一. SPI通讯基本原理
1. SPI通讯介绍
SPI(Serial Perripheral Interface, 串行外围设备接口)是 Motorola 公司推出的一种同步串行接口技术。SPI 总线在物理上是通过接在外围设备微控制器(PICmicro) 上面的微处理控制单元 (MCU) 上叫作同步串行端口(Synchronous Serial Port) 的模块(Module)来实现的, 它允许 MCU 以全双工的同步串行方式, 与各种外围设备进行高速数据通信。
SPI 主要应用在 EEPROM, Flash, 实时时钟(RTC), 数模转换器(ADC), 数字信号处理器(DSP) 以及数字信号解码器之间。它在芯片中只占用四根管脚 (Pin) 用来控制以及数据传输, 节约了芯片的 pin 数目, 同时为 PCB 在布局上节省了空间。正是出于这种简单易用的特性, 现在越来越多的芯片上都集成了 SPI技术。
SPI主要有以下几方面特点:
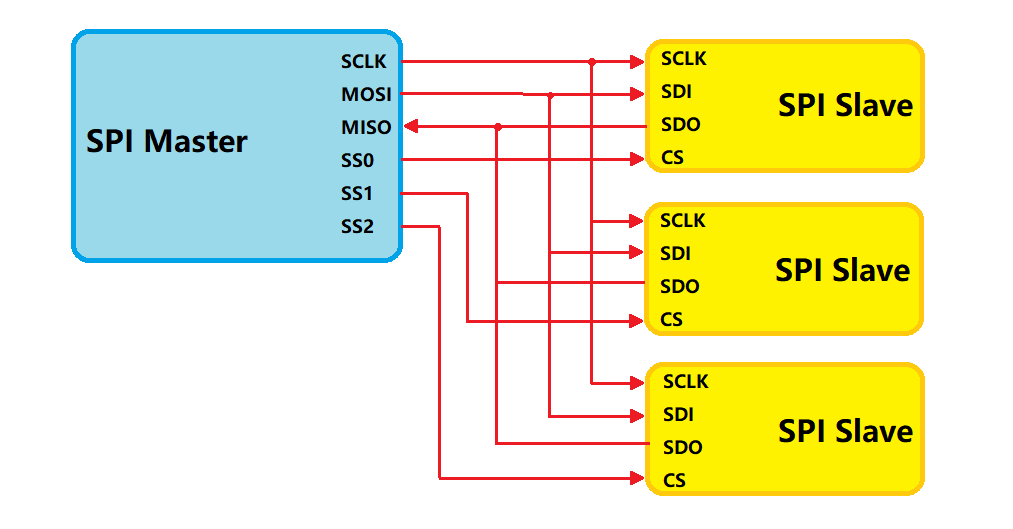
- 采用主-从模式(Master-Slave) 的控制方式
SPI 规定了两个 SPI 设备之间通信必须由主设备 (Master) 来控制次设备 (Slave). 一个 Master 设备可以通过提供 Clock 以及对 Slave 设备进行片选 (Slave Select) 来控制多个 Slave 设备, SPI 协议还规定 Slave 设备的 Clock 由 Master 设备通过 SCK 管脚提供给 Slave 设备, Slave 设备本身不能产生或控制 Clock, 没有 Clock 则 Slave 设备不能正常工作.
-
采用同步方式(Synchronous)传输数据
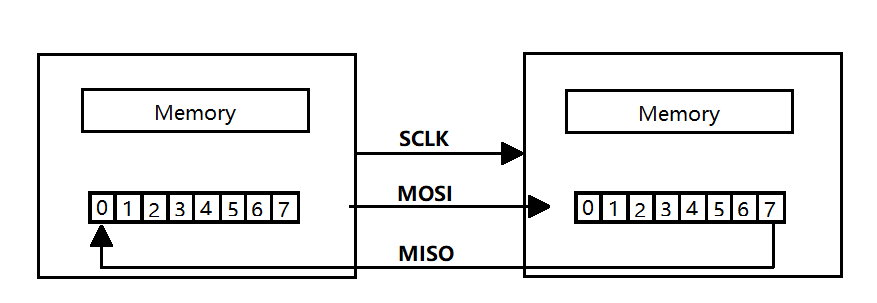
Master 设备会根据将要交换的数据来产生相应的时钟脉冲(Clock Pulse), 时钟脉冲组成了时钟信号(Clock Signal) , 时钟信号通过时钟极性 (CPOL) 和 时钟相位 (CPHA) 控制着两个 SPI 设备间何时数据交换以及何时对接收到的数据进行采样, 来保证数据在两个设备之间是同步传输的. -
数据交换(Data Exchanges)
SPI 设备间的数据传输之所以又被称为数据交换, 是因为 SPI 协议规定一个 SPI 设备不能在数据通信过程中仅仅只充当一个 “发送者(Transmitter)” 或者 “接收者(Receiver)”. 在每个 Clock 周期内, SPI 设备都会发送并接收一个 bit 大小的数据, 相当于该设备有一个 bit 大小的数据被交换了.
