数字IC验证基础知识汇总
- 一、SV基础
- SV和V的比较
- 1.1 阻塞赋值和非阻塞赋值
- 1.2 SV数据类型
- 1、内建数据类型
- 2、定宽数组
- 1.3 定宽数组
- 1、定宽数组
- 2、定宽数组的类别
- 1.4 动态数组
- 1.5 队列
- 1.6 关联数组
- 1.7 数组方法:定位排序
- 1、常用定位方法
- 2、常用排序方法
- 3、常用缩减/运算方法
- 1.8 类型转换与$cast
- 1、隐式转换
- 2、显式转换
- 1.9 ref 和 const
- 1、ref
- 2、const
- 1.10 任务(task),函数(function),虚方法(virtual task/function)
- 1、task和function的共同点
- 2、task和function不同点
- 3、虚方法(virtual task/function)
- 1.11 class和module的区别
- 1、class
- 2、module
- 3、interface
- 1.12 fork线程
- 1、fork…join
- 2、fork…join_none
- 3、fork…join_any
- 4、wait fork
- 5、disable fork_name/fork
- 1.13 wait和@的区别
- 1、-> 用来触发事件
- 2、wait和 @ 用来等待事件
- 1.14 线程间的通信(事件(event)、旗语(semaphore)和信箱(mailbox))
- 1、事件event
- 2、旗语semaphore
- 3、信箱mailbox
- 1.15 随机化和约束(randomization&constraints)
- 1、为什么要随机化和约束
- 2、随机化的对象
- 3、随机化的方法
- 4、常用的随机函数
- 5、随机化和约束的控制
- 1.16 Program和Module
- 1、program
- 2、module
- 3、为什么要有program
- 1.17 断言(Assertion)
- 1、立即断言(immediate assertion)
- 2、并发断言(concurrent assertion)
- 3、断言中的sequence
- 4、断言中的property
- 5、交叠蕴含(|->)和非交叠蕴含(|=>)
- 6、sequence和property的区别和联系
- 1.18 SV中import和package、`include的区别
- 1、package
- 2、import
- 3、`include
- 1.19 SV中全局与局部变量、静态变量和动态变量
- 1、全局变量与局部变量作用域
- 2、动态变量与静态变量区别
- 1.20 SV的仿真调度机制(Scheduler)
- 1、为什么有仿真调度机制
- 2、离散事件执行模型(Discrete event execution)
- 3、时间片Time slot/step
- 4、事件区域Event Regions
- 二、UVM基础
- 2.1 UVM的优势和劣势、方法学的演变
- 1、UVM比SV的优势
- 2、UVM比SV的劣势
- 3、验证方法学的演变
- 2.2 UVM树形结构
- 1、UVM树
- 2、UVM常用类的继承关系
- 2.3 UVM组件Components
- 1、driver
- 2、sequencer
- 3、scoreboard
- 4、monitor
- 5、env
- 6、agent
- 7、reference model
- 8、transaction
- 2.4 启动测试平台
- 1、UVM验证平台启动及执行的流程图
- 2、启动测试测试平台方法
- 3、启动测试平台后执行流程
- 2.5 Components和Objects的联系与区别
- 1、联系
- 2、区别
- 2.6 uvm_component_utils和uvm_object_utils的区别
- 2.7 接口(interface)和虚拟接口(virtual interface)
- 1、interface接口
- 2、接口中的modport
- 3、接口中的clocking
- 4、接口是可综合的
- 5、virtual interface
- 2.8 sequence机制
- 1、什么是sequence机制
- 2、为什么要sequence
- 3、layer sequence
- 4、virtual sequence
- 2.9 phase机制
- 1、什么是phase机制
- 2、phase机制图
- 3、 phase有哪些
- 4、动态运行phase(run phase)
- 5、function phase(不消耗仿真时间)
- 6、task phase(消耗仿真时间)
- 7、与phase相关的类
- 2.10 Objection机制
- 2.11 factory工厂机制
- 1、什么是工厂机制
- 2、工厂机制的步骤
- 2.12 config_db机制
- 1、config_db的作用
- 2、set函数
- 3、get函数
- 4、省略get的情况
- 5、set函数的优先级(不同模块对同一个参数有多个set)
- 6、uvm_config_db和uvm_resource_db的区别
- 2.13 field_automation域的自动化机制
- 1、什么是field_automation
- 2、field_automation使用方法
- 2.14 UVM的层次引用
- 2.15 UVM的消息管理
- 1、信息的安全级别severity(反应的是信息的安全级别)
- 2、对冗余级别verbosity的打印控制
- 2.16 uvm_do系列宏
- 1、uvm_do的作用
- 2、一系列的uvm_do宏
- 2.17 uvm_create和uvm_send
- 2.18 事务级建模TLM
- 1、TLM的基本介绍
- 2、TLM的操作
- 3、TLM的端口与连接
- 2.19 Register Model寄存器模型
- 1、什么是Register Model
- 2、RAL(Register Abstraction Layer)
- 3、前门访问
- 4、后门访问
- 三、验证通识/思想
- 3.1 验证方法与流程
- 3.2 代码覆盖率与功能覆盖率
- 1、代码覆盖率
- 2、功能覆盖率
- 3、代码覆盖率低,功能覆盖率高
- 4、代码覆盖率高,功能覆盖率低
- 3.3 OOP思想
- 1、OOP定义
- 2、封装
- 3、继承
- 4、多态
- 5、SV中的封装
- 6、SV中的继承
- 7、SV中的多态
一、SV基础
SV和V的比较
SV是验证语言,建模能力更强,有点像V和C的结合;V是设计语言,更侧重对硬件电路的具体描述。
- SV有接口,接口把各种信号封装在一起,来进行不同模块之间的信号交流
- SV加了断言,来做验证
- SV还有一些C语言的数据类型,比如用户自定义类型,typedef;枚举类型,还有引用和const常量
- 还有一些比如C里的跳转语句,break,continue,return等
1.1 阻塞赋值和非阻塞赋值
- 阻塞赋值:=。指同一个always块中,后面的赋值语句在前面一句赋值结束后再开始赋值,顺序执行。
- 非阻塞赋值:=>。赋值时先计算非阻塞赋值符号右边的表达式,之后前后的语句是同时赋值的,并行执行,一般时序逻辑用非阻塞。
1.2 SV数据类型
1、内建数据类型
(四值逻辑有)interger,logic,reg,线网(wire, tri),time(unsigned);(二值逻辑有)byte, short int, int, long int, bit(unsigned),real(双精度浮点数)
2、定宽数组
宽度要定义好,在编译时确定。
1.3 定宽数组
1、定宽数组
声明时定义数组宽度,编译时是知道宽度的,如:int array[0:7][0:3]int array[8][4]。
2、定宽数组的类别
(1)合并数组:如 bit [3:0] [7:0] array,数组大小的定义必须是[MSB: LSB],不能是[Size] ,合并数组在存储时是连续的。
