这段时间想着把自己之前学到到一些比较知识写在这,也是个留念,虽然现在工作内容和语音识别没有任何交集,但是毕竟那么用心的去学过。。。。
关于语音分析的知识点:
短时傅立叶变换(short-time fourier transform)就能解决这个问题。声音信号虽然不是平稳信号,但在较短的一段时间内,可以看作是平稳的。符合直觉的解决方案是取一小段进行傅立叶变换,这也正是短时傅立叶变换的核心思想。
短时加窗处理:
语音信号在相对较短的时间是平稳的,我们一般选择10~30ms
为了得到短时的语音信号,要对语音信号进行加窗的操作,窗函数平滑的在语音信号上滑动,将语音信号分成帧。分帧可以连续,也可以采用交叠分段,交叠部分称为帧移
相邻的窗之间要重叠是为了不损失时间信号的信息,窗函数的宽度一般等于快速傅立叶变换的点数
加窗时,不同窗口将影响到语音信号分析的结果,常用的就是有haming window,hanning window。
我们一般使用短时分析技术来分析语音,语音具有时变性质,是一个非稳态的过程。但语音是由人的口腔肌肉运动构成声道的某种形状而产生的响应,而这种肌肉运动频率相对于语音频率来说是缓慢的,所以在一个短的时间内,语音的特性相对稳定,这个时间根据研究大致在10-30ms,所以我们使用10-30ms的窗函数长度进行分析是非常合适的
时域分析:
一般从下面四个方面来分析:
- 短时能量
- 短时过零率
利用短时能量可以区分清音和浊音,因为浊音的能量要比清音的能量大得多;可以用短时平均过零率来初步判断清音和浊音。在发浊音时,声带振动,浊音集中在低频段,然而在发清音时,声带振动,主要集中在高频段。短时平均过零率可以在一定程度上反映频率的高低,因此在浊音段,一般具有较低的过零率,而在清音段具有较高的过零率.用这两个特征结合起来判断清浊音是十分准确的。
3. 自相关函数
浊音信号的自相关函数在基音周期的整数倍位置上出现峰值,而清音的自相关函数没有明显的峰值出现,因此检测自相关函数是否有峰值就可以判断是清音或浊音,峰-峰值之间对应的就是基音周期。
参考语音中典型的特征提取,为什么通常采用多变量GMM而不是单变量GMM来对提取的特征进行建模?
单变量GMM是只由一个变量而产生的高斯分布,而多变量高斯是由多个变量和组成的联合分布。在对语音信号做特征提取时,往往我们所提取的变量都是多个(比如MFCC).所以一般采用多变量GMM进行特征提取.
在语音识别系统中,哪些因素影响基本识别单元的选择?
对于小词汇量的孤立词识别系统,您会选择什么单位?
对于大词汇量连续语音识别系统和词汇量的孤立词识别系统我们一般会选择不同的识别单元。可以选择的基元包括word、syllable、semi-syllable、initial/final和phone等。孤立词语音识别和连接词语音识别时,把词或短语作为一个基本的语音单元,由于连续语音中词与词之间的相互影响比起词内音素或音节的相互影响还是要小得多,以词作为基本单元建立模型,对于简化识别系统的结构和训练过程是很有效的
在对GMM进行建模的时候,使用完全协方差矩阵建模还是使用对角协方差建模,有什么区别?
一般来说对GMM进行建模,使用对角协方差矩阵会更好,对角的协方差矩阵,那么只有D个参数,而如果是普通的协方差矩阵,那么有D(D+1)/2个参数。为了简化计算,我们通常使用对角的协方差矩阵。
如何得到倒谱
倒谱分析分为四步,第一步信号加窗。声音信号在产生时天然地受到发声部位物理形态的限制,是缓变信号,频谱分析不需要很长范围,所以加窗。
第二步是做频谱分析,转换到频域。
第三步是对频谱取对数。由第二步我们知道,缓变信号和快变信号以乘积的方式耦合,所以取对数之后,缓变信号和快变信号以相加的方式耦合
第四步是取傅里叶变换(逆变换,离散傅里叶变换和逆变换只差一个系数)。这样就能够将乘积变加法后的高频信号和低频信号的耦合分开来分析了。
解释一下UBM为什么用在语音识别
UBM相当于一个大的混合高斯分布模型,他是为了解决目标用户训练数据太少的问题,用大量非目标用户数据训练出一个拟合通用特征的大型GMM
在得到倒谱的时候,为什么要做对数操作
The slowly varying signal and the fast varying signal are coupled in a product manner. After taking the logarithm, the slowly varying signal and the fast varying signal are coupled in an additive manner.