一个 Slave 设备要想能够接收到 Master 发过来的控制信号, 必须在此之前能够被 Master 设备进行访问 (Access). 所以, Master 设备必须首先通过 SS/CS pin 对 Slave 设备进行片选, 把想要访问的 Slave 设备选上.
在数据传输的过程中, 每次接收到的数据必须在下一次数据传输之前被采样. 如果之前接收到的数据没有被读取, 那么这些已经接收完成的数据将有可能会被丢弃, 导致 SPI 物理模块最终失效. 因此, 在程序中一般都会在 SPI 传输完数据后, 去读取 SPI 设备里的数据, 即使这些数据(Dummy Data)在我们的程序里是无用的.
2. SPI主从模块通讯规则
如图是对 SPI 设备间通信的一个简单的描述, 下面就来解释一下图中所示的几个组件(Module):
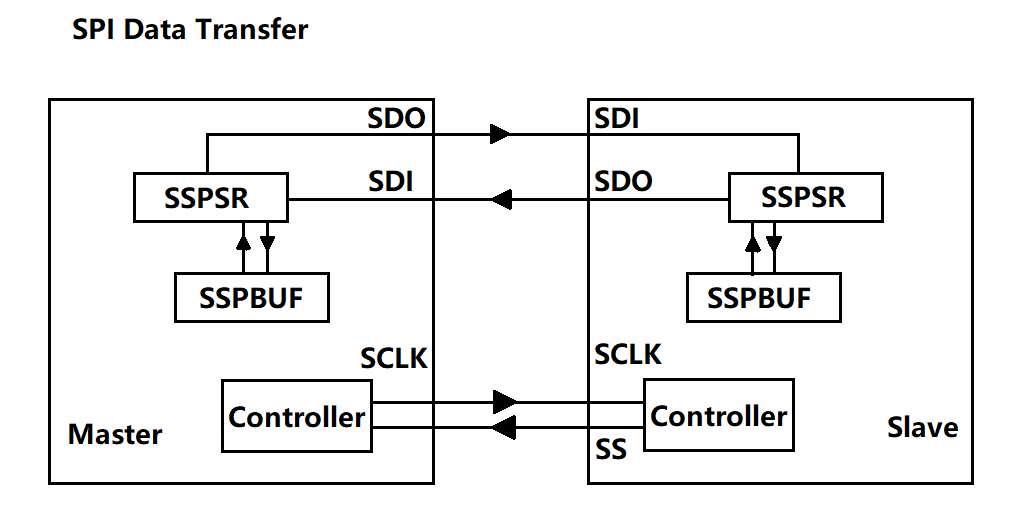
SSPBUF, Synchronous Serial Port Buffer, 泛指 SPI 设备里面的内部缓冲区, 一般在物理上是以 FIFO 的形式, 保存传输过程中的临时数据;
SSPSR, Synchronous Serial Port Register, 泛指 SPI 设备里面的移位寄存器(Shift Regitser), 它的作用是根据设置好的数据位宽(bit-width) 把数据移入或者移出 SSPBUF;
Controller, 泛指 SPI 设备里面的控制寄存器, 可以通过配置它们来设置 SPI 总线的传输模式.
