Tinkerpop highlevel-arch
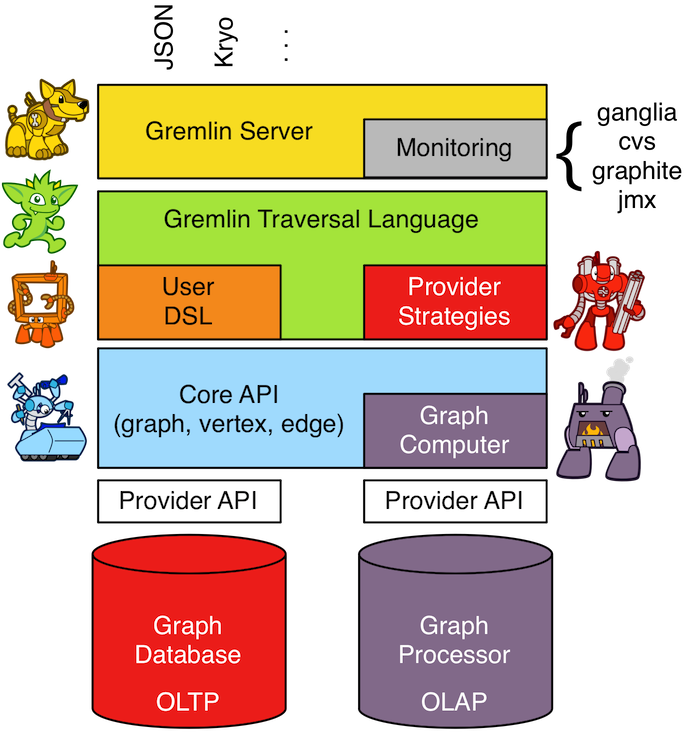
- gremlin server: httpserver/websocket server接收标准的gremlin dsl语法,自身相当于一个计算节点,完成图的遍历,或者操作DML语言,操作底层OLTP图库。
- gremlin traversal language: 图的查询遍历语言及语言解释实现,类似sqlparser
- provider strategies: vendor可自定义的策略,如对某些遍历步骤可优化,g.v("filter")可走全文搜索,而非全表scan。
- core api(for OLTP) : 图库的curd操作,包括traveral,追求低延时,高吞吐,尽量少的慢查询。
- graph computer(for OLAP) : 有MR/spark引擎,通过MR分治思想或DAG图做一些大数据处理,充分利用多机计算能力,这个规范是可选实现。
核心在于提供gremlin查询语法及引擎,类似sqlparse,把查询语言转变成执行计划。还有core-api 节点,边的抽象,为底层OLTP&OLAP引擎可以自由切换成其他厂商实现,当然也内嵌了一套内存图库实现,以供vendor参考。
OLTP和OLAP
列表数据存储在一系列列中,而在行表中,它将表记录存储在一系列行中。
oltp vs olap
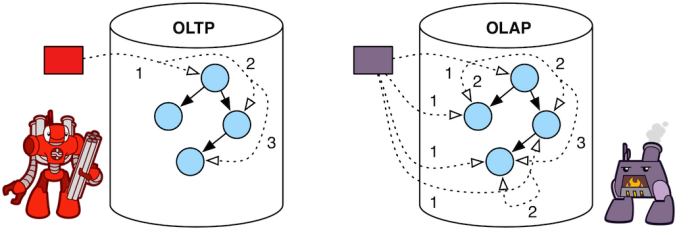
OLTP(使用行表)
实时,有限数据访问,随机数据访问,顺序处理,查询。 例如:Hbase、TinkerPop
- OLTP查询:行表用于有效地返回整行,适用于需要频繁变换表(需要根据某些条件更新/删除表行时)的OLTP方案。在这些情况下,行表与列表相比具有明显的优势。
- 点查询:行表也适用于点查询(例如,基于某些where子句条件仅选择几条记录的查询)。
- 小维度表:行表也适用于创建小维度表,因为这些表可以创建为复制表(在所有数据服务器上复制表数据)。
- 创建索引:行表还允许在表的某些列上创建索引以提高性能。
OLAP(使用列表)
长时间运行,访问整个数据集,顺序数据访问,并行处理,批处理。 例如:Spark、Hive、Cassandra
- 分析查询:列表对于OLAP查询具有明显的优势,因此建议将此类查询中涉及的大表创建为列式表。这些表很少发生变异(删除/更新)。对于列表上的给定查询,只会读取所需的列(因为只需要扫描所需的子集列),从而提供更好的扫描性能。因此,与行表相比,聚合查询在列表上执行得更快。
- 数据压缩:列表提供的另一个优点是可以高效地压缩数据,从而减少大型表的总存储空间。
