多智能体强化学习在城市交通网络信号 控制方法中的应用综述
交通信号控制系统在物理位置和控制逻辑上分散于动态变化的网络交通环境, 将每个路口的交通信号控制器看做一个异质的智能体, 非常适合采用无模型、自学习、数据驱动的多智能体强化学习(MARL) 方法建模与描述。
本文系统回顾了现有MARL方法在城市道路交通网络信号控制中的研究和应用, 探讨了将 MARL应用于大规模区域交通控制的关键问题。
为了研究该方法的现状、存在问题及发展前景, 论文跟踪了多智能体强化学习在国内外交通控制领域 的具体应用, 包括:交通信号 MARL 控制概念模型、完全孤立的多智能体强化学习的控制、 部分状态合作的多智能体强化学习控制、动作联动的多智能体强化学习控制。
背景
Multi agent reinforcement learning based traffic signal control for integrated urban network: survey of state
多智能体强化学习(multi-agent reinforcement learning, MARL)
MARL控制可根据控制效果的反馈信息自主学习并优化策略知识,是一种真正的闭环反馈控制。
1 交通信号MARL控制基本概念
1. 1 RL交通控制标准模型
交通信号 RL 智能体的标准模型如图1 所示。 每个路口的交通信号机被抽象为一个智能体, 控制对象为道路交通网络上的时变交通流。
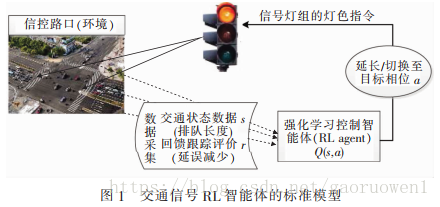
RL 智能体与被控对象在闭环系统中不断进行交互, 通过观察交通环境的实时状态, 提取信号控制所需的交通状态信息和反馈奖励信息, 选择相应的行为动作并执行; 进而跟踪评测所选择动作的控制效果, 以累积回报收益最大化为目标, 优化控制策略直至收敛到状态和动作的最优概率映射。
因此, RL智能体将控制系统的优化过程按照时间进程划分为状态相互联系的多个阶段, 并在每个阶段根据当前状态进行最优决策, 这是典型的马尔可夫决策过程MDP 。相较于动态规划求解 MDP需要系统状态转移概率和反馈函数模型, RL将学习看做是试错过程。
1. 2 RL交通控制优化技术
根据 RL智能体学习频率及优化参数的不同, 交通信号RL优化技术分为周期式 和 非周期式控制两种类型。
周期式RL控制:在相位结构和相位顺序固定的前提下,以周期、绿信比和相位差作为控制方案的优化参数, 每隔当前周期的整数倍时间间隔, 采用RL算法对这些参数进行优化调整
非周期式RL控制:遵循感应信号控制的逻辑框架,根据时变交通流的波动, 每隔单位延长时间(1~3s), 采用RL算法对相位结构、相位顺序或相位时长进行优化, 以实时响应交通需求的变化。 这种优化技术摈弃了传统协调控制中周期和相位差的概念 , 由实际交通流即时决策相位方案及相位时长。
2 交通网络MARL控制
交通网络MARL 控制是单路口RL控制向随机博弈环境下区域交通网络的扩展, 通过多个路口RL智能体间的联动协调, 逼近网络交通流的最优均衡策略 。
由于区域内全部RL智能体同时学习和同时决策,每一个RL智能体都面临移动目标学习问题, 即本地智能体的最优策略将随着区域内其他智能体策略的变化而变化。
根据智能体间交通状态和信号动作的协调水平, 交通网络MARL控制可分为三类 : 完全独立的多智能体强化学习控制、部分状态合作的多智能体强化学习控制 和 动作联动的多智能体强化学习控制 。
2. 1 完全独立的MARL控制
此方法假设路口处于静态随机的交通环境, 即每个 RL 智能体的决策仅受路口本地状态和本地动作的影响, 只需通过在普通Q值更新规则中增加智能体i的索引下标, 将单智能体RL控制方法直接拓展并应用到多个路口即可。
整体而言, 对完全孤立的MARL 控制, RL智能体采用Q、 SARSA或R学习等时间差分RL算法进行本地最优控制,不同学者分别定义其RL智能体五类结构要素。
Wiering【20】将基于模型的 RL方法应用于小路网交通信号控制, 提出了三种RL控制系统。
缺点:
