最近在k8s环境上,碰到udp丢包的问题,测试拓扑图如下,
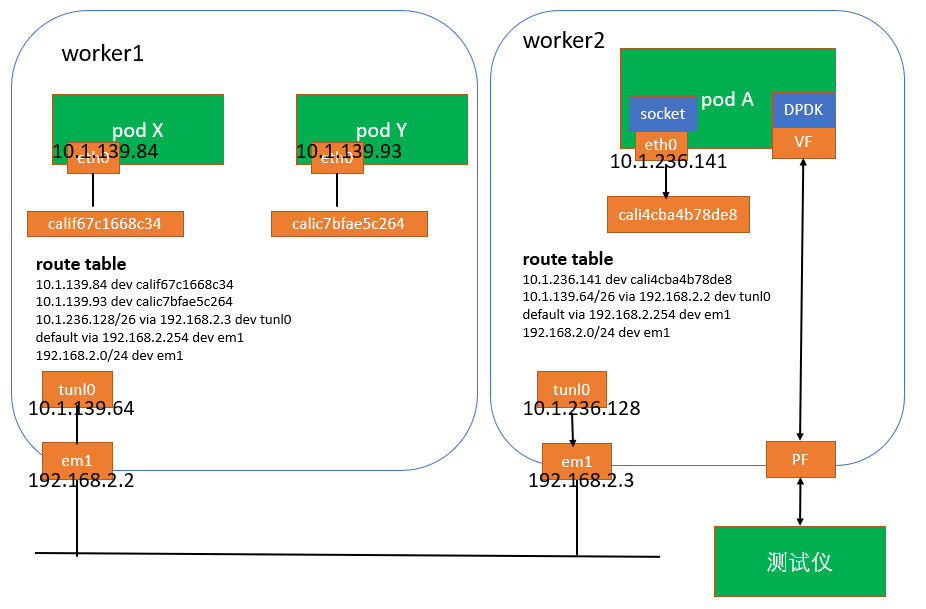
image.png
测试仪发送某种类型的报文进行性能测试,报文目的mac为VF的mac。对于发出去的每个报文,必须在3s内收到响应,否则认为丢包,会重新发送一次,此时会有retransmit的统计。
pod A有两个网卡,eth0(calico cni创建)和VF(sriov cni创建)。pod内部还运行着一个多线程进程,一个收包线程通过DPDK从VF收包,然后round robin分发到四个工作线程,这四个线程收到报文后,会封装一层udp(目的port固定,源port使用全局变量控制在一个范围内,四个线程每次获取一个port号后加一,注意此过程对全局变量操作没加锁),和一层ip(目的ip为service ip,源ip为pod A的eth0上的ip),然后调用原始套接字接口,将封装后的报文从eth0发给service ip。
pod X和pod Y是service的后端endpoint,通过socket从eth0收包处进行理。
问题描述:在测试仪上观察到大量retransmit计数。
问题分析:既然有retransmit,肯定是有丢包的,接下来重点分析为什么丢包,包被丢在什么位置。
a. 因为测试仪速率很大,最开始怀疑是达到性能瓶颈了,但是将速率降下来(每秒一百个报文左右)后发现仍然有retransmit计数,而且线程的cpupin都是没有问题的,不存在抢占问题,所以应该不是性能问题。
b. 降到速率后,观察到在VF处的收包统计,调用socket接口从eth0发包计数和测试仪是可以对上的,说明是在pod A的eth0发往service的路径上被丢弃的。
c. 查看drop计数。在pod A的eth0发往service的路径走的是kernel协议栈,既然丢包了大概率是有drop计数的,在报文路径上查看了如下几个drop计数,结果一无所获,很是遗憾。
1. 网卡计数:ip -s link show dev
2. 软中断计数: cat /proc/net/softnet_stat
3. snmp中关于udp丢包计数(pod内部查看):cat /proc/net/snmp
d. 接下来就是抓包了,按照前面的拓扑图,抓包路径也比较清楚。分别在pod内部的eth0,worker的calixxx,tunl0和em1抓包。结果是在pod A的eth0和worker2的cali4cba4b78de8上能抓到两个报文(第一个为在后面流程被drop的,第二个为retransmit的),但是在worker2上的tunl0,em1和worker1上的pod中只能抓到retransmit的报文,说明报文肯定是在worker2上tunl0封装ipip报文之前被丢弃的。
e. 重点分析worker2上,报文从cali4cba4b78de8发出去到tunl0封装之间都有哪些流程。如下图,中间需要经过conntrack和nat模块处理。
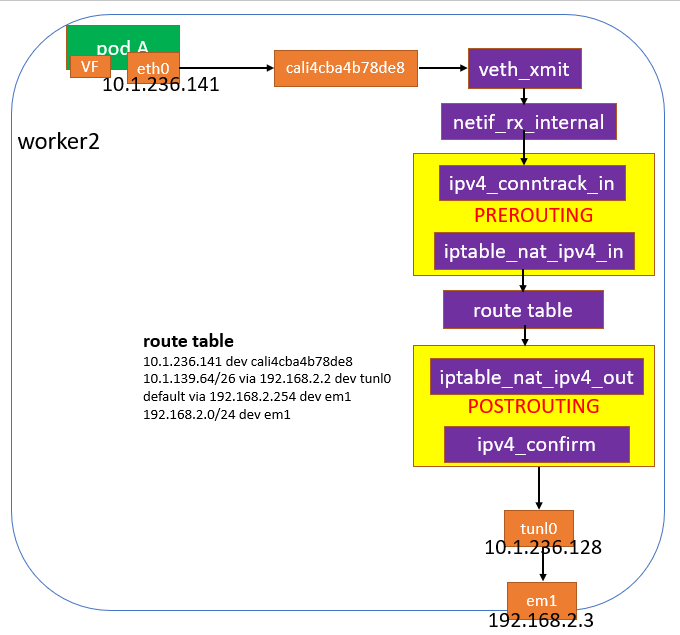
image.png
报文从pod A经过eth0发出去后,会到达cali4cba4b78de8,然后进入worker2内核协议栈netif_rx_internal,在PREROUINT链上,报文首先经过连接跟踪模块ipv4_conntrack_in的处理,如果此报文是一条数据流的首包的话,查找全局链表肯定是找不到的,就会创建conntrack表项,并将表项添加到percpu的未确认链表上,然后经过nat模块时,查到dnat规则,修改目的ip和port,重新查找路由表。
在POSTROUTING链上,在ipv4_confirm函数中,会将conntrack表项从percpu的未确认链表上删除,同时添加到全局链表上。
这里有一个问题,假如数据包A和数据包B有相同的五元组,并且从两个cpu对应的线程发出,在ipv4_conntrack_in阶段,在全局链表查找不到表项,就会创建两个完全一样的conntrack表项(original和reply方向的tuple完全一样),后面经过dnat后,虽然reply的tuple可能会改变,但是original的tuple一直是不变的。在ipv4_confirm阶段,将两个tuple添加到全局链表时,如果数据包A的origianl和reply tuple先添加成功,那么当数据包B添加时,就会发现orginal的tuple已经存在了,就会丢弃数据包B,同时增加统计计数 insert_failed,代码如下
__nf_conntrack_confirm(struct sk_buff *skb)
/* See if there's one in the list already, including reverse:
NAT could have grabbed it without realizing, since we're
not in the hash. If there is, we lost race. */
hlist_nulls_for_each_entry(h, n, &net->ct.hash[hash], hnnode)
if (nf_ct_tuple_equal(&ct->tuplehash[IP_CT_DIR_ORIGINAL].tuple,
&h->tuple) &&