通常情况下, 我们只需要对上图所描述的四个管脚(pin) 进行编程即可控制整个 SPI 设备之间的数据通信:
SCK, Serial Clock, 主要的作用是 Master 设备往 Slave 设备传输时钟信号, 控制数据交换的时机以及速率;
SS/CS, Slave Select/Chip Select, 用于 Master 设备片选 Slave 设备, 使被选中的 Slave 设备能够被 Master 设备所访问;
SDO/MOSI, Serial Data Output/Master Out Slave In, 在 Master 上面也被称为 Tx-Channel, 作为数据的出口, 主要用于 SPI 设备发送数据;
SDI/MISO, Serial Data Input/Master In Slave Out, 在 Master 上面也被称为 Rx-Channel, 作为数据的入口, 主要用于SPI 设备接收数据;
SPI 设备在进行通信的过程中, Master 设备和 Slave 设备之间会产生一个数据链路回环(Data Loop), 就像上图所画的那样, 通过 SDO 和 SDI 管脚, SSPSR 控制数据移入移出 SSPBUF, Controller 确定 SPI 总线的通信模式, SCK 传输时钟信号.
-
timing
首先, 在这里解释一下两个概念:
CPOL: 时钟极性, 表示 SPI 在空闲时, 时钟信号是高电平还是低电平. 若 CPOL 被设为 1, 那么该设备在空闲时 SCK 管脚下的时钟信号为高电平. 当 CPOL 被设为 0 时则正好相反.
CPHA: 时钟相位, 表示 SPI 设备是在 SCK 管脚上的时钟信号变为上升沿时触发数据采样, 还是在时钟信号变为下降沿时触发数据采样. 若 CPHA 被设置为 1, 则 SPI 设备在时钟信号变为下降沿时触发数据采样, 在上升沿时发送数据. 当 CPHA 被设为 0 时也正好相反.
本例所使用的 SPI 数据传输模式被设置成 CPOL = 1, CPHA = 1. 这样, 在一个 Clock 周期内, 每个单独的 SPI 设备都能以全双工(Full-Duplex) 的方式, 同时发送和接收 1 bit 数据, 即相当于交换了 1 bit 大小的数据. 如果 SPI 总线的 Channel-Width 被设置成 Byte, 表示 SPI 总线上每次数据传输的最小单位为 Byte, 那么挂载在该 SPI 总线的设备每次数据传输的过程至少需要 8 个 Clock 周期(忽略设备的物理延迟). 因此, SPI 总线的频率越快, Clock 周期越短, 则 SPI 设备间数据交换的速率就越快. -
SSPSR
SSPSR 是 SPI 设备内部的移位寄存器(Shift Register). 它的主要作用是根据 SPI 时钟信号状态, 往 SSPBUF 里移入或者移出数据, 每次移动的数据大小由 Bus-Width 以及 Channel-Width 所决定.
Bus-Width 的作用是指定地址总线到 Master 设备之间数据传输的单位.
例如, 我们想要往 Master 设备里面的 SSPBUF 写入 16 Byte 大小的数据: 首先, 给 Master 设备的配置寄存器设置 Bus-Width 为 Byte; 然后往 Master 设备的 Tx-Data 移位寄存器在地址总线的入口写入数据, 每次写入 1 Byte 大小的数据(使用 writeb 函数); 写完 1 Byte 数据之后, Master 设备里面的 Tx-Data 移位寄存器会自动把从地址总线传来的1 Byte 数据移入 SSPBUF 里; 上述动作一共需要重复执行 16 次.
Channel-Width 的作用是指定 Master 设备与 Slave 设备之间数据传输的单位. 与 Bus-Width 相似, Master 设备内部的移位寄存器会依据 Channel-Width 自动地把数据从 Master-SSPBUF 里通过 Master-SDO 管脚搬运到 Slave 设备里的 Slave-SDI 引脚, Slave-SSPSR 再把每次接收的数据移入 Slave-SSPBUF里.
通常情况下, Bus-Width 总是会大于或等于 Channel-Width, 这样能保证不会出现因 Master 与 Slave 之间数据交换的频率比地址总线与 Master 之间的数据交换频率要快, 导致 SSPBUF 里面存放的数据为无效数据这样的情况. -
SSPBUF
我们知道, 在每个时钟周期内, Master 与 Slave 之间交换的数据其实都是 SPI 内部移位寄存器从 SSPBUF 里面拷贝的. 我们可以通过往 SSPBUF 对应的寄存器 (Tx-Data / Rx-Data register) 里读写数据, 间接地操控 SPI 设备内部的 SSPBUF.
