1.测试环境
OS:Linux
DB:mysql-5.5.18
table:innodb存储引擎
表定义如下:
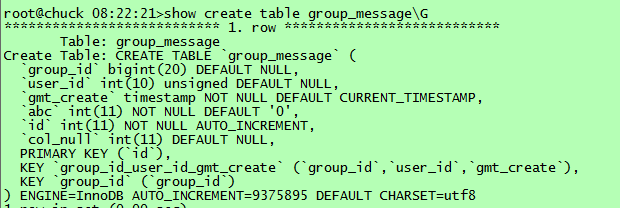
2. 测试场景与分析【统计表group_message的记录数目】
(1)select count(*)方式

(2)select count(1)方式

(3)select count(col_name)方式
分别使用
select count(group_id)
select count(user_id)
select count(col_null)
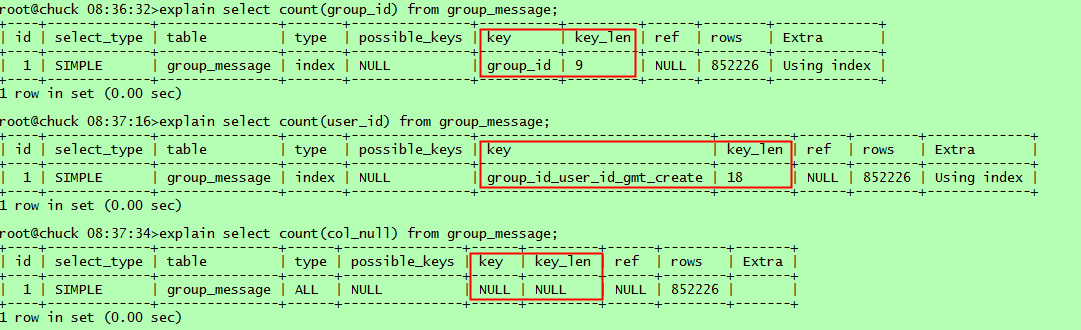
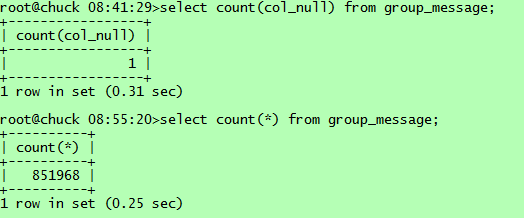
通过上述测试结果可以看到,select count(*)和select count(1)都使用了group_id这个最短的二级索引。可能有人会问为啥不用更短的主键索引【int类型】呢,这主要是因为innodb存储引擎下,主键索引实质包含了索引和数据,扫描主键索引实际是扫描物理记录,代价实质是最大的。再来看看几种select count(col_name), count(group_id)使用了最短二级索引,因为该列就是索引列;而count(user_id)则使用了组合索引,由于user_id实质不能利用该索引,但扫描索引也能得到记录数,而且比扫描物理记录代价小,这里应该是mysql的一个优化;count(col_null)则不能使用索引,因为该列含有null值,所以效率最低。另外,对于含有null值的行,count(col_null)实际不会统计,这会与你想统计表记录数目的初衷不符,比如测试表有852226条记录,但col_null列只有1行非空,则统计结果如下:
3.测试结论
mysql中,需要通过selct count 统计表记录数目时,使用count(*)或count(1)就好。
最后
以上就是聪慧蜜蜂最近收集整理的关于mysql技巧之select count的区别分析的全部内容,更多相关mysql技巧之select内容请搜索靠谱客的其他文章。








发表评论 取消回复