zone == nf_ct_zone(nf_ct_tuplehash_to_ctrack(h)))
goto out;
hlist_nulls_for_each_entry(h, n, &net->ct.hash[reply_hash], hnnode)
if (nf_ct_tuple_equal(&ct->tuplehash[IP_CT_DIR_REPLY].tuple,
&h->tuple) &&
zone == nf_ct_zone(nf_ct_tuplehash_to_ctrack(h)))
goto out;
out:
nf_ct_add_to_dying_list(ct);
nf_conntrack_double_unlock(hash, reply_hash);
NF_CT_STAT_INC(net, insert_failed);
local_bh_enable();
return NF_DROP;
再次分析下抓到的数据包发现每次丢包时,被丢的数据包和上一个数据包的五元组是完全相同的。因为同一个线程,源port是递加的,所以这俩个五元组完全一样的数据包应该是两个线程发送,正好符合上面的分析。
通过下面命令查看了下计数insert_failed,复现问题时果然在涨。
cat /proc/net/stat/nf_conntrack
或者
conntrack -S
[worker-2 ~]# cat /proc/net/stat/nf_conntrack
entries searched found new invalid ignore delete delete_list insert insert_failed drop early_drop icmp_error expect_new expect_create expect_delete search_restart
00000384 002f80e4 0f355850 00133416 0000dcc2 0006755f 0012688f 0006726d 00073df4 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000384 0003ae27 014d9677 0001d72b 000000e3 0006849d 00034c22 000318dd 0001a3e6 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000384 0003a791 014a3151 0001d96a 000000de 00068456 0002b175 00027d3c 0001a531 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
00000384 000393e7 0147cbbf 0001d4a6 000000ba 0006709a 00024252 00020edd 0001a131 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
现在肯定就是这个问题导致的,如何修改来验证呢?只要修改代码将四个线程发包时的源port写成固定,就不会有五元组完全一样的数据包了。
总结
此问题复现条件:
a. 多线程或者多进程,并且运行在不同的cpu上。只有不同cpu上的线程/进程才会真正并发执行,在链接跟踪表查找时才有可能出现冲突。
b. 相同的五元组。
后来上网查了下,这个问题在18年就被发现了,可以参考下此问题的root cause和如何fix
https://www.weave.works/blog/racy-conntrack-and-dns-lookup-timeouts
虽然fix了,但是计数insert_failed依然会增长,只不过不会丢包而已。
而且网上有如下两个说法
a. 只有udp才会出现此问题,tcp不会出现。这个说法也没错,因为在正常使用时,udp socket不用经过三次握手,每个线程可以直接调用udp socket发包,而tcp socket一般会在某个线程上创建,并且经过三次握手,此时会创建连接跟踪表项,所以即使有多个线程通过调用tcp socket发包,也不会有冲突。协议工作方式有关,而跟协议报文没关系。后面会使用原始套接字发送udp和tcp报文,都可以复现问题。
b. 多个线程同时调用同一个socket发包。这个说法的意思只是为了保证五元组是相同的,因为同一个socket源port和源ip是不变的。其实使用多个原始套接字同时发包也能出现此问题。
复现
如下代码,创建四个线程,每个线程创建一个udp类型的原始套接字同时发包,目的port为80,目的ip为2.2.2.4, 源ip为2.2.2.2,源port不断变化。
root@node2:~# cat udp_client.c
#include <sys/socket.h>
#include <sys/ioctl.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <linux/if.h>
#include <linux/udp.h>
#include <linux/ip.h>
#include <linux/if_ether.h>
#include <linux/if_packet.h>
#include <net/ethernet.h>
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
