文章目录
- 引言
- RK1808
- RK1808人工智能计算棒
- RK1808芯片架构
- 优势
- 极致低功耗
- 强大AI运算能力
- 面向AIoT应用的丰富接口
- 易于开发
- RK1808具体的规格信息
- RK1808测评
- NVIDA Jetson Nano、 tx1/2、Xavier
- 测评
- 规格参数
- 优势
- 树莓派3/4
- 测评
- 规格参数
- 总结
引言
AIoT开启了继物联网、人工智能后又一大想象无限的领域,同时也给智慧物联、人工智能在应用层面拓展更多可能性开启新的篇章。边缘计算对势头正盛的物联网的发展至关重要。近日,机器学习和数据科学咨询公司 Tryolabs 发布了一篇基准评测报告,测试比较了英伟达 Jetson Nano、谷歌 Coral 开发板(内置 Edge TPU)、英特尔神经计算棒这三款针对机器学习设计的边缘计算设备以及与不同的机器学习模型的组合。结果表明,无论是在推理时间还是准确度方面,英伟达的 Jetson Nano 都是当之无愧的赢家。另外他们也给出了在树莓派 3B 与英伟达 2080ti GPU 上的结果以供参考。
RK1808
RK1808人工智能计算棒
便携的边缘计算设备,有基于Movidius Myriad 2的神经计算棒一代,而后有基于Google Edge TPU的Coral神经计算棒、INTEL Myriad X的神经计算棒二代,“若派Ropal”神经计算棒,Intel加速棒等,虽然说各有特色,但还是有一个共同点,那就是不便宜,对于国内一些想开拓边缘计算领域的中小企业或者走量的企业来说,成本不是太好控制,因此推荐国产瑞芯微RK1808人工智能计算棒——一款物美价廉的深度学习开发工具。