(2)非合并数组:如 bit [7:0] array2[3:0] 或 bit[7:0] array2[4],在内存里是不连续存储的。
1.4 动态数组
- 用 [] 来声明,之后用 new[length] 来分配空间,用delete来删除。动态数组在编译时不指定空间大小,在运行时再确定数组空间大小。
- 常用方法:
声明:int dyn [];
分配空间:dyn = new[5];
删除所有元素/清空数组:dyn = dyn.delete();
返回数组大小:dyn.size();
1.5 队列
- 用 [$] 来声明,队列下标为0到$。是FIFO逻辑,先进先出的,可以在任何地方添加、删除元素,索引任一元素。
- 常用方法:
插入:q.insert(1,5); // 在1号位插入5(最左边的是0号位)
删除:q.delete(1); // 删除1号位元素 q.delete(); // 清空整个队列
排序:q.sort();
搜索:q.search(elem);
在队列头插入数据:q.push_front(5);
在队列尾插入数据:q.push_back(5);
从队列头输出数据:data = q.pop_fount();
从队列尾输出数据:data = q.pop_back();
1.6 关联数组
- 一般用来存储超大容量的稀疏数组,因为大容量数组里一般有很多空间不会被存储和访问。关联数组可以保存有效的数据元素,只为实际写入的数据分配空间。声明时在方括号里放用来索引的数据类型 [数据类型],其中索引作为key,索引对应的数据作为value。
- 常用方法:
声明:bit [31:0] assoc_array [string]; // 用string作索引
返回元素个数:assoc _array. num();
删除:assoc _array.delete(“string0”); // 删除string0对应的key和value
assoc _array.delete(); // 清空队列
检查是否存在:assoc _array.exists(“string0”);
输出第一个key:assoc _array. first(var); // 输出第一个key赋给var
输出最后一个key:assoc _array. last(var);
将上个key输出:assoc_array. prev(var); // 如果前面没有key,就返回第一个key
将下个key输出:assoc_array.next(var);//如果后面没有key,返回最后一个key
1.7 数组方法:定位排序
1、常用定位方法
返回值都是队列,关联数组返回的队列的数据类型和关联数组的索引的类型一样,其他数组返回int类型的队列。
(1) array.find with(…) :返回满足条件的所有元素
(2) array.find_index with(…) :返回满足条件的所有元素索引
(3) array.find_first with(…) :返回满足条件的第一个元素
(4) array.find_first_index with(…) :返回满足条件的第一个元素索引
(5) array.find_last with(…) :返回满足条件的最后一个元素
(6) array.find_last_index with(…) :返回满足条件的最后一个元素索引
(7) array.max() / q.min():返回最大/小元素
(8) array.unique():返回只出现过一次的元素(唯一值)
(9) array.unique_index():返回唯一值的索引
2、常用排序方法
(1) array.reverse():逆序颠倒(不能加with)
(2) array.sort():升序排列(从小到大)
(3) array.rsort():降序排列(从大到小)
(4) array.shuffle():随机打乱(不能加with)
3、常用缩减/运算方法
(1) array.sum():求和
(2) array.product():求积
(3) array.and():相与
(4) array.or():相或
(5) array.xor():异或
1.8 类型转换与$cast
1、隐式转换
不需要具体的转化的操作符,直接用赋值。比如把4bit的数据转换到5bit,先做位宽拓展,再赋值。
2、显式转换
需要操作符或者转换函数
- 静态转换:在转换的表达式前加上单引号,不对转换值做检查,可能会转换失败,而且不报错。
- 动态转换:用 $cast(target,source),是一个向下类型转换。比如一个类的句柄指向了子类对象,可以用cast来把新的子类句柄指向这个子类对象。还可以用来检查enum枚举类型有没有越界,如果越界了就返回0。
1.9 ref 和 const
1、ref
ref相当于一个指针,表示引用,而不是复制,如果直接传递参数,参数会被复制到堆栈区,但是用ref进行参数传递,比如传到function或者task里,在内部修改这个参数,传递进来的原参数也会跟着改变。
2、const
如果只是希望利用ref这个引用,而不复制到堆栈区的优点,又怕不小心改动了这个参数的值,就在前面加const。
1.10 任务(task),函数(function),虚方法(virtual task/function)
1、task和function的共同点
(1) verilog中task和function是相同的。
(2) 将复杂代码分割成小段落,便于理解和调用,简化程序,功能单一。
(3) 端口参数默认都是输入,除非声明其他类型。
(4) 数据类型默认是logic,除非声明为其他类型。
(5) 可以存在多个语句,不用begin…end做开始结尾。
(6) wire类型数据不可以在端口使用。
(7) 通过引用、值、名称、位置传递参数值。
2、task和function不同点
sv中增加的使用:在静态task和function中声明动态变量,以及在动态task和function中声明静态变量。
(1) function不能消耗仿真时间;task可以消耗仿真时间;比如function不能带有#100的时延语句、不能有@(posedge clk)、不能有wait(ready)的阻塞语句。
(2) function不能调用task;task可以调用function或task;注意:sv中允许function调用task,但只能在fork…join_none生成的线程中调用。
(3) function可以使用void表示不返回结果;task不使用void表示不返回结果。
(4) function只能返回一个值;注意:task无返回值;verilog fucntion必须要有一个返回值;sv可以使用void’(call_function(params))避免返回值。
3、虚方法(virtual task/function)
对于普通的函数,子类中重写的方法在父类中不可见,而如果在父类中定义一个虚函数,子类对应的重写就在父类中可见了,主要是用来父类看看子类干了什么的。当定义了virtual时,在子类中调用某task/function时,会先查找在子类中是否定义了该 task/function,如果子类没有定义,则在父类中查找。未定义virtual时,只在子类中查找,没有定义就是编译器报错。所以如果某一class会被继承,则用户定义的task/function(除new(),randomized(),per_randomize(),pose_randomize()外),一般就会加上virtual关键字,以备后续扩展。
1.11 class和module的区别
1、class
动态对象,可以在仿真的生命周期中销毁。
2、module
静态对象,在仿真期间始终存在。
3、interface
静态对象,所以只能用在module这种静态对象中;driver等components为动态的对象类,所以driver中用virtual interface,需要通过指针指向实际的interface。
1.12 fork线程
1、fork…join
内部语句并发执行,但内部若有begin…end,则begin…end中的语句还是顺序执行。等内部语句都执行完了,再继续执行join后面的语句。
2、fork…join_none
