SAST weekly是由电子工程系学生科协推出的科技系列推送,内容涵盖信息领域技术科普、研究前沿热点介绍、科技新闻跟进探索等多个方面,帮助同学们增长姿势,开拓眼界,每周更新,欢迎关注,欢迎愿意分享知识的同学投稿eesast@mail.tsinghua.edu.cn
伴随着AI的热潮,AI硬件也备受关注
你是否对深鉴的FPGA和谷歌的TPU充满好奇?
就随我了解一下AI硬件吧!
AI硬件大体上可以按照下面的4个象限进行分类

从功能上看,可以分成Training和Inference;而从应用场景则可以分成“ Cloud / Data Center”和“Edge / Embedded”两大类,其中在Edge端做training目前还不是很明确的需求。
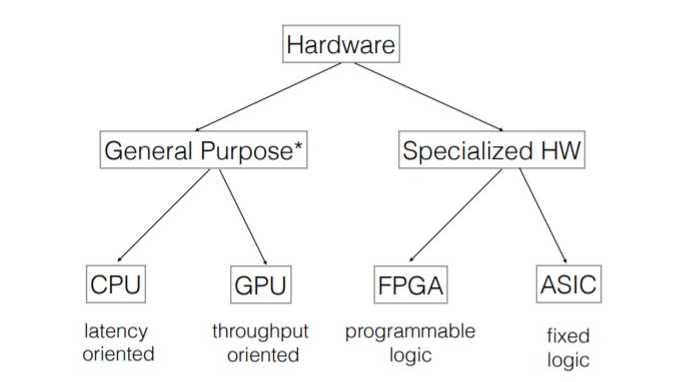
从GPU这样的通用设计,到FPGA这样的可编程器件,到专用的特定领域芯片ASIC(Application Specific Integrated Circuit,如TPU),速度越来越快,但可扩展性越来越低。
接下来将从这几个方面进行描述
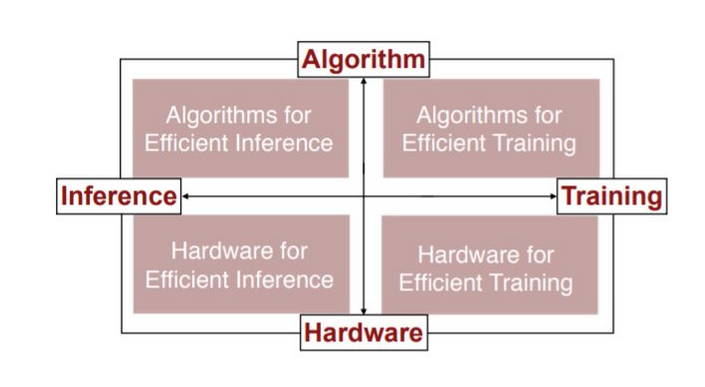
接下来将从这几个方面进行描述