基于RK1808 NPU芯片,主要面向基于人工智能平台以及边缘计算产品的深度学习开发者。
RK1808人工智能计算棒算是众多边缘计算设备中的佼佼者,外观时尚精致,尺寸只有60mm*19mm(差不多传统U盘大小),并且有多种颜色可选。接口采用USb3.0 Type A接口,无风扇设计,利用USB接口供电,使用时无需连接云端,即可为开发主机设备以及众多第三方的单板计算机提供基于深度学习网络模型的推理加速。
瑞芯微RK1808人工智能计算棒的内置芯片RK1808,这是在瑞芯微在CES2019消费电子展发布的一款内置高能效NPU的AIoT芯片解决方案,在硬件规格上,瑞芯微RK1808 AIoT芯片采用双核Cortex-A35架构,NPU峰值算力高达3.0TOPs,VPU支持1080P视频编解码,支持麦克风阵列并具有硬件VAD功能,支持摄像头视频信号输入并具有内置ISP。
RK1808芯片架构
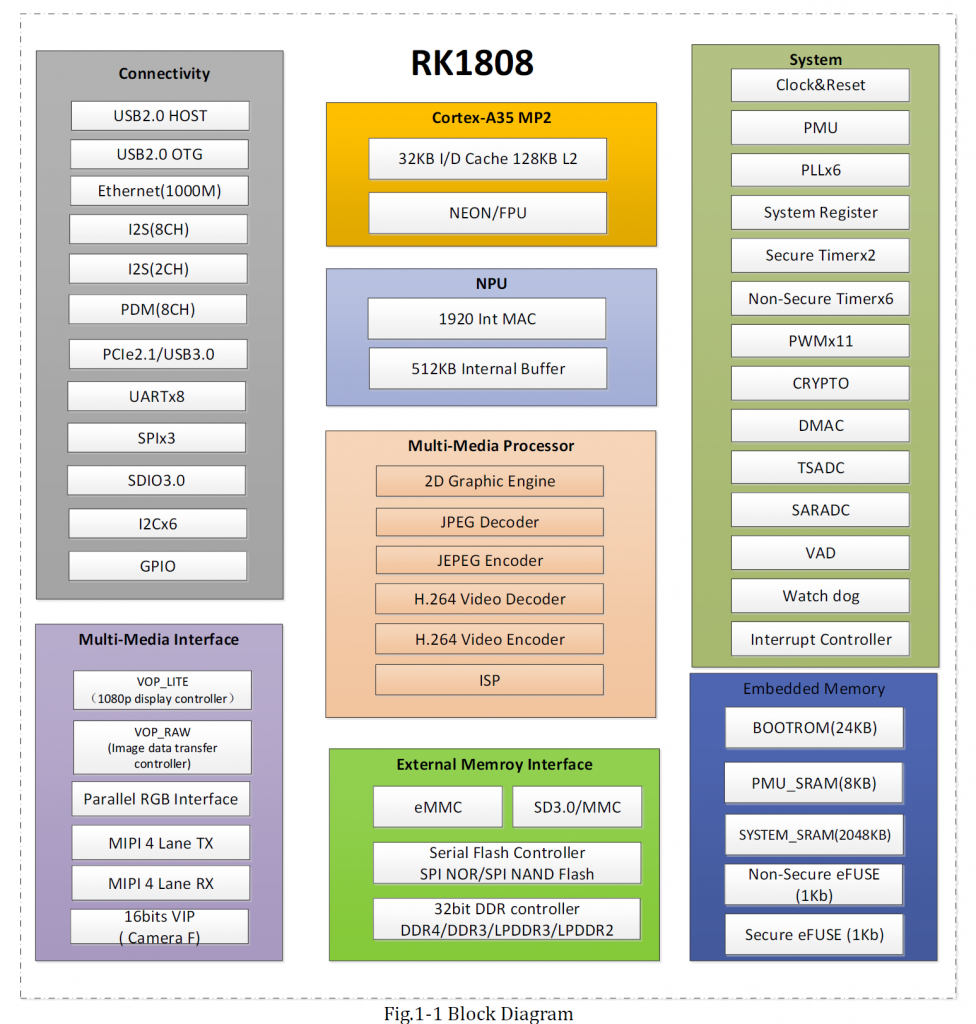
优势
极致低功耗
- 芯片采用22nm FD-SOI工艺,相同性能下功耗相比主流28nm工艺可降低30%左右;
- 内置2MB系统级SRam,可实现always-on设备无DDR运行;
- 具有硬件VAD功能,支持低功耗侦听远场唤醒。