EM算法的原理
The EM algorithm is a maximum likelihood estimation method for solving model distribution parameters from "incomplete data".
Since we cannot directly calculate the model distribution parameters, we can first guess the hidden data (step E of the EM algorithm), and then maximize the log likelihood based on the observed data and the guessed hidden data to solve our model Parameters (M steps of EM algorithm). Since our previous hidden data was guesswork, the model parameters obtained at this time are generally not the results we want. But it doesn't matter, we continue to guess the hidden data (step E of the EM algorithm) based on the currently obtained model parameters, and then continue to maximize the log likelihood to solve our model parameters (step M of the EM algorithm). By analogy, iterate continuously until the model distribution parameters are basically unchanged, the algorithm converges, and the appropriate model parameters are found.
HMM中的隐变量是啥
HMM模型的目的就是根据观察的序列,估计“最可能”的模型。The hidden element is跳转概率和发射概率。
状态的跳转概率指的是从一个隐状态跳转到另一个隐状态的概率,而发射概率指的是如果状态是P1或P2。我们观察到序列的概率分布。
对HMM进行建模一般使用什么级别的声学单位?
我们通常对子词单元进行HMM建模。虽然词很多,但是组成词的因素是不多的,比如英语的音素也就是四五十个左右。因此我们可以对每一个phone建立一个HMM模型,而词的HMM就可以使用它的phone的HMM拼接起来。
如何为你的语音识别系统设计交叉验证?
I would use 10-fold cross validation approach.
1. Divide the entire training set S into k disjoint subsets. Assuming that the number of training examples in S is m, then each subset has m/10 training examples, and the corresponding subset is called {s1 ,s2,…,s10}.
2. Each time from the divided subsets, take one as the test set, and the other 9 as the training set
3. Train out the model
4. Put this model on the test set to get the classification rate
5. Calculate the average of the classification rates obtained 10 times as the true classification rate of the model or hypothesis function.
This method makes full use of all samples. But the calculation is cumbersome, requiring 10 training and 10 testing。
你用什么特征来建立你的语音识别系统?
