对于分帧加窗,可以分为三步,第一步是弄清楚为什么要进行分帧加窗?第三步是搞清楚如何实现分帧加窗操作?最后是代码实现。
1、为什么要进行分帧加窗操作?
语音信号为非平稳信号,其统计属性是随着时间变化的,以汉语为例,一句话中包含很多生母和韵母,不同的拼音,发音的特点很明显是不一样的;但是,语音又具有但是平稳的属性,比如汉语里的一个声母或者韵母,往往只会持续几十到几百毫秒,这一个发音单元里,语音信号表现出明显的稳定性、规律性,在进行语音识别时,对于一句话识别的过程也是以较小的发音单元(音素、字、字节)为单位进行识别的,因此可以用滑动窗来提取短时片段,也即进行分帧加窗操作。【注:加粗部分来源于孙思宁博士的课和课件】
2、如何进行分帧加窗操作?
2.1 相关术语
帧长:一帧语音信号的长度,长度可以用多种方式表示,如果用时间表示,一帧信号通常取在15ms-30ms之间,经验值为25ms(论文上大多数人用)。帧长为25ms的一帧信号指的是时长有25毫秒的语音信号。也可以用信号的采样点数来表示,如果一个信号的采样率为16kHz,则一帧信号由 16kHz * 25ms = 400个采样点组成。
帧移:指的是每次分帧时移动的距离,以第一帧信号的起始点开始移动一个帧移,开始下一帧。同样也可以用两种方式表示,用时间表示,常设为10ms,用采样点表示,16kHz采样率的信号帧移一般为160个采样点。
加窗:分帧后每一帧的开始和结束都会出现间断,因此分割的帧越多,与原始信号的误差就越大,加窗就是为了解决这个问题,使成帧后的信号变得连续,并且每一帧都会表现出周期函数的特性。常见的窗函数有:矩形窗、汉明窗、汉宁窗等,在语音信号处理中,通常使用汉明窗,其公式如下:
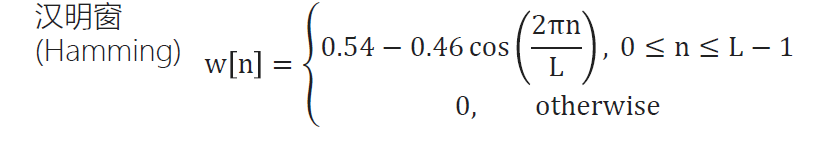
2.2 分帧加窗的具体操作
首先要根据信号长度、帧移、帧长计算出该信号一共可以分的帧数,帧数的计算公式如下:
帧数 = (信号长度-帧长)➗帧移 +1
具体的分帧操作如下图所示:
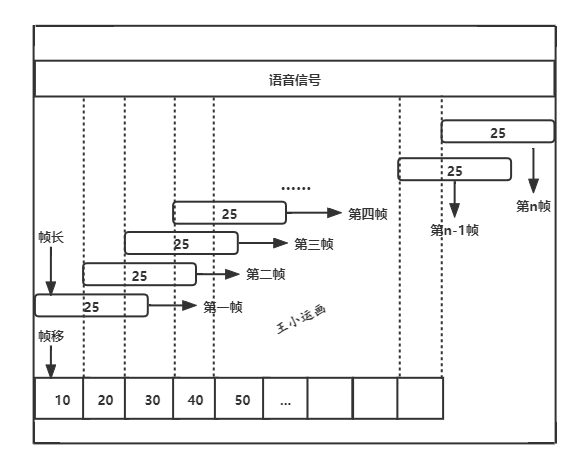
图2-1 分帧的具体操作
加窗操作比较简单,仅需将分帧的每一帧信号一次与窗函数进行相乘即可,其中窗函数可以从numpy里直接调用。
在分帧操作时,会遇到最后剩下的信号长度不够一帧的情况,此时需要将对这一段信号进行补零操作,使之达到一帧的长度,或者可以直接将之抛弃,因为最后一帧处于句子最末尾部分,大部分为静音片段。
3 分帧加窗的代码实现
以下是实现分帧加窗的具体代码
def enframe(signal, frame_len=frame_len, frame_shift=frame_shift, win=np.hamming(frame_len)):
"""
calculate the number of frames:
frames = (num_samples -frame_len) / frame_shift +1
"""
num_samples = signal.size
num_frames = np.floor((num_samples - frame_len) / frame_shift)+1
# calculate the numbers of frames
frames = np.zeros((int(num_frames),frame_len)) # (num_frames,frame_len)
# Initialize an array for putting the frame signals into it
for i in range(int(num_frames)):
frames[i,:] = signal[i*frame_shift:i*frame_shift + frame_len]
frames[i,:] = frames[i,:] * win
return frames其中需要注意以下几点:
①signal代表经过预加重后的信号,frame_len为帧长,frame_shift为帧移。
②np.hamming(frame_len)实现了汉明窗函数。
③上面的代码中,如果计算出信号长为5.2帧,则取为5帧,因为最后一帧一般都是静音信号,可以省略。初始化一个存放帧信号的数组frames,然后依次将signal信号里的数据按照分帧操作赋值给frames。
④如果输入信号的采样率为16kHz,帧长为400个采样点,帧移为160个采样点,则经过分帧加窗后得到的数组的形状为(帧数行,帧长列)。
若有写错之处,请各位朋友帮忙指正!
最后
以上就是虚幻老鼠最近收集整理的关于语音预处理之分帧加窗的全部内容,更多相关语音预处理之分帧加窗内容请搜索靠谱客的其他文章。








发表评论 取消回复