强大AI运算能力
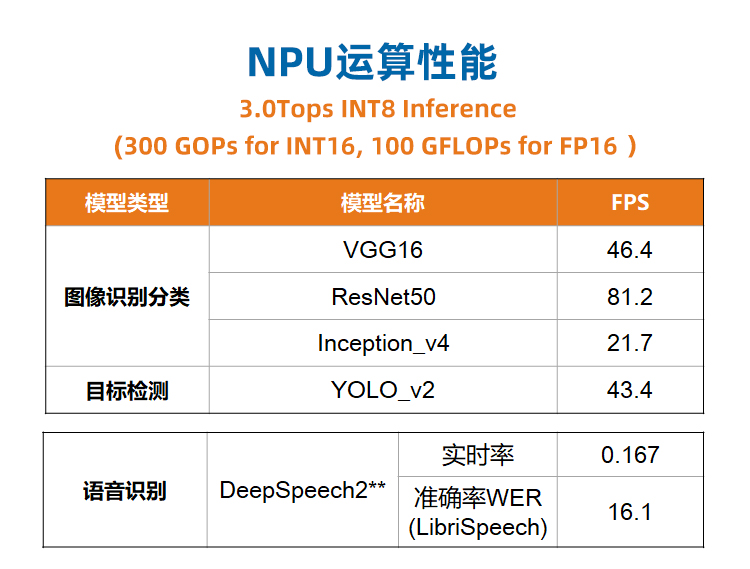
- 内置的NPU算力最高可达3TOPs;
- 支持INT8/INT16/FP16混合运算,
- 最大程度兼顾性能、功耗及运算精度;
- 支持tensorflow/MXNet/PyTorch/Caffe等一系列框架的网络模型转换,兼容性强。
面向AIoT应用的丰富接口
- RK1808具有丰富的外设接口,便于应用扩展,视频支持MIPI/CIF/BT1120输入,支持MIPI/RGB显示输出;
- 具有PWM/i2C/SPI/uart等一系列传感器输入输出接口;
- 具有USB3.0/USB2.0/PCIE等高速设备接口,支持千兆以太网及外置WiFi/BT模块;
- 音频支持麦克风阵列输入,同时支持音频输出。
易于开发
- 支持LINUX系统,
- AI应用开发SDK支持C/c++及Python,方便客户浮点到定点网络的转换以及调试,开发便捷度极强。
总所周知,AI算力是制约AI产业发展和开发者创新的痛点之一,瑞芯微RK1808 AIoT芯片平台具备的可无限量叠加、级联特性,将激活更丰富的AI应用场景与创新产品,满足产业链合作伙伴对AI高性能计算的产品需求。
RK1808具体的规格信息
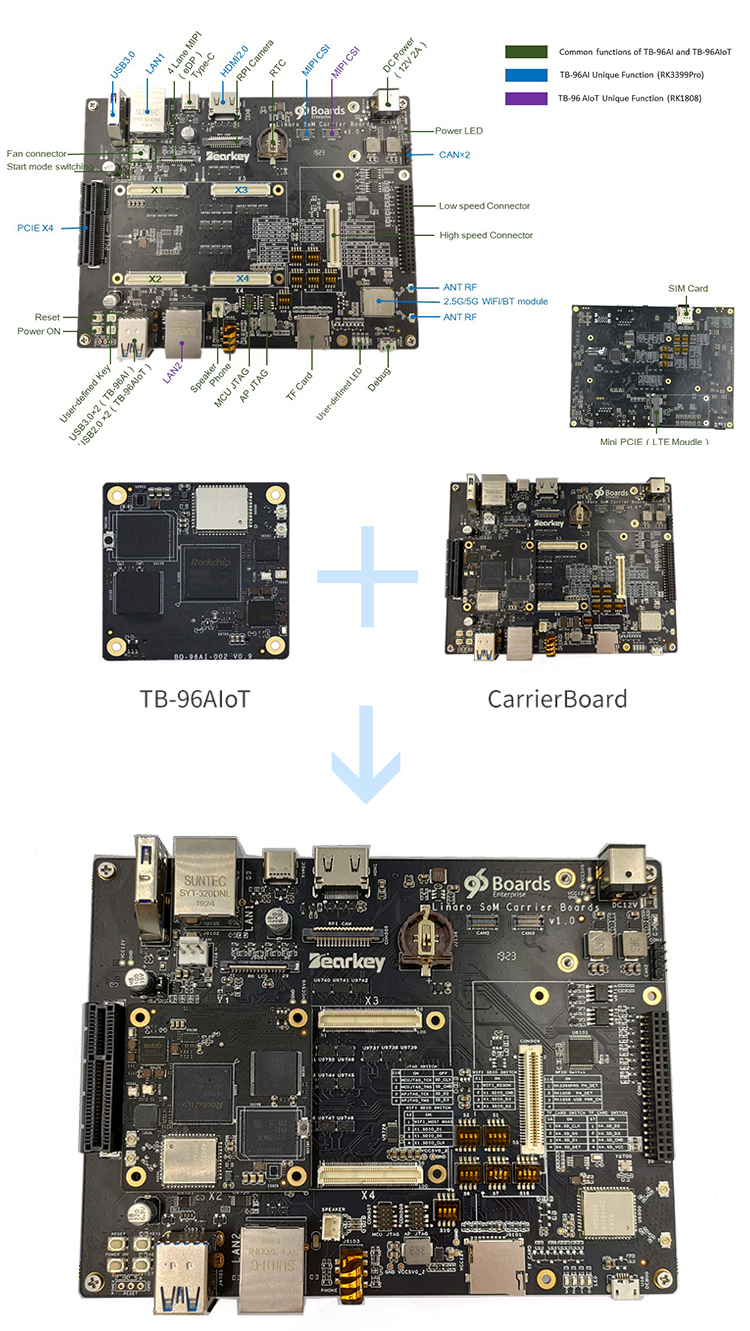