不会等创建的线程完成,而是直接执行join_none后面的语句(父线程和子线程同时运行(父线程优先级更高))。
3、fork…join_any
等待至少一个线程完成,再执行join_any后面的语句(任何一个子线程被调用,父线程都会继续运行)。
4、wait fork
等待所有衍生线程结束再执行后面语句。
5、disable fork_name/fork
停止单个/多个线程。
1.13 wait和@的区别
1、-> 用来触发事件
2、wait和 @ 用来等待事件
- @ 是阻塞的,只有等到@的事件被触发了,对应的进程才会往后执行,而且它类似于边沿触发,如果@等待事件和->触发事件在同一个时间开始执行,也就是会产生竞争,因为@是边沿等待,时间很短,在竞争中可能就等不到这个事件。
- 而wait基本相反,是非阻塞的,还会和triggered函数搭配使用,triggered来检测这个事件有没有被触发过,或者正在触发,如果wait执行的时候这个事件已经触发了,wait就不等了,而且wait是电平等待,哪怕有竞争,也就是事件的触发和wait是同时执行的,wait也能等到这个事件。不过在循环里等待事件的时候要用@,因为wait是电平触发,这个循环触发了,下个循环还是这个电平,继续触发,会形成一个零延时循环。
1.14 线程间的通信(事件(event)、旗语(semaphore)和信箱(mailbox))
1、事件event
用来实现线程的同步,用 -> 符号来触发事件,用wait或@来等待事件,还有triggerred函数来检测这个事件有没有被触发过或者正在触发。
2、旗语semaphore
用来实现对同一资源的访问控制,避免两个并行进程同时对这个数据进行修改,比如一条总线有多个Master,但只允许一个来驱动,就可以用旗语。用new来创建带有单个或者多个钥匙的旗语,用get来获取钥匙,用put来放钥匙,返回钥匙,还有try_get来非阻塞地获取钥匙,返回1表示有足够的钥匙,返回0表示钥匙不够
3、信箱mailbox
类似一个用来连接发送端和接收端的FIFO,相当于直接在不同的进程中搭建了一个桥梁,在桥上可以传东西;用new来实例化,例化的时候有一个可选参数size,表示信箱的容量,也可以不指定,信箱容量就是无限大的;用put把数据放进信箱里,用get来从信箱里读数据,它们都是阻塞的,如果信箱满,put会被阻塞,信箱空,get会被阻塞。
1.15 随机化和约束(randomization&constraints)
1、为什么要随机化和约束
相比于定向测试,随机测试可以减少很多代码量,产生更多样的激励,提高验证的效率。而没有约束的随机化会在产生有效激励的同时产生很多无效激励,非法激励。所以需要约束来限定激励的合法取值范围,还可以指定各个数值的随机权重分布,来提高效率。
2、随机化的对象
- 基本配置:通过寄存器来随机化一些基本的模块或系统本身的配置;
- 外部环境配置:通过随机化验证环境,比如时钟信号,外部的一些信号像 触发信号等;
- 原始的参数数据:比如数据位宽。
3、随机化的方法
- rand关键词:对变量进行随机化;
- randc关键词:对变量进行周期随机化,在限定范围内,所有值都赋值了一圈后才可以重复,实现的效果类似于用rand对这个变量在给定范围内随机赋值,每次生成一个值都存到队列里,下次用rand随机的时候要先判断随机出的值跟队列里有没有重复,如果不重复才对把值赋给这个变量,直到所有值都随机过一遍,就清空这个队列,再继续下一轮的随机;
- std::randomize() 函数:对一个类进行随机,这个类内部可以放约束constraint;
- dist关键词:在约束中产生随机数的权重分布,:= 表示范围内的权重都等于这个值, : / 表示权重值均分到范围里的每一个值;
- inside关键词:表示变量在某个集合里随机化;
- randomize() with:增加额外的约束,和类内的约束是等效的,但如果内外约束冲突,随机化的求解会失败;
- ->和if-else来表示条件约束:->前的条件若真,则执行->后面的约束
4、常用的随机函数
- $random() :均匀分布,返回32bit有符号随机数;
- $urandom() :均匀分布,返回32bit无符号随机数;
- $urandom_range() : 指定范围内的均匀分布,有两个参数,一个是范围的上限值,一个是可选的下限值。
5、随机化和约束的控制
- constraint_mode() 用来打开或关闭约束;
- soft来修饰软约束,当与其他约束冲突时,软约束的优先级更低。
rand int data1, data2;
constraint c0 {
data1 dist {0:=40, [1:3]:=60}; // weight = 40, 60, 60, 60 for 0, 1, 2, 3
data2 dist {0:/40, [1:3]:/60}; // weight = 40, 20, 20, 20 for 0, 1, 2, 3
}
rand int data3;
constraint c1{
data3 inside { [0:3] }; // 0 <= data3 <= 3
}
1.16 Program和Module
1、program
跟module类似,但是不能有module,always块,interface,program,可以调用其他module块里的task或function
2、module
内部可以有program,但是不能调用其他program块里的task或function
3、为什么要有program
program在SV的仿真调度机制里是在Reactive Region集合里执行的,而Module是在Active Region集合里执行的,为了把验证代码和RTL代码分开,减少竞争冒险。
1.17 断言(Assertion)
断言有立即断言(Immediate assertion)与并发断言(Concurrent assertion)。
1、立即断言(immediate assertion)
立即断言基于事件,必须放置在程序块中,只能用于动态仿真,没有时间的概念。立即断言与并发断言关键字区分在于“property”。简单的立即断言示例如下:
always_comb begin
a_ia :assert( a && b );
end
像Verilog的连续赋值块,当a或b变化时,a_ia会执行,当a和b都为高时断言成功,否则断言失败。
特征:
- 基于模拟事件的语义。
- 测试表达式的求值就像在过程块中的其他Verilog的表达式一样。他们本质不是时序相关的,而是立即被求值。
- 必须放在过程快的定义中。
- 只能用于动态模拟。
2、并发断言(concurrent assertion)
并发断言基于时钟周期进行,可以放置于procedural block、module、interface及program中。在静态(形式)验证及动态仿真工具中均可以应用。简单的并发断言示例如下:
a_cc: assert property ((@posedge clk) not (a && b));
a_cc将在每个时钟上升沿进行断言检测,若a和b同时为高,则断言失败。
特征:
- 基于时钟周期的。
- 在时钟边缘根据调用的变量的采样值计算测试表达式。
- 变量的采样在预备阶段完成,而表达式的计算在调度器的观察阶段完成。
- 可以被放到过程快(procedural block)、模块(module)、接口(interface),或者一个程序(program)的定义中。
- 可以在静态(形式的)验证和动态验证(模拟)工具中使用。
3、断言中的sequence
描述了跟时钟周期相关的行为,可以包含布尔表达式,还有一些操作符,##延时时钟周期、重复操作[*n]等。可以在module、interface、program、package、clocking里声明,但是不能在class里,可以构成property。
4、断言中的property
里面可以用sequence,还可以用蕴含操作符,和sequence一样也只能用于module、interface、program、package、clocking里,不能用于class里。
5、交叠蕴含(|->)和非交叠蕴含(|=>)