高效推理的硬件实现
芯片上优化的目标,一个是性能,一个是能效。优化能耗,即优化能耗,主要减少对DRAM和buffer的访存次数。优化性能,即优化计算单元在整体工作过程中的利用率,让PE(Processing Element)时刻保持忙碌。
1.减少访存次数,最常用的办法就是进行数据复用。数据复用分为输入复用(input Reuse),输出复用(Output Reuse),权重复用(Weight Reuse)等。
以输入复用为例,指读入N个小map,在运算单元(矩阵乘)内部做充分的计算,将这一层对应的M个map输出都遍历一遍,完成所有的计算。这一层input buffer只要访问一次,但是weight buffer和output buffer却要进行频繁的交互。
此外,还可以设计数据传输网络,优化dataflow,通过PE之间共享输入数据,减少访存次数。
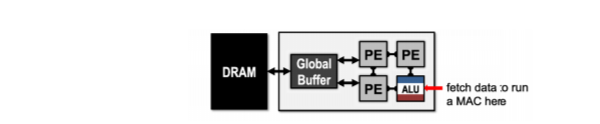
注:MAC(multiply-and-accumulate)
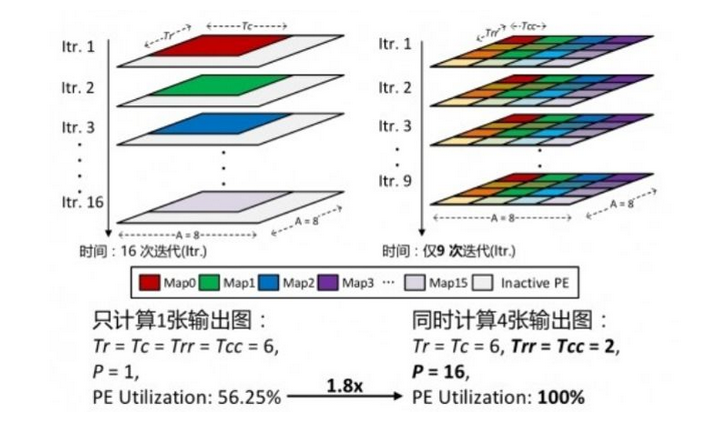
2.提高PE的利用率,可以优化卷积映射的方法,output map任务与PE阵列对应。比如PE阵列的大小是8*8,输出feature map的尺寸和PE的尺寸不一样,这样就导致有较多的计算资源没有用上。
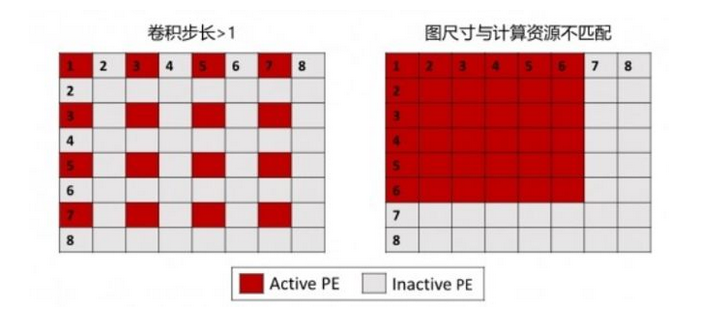
这个时候可以采用并行卷积映射办法,通过并行地计算更多的输出图来获得更高的PE利用率
高效训练的算法实现
-
并行化:模型的并行化可以将其分成不同的部分进行训练:卷积层可以不同的区域之间并行,全连接层的并行可以不同的输出activation之间并联;数据的并行化可以不同的训练样本之间并行,不过权重要同步更新;超参数的并行可以同时尝试不同可选的网络。
-
混合精度计算
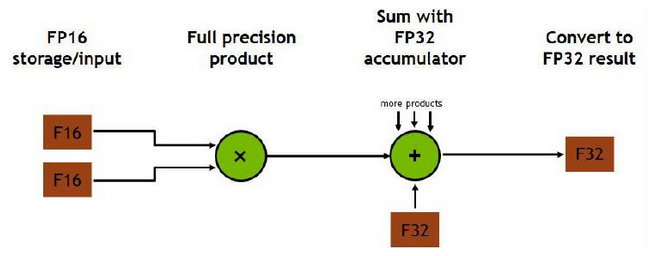
乘法的时候采用float16,减少运算;加法的时候采用float32,保证精度。
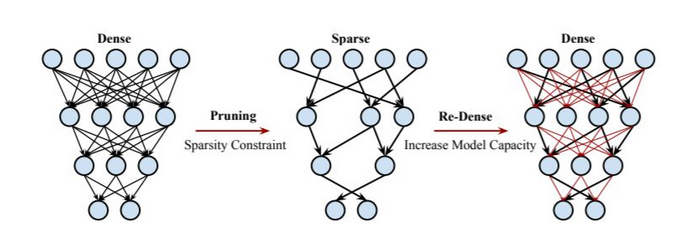
3.此外,还有对训练做量化;通过模型蒸馏将老师模型获得的知识迁移到学生模型上去;对模型剪枝训练,再重新增加树枝等方法。
高效训练的硬件实现
针对神经网络需要研制专用的指令集以提高性能,比如NVIDIA的Volta架构就采用了新型指令集,增加了Tensor Cores,执行混合精度浮点加法乘法,从而相比于之前的架构有着更高的吞吐率。类似的,TPU的指令集是一个十分专用的指令集,CISC类型,主要是针对推理的访存和运算指令。
参考资料:
[1]Han, Song, Huizi Mao, and William J. Dally. "Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding." arXiv preprint arXiv:1510.00149 (2015).
[2]Yin, Shouyi, et al. "A high energy efficient reconfigurable hybrid neural network processor for deep learning applications." IEEE Journal of Solid-State Circuits 53.4 (2018): 968-982.
大家如果想对这方面有更多了解的话,可以参考 "Efficient processing of deep neural networks: A tutorial and survey." 以及关注StarryHeavensAbove公众号~
转载于:https://my.oschina.net/shannanzi/blog/2223455
最后
以上就是贪玩银耳汤最近收集整理的关于浅谈AI硬件的全部内容,更多相关浅谈AI硬件内容请搜索靠谱客的其他文章。







![[译]利用贝叶斯推理做硬件故障率的准实时预测](https://www.shuijiaxian.com/files_image/reation/bcimg17.png)
发表评论 取消回复