在封装上,RK1808采用FCCSP 420封装,0.3mm balls,球间距为0.5/0.35mm,说穿了这款芯片绝不适合业余爱好者去折腾,还是适合有实力的企业去开发,个人用户使用这些企业现成的产品即可,或者使用瑞芯微刚刚推出的RK1808人工智能计算棒。
- 双核Cortex-A35,内部集成2MB SRAM
- DDR 32位 数据宽度,最大支持2GB DDR3/DDR3L/LPDDR3/LPDDR3L-1600
- 集成512KB内部缓冲区的神经处理单元,支持:每个周期支持最多1920 Int8,最多192 Int16以及最多64 FP16 MAC操
- eMMC 4.5 1/4/8位,最高速率150MB/s
- SD/MMC支持
- SPI Flash x1-4-8 data
- 视频编码器/解码器高达1080p
- 视频输入DPI 8-10-12-16位高达150MB/s
- 摄像头输入MIPI CSI最多4个数据通道,2.0Gbps,MIPI-HS,MIPI-LP
- LCD RGB 8/8/8高达1280×800@60fps
- MIPI DSI 1920×1080,最多4个数据通道,2.0GbpsA
- 支持音频I2S接口、千兆以太网、USB2.0 HOST/OTG、USB3.0 5Gbps
- PCIe 1/2链路,每条链路2.5Gbps
- SPI,I2C,UART
- x4 10bit SAR adc 1Msps
- -40~125℃工作温度,针对汽车和工业视觉应用
RK1808测评

NVIDA Jetson Nano、 tx1/2、Xavier
测评