由于区域内多个RL智能体间同时学习和同时行动, 而智能体间没有协调机制, 每个智能体都面临着移动目标学习的难题,系统无法收敛到均衡的联合策略, 且孤立路口的交通状态不能有效描述过饱和的交通网络 。
改进:
为平衡不同交通状态下控制收益和出行损失, 有学者提出了多目标反馈的RL控制方法【22~24】, 这其中如何标准化设计多目标反馈函数是关键。
为解决传统表格型RL控制系统的维度灾难, 自适应动态规划方法ADP被应用于交通信号控制。 根据值函数逼近方式的不同, ADP交通控制方法可分为基于智能计算的非线性逼近【26】和带可调参数的数学逼近【27】 。 然而RL、神经网络、逼近函数等多种模型或算法的深度耦合可能致使混合MARL 控制模型的可解释性差。
2. 2 部分状态合作的MARL控制
部分状态合作的MARL 控制通过智能体间的点对点通信,获得上/下游路口的交通数据,并以此拓展本地 RL 智能体的交通状态感知空间,构造了部分状态联合的 Q 值函数, 提高其对动态随机环境的观察能力 。
s为智能体i的联合状态向量, 包括本地和邻近路口交通状态信息。
Balaji等人【19】:邻近状态和策略知识Q值共享
Aziz等人【29】: 首次将R学习应用于分散式交通信号控制;采用基于交通状态划分的反馈函数, 实现多目标控制。
Pra等人【30】:基于Q学习的分散式RL控制方法, 每个智能体根据本地路口的交通数据和邻近路口的反馈信息, 拓展本地反馈函数的结构
优点:
与完全孤立的MARL控制相比, 部分状态合作的MARL控制可更准确地响应区域内交通状态模式的变化, 系统控制效益平均提高10%以上,减少了大流量条件下排队上溯情况的发生 。
缺点:
这种控制方法仅考虑了上下游路口的简单状态标志信息, 多路口之间没有动作联动, 不能系统描述网络交通流的动态性 ;
同时,研究发现周期式RL优化技术应用于多路口协调控制存在时效性差等问题。
2. 3 动作联动的MARL控制
动作联动的MARL控制将之前单智能体的状态和动作分别替换为动态随机环境下的 联合状态 和 联合动作, 并在每一个博弈对策阶段, 估计均衡策略的值函数, 实现多个智能体间的同时对策, 通过如此反复迭代逼近最优策略 , 以此寻找随机环境下系统的唯一均衡 。
Kuyer等人【32】基于协作图 max-plus算法
EI-Tantawy等人【10】物理临近 两两对策 NSCP算法
Zhu等人【33】 概率图模型中的联合树推理 全部路口
缺点:
在动作联动的MARL控制中加粗样式,RL智能体的Q值空间将随智能体数量、状态空间及动作空间的增加呈指数级增长, 致使其值函数的存储和查询效率难以保证。
因此, 几乎所有动作联动的MARL算法的核心都是如何设计多智能体联合状态—联合动作的基础数据结构、精细协调机制和有效估计值函数, 通过协调多个智能体的动作选择, 达到唯一的系统均衡 。
3 总结
需要注意的是, 国内外学者在突破交通信号MARL控制的先进算法以逼近理论最优解的同时, 应重点关注其交通状态特征抽取、自稳定机制、多目标反馈、状态离散等一系列基础问题的认识与解析, 切实推动 MARL控制方法在工程实践中的应用。
挑战:
交通状态的特征提取: 联合学习单元的状态空间数量仍非常庞大。为克服维数灾难等难题, 自适应动态规划方法被提出。 但这类方法的好坏直接取决于逼近函数的配置和参数的选择, 这给算法的设计带来了诸多挑战。
同时,不同层级( 区域、干线、单点) 的MARL控制问题对交通状态特征的要求不同, 需要合理地抽取其数据模型的特征;否则, 模型将被过度泛化或超拟合, 数据反而将成为噪声。
多模式交通整合控制: 多数MARL研究仅考虑了机动车, 并未涉及公共交通、行人和非机动车等模式,这样就忽略了公共交通等大容量交通方式的综合效益。 可考虑设计大容量公交优先等规则, 采用多模式交通的综合效益权重, 拓展反馈奖励的结构, 以实现多模式交通的整合控制。
联动协调机制
最后
以上就是谦让画板最近收集整理的关于读书笔记 - 多智能体强化学习在城市交通网络信号的综述2018的全部内容,更多相关读书笔记内容请搜索靠谱客的其他文章。








发表评论 取消回复