摘要: 绝不应放过这样的审视和反思的机会
编者注:2020 年 8 月 15 日,Medalla 测试网出现了验证者参与率的大幅下降,起因是 Prysm 客户端默认使用 Cloudflare 公司的 roughtime 服务来较准节点的本地时间,但当时的 roughtime 服务出了错,导致所有 Prysm 节点的本地时间都快了 4 个小时,如此一来,Prysm 节点就与使用其它客户端的节点隔绝开来了。
事发之后,Prysm 客户端团队迅速推出了紧急修复并密切跟踪事态。但 Medalla 测试网仍因为各种原因而继续动荡,无法敲定 epoch。事实上,事发之后,截至发文之时,Medalla 测试网仅在北京时间 2020 年 8 月 20 日凌晨曾敲定区块,随后验证者参与度又降到了 66% 以下,未能敲定区块。
事实虽然令人不安,但它恰好提供了一个我们审视 Eth2 网络、审视节点行为的机会 —— 绝不应放过这样的审视和反思的机会,否则我们仍有可能重蹈覆辙。
我们选择了多份材料,尝试多角度、多层次地复现完整的事实、囊括尽可能多不应被忽略的因素。诚然,我们缺乏能观察到去中心化网络全局情形的上帝之眼,认知的深度必定有其边界,但我们仍然希望,对陷入混沌的网络的恢复过程和参与者在此过程中的激励因素,能有一个完整的描述。到目前为止,这个目标还未实现。
第一份材料,来自 Prysm 客户端工程师 prestonvanloon.eth 在推特上对事件的报告。
Medalla 测试网全局性故障初探
phil.eth:ETH 2.0 测试网 Medalla 目前无法敲定区块,因为 Prysm 客户端的 roughtime 时钟同步出了问题。目前已经有了修复方案。请 Prysm 用户更新并重启你们的客户端。这一突发情况再次表明了客户端多样性以及测试网的重要性。
prestonvanloon.eth:
今天(8 月 15 日)早些时候,Prysm 出现了全局性故障,持续时间将近 90 分钟。本次事件的始末如下:
世界协调时 17:30(北京时间凌晨 1:30)左右,@terencechain 发现其客户端的时钟提前了 4 小时。很快,出现时钟偏移报警,discord 频道也被大量用户报告淹没。
Prysm 客户端确实出了问题。
Medalla 测试网上的验证者参与度骤降,其下降速度甚至超越了 $YAM 的归零速度,从 75% 降至 5% 以下。Prysmatic Labs 团队立即展开了紧急行动。
我们决定将软件改成默认禁用 roughtime 时钟同步,取而代之的是可选择的功能切换(feature flag)。这样可以防止此类问题再次大规模爆发。从现在开始,roughtime 的结果将仅供客户端软件参考,不再用于自动时钟校准。
下图是 Prysm 节点出现超过 2 秒的时钟偏移(clock skew)的时间段,从北京时间凌晨 1:30 至 3:00 持续了大约 90 分钟。(注:下图是太平洋标准时间。)
- 图片来源:@prestonvanloon.eth -
现在,我们正看着这个数据思考一个问题 “roughtime 服务器怎么会偏差这么大?” 数据显示,所有 Prysm 服务器报告的偏移量都在 0.1 秒不到。最后为什么会提前 4 小时??
- 图片来源:@prestonvanloon.eth -
我们还在调查这个问题!肯定是 roughtime 的增量计算出了 bug ,我们希望能尽快找到它。无论调查结果如何,我们认为应该将自动时间校准作为可选项,甚至彻底取消掉。
欢迎阅读完整的事后调查报告,了解最新的调查进展。
在主网上线之前,测试网就是用来发现这类问题的。面对这种情况,多几个客户端选择对用户更为有利。
(完)
原文链接:
https://twitter.com/preston_vanloon/status/1294392007599652865
作者:prestonvanloon.eth
翻译&校对: 闵敏 & 阿剑
编者注:第二份材料来自 Prysm 客户端团队的分析报告,有详尽的时间线记录。从中我们可以知晓 Prysm 客户端发布紧急修复的整个过程,以及紧急修复带来的连带影响(紧急修复自身也带来了问题)。截至本译稿发表之时,该分析报告表示已经找到了故障的具体原因。值得一提的是,报告原文所用的都是 UTC 时间(世界协调时),我们一律转换成了北京时间。