例如, 在发送数据之前, 我们应该先往 Master 的 Tx-Data 寄存器写入将要发送出去的数据, 这些数据会被 Master-SSPSR 移位寄存器根据 Bus-Width 自动移入 Master-SSPBUF 里, 然后这些数据又会被 Master-SSPSR 根据 Channel-Width 从 Master-SSPBUF 中移出, 通过 Master-SDO 管脚传给 Slave-SDI 管脚, Slave-SSPSR 则把从 Slave-SDI 接收到的数据移入 Slave-SSPBUF 里. 与此同时, Slave-SSPBUF 里面的数据根据每次接收数据的大小(Channel-Width), 通过 Slave-SDO 发往 Master-SDI, Master-SSPSR 再把从 Master-SDI 接收的数据移入 Master-SSPBUF.在单次数据传输完成之后, 用户程序可以通过从 Master 设备的 Rx-Data 寄存器读取 Master 设备数据交换得到的数据. -
Controller
Master 设备里面的 Controller 主要通过时钟信号(Clock Signal)以及片选信号(Slave Select Signal)来控制 Slave 设备. Slave 设备会一直等待, 直到接收到 Master 设备发过来的片选信号, 然后根据时钟信号来工作.
Master 设备的片选操作必须由程序所实现. 例如: 由程序把 SS/CS 管脚的时钟信号拉低电平, 完成 SPI 设备数据通信的前期工作; 当程序想让 SPI 设备结束数据通信时, 再把 SS/CS 管脚上的时钟信号拉高电平.
二. SPI主从模块案例与FPGA实现
1. 案例描述
设计4线SPI master 模块和slave 模块,要求如下:
- 主机模块(master)接口定义:
module spi_master(
input clk_40k, //时钟信号,40kHz
input rst_n, //复位信号,低有效
input [7:0] data_in, //主机准备要输出给从机的数据,8位宽
input send_start, //通信使能信号,高有效,宽度为1个时钟周期(40kHz),收到该信号后开始一次主从设备通信。
output [7:0] data_out, //主机从从机接收到的数据,8位宽
output data_out_vld, //输出数据有效标志,高电平有效,宽度为1个时钟周期(40kHz)
output cs_n, //从设备片选使能信号,低有效,低电平时选中从设备与主设备进行通信,处于通信状态时维持低电平。
output sclk, //同步时钟,1kHz,空闲时置低电平
input miso, //主机当前从从机收到的串行数据
output mosi //主机当前发送给从机的串行数据
);
- 从机模块(slave)接口定义:
module spi_slave(
input rst_n, //复位信号,低有效
input cs_n, //从设备片选使能信号
input sclk, //SPI时钟,1kHz空闲时置低电平,
input mosi, //从机从主机接收到的串行数据
output miso, //从机要发送给主机的串行数据
output [7:0] reg0_out, //内部寄存器0的值
output [7:0] reg1_out, //内部寄存器1的值
output [7:0] reg2_out, //内部寄存器2的值
output [7:0] reg3_out //内部寄存器3的值
);
- 电路功能描述:
Slave模块中有四个八位内部寄存器(reg0、reg1、reg2、reg3),地址分别为 0~3,master模块通过SPI总线配置slave模块中四个寄存器的值,slave寄存器的值直接通过其端口输出。
Master模块收到send_start信号之后,将数据data_in通过spi总线发送到slave模块的reg0,然后将data_in循环右移两位后发送到slave模块的reg1,然后再将data_in循环右移两位发送到reg2,最后将data_in再循环右移两位发送到reg3。至此,master完成对slave中所有寄存器的配置。然后master再通过spi总线将slave中reg3的数据读出来,通过data_out输出,并同时给出一个周期宽度的data_out_vld。
- SPI传输格式:
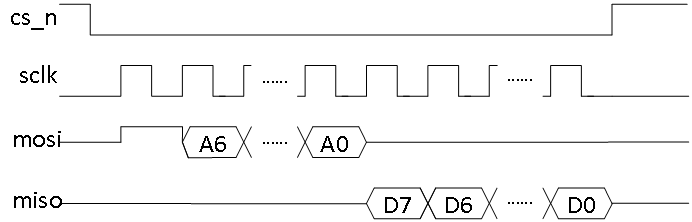
SPI每帧数据包含16位,最先发送的第0位为读写控制位,该位为0代表master向slave写数据,为1则代表master从slave读数据;随后发送的第1-7位为地址位,先发高位地址再发低位地址,9-16位为数据位,高位数据先发。所有数据均在sclk的上升沿产生,下降沿采样。
SPI写数据格式如图1所示:
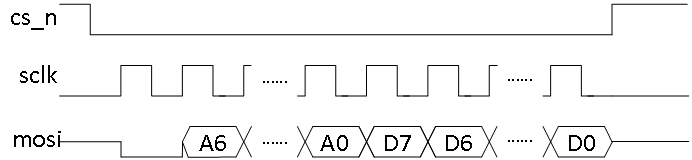
SPI读数据格式如图2所示:
2. 设计思路
- SPI协议由主从双方确定,此处要求主模块每次发送5组数,前四组用于发送数据到不同地址的从模块,第五组用于发送地址读取最后一个从模块接收到的数据,因此按要求将mosi发送出去即可;
- 从模块slave将读取的数据mosi进行判断,若读取到1,判断随后7位是否为地址为,是则将所在地址的slave从模块数据通过miso发送;若读取到0,判断随后7位是否为地址为,是则将mosi发送的数据接收到所在地址的slave从模块的寄存器内。
3. FPGA源码
1.SPI_master: 主模块
module spi_master(
input clk_40k,
input rst_n,
input [7:0] data_in,
input send_start,
output reg [7:0] data_out,
