近来学习聚类,发现聚类中有一个非常有趣的方向—社交网络分析,这篇只是一篇概况,并没有太多的公式推导和代码,基本是用人话解释社交网络分析中的常用的几种算法。详细到每个算法的以后有空再把详细的公式和代码补上。
目录:
1.应用场景
2.分析指标
3.社区发现算法
3.1 GN算法
3.2 Louvain算法
3.3 LPA与SLPA
- 应用场景
社交网络分析中最常用的就是社交圈子的识别,所谓物以类聚,人以群分,一旦能对社交圈子进行分类,能做的事情就会很多。
FaceBook和微信是关于人与人之间的强关系网络,划分社交圈有助于朋友间相互推荐。
领英是关于职业的社交的社交网络,有助于求职和商务合作交流。
微博,Twitter,豆瓣,微信公众号是关于关注与被关注的的弱关系网络,有助于消息和知识的传播。
分好社交网络之后可以对人进行精准化营销,推荐个性化的商品和服务,比如京东;
疾病传播也是由一个中心点向外扩散,切断网络中的关键节点就可以有效阻止传染病的传播;
识别互联网金融行业中的欺诈团伙,进行反欺诈预测;
这只是其中的三个方面,还有很多应用在此不作细讲。
2.分析指标
图,简单来说就是人物(事物)关系的形象化表示。节点(node)代表一个人物,边(edge)代表人物关系。有向图用箭头表示人物间的关系,无向图用线段表示人物间的关系。
顺便提供两份图数据集,可以自己拿来做实验:
斯坦福大学实验数据
网络分析数据集
这里重点讲述社交网络算法的分析指标。
度(Degree)
连接点活跃性的度量;与点相连的边的数目。在有向图中,以顶点A为起点记为出度(out degree)OD(A),以顶点A为终点入度(In degree)ID(A),则顶点A的度为D(A) = OD(A) + ID(A)。
Igraph是图计算和社交网络分析的常用工具,提供了python的接口,安装方式参考官网:Igraph官网点这
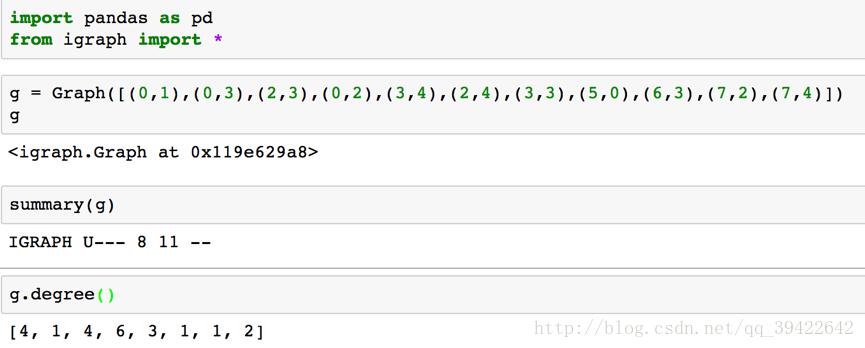
算了,还是拿权游的数据玩一下比较爽。
计算度:
import csv
edges = []
firstline = True
with open('/Users/huanghuaixian/desktop/stormofswords.csv','r') as f:
for row in csv.reader(f.read().splitlines()):
if firstline == True:
firstline = False
continue
u,v,weight = [i for i in row]
edges.append((u,v,int(weight)))
from igraph import Graph as IGraph
g = IGraph.TupleList(edges ,directed = True ,vertex_name_attr = 'name' ,edge_attrs = None ,weights = True)
print(g)
for p in g.vs:
print(p['name'],p.degree())分析一下网络结构:
#角色数
g.vcount()
#143个角色#网络直径,网络中最长最短路径
print(g.diameter())
#输出7最短路径
print(g.shortest_paths("Sansa","Margaery"))
print([ names[x] for x in g.get_all_shortest_paths("Sansa","Margaery")[0]])
for p in g.get_all_shortest_paths('Sansa'):
print([names[x]for x in p])
#输出1和所有以Sansa开始的最短路径紧密中心性(closness centrality)
节点V到达其他节点的难易程度,也就是到其他所有节点距离的平均值的倒数。
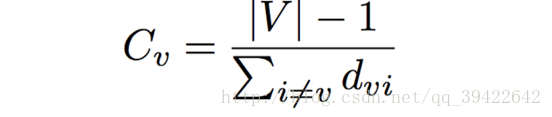
代码实现:
ccvs = []
for p in zip(g.vs, g.closeness()):
ccvs.append({"name": p[0]["name"], "cc": p[1]})
sorted(ccvs, key=lambda k: k['cc'], reverse=True)[:10][{‘cc’: 0.5120772946859904, ‘name’: ‘Tyrion’},
{‘cc’: 0.5096153846153846, ‘name’: ‘Sansa’},
{‘cc’: 0.5, ‘name’: ‘Robert’},
{‘cc’: 0.48847926267281105, ‘name’: ‘Robb’},
{‘cc’: 0.48623853211009177, ‘name’: ‘Arya’},
{‘cc’: 0.4796380090497738, ‘name’: ‘Jaime’},