交叠蕴含的符号是 |-> ,如果先行算子匹配,在同一个时钟周期计算后续算子表达式。非交叠蕴含的符号是 |=> ,如果先行算子匹配,在下一个时钟周期计算后续算子表达式。
6、sequence和property的区别和联系
- 任何在sequence中的表达式都可以放到property中。
- 任何在property中的表达式也可以放到sequence中,但只有property中才能使用蕴含操作符。
- property中可以实例化其他property和sequence,sequence中也可以调用其他sequence,但不能实例化property。
- property需要用cover/assert/assume等关键词进行实例化,但sequence直接调用即可。
1.18 SV中import和package、`include的区别
1、package
package的作用不仅仅是将文件进行打包,而且会对打包的文件限定package作用域范围,这些文件只在package作用域范围内可见。
2、import
import package的作用:主要是将package的作用域范围扩大,让package中的内容在import所在作用域内可见。
3、`include
'include是将文本直接复制来的,在预处理时完成,比import执行的更早。
1.19 SV中全局与局部变量、静态变量和动态变量
1、全局变量与局部变量作用域
在SV中,所有成员默认都是 public 类型的代表全局变量,除非显示的使用关键字 local/protected 来声明表示局部变量。local与protected均可对方法或者属性进行修饰说明。
- public默认类型表示变量在无修饰情况下默认为是public类型,此类型也是最“暴露”的类型。用此关键字修饰(或者无修饰默认此修饰)的变量或者方法都可以被外部调用或者类继承。
- local 关键字表示成员或方法只对该类的对象可见,扩展类以及类外不可见。
- protected 关键字表示成员或方法对该类以及扩展类可见,对类外不可见。
2、动态变量与静态变量区别
- 在SV中,将数据的生命周期分为动态(automatic)和静态(static)。
- 局部变量的生命周期同其所在域共存亡,如function/task中的临时变量,在其方法调用结束后,临时变量的生命也将终结,所以它们是动态生命周期。
- 全局变量伴随着程序开始执行到结束一直存在,它们是静态生命周期。
- 如果数据变量被声明为automatic,那么在进入该进程/方法后,automatic变量会被创建,而在离开该进程/方法后,automatic变量会被销毁。而static变量在仿真开始时就会被创建,自身不会被销毁,可以被多个进程/方法共享。
- 只有声明为automatic的变量才是动态变量,其他类型默认为static静态类型。
1.20 SV的仿真调度机制(Scheduler)
1、为什么有仿真调度机制
写SV的时候很多进程都是并行的,但是实际在软件里里仿真的时候,都是CPU上串行执行的。所以SV需要一个从并行到串行的转换机制,来规定一些并行的语句在CPU串行执行的时候实际上的先后顺序,做一个顺序或者说是优先级的调度,就叫做仿真调度机制。
2、离散事件执行模型(Discrete event execution)
仿真是基于时间片进行的,是离散的。这个模型就是仿真基于事件的建模,还有事件的优先级的调度。仿真的时候,更新事件和求值事件交替执行。事件包括了:
- 更新事件update event:仿真过程中,信号每次的变化就是一次更新事件,进程是对更新事件敏感的。
- 求值事件evaluation event:当一个更新事件被执行时,所有对该更新事件敏感的进程都会被求值,这个顺序是任意的,求值过程本身就是一种事件,叫做求值事件。
3、时间片Time slot/step
仿真是基于离散的时刻点来进行的,各种事件都是在某一个时间片被触发,一个时间片上的事件全部执行完之后,再执行下一个时间片。
#1step:step的时间单位是定义的最小的时间精度,比如1ps,就是仿真的时候最小的时间单位。
4、事件区域Event Regions
通过划分事件区域来确定执行顺序(按顺序)。
- Pre-poned Region:对于一个新的SV指令,采样数据,为断言做准备。
- Active Region set:有3个(Active Region, Inactive Region, NBA Region),执行RTL代码的module里定义的各种事件。Active Region计算阻塞赋值,还有非阻塞赋值的右侧表达式的结果,传给后面NBA Region;Inactive Region计算#0延迟下的阻塞赋值;NBA Region把非阻塞赋值的右侧表达式的结果赋值给左边。
- Observed Region:断言相关的区域,把第一个Preponed Region采样到的数据拿来计算断言。
- Reactive Region set:有3个(Reactive Region, Re-Inactive Region, Re-NBA Region),验证相关的区域。 Reactive Region要执行program里的阻塞赋值,还有计算非阻塞赋值右边的表达式的值,并且作为更新事件调度到后面的Re-NBA Region;Re-Inactive Region执行program里#0延迟的进程,比如fork…join_none后面加一个#0,本来父线程和子线程的优先级是一样的,这样内部的子线程可以优先于父线程执行;Re-NBA Region执行前面Reactive Region传过来的非阻塞赋值右边的值赋值到左边。
- Post-poned Region:调用monitor函数,输出更新值;收集功能覆盖率(strobe函数采样的)。
二、UVM基础
2.1 UVM的优势和劣势、方法学的演变
1、UVM比SV的优势
相比于用SV直接搭验证平台,优势主要是可复用性,相当于构建了一个验证平台的框架,之后往里填内容,不用从头搭起,大大减少了搭建验证平台初期的工作量,像phase机制,把各种行为写到对应的phase里去,它就会自己按照顺序执行,而且UVM的验证平台和测试用例是分开的,验证平台搭好之后其实一般不会大改,但是测试用例,激励,sequences这些在验证的过程中可能需要很多修改,更新,迭代,把它们分开来比较好单独处理。此外还有:目前一些主流的EDA工具,Cadence/Mentor/Synopsys的都支持UVM,可移植性比较强;支持覆盖率驱动的验证;支持寄存器模型。
2、UVM比SV的劣势
需要另外学,学起来需要时间。
3、验证方法学的演变
- 最开始Cadence发布了eRM,用e语言,包括了激励和check的策略,还有覆盖率模型;
- 之后Synopsys发布了RVM;
- 再往后Mentor发布了AVM,是用systemverilog和systemC实现的,提出了TLM事务级建模;
- AVM的同一年,Synopsys发布了VMM,是改进版的RVM,RVM是基于vera语言,Synopsys可能觉得SystemVerilog比较有前景,就发布了基于SystemVerilog的VMM,这个VMM里还加了callback机制;
- 之后差不多的时间,Cadence也发布了基于SystemVerilog的方法学,叫URM,里面也有TLM,还有factory,config_db;
- 后来Cadence和Mentor合作发布了一个OVM;
- 再然后就是UVM了,是Accellera公司在OVM的基础上推出的,并且加上了VMM的callback机制。
2.2 UVM树形结构
1、UVM树
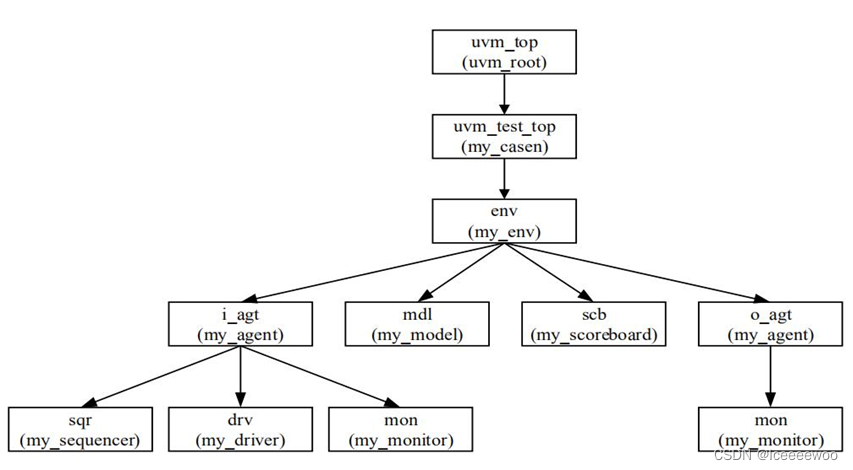
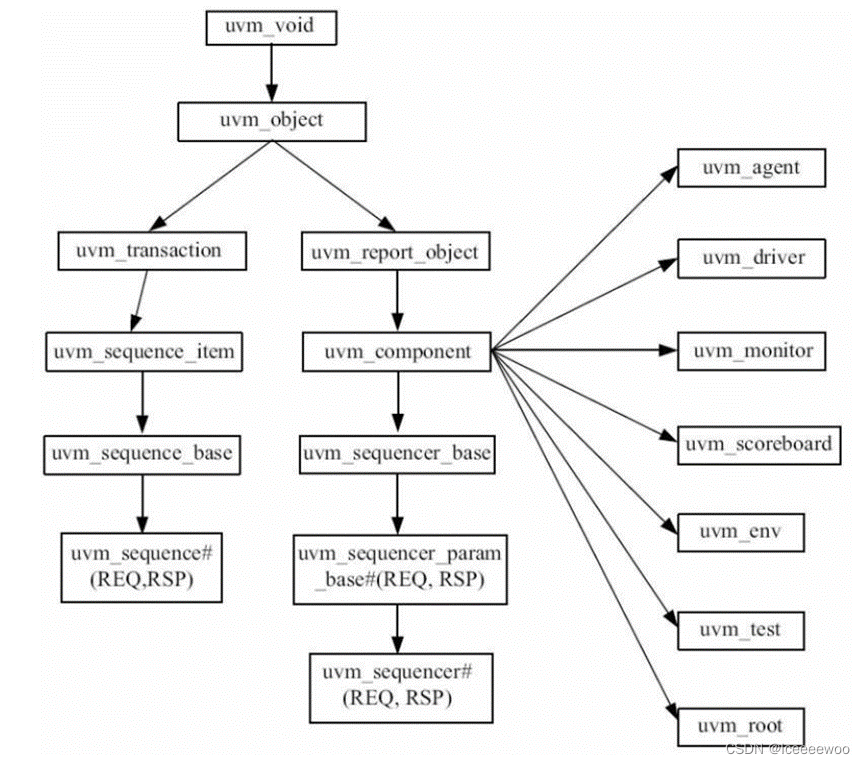
2、UVM常用类的继承关系
2.3 UVM组件Components
1、driver
从sequencer接收transaction,再传给DUT,也就是给DUT提供各种激励驱动,来模拟DUT的真实使用情况。
2、sequencer
将sequence产生的transaction传给driver。
3、scoreboard
check DUT的输出是否符合预期。