FP32(单精度)格式数据,batchsize=32,数据为吞吐量(img/s)

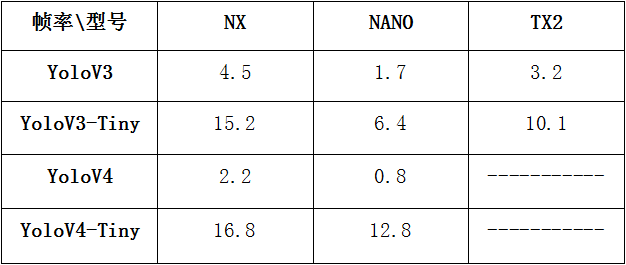
Jetson开发板测速结果
1.MaskRCNN+TensorRT在Jetson tx2上的测速
2.FasterRCNN+TensorRT在Jetson TX2上测速
3.MaskRCNN+TensorRT在Jetson Xavier上的测速
4.pytorch+FasterRCNN在Jetson Xavier上的测速
5.MaskRCNN+TensorRT在Jetson Xavier NX上的测速
6.pytorch+FasterRCNN在Jetson Xavier NX上的测速
规格参数
参照:https://www.nvidia.cn/autonomous-machines/embedded-systems/
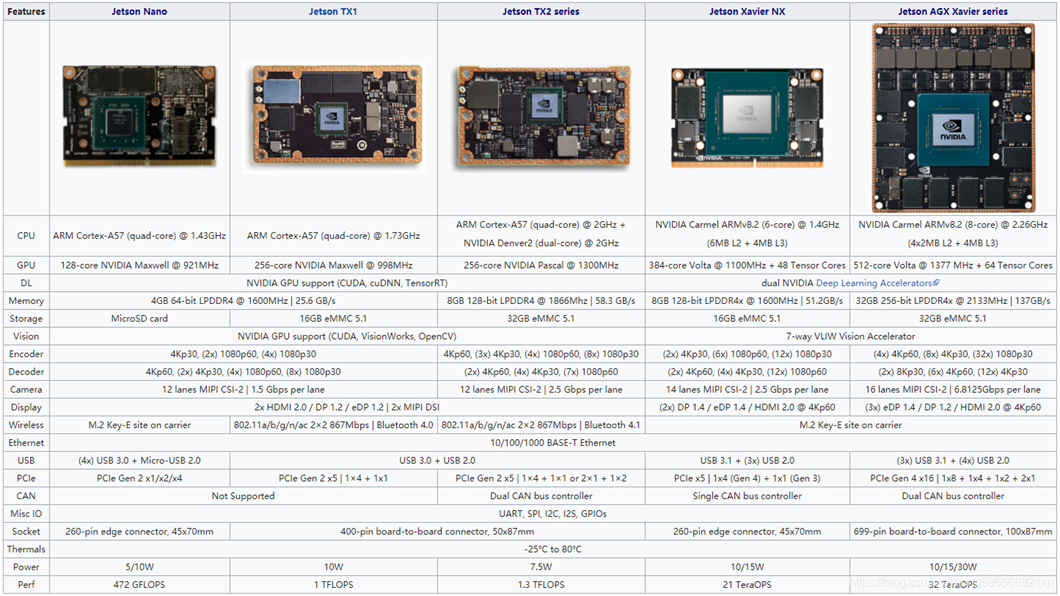
价格:

优势
- 体型小巧,性能强大,价格实惠,整体采用类似树莓派的硬件设计,支持一系列流行的AI框架,并且英伟达投入了大量的研发精力为其打造了与之配套的Jetpack SDK开发包,通过该开发包可以使学习和开发AI产品变得更加简单和便捷。
- 专为AI而设计,性能相比树莓派更强大,搭载四核Cortex-A57处理器,128/256/384/512核Maxwell GPU及4GB LPDDR内存,可为机器人终端、工业视觉终端带来足够的AI算力。