{‘cc’: 0.4796380090497738, ‘name’: ‘Jon’},
{‘cc’: 0.4796380090497738, ‘name’: ‘Stannis’},
{‘cc’: 0.4690265486725664, ‘name’: ‘Tywin’},
{‘cc’: 0.4608695652173913, ‘name’: ‘Eddard’}]
介数中心性(betweenness centrality)
核心思想是两个非邻接成员间的相互作用依赖于网络中的其他成员,特别是两成员间路径上的成员,它们对两非邻接成员间起着某种控制或依赖关系。如果一个成员A位于其他成员的多条最短路径上,那么成员A的作用就比较大,也具有较大的介数中心性。
本质:网络中包含成员B的所有最短路径条数占所有最短路径条数的百分比。
计算公式如下:
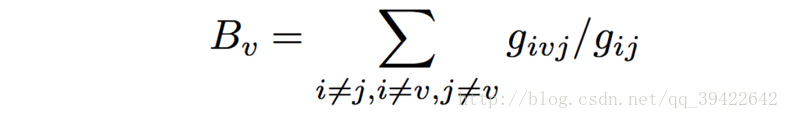
计算步骤:
1.计算每对节点(i,j)的最短路径(需要得到具体的路径)
2. 对各节点判断v是否在最短路径下
3. 累加经过v的最短路径条数
#偷懒一下
btvs = []
for p in zip(g.vs, g.betweenness()):
btvs.append({"name": p[0]["name"], "bt": p[1]})
sorted(btvs, key=lambda k: k['bt'], reverse=True)[:10]结果:
[{‘bt’: 332.9746031746032, ‘name’: ‘Tyrion’},
{‘bt’: 244.63571428571433, ‘name’: ‘Samwell’},
{‘bt’: 226.2047619047619, ‘name’: ‘Stannis’},
{‘bt’: 208.62301587301587, ‘name’: ‘Robert’},
{‘bt’: 138.66666666666666, ‘name’: ‘Mance’},
{‘bt’: 119.99563492063493, ‘name’: ‘Jaime’},
{‘bt’: 114.33333333333334, ‘name’: ‘Sandor’},
{‘bt’: 111.26666666666665, ‘name’: ‘Jon’},
{‘bt’: 90.65, ‘name’: ‘Janos’},
{‘bt’: 64.59761904761905, ‘name’: ‘Aemon’}]
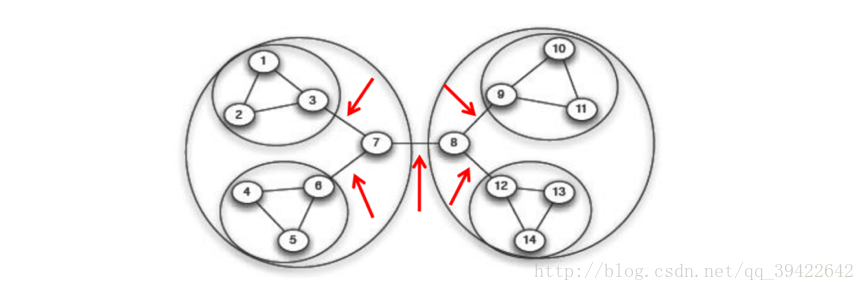
3 . 社区发现算法
社区相当抱团,类似群的概念,同一个社区内的连接紧密,而社区间的连接非常稀疏。社区发现可以理解为在图中发现n个社区,他们连接非常紧密。
3.1 GN 算法
边介数(betweenness):网络中经过该边的最短路径占所有最短路径的比例。
GN算法计算步骤:
1. 计算网络中所有边的介数
2. 找到介数最高的边,并将它从网络中移除
3. 重复以上步骤,直到每个节点就是一个社区为止。
3.2 Louvain 算法
Louvain算法是基于模块度的算法,其优化目标就是最大化整个社区网络结构的模块度。
模块度
它的物理含义是社区内节点的连边数与随机情况下节点的连边数之差,它可以衡量一个社区紧密程度的度量。因此模块度就可以作为优化函数优化社区的分类。
计算方法如下:
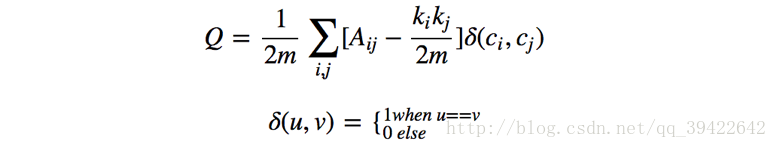
其中
Aij
是节点i与节点j之间的权重,网络不是带权图时,所有边的权重看作是1;
ki
=
∑jAij
表示所有与节点i相连的权重之和;
ci
表示节点i所属的社区;
m=
12∑ijAij
表示所有边的权重之和,取值范围:[-1/2,1)。
算法思想
1. 不断遍历网络中的节点,尝试把单个节点加入能使模块度提升最大的社区,直到所有节点不再改变
2. 将第一阶段形成的一个个小的社区并为一个节点,重新构造网络。这时边的权重为两个节点内所有原始节点的边权重之和。
3. 重复以上两步
更多请参考:点这
3.3 LPA与SLPA
LPA算法思想:
1. 初始化每个节点,并赋予唯一标签
2. 根据邻居节点最常见的标签更新每个节点的标签
3. 最终收敛后标签一致的节点属于同一社区
SLPA算法思想:
SLPA是LPA的扩展。
1. 给每个节点设置一个list存储历史标签
2. 每个speaker节点带概率选择自己标签列表中标签传播给listener节点。(两个节点互为邻居节点)
3. 节点将最热门的标签更新到标签列表中
4. 使用阀值去除低频标签,产出标签一致的节点为社区。
参考:
代码部分取自该博客
七月在线算法课程课件
概念解释的通俗易懂
最后
以上就是孝顺世界最近收集整理的关于社交网络分析算法(SNA)的全部内容,更多相关社交网络分析算法(SNA)内容请搜索靠谱客的其他文章。








发表评论 取消回复