4、monitor
driver负责把transaction级别的数据转变成DUT的端口级别,并驱动给DUT;monitor的行为与其相对,用于收集DUT的端口数据,并将其转换成transcation交给后续的组件如reference model, scoreboard等处理。
5、env
一个容器类,把各个组件打包在一起,然后在env里例化这些组件。
6、agent
有的组件如driver和monitor的部分代码高度相似,本质是因为二者处理同一种协议。由于这种相似性,UVM将二者封装到一起,成为一个agent。不同的agent代表了不同的协议。
7、reference model
当DUT在执行某指令时,验证平台也必须相应完成同样的指令,得到输出。完成这个过程的即参考模型。
8、transaction
各组件之间信息的传递是基于transaction的。一般来说,物理协议中的数据交换都是以帧或包为单位的,通常在一帧或者一个包里要定义好各项参数,每个包的大小不一样。transaction就是用于模拟这种实际情况,一笔transaction就是一个包。
2.4 启动测试平台
1、UVM验证平台启动及执行的流程图
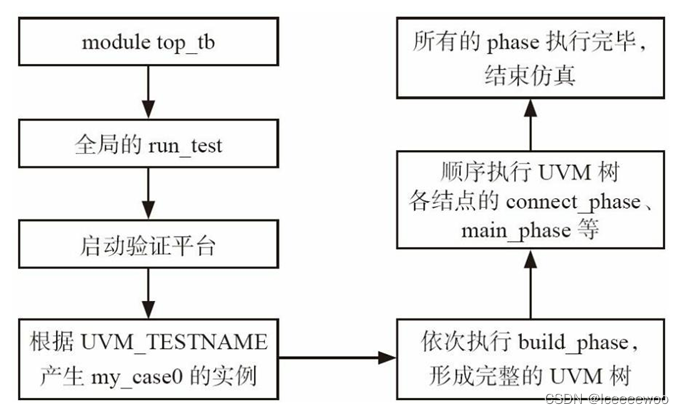
2、启动测试测试平台方法
- 在顶层模块(tb_top)的run_test(“my_case0”)中添加测试用例名
- 是在命令行中指定测试用例(如+UVM_TESTNAME = my_case0)
3、启动测试平台后执行流程
- 得到正确的test_name
- 初始化objection机制
- 创建uvm_test_top实例
- 调用phase控制方法,安排所有的phase方法执行顺序
- 等待所有的phase执行结束,关闭phase控制进程
- 报告总结和仿真结束
2.5 Components和Objects的联系与区别
1、联系
uvm_component派生自uvm_object,因此components继承了许多objects的特性,同时又有一些自己的特质。
2、区别
- components有两个特性是objects没有的,一是通过在new的时候指定parent参数来形成树形的组织结构,所有UVM树的结点都是有component组成的,二是具有phase机制的自动执行特点。
- components是静态实体,没有生命周期的,从仿真开始一直存在到仿真结束,而objects有生命周期,是在中途产生,中途结束的。
- components始终连接到硬件或者TLM端口,而objects不会连接这些。
2.6 uvm_component_utils和uvm_object_utils的区别
1、utils宏定义注册机制保证了object/components进行正确factory操作所需的基础结构。
2、uvm_component_utils派生自uvm_object_utils,所以uvm_component_utils拥有uvm_object_utils的特性,同时又有自己的一些特质。uvm_component_utils有两大特性是uvm_object_utils没有的:
(1) 是通过在new的时候指定parent参数来形成一种树形的组织结构。
(2) 是由phase的自动执行特点。
2.7 接口(interface)和虚拟接口(virtual interface)
1、interface接口
主要是用来简化模块之间的连接,还有实现类和模块之间的通信。它是对模块端口信号还有功能进行一个标准化的封装。可以在接口里定义变量,任务,和函数,modport, clocking,assertion,还可以用always和initial语句,写一些可能会复用的东西。比如总线接口,就会定义成interface。
2、接口中的modport
主要是提供了方向信息(信号的输入输出方向),来支持主从类型的通信。对于同一个interface,不同的组件可能有不同的视角,比如对于driver是输出的信号,而对于monitor可能是输入信号。所以引入modport来进行方向的支持。
3、接口中的clocking
规定了信号之间的时序关系。默认情况下interface里的信号是异步的,就可以通过clocking定义一组跟时钟同步的信号,还可以为clocking块中的信号设置建立时间与保持时间(默认都是1ns)
4、接口是可综合的
5、virtual interface
interface是静态对象,所以只能用在module这种静态对象中声明,不能在class这种动态对象里声明,所以就有了virtual interface,它可以用在class中。但是它是virtual的嘛,virtual指的就是指针,句柄,它本身没有什么内容,是要指向实际的interface的,在class中声明一个virtual interface,然后通过config_db机制来连接它们两,在module里set,在class里get,就把interface的内容赋给virtual interface了。
2.8 sequence机制
1、什么是sequence机制
sequence产生transaction,发给sequencer,再由driver驱动,传给DUT。一个sequence发送transaction前,要先发送一个请求,sequencer把这个请求放在一个仲裁队列中。sequencer要检测仲裁队列里是否有某个sequence发送tr的请求;检测driver是否申请要tr
2、为什么要sequence
sequence机制是为了将test case和testbench分离开,对于一个项目而言,testbench是相对稳定的测试平台,而针对具体模块的test case差别很大,引入sequence可以比较灵活地分别处理这两部分。
3、layer sequence
通过构建层次化的sequence,来与register model进行访问操作。
4、virtual sequence
主要起到一个调度的作用。因为driver只能驱动一种实际的接口,对应一种transaction的sequence,如果要对多个接口同时激励,就需要virtual sequence/sequencer。这个virtual的意思是不产生具体的某种transaction,而是控制其他的sequence为相应地sequencer产生transaction,virtual sequence用来做不同类型sequence之间的调度的:
- 定义virtual sequencer,里面有各个env里的子sequencer类型的指针。
- 在base_test里实现virtual sequence的例化,通过function connect_phase实现子sequence和对应sequencer的连接。
- 定义virtual sequence,里面对各个sequence实例化,然后用uvm_do宏来进行sequencer的调度;(最后在具体的test定义里,用config_db机制把virtual sequencer的default_sequence设置为具体的virtual sequence)。
2.9 phase机制
1、什么是phase机制
UVM提供的一个梳理执行顺序的方案,把代码写到对应的phase里,这些phase就会按照一定顺序自动执行。
2、phase机制图
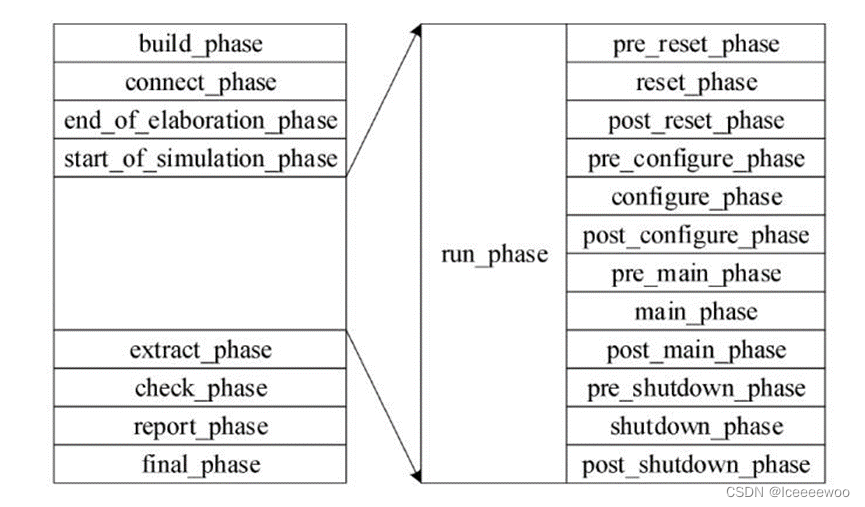
3、 phase有哪些
按照执行顺序有build_phase(进行组件的实例化,构建UVM树)、connect_phase(通过类中定义的各种数据接口来连接各个组件)、end_of_elaboration_phase(测试环境的微调,比如显示环境结构,打开文件等)、start_of_simulation_phase(准备testbench的仿真,设置断点,设置初始配置值)、run_phase,extract_phase(从tb中提取数据来观察设计的最终状态)、check_phase(检查不期望的数据)、report_phase(根据UVM_ERROR的数量来打印不同的信息,写到日志报告里)、final_phase(关闭文件,结束仿真)。