output reg data_out_vld,
output reg cs_n,
output reg sclk,
input miso,
output reg mosi
);
reg flag; //recieve&transfer part
reg addr_flag; //mosi address output
reg data_flag; //mosi data output
reg [4:0] bit_cnt; //bit count
reg [6:0] clk_cnt; //40 count
reg [2:0] cs_n_cnt; //data transform count
reg [7:0] data_in_m0; //shifting input data
reg [7:0] data_in_m1; //shifting input data
reg [7:0] data_in_m2; //shifting input data
reg [7:0] data_in_m3; //shifting input data
reg [7:0] rx_data_out; //output data
reg [7:0] addr0;
reg [7:0] addr1;
reg [7:0] addr2;
reg [7:0] addr3;
reg [7:0] read;
parameter reg0_address = 7'b0000000; //address of reg0
parameter reg1_address = 7'b0000001; //address of reg1
parameter reg2_address = 7'b0000010; //address of reg2
parameter reg3_address = 7'b0000011; //address of reg3
localparam idle = 1'b0;
localparam work = 1'b1;
localparam transfer = 1'b0;
localparam recieve = 1'b1;
//set address of reg
always @ *
begin
if(~rst_n)
begin
addr0 <= {1'b0, reg0_address};
addr1 <= {1'b0, reg1_address};
addr2 <= {1'b0, reg2_address};
addr3 <= {1'b0, reg3_address};
read <= {1'b1, reg3_address};
end
end
//cs_n
always @ (posedge clk_40k or negedge rst_n)
begin
if(~rst_n)
cs_n <= 1'b1;
else if(send_start == 1'b1)
cs_n <= 1'b0;
else if(clk_cnt == 7'd39 && bit_cnt == 5'd15 && cs_n_cnt == 3'b100)
cs_n <= 1'b1;
end
//clk_cnt 20 count
always @ (posedge clk_40k or negedge rst_n)
begin
if(~rst_n)
clk_cnt <= 7'b0;
else if(cs_n == 1'b0 && clk_cnt != 7'd39)
clk_cnt <= clk_cnt + 1'b1;
else if(cs_n == 1'b0 && clk_cnt == 7'd39)
clk_cnt <= 7'b0;
end
//sclk
always @ (posedge clk_40k or negedge rst_n)
begin
if(~rst_n)
sclk <= 1'b0;
else if(send_start == 1'b1)
sclk <= 1'b1;
else if(clk_cnt == 7'd19 || clk_cnt == 7'd39)
sclk <= ~sclk;
end
//bit_cnt 16 count
always @ (posedge clk_40k or negedge rst_n)
begin
if(~rst_n || cs_n)
bit_cnt <= 5'b0;
else if(bit_cnt != 5'd15 && cs_n == 1'b0 && clk_cnt == 7'd39)
bit_cnt <= bit_cnt + 1'b1;
else if(bit_cnt == 5'd15 && cs_n == 1'b0 && clk_cnt == 7'd39)
bit_cnt <= 5'b0;
else if(cs_n == 1'b1)
bit_cnt <= 5'b0;
end
//cs_n_cnt 4 salve count
always @ (posedge clk_40k or negedge rst_n)
begin
if(~rst_n || cs_n)
cs_n_cnt <= 3'b0;
else if(bit_cnt == 5'd15 && cs_n_cnt != 3'b100 && clk_cnt == 7'd39)
cs_n_cnt <= cs_n_cnt + 1'b1;
else if(bit_cnt == 5'd15 && cs_n_cnt == 3'b100 && clk_cnt == 7'd39)
cs_n_cnt <= 3'b0;
else if(cs_n == 1'b1)
cs_n_cnt <= 3'b0;
end
//input data shifting
always @ (posedge sclk)
begin
if(send_start == 1'b1)
begin
data_in_m0 <= data_in;