- 可提供472 GFLOP,支持高分辨率传感器,可以并行处理多个传感器,并可在每个传感器流上运行多个现代神经网络。
- 支持英伟达的NVIDIA JetPack组件包,其中包括用于深度学习、计算机视觉、GPU计算、多媒体处理等的板级支持包,CUDA,cuDNN和TensorRT软件库。
- 支持一系列流行的AI框架和算法,比如TensorFlow,PyTorch,Caffe / Caffe2,Keras,MXNet等,使得开发人员能够简单快速的将AI模型和框架集成到产品中,轻松实现图像识别,目标检测,姿势估计,语义分割,视频增强和智能分析等强大功能。
树莓派3/4
测评
以下是树莓派+intel加速棒与NVIDIA jetson性能对比:
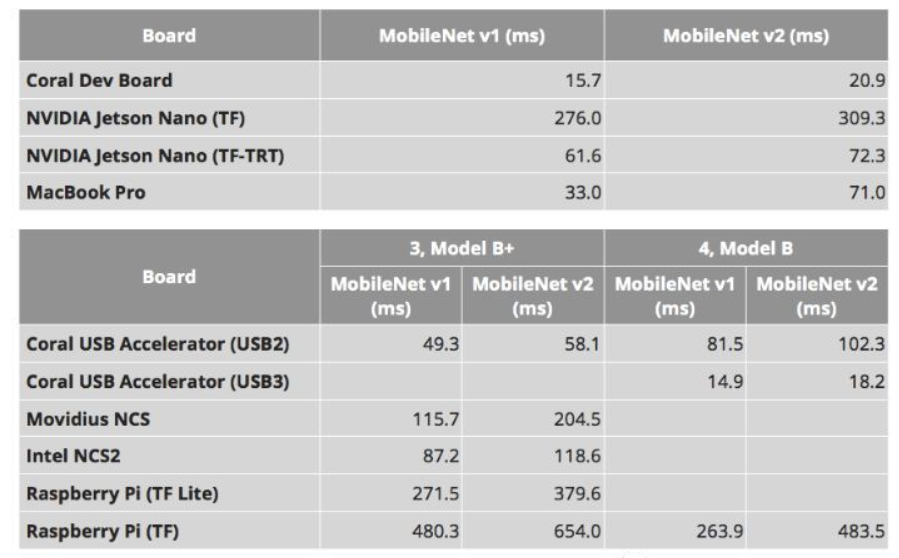
关于功耗对比:
规格参数
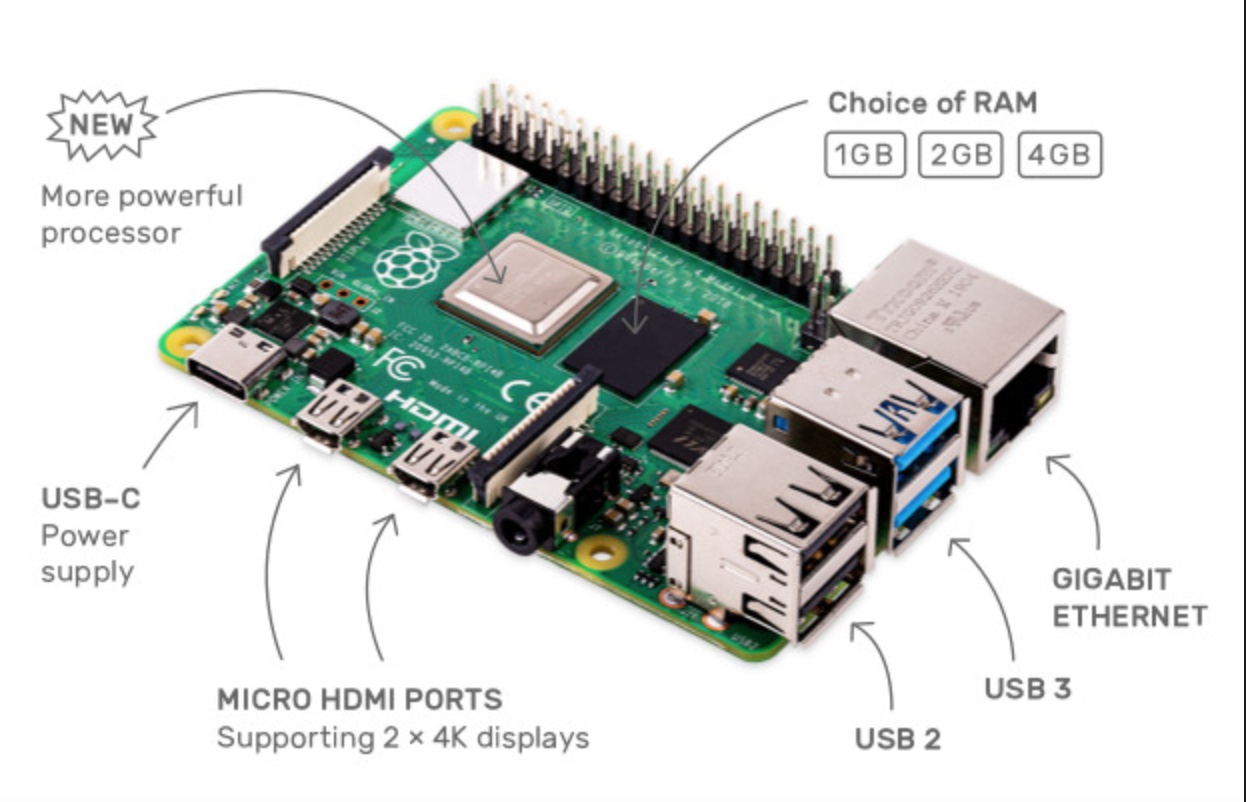
树莓派 4B 型主要硬件参数如下:
- 1.5GHz 四核 64 位 ARM Cortex-A72 芯片
- LPDDR4 SDRAM 内存,可选 1 / 2 / 4GB
- 板载全双工千兆以太网接口
- 板载双频802.11ac无线网络
- 板载蓝牙5.0
- 两个 USB 3.0 和两个 USB 2.0 接口
- 2 个 micro HDMI 输出,支持同时驱动双显示器,分辨率高达 4K
- VideoCore VI 显示芯片,支持 OpenGL ES 3.x.