#define __USE_GNU
#include<sched.h>
#include<ctype.h>
#include<string.h>
#include<pthread.h>
#define THREAD_COUNT 4
struct sockaddr_in sin;
unsigned char sendBuf[sizeof(struct ethhdr) + 60];
int info[THREAD_COUNT];
int sockfd[THREAD_COUNT];
static int source_port;
static int source;
static int last_use[THREAD_COUNT];
unsigned short checksum(unsigned short *buf,int nword)
{
unsigned long sum;
for(sum=0;nword>0;nword--)
{
sum += *buf++;
sum = (sum>>16) + (sum&0xffff);
}
return ~sum;
}
#define PORT_RANGE_START (40000)
#define PORT_RANGE_END (65535)
#define PORT_RANGE_MASK (PORT_RANGE_END - PORT_RANGE_START)
uint16_t get_port(uint32_t seed)
{
return (seed & PORT_RANGE_MASK) + PORT_RANGE_START;
}
int create_socket(int index)
{
//套接字
sockfd[index] = socket(AF_INET, SOCK_RAW, IPPROTO_UDP);
if (sockfd[index] == -1)
{
perror("create socket fail");
return 0;
}
int daddr = inet_addr("2.2.2.4");
sin.sin_family = AF_INET;
sin.sin_port = htons(80);
sin.sin_addr.s_addr = daddr;
int val = 1;
if (setsockopt(sockfd[index], IPPROTO_IP, IP_HDRINCL, &val, sizeof(val)) < 0)
{
printf("IP_HDRINCLn"); return 0;
}
//填充IP头部
struct iphdr ipheader;
memset(&ipheader, 0, sizeof(struct iphdr));
ipheader.version = 0x4;
ipheader.ihl = 0x5;
ipheader.tos = 0x00;
ipheader.tot_len = htons(60); //20 + 8 + 32
ipheader.id = 0x1000;
ipheader.frag_off = 0x0000;
ipheader.ttl = 128;
ipheader.protocol = 17;
ipheader.check = 0;
ipheader.saddr = inet_addr("2.2.2.2");
ipheader.daddr = daddr;
ipheader.check = checksum((void *)&ipheader, sizeof(struct iphdr));
struct udphdr udpheader;
udpheader.source = htons(1000);
udpheader.dest = htons(80);
udpheader.len = htons(40);
udpheader.check = 0;
memset(sendBuf, 0, sizeof(sendBuf));
memcpy(sendBuf, &ipheader, sizeof(struct iphdr));
memcpy(sendBuf + sizeof(struct iphdr), &udpheader, 8);
}
void *worker(void *arg)
{
int *a = (int *)arg;
int index = *a;
printf("the index is: %dn", index); //显示是第几个线程
cpu_set_t mask; //CPU核的集合
CPU_ZERO(&mask); //置空
CPU_SET(index, &mask); //设置亲和力值
if (sched_setaffinity(0, sizeof(mask), &mask) == -1)//设置线程CPU亲和力
{
printf("warning: could not set CPU affinity, continuing...n");
}
create_socket(index);
while (1) {
if (source == last_use[index])
continue;
struct udphdr* udpheader = NULL;
udpheader = (struct udphdr*)(sendBuf + sizeof(struct iphdr));
last_use[index] = source;