data_in_m1 <= {data_in[1:0],data_in[7:2]};
data_in_m2 <= {data_in[3:0],data_in[7:4]};
data_in_m3 <= {data_in[5:0],data_in[7:6]};
end
end
//send part mosi
//flag of transfering address and data
always @ (negedge sclk or negedge rst_n)
begin
if(~rst_n)
begin
addr_flag <= work;
data_flag <= idle;
end
else if(bit_cnt == 5'd7)
begin
addr_flag <= idle;
data_flag <= work;
end
else if(bit_cnt == 5'd15 || send_start == 1'b1)
begin
addr_flag <= work;
data_flag <= idle;
end
end
//output mosi address and data
always @ (posedge sclk)
begin
if(addr_flag == work && cs_n == 1'b0)
begin
case(cs_n_cnt)
3'b000:
begin
mosi <= addr0[7];
addr0 <= {addr0[6:0],addr0[7]};
end
3'b001:
begin
mosi <= addr1[7];
addr1 <= {addr1[6:0],addr1[7]};
end
3'b010:
begin
mosi <= addr2[7];
addr2 <= {addr2[6:0],addr2[7]};
end
3'b011:
begin
mosi <= addr3[7];
addr3 <= {addr3[6:0],addr3[7]};
end
3'b100:
begin
mosi <= read[7];
read <= {read[6:0],read[7]};
end
endcase
end
else if(data_flag == work && cs_n == 1'b0)
begin
case(cs_n_cnt)
3'b000:
begin
mosi <= data_in_m0[7];
data_in_m0 <= {data_in_m0[6:0],data_in_m0[7]};
end
3'b001:
begin
mosi <= data_in_m1[7];
data_in_m1 <= {data_in_m1[6:0],data_in_m1[7]};
end
3'b010:
begin
mosi <= data_in_m2[7];
data_in_m2 <= {data_in_m2[6:0],data_in_m2[7]};
end
3'b011:
begin
mosi <= data_in_m3[7];
data_in_m3 <= {data_in_m3[6:0],data_in_m3[7]};
end
3'b100:
begin
mosi <= 1'bz;
end
endcase
end
else if(cs_n == 1'b1)
mosi <= 1'bz;
end
//recieve part miso
//recieve data
always @ (negedge sclk or negedge rst_n)
begin
if(~rst_n)
rx_data_out <= 8'b0;
else if(flag == 1'b1)
rx_data_out <= {rx_data_out[6:0],miso};
end
//output & valid
always @ (posedge clk_40k or negedge rst_n)
begin
if(~rst_n)
data_out_vld <= 1'b0;
else if(bit_cnt == 5'd15 && clk_cnt== 7'd39 && cs_n == 1'b0 && cs_n_cnt == 3'b100)
begin
data_out_vld <= 1'b1;
data_out <= rx_data_out;
end
else
data_out_vld <= 1'b0;
end
//recieve/transfer switch
always @ (posedge clk_40k or negedge rst_n)
begin
if(~rst_n)
flag <= 1'b0;
else if(clk_cnt == 7'd39 && bit_cnt == 5'd7 && cs_n_cnt == 3'b100 && flag == 1'b0)
flag <= 1'b1;
else if(clk_cnt == 7'd0 && bit_cnt == 5'd0 && flag == 1'b1)
flag <= 1'b0;
end
endmodule
2.SPI_slave: 从模块
module spi_slave
(
input rst_n,
input cs_n,
input sclk,
input mosi,
output reg miso,
output reg [7:0] reg0_out,
output reg [7:0] reg1_out,
output reg [7:0] reg2_out,
output reg [7:0] reg3_out
);
reg [6:0] bit_cnt;
reg state;
reg n_state;
reg [6:0] address;
reg token;
localparam idle = 1'b0;
localparam transmit = 1'b1;