“roughtime” 事件分析报告
作者:Terence、Raul、Preston 状态:等待决议。根本原因已找到,问题已缓解。 网络:Medalla 总结:Cloudflare 的 roughtime 服务器全都返回错误信息,而 Prysm 节点并没有采取适当的应急措施。这个 bug 导致所有 Prysm 节点出现时钟偏移(clock skew)。在时钟偏移的影响下,验证者为超前的 slot(时隙)提议区块并生成见证消息。 影响:由于 roughtime 响应错误以及出现时钟偏移,验证者计算 slot 错误,提议的区块和生成的见证消息均无效。这个问题影响到了全局参与度。在北京时间凌晨 1:30 至 2:45 之间,所有 Prysm 节点都受到了影响。 根本原因:来自 Cloudflare 服务器的 roughtime 响应出错。具体来说,是因为 “ticktock” 报告了一个 24 小时之后的时间。这个时间戳,再经过所有 6 个服务器的数据取平均值,是的所有 Prysm 节点都产生了 +4 小时的时间调整。 解决方案:在我们评估 roughtime 响应错误所引发的潜在问题时,先将 roughtime 时钟同步设为可选项。 发现:Terence 最先发现了这个问题。他注意到一个本地信标链节点一直在拒绝超前的区块和见证消息。几分钟之后,由于 roughtime 时钟偏移量较高,产生了报警。同时, #general 和 #bug-report 频道的用户开始报告本地节点拒绝超前区块和见证信息的问题。
经验教训
哪里出了问题
-
我们误以为,对于 roughtime 服务器故障的问题,我们有适当的应急方案。
-
网络中的每个 Prysm 节点同时受到影响,导致验证者参与率大幅降低。
-
Prysmatic Labs 团队原以为,NTP 服务器本身较为分散,而且每个服务器都开放 6 个端口,不会出现全局故障的问题。
万幸的是
-
一位贡献者已经向我们提交了一个 Pull Request(感谢 @ncitron),把 roughtime 时间校准设为可以选择退出的功能。
-
我们已经可以用命令行功能标签(flag)立即选择取消 roughtime 时钟校准,这让修复措施变得简单,而且只需一次 Pull Requtest 就能验证。
-
用户在 Discord 上积极参与讨论。当节点出现问题时,有大量用户提供了详细报告和重要指标。
-
我们有一个持续不断的重同步机制,当它发现时钟偏移量超过 2 秒时,它会不断更新节点本地的时间。我们一直在重新校准 roughtime 时钟,以便更快解决这一问题。这可能让这次事件提前了大约 30 分钟至 1 小时结束。
-
roughtime 时钟同步问题似乎在大约 90 分钟后就解决了,而且在我们能够紧急发布新版本前,这个事件就已经结束了。
1:25 AM :Terence 发现他的本地节点由于一直拒绝超前区块,收到了大量报警。这些区块的 slot 都超前了 4 个多小时。
1:28 AM :Prometheus(普罗米修斯)监控报警系统收到了 roughtime 偏移量高的报警。那时,距离网络最后一次敲定区块过去了 10 epoch(时段)。
1:35 AM :至少有 30 名用户在 Discord 频道表示他们开始收到下方报警:WARN roughtime: Roughtime reports your clock is off by more than 2 seconds offset=4h0m0.028854657s (roughtime 警报:Roughtime 报告你的时钟误差超过 2 秒,偏移量 = 4h0m0.028854657s)
1:43 AM :Terence 在 #war-room 频道群发了告警消息,称这是一个 PS0 级别的事件,需要大家共渡难关。
1:45 AM :Discord 频道的用户提出,重启信标链节点和验证者客户端无法暂时解决这个问题。最可行的方案是将 roughtime 时钟同步设为可选禁用的功能。
1:51 AM :问题上升到了多客户端聊天室
1:52 AM :Ivan 完成了 https://github.com/prysmaticlabs/prysm/pull/6898
2:00 AM :Terence 与 512 位验证者一起在本地测试了 6898 号 Pull Request 。