列表不适用于OLTP方案。在这种情况下,建议使用行表。
JG和HG的OLTP/OLAP
一个图分析系统除了图数据库外还要有图计算引擎,主要目的是为了进行除遍历外的图算法分析。
其后端存储中,neo4j等使用自己的原生图存储,而JG/HG等则用非原生图存储,通常将图结构序列化存储到RDBMS中。
原生图存储一般都是经过专门为了存储和管理图结构而优化的,遍历查询性能很高,但掐非遍历类的查询则不占优势,且为了全局搜索还会占用大量内存。
前述的图数据库相当于OLTP,而图计算则相当于OLAP。有的图数据库也继承了少量的图计算能力,但真正的大型系统还是需要单独的计算框架。
OLTP实现方法
JG和HG集成了各大开源存储系统,如hbase,Cassandra,BerkeleyDB,以及整合开源搜索引擎,如solr, ElasticSearch. 总体来说实现了一个OLTP图库. 两者架构大体相似。
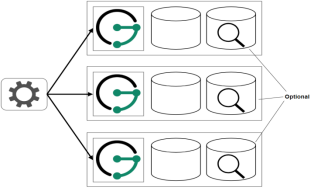
(1)极简方案

对于测试或者单应用来说,JG/HG服务可以和后端存储/索引部署在一台机器上
(2)快速上手方案对于测试或者单应用来说,JG/HG服务可以和后端存储/索引部署在一台机器上。
(下左图)这种场景是大多数用户在刚开始使用JG/HG时可能要选择的场景。它提供了可伸缩性和容错性所需要的最少服务数量。每个JG/HG服务运行在单独的存储后端和可选的索引后端。
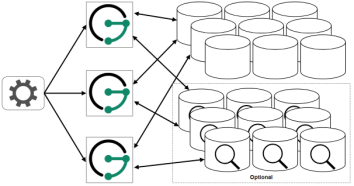
(3)建议部署方案
(上右图)JG/HG服务实例集群不和存储后端集群和索引后端集群部署在一起,他们被分配到不同的服务器上集群上。建议不同的组件集群(JG/HG服务、索引后端、存储后端)部署到不同的服务器集群上,这样能够方便扩容和管理,相互之间也互不依赖。这为维护更多的服务器提供了更高的灵活性。
(4)嵌入式方案
基于JVM的应用程序可以直接嵌入一个JG/HG包,而不用连接到JG/HG服务。虽然这样可以减少管理开销,这导致不能对JG/HG进行单独扩容。JG/HG嵌入式部署方案是其他部署方案的变种,JG/HG只是从服务器直接移动到应用程序中,因为它现在只是用作库,而不是独立的服务。
OLAP实现方法
基于图的并行计算框架,有google的Pregel,基于Spark的GraphX,Apache下的Giraph/HAMA以及GraphLab,其中Giraph是Pregel的开源实现。
OLAP标准在tinkerpop框架里面是可选的,使用自身的实现为单机内存实现,分布式的实现:
- 在janusGraph中可通过使用Spark集群进行distributed OLAP方面工作(spark仅作为底层计算层,api还用Gremlin).