4、动态运行phase(run phase)
reset、configure、main、shutdown四个phase是核心,这四个phase通常模拟DUT的正常工作方式。每个phase又有pre(前)与post(后)之分,所以一共12个phase。
(1) reset_phase:对DUT进行复位、初始化等操作。
pre_reset_phase、post_reset_phase
(2) configure_phase:对DUT进行配置。
pre_configure_phase、post_configure_phase
(3) main_phase:DUT的运行主要在main_phase完成。
pre_main_phase、post_main_phase
(4) shutdown_phase:做一些跟DUT关机,断电相关的操作。
pre_shutdown_phase、post_shutdown_phase
(run_phase都是并行执行,其他的是串行。run_phase运行时间最长,从仿真开始到仿真结束,测试用例产生激励是在run_phase)。
5、function phase(不消耗仿真时间)
build_phase(自顶向下,因为是最先执行,用来构建UVM树的,需要从根结点出发往叶子结点一步步构建,否则下层的类还没有通过上层类来进行实例化),其他(均自下向上)。比如connect_phase也是自下向上,因为需要先连好下层模块才能继续连接上层模块。
6、task phase(消耗仿真时间)
run_phase(自顶向下,实际是自上而下的启动,同时运行)。
7、与phase相关的类
uvm_phase(定义了phase的行为、状态、内容),uvm_domain(phase的进度结点),uvm_bottomup_phase(实现bottomup函数),uvm_topdown_phase(实现topdown函数),uvm_task_phase(实现task phase,也就是run_phase)。
2.10 Objection机制
用来控制run_phase这种消耗仿真时间的phase的启动和结束,run_phase通过raise_objection来启动,最后通过drop_objection来结束,中间比如说,通过start来启动sequence,自动执行sequence里的body任务,等到sequence发送完后drop_objection。进入到某一个run_phase的时候,UVM会收集这个phase所有的raise_objection,并且实时监测它们有没有对应的drop_objection,如果所有的objection都被drop了,且如果有set_drain_time会等待延时过后,然后就关闭这个phase,到下一个phase,所有的phase都执行完了,就会调用$finish结束(关闭testbench)
2.11 factory工厂机制
1、什么是工厂机制
对testbench中的实例进行重写,提高代码的可重用性。
2、工厂机制的步骤
- registration注册,对component类型用uvm_component_utils宏注册,对object类型用uvm_object_utils宏注册,如果component类或者object类带了参数的话,就用uvm_component_param_utils或uvm_object_param_utils宏注册;
- construction对象的实例化,用component或object类型的对象用create方法来实例化;
- overriding重写覆盖,对component或object类型的覆盖,来提高代码的可重用性,比如说用set_inst_override_by_type(original_type, override_type, full_inst_path)方法来局部覆盖,set_type_override_by_type(original_type, override_type)方法来全局覆盖。
- 之后可以用factory.print来检查覆盖的结果,也可以用uvm_top.print_topology来显示UVM的拓扑结构
2.12 config_db机制
1、config_db的作用
uvm_config_db是一个参数化类,用于将不同类型的参数配置到uvm数据库中。通过set和get函数来在UVM各个模块间传递参数、接口,一般在build_phase使用。
2、set函数
有4个参数:uvm_component实例的指针;相对于第一个参数的相对路径;传递参数的标记,和get的第三个参数一样;传递参数的值
3、get函数
有4个参数:前两个参数含义和set一样;第3个参数也是传递参数的标记,和set的第三个参数一模一样;第4个参数是收信的参数变量名
4、省略get的情况
要用到field automation机制。首先收信的模块要在factory里注册;将收信模块中的目标变量在field automation机制实现;之后就睡自动调用build_phase里的super.build_phase()语句,自动执行相应的get函数
5、set函数的优先级(不同模块对同一个参数有多个set)
对于不同模块,取决于set函数的第一个参数的层次,越靠近UVM树的顶部,优先级越高;如果是同一个模块有多个set函数,后执行的set函数优先级更高
6、uvm_config_db和uvm_resource_db的区别
二者都是参数化的类,用来将不同类型的参数配置到uvm数据库中,uvm_config_db 采取的策略是“parent wins”,会按照UVM树的层次,TOP层的配置优先写入。uvm_resource_db 采取的是“last write wins”,是最后写入的配置优先,如果top层和bottom层都对同一个变量进行配置,在build_phase因为是top-down的执行顺序,最后写入的是bottom层的配置,就会被当成有效值写入,这个在UVM树形层次结构里用着不方便。
2.13 field_automation域的自动化机制
1、什么是field_automation
可以在factory机制注册UVM类的时候,同时声明一些后面会用到的成员变量,比如用来做对象拷贝、克隆、打印之类的变量。
2、field_automation使用方法
在factory机制注册一个component或object时,比如在uvm_component_utils_begin和end之间,用uvm_field_int宏来声明int变量,uvm_field_object宏来声明object句柄。这些宏都有两个参数(ARGument, FLAG),Argument是被声明的成员变量,FLAG是之后会参与的数据操作类型,比如UVM_ALL_ON, UVM_DEFAULT, UVM_COPY, UVM_COMPARE, UVM_PRINT等等
2.14 UVM的层次引用
build_phase构建UVM树的层次,之后层次引用是用来指定对象,比如要把sequencer类的对象连到driver的实例,可以在i_agt的connect_phase里用seq_item_port接口和seq_item_export接口把二者连起来(drv.eq_item_port.connect(sqr.seq_item_export);)
2.15 UVM的消息管理
1、信息的安全级别severity(反应的是信息的安全级别)
- UVM_INFO宏:用来打印信息,有3个参数,(1)id,字符串,用于把打印的信息归类;(2)message,字符串,具体需要打印的信息;(3)冗余级别Verbosity,UVM_NONE, UVM_LOW, UVM_MEDIUM(默认), UVM_HIGH,UVM_FULL, UVM_DEBUG,冗余级别越低越关键。
- UVM_WARNING宏:只有前两个参数id和message,verbosity是UVM_NONE。用来打印一些warning信息
- UVM_ERROR宏:只有前两个参数id和message,verbosity是UVM_NONE。用来打印一些error信息。可以在phase里借助set_report_max_quit_count函数来设置阈值,比如设置10个,当出现10个UVM_ERROR就会自动结束仿真