udpheader->source = htons(source);
udpheader->check = 0;
udpheader->check = checksum((void *)udpheader, 40);
printf("source port is %d on thread %d socket: %dn", udpheader->source, index, sockfd[index]);
int len= sendto(sockfd[index], sendBuf, sizeof(sendBuf), 0, (const struct sockaddr*)&sin, sizeof(struct sockaddr));
if (len > 0)
printf("send success.n");
else
perror("send fail");
}
}
int main(void)
{
int i = 0;
//创建多个线程
for (i = 0; i < THREAD_COUNT; i++) {
pthread_t p_info = (pthread_t)malloc(sizeof(pthread_t));
info[i] = i;
int err = pthread_create(&p_info, NULL, &worker, (void*)&info[i]);
if (err != 0) {
printf("pthread create failedn");
}
}
//每隔一段时间就更新源port
i = 0;
while (i != 10000) {
source = htons(get_port(source_port++));
usleep(1000);
i++;
}
return 0;
}
下面编译程序,开始复现
//配置ens8 ip为2.2.2.2/24
root@node2:~#ifconfig ens8 2.2.2.2/24
//2.2.2.4是不存在的,所以需要配置静态arp
root@node2:~#arp -s 2.2.2.4 00:00:00:00:00:01
//编译
root@node2:~#gcc -o udp udp_client.c -lpthread
//程序执行前,查看计数
root@node2:~# conntrack -S
cpu=0 found=0 invalid=57309 ignore=1171 insert=0 insert_failed=2636 drop=1730 early_drop=0 error=0 search_restart=3215
cpu=1 found=0 invalid=53922 ignore=1368 insert=0 insert_failed=3344 drop=2464 early_drop=0 error=0 search_restart=3048
cpu=2 found=0 invalid=61931 ignore=1591 insert=0 insert_failed=2573 drop=2035 early_drop=0 error=0 search_restart=2669
cpu=3 found=0 invalid=59014 ignore=383 insert=0 insert_failed=1124 drop=571 early_drop=0 error=0 search_restart=1790
//执行程序一段时间,比如一分钟
root@node2:~#./udp
//再次查看计数,可看到insert_failed已经在涨了
root@node2:~# conntrack -S
cpu=0 found=0 invalid=57309 ignore=1171 insert=0 insert_failed=2637 drop=1730 early_drop=0 error=0 search_restart=3215
cpu=1 found=0 invalid=53922 ignore=1368 insert=0 insert_failed=3345 drop=2464 early_drop=0 error=0 search_restart=3048
cpu=2 found=0 invalid=61931 ignore=1591 insert=0 insert_failed=2573 drop=2035 early_drop=0 error=0 search_restart=2669
cpu=3 found=0 invalid=59014 ignore=383 insert=0 insert_failed=1126 drop=571 early_drop=0 error=0 search_restart=1790
参考
此问题的复现方法和fix时的log
https://github.com/brb/conntrack-race
腾讯云-k8s网络疑难杂症排查分享
https://segmentfault.com/a/1190000020069368?utm_source=tag-newest
也可参考:k8s之udp丢包问题 - 简书 (jianshu.com)
最后
以上就是勤劳铃铛最近收集整理的关于k8s之udp丢包问题总结复现参考的全部内容,更多相关k8s之udp丢包问题总结复现参考内容请搜索靠谱客的其他文章。








发表评论 取消回复