- 在HugeGraph中通过hugegraph-spark工具将图数据从HG(数据源)抽取到Spark集群进行distributed OLAP方面工作(独立使用GraphX api 进行业务逻辑计算)
两者对比
图数据库组件
一个完善的图数据系统应该至少包括图存储及图处理引擎,数据导入导出,管理运维,查询和计算,商业化产品需要有高可用及容灾备份。
相同点:
| 功能 | HugeGraph | JanusGraph |
|
|
|
|
| 索引后端 | Solr、ES 等,用于加快访问速度并支持更复杂的查询语句 | |
| 分布式OLTP后端 (图存储) | 集成Hbase、Cassandra 等 都是准实时的离线图计算框架:数据按batch大小计算 | |
| 图处理 | 都是使用Tinkerpop3 | |
| 分布式OLAP引擎 | 集成Spark | |
| Gremlin遍历 (查询和计算) | 都是单机计算。复杂如PageRank等才提交给Spark | |
| 高可用及容灾备份 | 底层Hbase有,HG/JG都没实现 (以后商业版HG会实现) | |
| 水平扩展 | 支持 | |
| 不同的后端存储之间转换 | 支持 | |
| ACID特性和最终一致性 | 支持,使用HBase后端 | |
| 都没有实现分布式 (区别于存储分布式) | 从janusGraph-9.9.2章节最新的配置信息可知:
| |
| 异常处理 | 异常处理很low,经常不知道错误的原因 | |
|
|
| |
是不是titan/JanusGraph看起来很相似?!(如果在JanusGraph之上做一些封装,对接janusService和可视化那就更像了)
看其致谢果不其然,不过里面还是有创新和扩展的,如果他能持续的接纳Janus的优点并对其扩展和生态封装并长久发展的话用这个倒是不错,可惜就在。。。封装完就收费了。
HugeGraph relies on the TinkerPopframework, we refer to the storage structure of JanusGraph and the schema definition ofDataStax. Thanks to Tinkerpop, thanks to JanusGraph and Titan, thanks to DataStax. Thanks to all other organizations or authors who contributed to the project.

异同点:
| 功能 | HugeGraph | JanusGraph |
| 特性 | 把其它组件封装一下,变成自己的 | 与其他组件的交互(DIY)能力强 |
| 分布式OLAP | 集成并使用Spark-2.1.1 GranphX API (已转向收费) | 使用Gremlin API 并将Spark-2.2.x集成为底层计算引擎 |
| 可视化工具 | 仅使用自带HugeGraph-Studio | 无,可集成Cytoscape、Gephi 等 |
| OLAP复杂计算 | Titan比GraphX快,所以:JG > HG(来自知乎) | |
| 数据导入
| 仅支持本地csv,json文件导入 (更多:看Hugegraph数据导入导出总结章节) | 据说支持本地csv等文件、hdfs导入 (无参考文档)
批量导入:与HugeGraph一样需要严格的数据格式,但JanusGraph中没有实现导入数据的方法。
|
| 图管理 | 无从下手配置与创建多图 (缺少相关文档,也不支持指定OLAP引擎) | 方便从配置文件创建不同的图 1.ConfiguredGraphFactory方式,使用默认配置与后端创建图:
2.JanusGraphFactory方式,使用自定义配置指定存储后端与OLAP计算后端(如使用spark集群)等初始化图:
|
| 管理运维 管理/优化复杂性 | 难(耦合高) | 较难(集成多) |
| Schema管理模块 | 不支持自动创建schema | 支持自动创建schema |
| 高频图算法
| 封装了(ShortestPath、k-out、k-neighbor等),使用更友好
| 通过Gremlin 代码自行实现 |
| 可插入节点数 | 千万级,节点id长度超过千万插入失败 | 可过亿(JG相对于HG更大规模) |
| 节点类型 | Int/String(必须小于9位数) | Int(长整形,位数不限) |
| hbase后端版本 | Hbase-2 (可能是比Titan快点的原因) | Hbase-1 (继承了老Titan,还未做升级) |