- UVM_FATAL宏: 只有前两个参数id和message,verbosity是UVM_NONE。用来打印致命错误信息,如果出现了UVM_FATAL,仿真会马上停止。
2、对冗余级别verbosity的打印控制
sim指令时加上+uvm_set_verbosity=veribosity,其中verbosity表示要打印信息的冗余程度,或者说是打印时容易被过滤的程度,比如UVM_LOW,那么所有冗余度低于UVM_LOW的都会被打印。
2.16 uvm_do系列宏
1、uvm_do的作用
创建一个transaction的实例,把它随机化,之后送给sequencer,等driver取走这个transaction后,返回一个item_done信号,uvm_do就执行完毕并返回,再执行下一次uvm_do,产生新的transaction。
2、一系列的uvm_do宏
第一类:uvm_do类
- uvm_do:只有一个参数,即产生的transaction
- uvm_do_pri(ority):除了第一个参数transaction外,还有一个参数priority优先级,sequencer的仲裁机制根据transaction的优先级来进行选择。没指定优先级时默认为-1,指定时的数值是大于等于-1的整数,数字越大,优先级越高。
- uvm_do_with:第一个参数transaction,第二个参数constraints,在随机化时对transaction的某些字段进行约束。
- uvm_do_pri_with:前两者的结合
第二类:uvm_do_on类
uvm_do_on:on表示展示出来,就是显式地指定产生的这个transaction具体是哪个sequencer来发送。它有两个参数,对应的就是transaction的指针和sequencer的指针。而对于uvm_do而言,它默认的sequencer就是调用uvm_do宏的这个sequence在启动时指定的sequencer
2.17 uvm_create和uvm_send
- 除了用uvm_do来产生txn,还可以用uvm_create和uvm_send来产生。
- uvm_create 用来实例化txn,uvm_send 把txn发送出去,还有uvm_rand_send宏是对一个已经实例化的txn,先进行随机化,再发送出去。
- uvm_send宏的主要作用 (相比于uvm_do):如果一个txn占用的内存比较大,前后的txn可以使用同一块内存,只是里面的内容不一样,可以节省内存。
2.18 事务级建模TLM
1、TLM的基本介绍
- Transaction Level Model,最早是在AVM里被提出的,用来在模块之间比如monitor和scoreboard之间直接进行通信的一种模型,本来如果没有TLM的话,需要用config_db机制,在base_test里set,在monitor和scoreboard里get,如果它们两要通信,monitor就对应地改这个config_object,scoreboard监测它,看它变没变,但是这个过程很麻烦,而且需要base_test的参与,可能base_test有一个子类不小心改到这个变量就会有问题,所以就引入了TLM,给monitor和scoreboard专门搭了一个桥梁,进行通信。
- TLM有两个通信的对象,叫initiator和target,发起通信的叫initiator,响应的叫target,这个指的是控制方向,不是数据传输的方向。而根据数据传输的方向对应有productor和consumer,数据传输,也就是transaction从productor传到consumer。
2、TLM的操作
有put,get,transport。put就是initiator把一个transaction发给target,get就是initiator向target索取一个transaction,transport相当于put+get,initiator先发一个请求,put过去,然后get,从target那里回来一个response。这三种操作都对应的有阻塞,非阻塞,和又可以阻塞又可以非阻塞(比如uvm_blocking_put_port #(txn), uvm_nonblocking_put_port #(txn), uvm_put_port #(txn))。阻塞就是,比如说monitor来了一个txn,scoreboard可能在忙,那monitor就等着scoreboard忙完了,接收了这个txn,monitor再返回;非阻塞就是,monitor发了一下,要是scoreboard忙,它不会等,直接返回。
3、TLM的端口与连接
- 基本端口:PORT, EXPORT, IMP三种类型,在initiator端例化PORT,在中间层次例化EXPORT,在target端例化IMP,例化的时候要指定好自己的端口,对应的操作,阻塞还是非阻塞(比如uvm_blocking_put_port #(txn), uvm_nonblocking_put_port #(txn), uvm_put_port #(txn))。然后在env的connect_phase里用connect函数来连接,比如initiator.port.connect (target.export),PORT连到EXPORT,再EXPORT连到IMP;或者PORT直接连到IMP。
- analysis系列端口:analysis_port和analysis_export端口:一个analysis端口可以连接多个IMP,类似广播,但是基本端口(put, get)默认是一对一的通信;analysis端口没有阻塞和非阻塞,因为是广播嘛,没什么等不等的,发了就返回了。
- analysis端口只有write操作:在analysis_imp对应的component,要定义一个write函数,参数是传递的transaction。
- uvm_tlm_analysis_fifo:比如在monitor和scoreboard之间加一个FIFO,FIFO做一个缓存的作用。没有FIFO的时候,Monitor发过来,scoreboard只能被动地选择接收或者忙的时候不接收,但是中间有了一个FIFO,就可以把数据先存到FIFO里,让scoreboard可以主动选择在不忙的时候接收transaction。monitor还是analysis_port,FIFO对着monitor和scoreboard的端口都是analysis_imp,而scoreboard也用port端口。还有几个FIFO相关的函数:is_empty / is_full可以查FIFO现在是否空 / 满,used函数可以查FIFO里目前有多少个txn,还有flush是复位的时候可以用来清空FIFO。(FIFO的好处)用了FIFO之后,就不用在scoreboard里写write函数了,它需要transaction的时候就找FIFO拿(get操作),可以主动选择接收。
2.19 Register Model寄存器模型
1、什么是Register Model
是对DUT的register建模,把各种register和对应的操作封装在一起,然后这个register model通过一个中间变量uvm_reg_bus_op来对DUT进行Register控制。
2、RAL(Register Abstraction Layer)
- 首先有一个uvm_reg_block:一般相同的base_address的register会放在同一个reg_block里。reg_block里有uvm_reg,对应的是DUT的每个register。uvm_reg里会有多个uvm_reg_field,对应的是这个register的每个bit field。
- uvm_reg_block 里还有uvm_reg_map来做地址映射,通过base_address和各个register的offset,对应到实际的memory里的地址。还可以进行前门访问。
- uvm_reg_block里还有uvm_reg_adapter,前门访问的时候会通过sequence产生一个uvm_reg_bus_op类型的变量,它需要在adapter里通过reg2bus和bus2reg的函数来转换成bus的transaction,再传给DUT。实现bus需要的txn和uvm_reg_bus_op之间的转换