- 支持 HEVC 视频 4Kp60 硬解码
- USB Type-C 供电接口
优势:
- 用上了最新的 TensorFlow Lite 之后,跑同一个数据集的速度达到了之前用 TensorFlow 时的 3 至 4 倍。
- 树莓派 4B 处理机器学习任务的算力超过树莓派 3B+ 的4倍,已经能和 NVIDIA Jetson Nano 有的一拼了。
- 如果加上 Coral USB 加速器的话,处理速度甚至能比肩 Google 的 Coral 开发板,而总价格还更便宜。
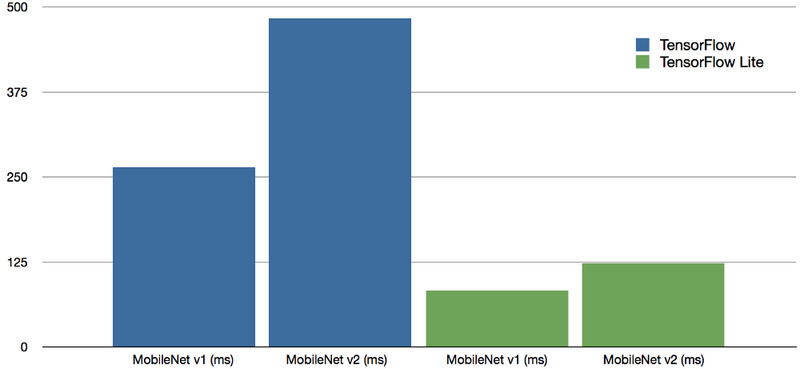
本次测试中在新树莓派 4b 上分别使用 MobileNet v1 SSD 0.75 深度模型,以及 MobileNet v2 SSD 模型进行基准测试,都使用了 Common Objects in Context (COCO) 数据集进行训练,输入图像分辨率都是 300x300,使用 TensorFlow 时运算时间分别为 263.9 毫秒和 483.5 毫秒,而使用 TensorFlow Lite 时的运算时间为 82.7 毫秒和 122.6 毫秒。
总结
新树莓派 4 带来的新能提升,使得树莓派成为了相当有竞争力的前沿机器学习处理平台。在用上 TensorFlow Lite 技术之后,树莓派 4 的处理能力得到了巨大的提升,能和专业的 NVIDIA Jetson Nano 以及英特尔神经网络计算棒 2 代一较高下。
新的树莓派 4 比 上述两种设备都便宜得多,1GB 版本的售价为 35 美元,4GB 版本的售价为 55 美元,而 NVIDIA Jetson Nano 和英特尔神经网络计算棒 2 代每个的售价都要 99 美元。特别是,对于计算棒来说,你还得买个树莓派来跟它配合使用,所以总成本将达到 134 美元。
虽然目前 Google 的 Coral 开发板依旧是同类产品中算力最强的板子,但既然有了 USB 3 加持,树莓派 4 + Coral USB 加速器的组合,价格也不过就在 109.99 美元上下,比起单价 149 美元的 Coral 开发板还是便宜了 39.01 美元,而且在性能方面甚至还略微超过了 Coral 开发板。
最后
以上就是懵懂小蝴蝶最近收集整理的关于主流边缘端部署嵌入式平台引言RK1808NVIDA Jetson Nano、 tx1/2、Xavier树莓派3/4的全部内容,更多相关主流边缘端部署嵌入式平台引言RK1808NVIDA内容请搜索靠谱客的其他文章。

![[RK3399][Android7.1] 获取gpio函数devm_gpiod_get_optional()](https://www.shuijiaxian.com/files_image/reation/bcimg8.png)






发表评论 取消回复