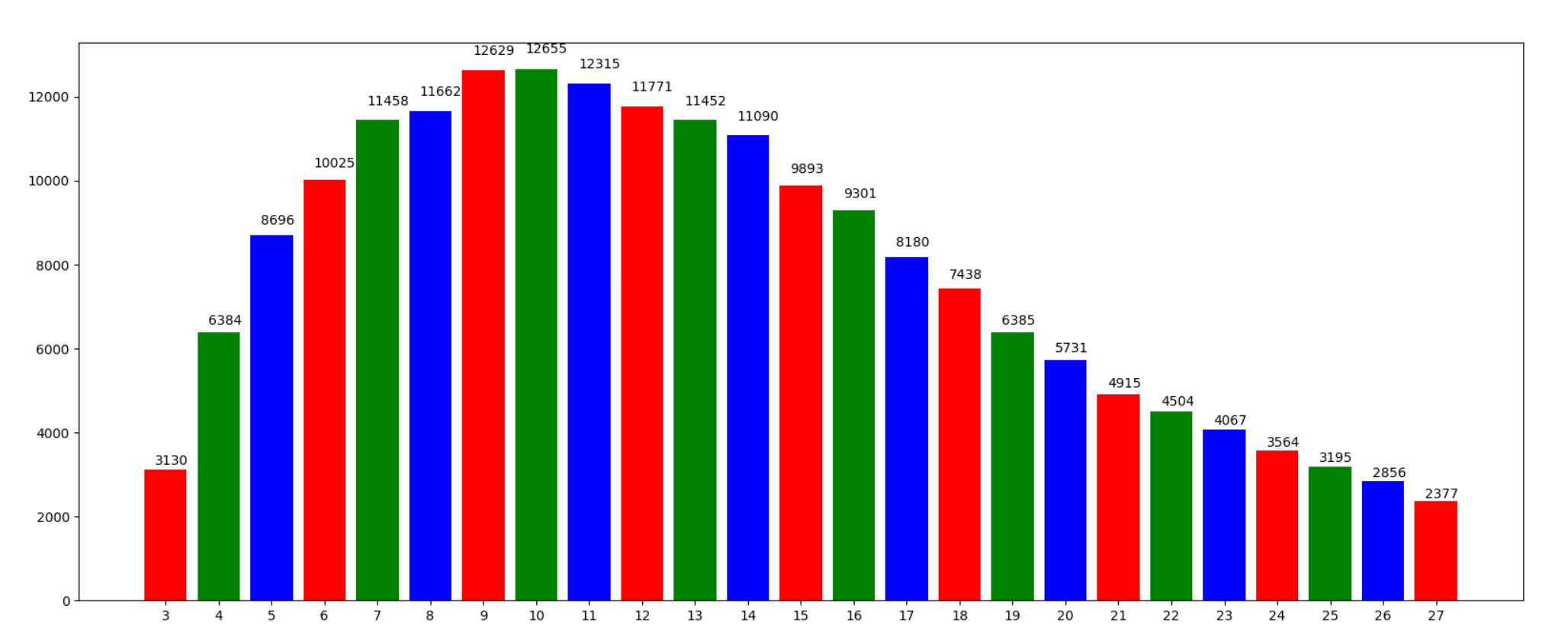
对22万行清单名称文本进行文本长度的探索,得到如下结果:(去除数量小于总数量1%的长度不做统计绘图)
平均长度: 15.95 中位长度: 13.0 最小长度: 1 最大长度: 275
值得注意的是,原始清单名称由于是人工输入的文本,存在噪声文本,提取这些清单名称文本时,需要对原始的清单名称做一些噪声文本的处理:
- 本身就极短的文本,如只有一两个中英文字符
- 除了标点符号和空格,只有一两个中英文字符
- 错误的将清单特征写到了清单名称里面的异常清单文本(实际中至少发现10个工程的清单出现了这样的错误)
- 表达的是规费、税金内容的清单名称,而非我们关注的分部分项的清单名称(名称不长,表达的是各种费用)
- 名称本身是单行文本,但却出现了异常的换行符,需要处理掉
附上清单名称文本提取的代码
if __name__ == '__main__':
# 是否开启调试模式。 最开始设计算法时,开启调试模式测试算法正确性,验证通过后关闭调试模式进行大批量处理
_DEBUG_MODE_ = False
# 若开启_DEBUG_MODE_,则只调试_DEBUG_COUNT_指定的文件数量,测试算法正确性
_DEBUG_COUNT_ = 10
# 结果是否保存到文件中
_RESULT_SAVE_FILE_ = True
# 提取的所有清单文本最后保存的文件名
_SAVE_FILE_NAME_ = "./qd_test_sample/qd_name_text_sample_unique.txt"
# 从哪个目录提取工程清单Json数据
_QD_JSON_SRC_FOLDER_ = "./qd_test_sample/qd_sample_json/json_data_3"
# --------------------------------------------------------------------------
# 从目录中读取工程清单文件列表,并依次处理每一个工程清单文件
# --------------------------------------------------------------------------
qd_flist = common.walkFile(_QD_JSON_SRC_FOLDER_, printScrn=False)
qd_text_sample_list = [] # 清单文本样本结果list
all_qd_count = 0 # 统计清单总数
for (i, f) in enumerate(qd_flist):
# 调试模式下,只调试部分文件,验证算法的正确性
if _DEBUG_MODE_ and qd_fcount>=_DEBUG_COUNT_:
break
# 读取该工程的造价清单json数据
qd_json = common.load_json_file(f)
all_qd_count += len(qd_json)
# 打印处理进度
if i%100==0:
print("正在处理第%d个文件"%i) # show progress
sys.stdout.flush() # 立刻刷新显示,否则会等到运行结束时控制台才会有输出
# 提取该工程所有清单的名称文本, extract_type指定了只提取清单名称
# get_qd_text_sample会去除噪声文本,同时对该工程内的清单文本去重
result = get_qd_text_sample(qd_json, extract_type="text_name")
# 容错机制:若该工程的清单数据有错,则停下来修正数据错误
if result[1]==-1:
print("Error file:", f, "==>", result[0]) # [0]为出错的清单文本
sys.exit(0)
#[0]为该工程的所有清单要提取的文本list,添加到总结果中
qd_text_sample_list.extend(result[0]) # 注意要用extend而不是append
print("-"*20 + "本次共提取" + "-"*20)
print("工程文件数量:", len(qd_flist)) # 一共多少个工程的清单
print("清单总计数量:", all_qd_count) # 一共有多少条清单
print("原始文本数量:", len(qd_text_sample_list)) # 去重前的清单文本数量
# --------------------------------------------------------------------------
# 去除所有清单文本中的重复文本和空行文本
# --------------------------------------------------------------------------
qd_key_text_unique_list = list(set(qd_text_sample_list)) # 所有文本去重
qd_key_text_unique_list = list(filter(None, qd_key_text_unique_list)) # 删除空行