| 社区支持 | 百度 | IBM、google等 |
| 数据量 |
| 1. 假如有 1 billion 的订单,10 billion 的边(十亿用户和商品,100以交易记录,比较符合淘宝的数据量) 分别使用上面的三种办法所需时间为:大于10天,2天,8个小时。所需要的资源量:很少(因为可以一条一条插入),很多(因为要join),比较多(需要批量导入)
|
| 边信息 | 可有无向边 | 仅支持有向边 |
| 全文检索功能 | 不支持 | 通过ES |
|
|
|
|
JanusGraph可视化工具:
Cytoscape:www.cytoscape.org/
Gephi plugin for Apache TinkerPop:tinkerpop.apache.org/docs/current/reference/
Graphexp:github.com/bricaud/graphexp
KeyLines by Cambridge Intelligence:cambridge-intelligence.com/visualizing-janusgraph-new-titandb-fork/
Linkurious:doc.linkurio.us/ogma/latest/tutorials/janusgraph/
问题
- 并没有实现真正意义上的事务。
- 没有发挥MPP思想,一个计算节点负责所有的图遍历。存储层hbase分布式化了,但自身计算节点并没有分布式化。janusGraph把hbase当做黑盒,纯客户端,图遍历拉取所有数据,没有深入定制到表格存储里面,这也是可预见可修改的地方。
- gremlin-server单机运算处理能力有限,势必要水平扩展,但core包中使用了有很多cache,有状态的,集群模式下要考虑内存状态一致性问题
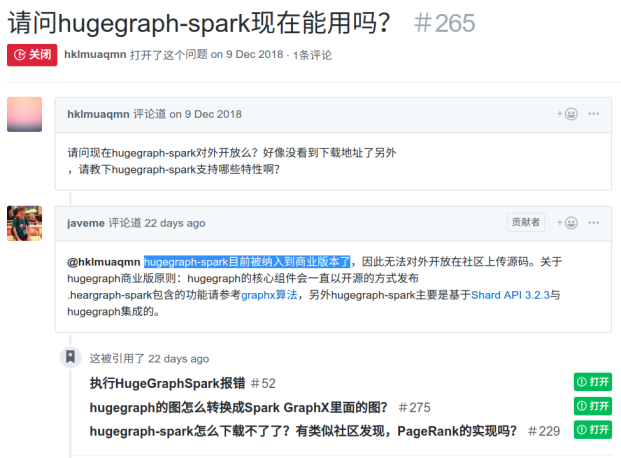
hugegraph是高可用的吗,是否支持动态扩展?--来自社区
高可用可以从多个维度来讲,包括
* 图的服务器引擎高可用,目前HugeGraphServer服务本身并没有高可用实现,只有一套简单的服务监控及失效拉起的功能(服务器的高可用在开发计划中)
* 存储后端高可用,卡桑德拉或HBase的等本身支持高可用。
× 所以,HG也并没有实现分布式
用户并发性:
如果元数据与数据都在Cassandra数据库中存储,理论上我是可以启动多个HugeGraphServer来对我服务的对吗??
:HugeGraphServer服务有缓存机制,元数据和图数据都会缓存,多个HugeGraphServer同时连一个Cassandra后端,可能会出现数据不一致的现象
局限
- g.V(... ids) 或g.E(... ids) 指向性query,配合hbase使用没问题,但g.V().has(filter) 可就是全表扫描了,避免该问题要配合全文搜索引擎使用。 g.V()默认实现GraphStep会把vetex信息拉倒当前进程,会dump图库所有节点信息,操作重,条目过多很容易就OOM。
- DSL语言设计之初就没有考虑过MPP体系,计算能力全压在当前进程,架设成常驻进程很容易出现CPU打满,QPS不足等问题。
总结:
- HugeGraph基于TinkerPop,很大程度借鉴了Titan和JanusGraph项目,用到了JanusGraph的storage存储框架和Titan的schema定义框架。
- Hugegraph-studio, hugegraph-tool是JanusGraph没有的组件,JanusGraph的可视化需要和Gephi这样的工具结合起来用。
- 不管JanusGraph还是HugeGraph,都只是封装层中间件,底层存储都是集成Nosql做存储引擎,大同小异。
- 数据导入配置都很复杂
还有一些汇报数据,这里不便放出,总之,跟领导汇报完,我最后选了JanusGraph,并已部署结束开始功能测试了,放出这篇文章的时候我的知识图谱平台架构刚写完,我们的最终目的是做一个个性化的"HugeGraph"平台产品,甚至从功能的丰富性上超越它。
推荐阅读:[AbutionGraph] 大规模实时动态时序知识图谱+AI平台
最后
以上就是诚心纸飞机最近收集整理的关于「JanusGraph与HugeGraph」图形数据库 - 技术选型-功能对比Tinkerpop highlevel-arch的全部内容,更多相关「JanusGraph与HugeGraph」图形数据库内容请搜索靠谱客的其他文章。








发表评论 取消回复