在语音识别和说话人识别中,常用的语音特征是基于Mel频率的倒谱系数。由于MFCC参数是将人耳的听觉感知特性和语音的产生机制相结合,因此大多数语音识别系统中广泛使用这种特征。除了可以使用MFCC之外,基音也被常用来区分语音的性别。由于男性和女性的基音的频率范围不同,一般来说男性的基音频率会比女性低,所以基音也是判断语音的性别的一个标准。
参照正常的生理年龄,概述一名75岁女性与35岁女性说话者的语音音调和共振峰频率的典型特征。
随着年龄的增长,女性的音调频率逐渐降低。 35岁女性的音调频率约为190HZ,但到75岁时,音调频率已降至140HZ左右。
共振峰频率(F1-F3):降低
说话者验证系统中的说话人间和说话人自身可变性是什么意思?举两个例子。 每个对系统的性能有什么影响,哪个更有影响力。 给出明确的答案理由。
说话人间的可变性是指说话者之间的差异,而说话人自身的可变性是指说话人自身之间的差异。
健康,情绪和年龄的差异可能会导致会话期间的差异。例如,当人们感冒时,他们的声音可能会降低。
不同人的声音之间的差异是会话间的可变性
人与人之间在发音器官上存在差异,例如和弦和声管的差异。
不同的人在说话习惯上有差异,包括方言节奏普通词汇和语音怪异语言等。
我们希望说话者在我们使用的训练数据中的差异更大,而说话者本身比其他人更小,以便我们可以建立一个更加稳定和强大的系统
在说话人识别系统中,我们尝试通过平均语义信息以提取包含语音信号的人格因素来从语音信号中提取语义信息,从而强调不同个体之间的差异。
因此,说话人之间的可变性对我们更具影响力。
解释在GMM-UBM说话者验证系统中使用对数似然比测试的原因,您的答案应包括相关方程式,以说明该方法的工作原理。



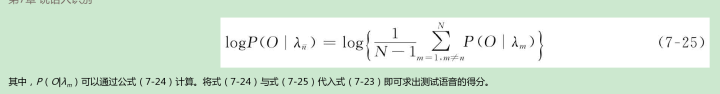
参考语音的源-滤波模型,描述语谱图中一个元音和一个摩擦的区别特征
从宽带频谱图中可以看出,元音显示出垂直条纹。 因为宽带频谱图滤波器的脉冲响应宽度与音调周期大约相同,所以这些垂直条纹之间的间隔时间就是音调周期。
在窄带频谱图中,可以看到元音的共振峰频率及其随时间的变化,并且可以看到浊音区域的谐波。
辅音通常比元音短,并且在声道急剧变化时能量,发音较少,其特征通常受随后的元音影响,因此分析比元音复杂。
在浊音期间,看不到浊音期间的垂直条纹,但是可以看到细密的杂乱纹理,这可以解释清音的白噪声激励的性质。
对于元音,从宽带谱图可以看出,谱图呈现垂直条纹。
由于宽带谱图滤波器的脉冲响应宽度与基音周期大致相同,所以这些垂直条纹之间的间隔时间就是基音周期。
在窄带谱图中,可以看到元音的共振峰频率及其随时间的变化,可以看到浊音区的谐波。
窄带频谱图和宽带频谱图有什么区别?请解释一下每种频谱图中发现了什么不同的信息,以及如何构造它们
根据带通滤波器的宽度,频谱图可分为宽带频谱图和窄带频谱图。
宽带频谱图的频率分辨率通常为300MHz- 400Hz,时间分辨率为2〜5ms。
窄带频谱图的频率分辨率为50-100Hz,时间分辨率的长度为5〜10ms。
进行语音分析时,如果窗函数的长度较长,则得到窄带频谱图,相反,如果窗函数的长度较短,则得到宽带谱图。
从窗户的长度来看,如果窗户覆盖多个音调周期-----窄带
如果窗口仅覆盖一个音调周期----宽带
概述从语音中提取MEL频率谱特征的过程。
您希望在此过程中保留语音信号中的哪些信息?为什么?
MFCC倒谱系数计算过程如下:
(1)将信号进行分帧,预加重和加汉明窗处理,然后进行短时傅里叶变换得到其频谱;
(2)求出频谱平方,即能量谱,并用M个Mel带通滤波器进行滤波,由于每一个频带中分量的作用在人耳中是叠加的,因此将每个滤波频带内的能量进行叠加,这时第k个滤波器输出功率谱x′(k);
(3)将每个滤波器的输出取对数,得到相应频带的对数功率谱;并进行反离散余弦变换,得到L个MFCC系数,一般L取12~16,如下式所示:
(4)这种直接得到的MFCC特征作为静态特征,将这种静态特征做一阶和二阶差分,得到相应的动态特征。
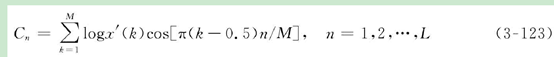
MFCC的物理含义是通过对语音识别领域中的物理语音信息(频谱包络和细节)进行编码而获得的一组特征向量。
这些都是语音物理信息,已被科学证明对语音识别非常有效。
参考书籍:
语音信号处理(第三版),张磊,韩纪庆,郑铁然著,清华大学出版社。
本文作者:淡淡的哈皮
有用就点个赞吧
最后
以上就是俭朴玉米最近收集整理的关于函数或变量 rtenslearn_c 无法识别_语音识别小结的全部内容,更多相关函数或变量内容请搜索靠谱客的其他文章。








发表评论 取消回复