//bit_cnt
always @ (posedge sclk or negedge rst_n)
if(~rst_n || cs_n)
bit_cnt <= 7'd0;
else if(bit_cnt == 7'd15)
bit_cnt <= 7'd0;
else if(state || n_state)
bit_cnt <= bit_cnt + 1'b1;
//n_state
always @ *
if(cs_n)
n_state <= idle;
else
n_state <= transmit;
//state
always @ (posedge sclk or negedge rst_n)
if(~rst_n)
state <= idle;
else
state <= n_state;
//reg_out
always @ (negedge sclk or negedge rst_n)
if(~rst_n)
begin
reg0_out <= 8'd0;
reg1_out <= 8'd0;
reg2_out <= 8'd0;
reg3_out <= 8'd0;
end
else if(bit_cnt >= 'd8 && token == 'b0)
begin
case(address)
7'd0:
reg0_out <= {reg0_out[6:0], mosi};
7'd1:
reg1_out <= {reg1_out[6:0], mosi};
7'd2:
reg2_out <= {reg2_out[6:0], mosi};
7'd3:
reg3_out <= {reg3_out[6:0], mosi};
endcase
end
//address
always @ (negedge sclk or negedge rst_n)
if(~rst_n)
address <= 7'd0;
else if(bit_cnt >= 7'd1 && bit_cnt <= 7'd7)
address <= {address[5:0], mosi};
//token
always @ (negedge sclk or negedge rst_n)
if(~rst_n)
token <= 1'b0;
else if(state == transmit && bit_cnt == 7'b0)
token <= mosi;
//miso
always @ (posedge sclk or negedge rst_n)
if(~rst_n || state == idle || cs_n)
miso <= 1'b0;
else if(state == transmit && token == 1'b1 && bit_cnt >= 7'd7)
begin
case(address)
7'd0: miso <= reg0_out[14-bit_cnt];
7'd1: miso <= reg1_out[14-bit_cnt];
7'd2: miso <= reg2_out[14-bit_cnt];
7'd3: miso <= reg3_out[14-bit_cnt];
endcase
end
else
miso <= 1'b0;
endmodule
3.testbench: 测试文件
`timescale 1us/1us
module tb();
reg clk_40k;
reg rst_n;
reg [7:0] data_in;
reg send_start;
wire sclk;
wire cs_n;
wire mosi;
wire miso;
wire [7:0] data_out;
wire data_out_vld;
wire [7:0] reg0_out;
wire [7:0] reg1_out;
wire [7:0] reg2_out;
wire [7:0] reg3_out;
spi_master i_spi_master(
.clk_40k (clk_40k ),
.rst_n (rst_n ),
.data_in (data_in ),
.send_start (send_start),
.sclk (sclk ),
.cs_n (cs_n ),
.mosi (mosi ),
.miso (miso ),
.data_out (data_out ),
.data_out_vld (data_out_vld )
);
spi_slave i_spi_slave(
.rst_n (rst_n ),
.cs_n (cs_n ),
.sclk (sclk ),
.mosi (mosi ),
.miso (miso ),
.reg0_out (reg0_out ),
.reg1_out (reg1_out ),
.reg2_out (reg2_out ),
.reg3_out (reg3_out )
);
initial
begin
rst_n = 1'b0;
#10 rst_n = 1'b1;
end
initial
begin
clk_40k = 1'b0;
forever
#1 clk_40k = ~clk_40k;
end
initial
begin
send_start = 1'b0;
data_in = 8'd0;
forever
begin
#200;
data_in = $random()%256;
send_start = 1'b1;
#2
send_start = 1'b0;
#8000;
end
end
endmodule
波形图输出结果:

最后
以上就是淡然发带最近收集整理的关于FPGA(三)——基于FPGA的SPI通讯协议实现一. SPI通讯基本原理二. SPI主从模块案例与FPGA实现波形图输出结果:的全部内容,更多相关FPGA(三)——基于FPGA的SPI通讯协议实现一.内容请搜索靠谱客的其他文章。








发表评论 取消回复