print("去重后文本数量:", len(qd_key_text_unique_list))
# --------------------------------------------------------------------------
# 将以上的有文本结果保存到文件中
# --------------------------------------------------------------------------
if _RESULT_SAVE_FILE_:
print("-"*20 + "结果写入文件中" + "-"*20)
common.list_save_file(qd_key_text_unique_list, _SAVE_FILE_NAME_, withId=False, title='', printScrn=False)
print("nn" + "="*20 + "结果已保存到文件中:" + _SAVE_FILE_NAME_ + "="*20)
else:
# 不保存到文件时,直接打印出结果
for (id, text) in enumerate(qd_key_text_unique_list):
print("%8d => %s"%(id, text))
print('/n/n===== all done ====/n/n')
附上清单名称文本长度探索代码
# --------------------------------------------------------------------------
# 装载样本
# --------------------------------------------------------------------------
qd_text_sample = common.load_txt_file(_TEXT_SRC_FILE_)
#调试模式下只取部分数据
if _DEBUG_MODE_:
# 由于相邻的文本非常相似,若在调试模式下只取部分样本将导致无法观察全局规律
# 因此 对所有样本乱序排列后 再取部分文本进行调试
random.shuffle(qd_text_sample)
qd_text_sample = qd_text_sample[:_DEBUG_COUNT_]
common.print_separator("共有"+str(len(qd_text_sample))+"条文本")
# 计算每个文本的长度
qd_text_lens = list(map(lambda x:len(x), qd_text_sample))
# 对所有文本长度list 求 均值、中位、最小、最大
len_average = np.mean(qd_text_lens)
len_median = np.median(qd_text_lens)
len_min = np.min(qd_text_lens)
len_max = np.max(qd_text_lens)
print("平均长度:", len_average)
print("中位长度:", len_median)
print("最小长度:", len_min)
print("最大长度:", len_max)
# 统计每种长度的文本数量
each_len_list = list(set(qd_text_lens))
each_len_count = [qd_text_lens.count(x) for x in each_len_list]
# 去除数量小于总数量1%的长度不做统计绘图
min_count = int(len(qd_text_sample)*0.01)
valid_len_list = []
valid_len_count = []
for i in range(len(each_len_list)):
if each_len_count[i]>min_count:
valid_len_list.append(each_len_list[i])
valid_len_count.append(each_len_count[i])
# 对每种长度的文本数量绘制柱状图
autolabel(plt.bar(range(len(valid_len_count)), valid_len_count, color='rgb', tick_label=valid_len_list))
plt.show()
最后
以上就是鲤鱼钢笔最近收集整理的关于[NLP工程项目实战:用NLP解决工程造价文本难题] (1) 开篇及文本特点探索问题背景我们的想法启动:文本特点探索(1)附上清单名称文本提取的代码附上清单名称文本长度探索代码的全部内容,更多相关[NLP工程项目实战:用NLP解决工程造价文本难题]内容请搜索靠谱客的其他文章。




![[NLP工程项目实战:用NLP解决工程造价文本难题] (1) 开篇及文本特点探索问题背景我们的想法启动:文本特点探索(1)附上清单名称文本提取的代码附上清单名称文本长度探索代码](https://www.shuijiaxian.com/files_image/reation/bcimg27.png)



发表评论 取消回复