2:20 AM :据已捕获的调试日志显示,“ticktock” 服务器有段时间一直在报告 24 小时之后的时间。
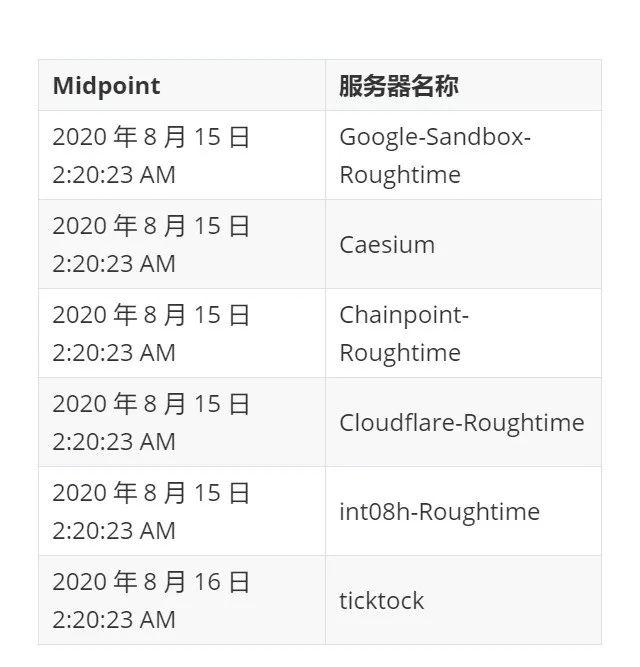
2:27 AM :Raul 联络了 Preston 。Preston 将在 1 小时内回来构建新版本。同时,我们将发布 docker 镜像。
2:40 AM :Preston 指出只靠紧急修复还不够,我们需要取消将 roughtime 时钟同步作为默认项。
2:42 AM :Raul 开始调查 Kibana ,并使用 fluentd 中的 filter(过滤器)分析来自 roughtime 的调试日志响应。
2:43 AM :Terence 交叉检查了信标链命名空间中所有 pod 的 kubectl 日志。正如预期的那样,pod 确实存在 roughtime 时钟偏移问题。
2:46 AM :Raul 向 6898 号 PR 提交了正确的修复程序。
3:05 AM :Raul 确认该修复程序可以让节点在本地工作。如果存在时钟偏移,修复程序会产生告警日志,但是不会试图基于 roughtime 服务器更新时间。
3:08 AM :Terence 在我们的 discord 频道向所有人宣布:“Prysm 节点出现 roughtime 响应错误,应急措施没有达到预期效果。我们已经找到了故障所在,很快就会进行紧急修复,并在 1 小时内上线新版本。在即将发布的新版本中,roughtime 时钟同步将不再是默认项。”
3:18 AM :Buildkite 单元测试、规范测试、docker 镜像构建成功。e2e 测试尚未完成。Preston 准备启动上线流程。
3:22 AM :新版本生成:https://github.com/prysmaticlabs/prysm/commit/d24f99d66db22691b69c76bc57c7509e7f3ba8fe。Terence 确认这个方法可以修复其验证者节点。Preston 开始使用新的 docker 镜像依次重启我们的有状态集合中的 pod 。集群验证者会基于新的镜像进行更新(不保留临时磁盘)。
3:34 AM :Docker 镜像被标记成 alpha 21 版本,稳定性好,二进制文件已经构建完成
3:34 AM :对有状态集合中 pod 的健康状态进行监控,确保滚动更新成功
3:36 AM :使用新的 docker 镜像对我们的验证者 pod 进行滚动启动。
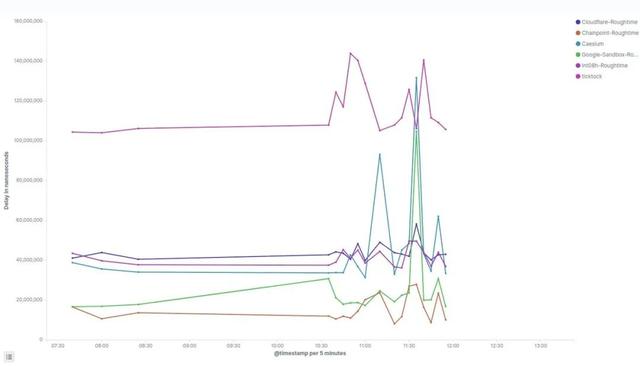
4:29 AM :在日志上查看返回的延时值。平均来看,这些值似乎都在 0.1 秒以下。延迟不是调查的关键指标。准确来说,“中点(midpoint)” 才是需要研究的地方。注:下表时间是太平洋标准时间。https://kibana.prylabs.network/goto/e5f5f64a4426c85aee1d76abc2d994be
- 图片来源:@prestonvanloon.eth -
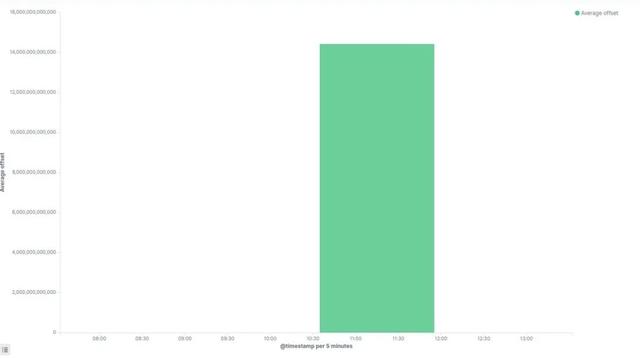
5:32 AM :查看高于 2 秒的偏移量。从该数据中可以看出,在长达 90 分钟的全局故障期间,Prylabs 出块节点的偏移量大约是 14000 秒。注:下表时间是太平洋标准时间。https://kibana.prylabs.network/goto/6ce2d73c13c0eef600b604fee6d8f4f4
- 图片来源:@prestonvanloon.eth -
4:41 AM :通过 Prometheus 报警系统关于平均偏移量的数据,我们可以明显看出在北京时间凌晨 1:30 至 2:45 之间确实存在时钟偏移问题,之后偏移量开始下降并恢复正常。
(图片无法复制,请至原文观看)
4:52 AM :即时调查结束。这次时钟偏移故障显然已经结束,而且修复程序已经发布。已经更新的节点将立即恢复,还没有更新的节点需要过段时间恢复。监控系统显示,验证者参与度在逐步回升。
6:20 AM :用户报告说罚没保护机制已经启动。这是因为之前的时钟偏移导致验证者超前 4 小时提议区块并生成见证消息。为了避免遭到罚没,Prysm 验证者没有继续提议无效区块。
8:13 AM :再次故障
8:13 AM :Nishant 注意到 6898 号 PR中存在严重缺陷。只有在 roughtime 功能标记开启的情况下,用户才能设置它的功能。
8:16 AM :Preston 更新了 “最新的” 二进制文件,使其指向 alpha 20 版本来实现临时回滚,并建议用户回滚至 alpha 20 版本。我们现在正在等待合并 7004 号 PR 作为 alpha 22 版本的候选。
8:45 AM :值班团队正在评估是否扩大热状态缓存的大小,以便 alpha 22 版本能够更快让网络重新开始敲定区块。当前默认的热状态缓存大小为 8 个 epoch ,但是 Medalla 测试网距离上一次敲定区块已经过去了将近 100 个 epoch 。
9:12 AM :值班团队决定将默认缓冲大小更新至 64 epoch ,并使其可以通过功能标记来配置。经过初步测试,这有可能会使内存使用量增加 1.5G 。等网络重新开始敲定区块后,缓冲大小还可以调整。
9:57 AM :所有 Prysmatic Labs 验证者节点都生成了会被罚没的见证消息。紧急修复程序删除了 Prylabs 验证者节点的本地存储。没有任何外部的罚没保护机制在运行。具体情形尚待确认……在 1024 名验证者中,至少有 800 名验证者已经或即将遭到罚没。
10:37 AM :多名用户报告称无法同步区块链。目前的问题是,网络中有太多节点在同一时间进行同步。Alpha 22 版本被推迟,需要等待进一步通知。
10:46 AM :Prylabs 团队认为现在最好的办法就是等待。用户应该运行 alpha 20 版本或最新的 docker 镜像。
2020/08/16
2:12 AM :正在对同步难的问题进行调查。
11:36 AM :Nishant 和 Victor 发布初始同步修复程序。参见 Pull Request 7012 。
2020/8/17
1:51 AM :合并拉取 7012 号 PR。一些用户报告说同步成功。Prysmatic Labs 开始将 7012 部署到出块节点上。
5:15 AM :从 commit 0be1957c2897909b943b80fdd028f5346ae6cde6 开始开发 Alpha.22 版本
5:33 AM :Alpha 22 版本发布。链接:https://github.com/prysmaticlabs/prysm/releases/tag/v1.0.0-alpha.22
5:40 AM :通过 Discord 频道宣布 Alpha 22 版本上线。Prysmatic 的值班团队继续监控同步情况,以便进行优化。与此同时,越来越多用户同步至最新区块。
12:53 AM :Alpha 23 版本上线,已在 Discord 频道宣布该消息。Alpha 23 版本包含一些同步修复程序,有望解决 Medalla 测试网的问题。建议用户在运行时开启 “--dev” 标记,以便获得更好的体验。
(完)
(文内有许多超链接,可点击左下 ”阅读原文“ 从 EthFans 网站上获取)
原文链接:
https://docs.google.com/document/d/11RmitNRui10LcLCyoXY6B1INCZZKq30gEU6BEg3EWfk/edit#
作者:Prysmatic Labs
翻译&校对: 闵敏 & 阿剑
作者:以太坊爱好者;来自链得得内容开放平台“得得号”,本文仅代表作者观点,不代表链得得官方立场凡“得得号”文章,原创性和内容的真实性由投稿人保证,如果稿件因抄袭、作假等行为导致的法律后果,由投稿人本人负责得得号平台发布文章,如有侵权、违规及其他不当言论内容,请广大读者监督,一经证实,平台会立即下线。如遇文章内容问题,请发送至邮箱:linggeqi@chaindd.com
最后
以上就是细心铃铛最近收集整理的关于zigbee节点频繁掉网的原因_Medalla 测试网网络动荡始末,Part-1Medalla 测试网全局性故障初探“roughtime” 事件分析报告的全部内容,更多相关zigbee节点频繁掉网的原因_Medalla内容请搜索靠谱客的其他文章。

![[转]ZigBee On Windows Mobile--ZigBee模块天线设计](https://www.shuijiaxian.com/files_image/reation/bcimg26.png)






发表评论 取消回复