- 另外还有uvm_memory,就是对DUT中的memory来建模用的。
- uvm_reg_predictor:用来观察DUT的register值的变化,把register的值送给scoreboard。reg_predictor也需要map来跟register model连在一起,还要adapter来进行bus2reg的转换。
3、前门访问
register model产生sequence,发给bus,之后bus传给DUT,对DUT进行register的操作,它是真实的物理时序访问,要消耗仿真时间。用来验证所有register访问DUT的物理通路正常工作。
4、后门访问
不经过bus总线,采用绝对路径对RTL寄存器进行读写操作,通过一些HDL函数(add_hdl_path,uvm_hdl_read, uvm_hdl_deposit),把register的操作直接传给DUT,不消耗仿真时间。前门访问没问题的基础上,用后门访问来节省访问register的时间。
三、验证通识/思想
有哪些验证手段?动态仿真、形式验证都有什么优缺点
门级仿真的作用是什么,STA的作用是什么
给一个模块,要能够根据SPEC进行功能点的分解,提出覆盖率
受约束的随机验证优缺点是什么
3.1 验证方法与流程
功能验证方法与流程
- 读specs文档还有接口文档,并提取功能点:写一个excel,根据specs列出具体的一个个小的功能点features和对应的各种寄存器的配置
- 根据spec文档和列出来的功能点,写testplan,对应各个功能点,列出之后需要写的各种testcase,收集覆盖率时要用到的断言,covergroup,coverpoint等
- 设计验证平台的结构,先确定可以复用的一些验证VIP,一般有总线的,时钟和复位的VIP,都会用上,然后确定为了这个IP本身在将来的复用,还需要把它的一些功能封装成VIP,每个VIP的对应一个agent,这个是最上层的,在这个agent里还有一些其他,比如基本的配置文件,sequencer,driver,monitor,这些VIP和DUT通过接口连接,所以在VIP内部还会有virtual interface来配套。还一定要有scoreboard,之后等DUT输出数据了,通过monitor送过去要和reference model的结果作比较,判断DUT输出的对不对
- 设计好验证平台的结构后,还要设计给DUT提供的激励有哪些,比如DUT的配置的随机化(在配置文件里一般会有register model,里面需要对各种register进行随机化,还有一些约束),还有一些总线,时钟复位VIP的配置随机化(比如时钟频率等,一般还会有约束,inside几种时钟频率);最主要的激励是sequences,给DUT输入的各种数据,控制信号等等,一种情形的激励要写成一个sequence class,所有的sequences放到一个大的文件里作为sequence library。
- 除了确定激励生成策略,还要设计check策略,主要是包括scoreboard和覆盖率,断言等等。scoreboard和监测DUT输出的monitor一般是通过TLM连接,scoreboard收到DUT的输出,要跟reference model的结果比较,判断DUT对不对。这个过程中还要收集覆盖率,需要写一些断言,covergroup,每个covergroup里还有一些coverpoint,每个coverpoint里会有一些bins,可能有的信号的值达不到,就写成ignore_bins。这些功能覆盖率相关的内容,在前面的testplan也会列出来,方便之后检查不能漏了。还有一些信号的组合需要写成cross
- 确定好这些之后,需要做一个review,和team讨论,修改验证计划
- 之后就可以开始用UVM搭建验证环境了
- 搭建好环境,需要再具体写详细的sequence,testcase,定义功能覆盖率
- 进行仿真,调试,每个testcase都要测过去,分析覆盖率,之后跑回归regression测试,反复修改迭代直到代码覆盖率和功能覆盖率都达到100%。过程中可能会测出DUT的bug,就跟设计那边沟通讨论
- 结束之后再开一次review,相比于第一次的review,这次要补充更多细节,包括过程中验出来的DUT的修改点
3.2 代码覆盖率与功能覆盖率
覆盖率用于评估验证的进度和testbench的完备性。
1、代码覆盖率
评估的是代码实现上的覆盖率,结合exclusion机制,代码覆盖率一般可以达到100%,但不代表testbench是完善的。
分类:1. 从代码本身来看,有branch coverage, condition coverage, statement coverage, expression coverage, trigger coverage; 2. 从状态机上看,有state coverage, transition coverage, Multi state - transition coverage; 3. 从仿真波形上看,有toggle coverage。(加粗的是QuestaSim支持的coverage)
2、功能覆盖率
代码覆盖率只能体现目前已经实现的设计需求有多少是被测试过的,但是不能体现在测试计划里,有哪些设计需求是根本没被实现的。因此引入了功能覆盖率,它指设计需求的覆盖率。
功能覆盖率通过covergroup来测试,每个covergroup里有若干个coverpoint,每个coverpoint有一组显式的bins值(功能覆盖率的衡量单位,最终的覆盖率等于采样覆盖到的bins数量除以总的bins数量)
3、代码覆盖率低,功能覆盖率高
说明写出来的设计需求或者covergroup基本都覆盖到了,但是代码实现里可能存在冗余,比如DUT有一些冗余的代码,导致这些冗余代码没有hit到。还有可能要检查一下功能覆盖里,会不会有covergroup本身写得不完善,比如有些采样值漏了,导致功能覆盖率是虚高,而相应地代码覆盖率是把这个问题给暴露出来了。
4、代码覆盖率高,功能覆盖率低
代码覆盖率高说明实现了的设计需求基本都正确实现了,那可以检查一下,有可能是有些设计需求根本就没实现;还有可能是测试激励数量少了,可以试试提高随机化次数或者增加一些随机化的约束;还有可能有的功能是一般情况下达不到的,是需要加到exclusion里的;还有可能有的cross自动生成了bins,但是我们不会hit到其中一部分bins,就可以用ignore_bins把这部分择出去。
3.3 OOP思想
1、OOP定义
指的是面向对象编程,有三大特性:封装,继承,和多态。
2、封装
指把对象的属性、方法封装在内部,外部访问时需要通过get或set方法来调用;
3、继承
指子类继承父类的属性和方法,并且可以另外定义自己的属性和方法,提高代码的可复用性。被声明为local的数据成员和方法只能对自己可见,对外部和子类都不可见;对声明为protected的数据成员和方法,对外部不可见,对自身和子类可见
4、多态
指方法的重写(覆盖)和重载,重写(覆盖)的参数列表和返回值不能变,重载是定义了多个同名函数,并且有不同的参数列表,返回值也可以不同
5、SV中的封装
静态变量/静态方法static和动态变量/动态方法automatic。static是仿真开始时就会被创建,直到仿真结束,可以被多个方法共享;automatic是进入该方法后自动创建,离开该方法后就被销毁
6、SV中的继承
从基类做扩展(extends)并产生新的子类的过程叫类的派生,当一个类被扩展并创建之后,该派生类就继承了其基类的数据成员、属性和方法,这就是类的继承。
继承后的类可以实现以下功能:
- 继承了原来类的方法,并可以修改
- 添加新的方法(function/task)
- 添加新的数据成员
在实现以上功能的同时需要满足一定的规则:
- 子类继承父类的所有数据成员和方法
- 子类可以添加新的数据成员和方法
- 子类可以重写基类中的数据成员和方法
- 如果一个方法被重写,其必须保持和父类的原有定义有一致的参数
- 子类可以通过super操作符来引用父类中的方法和成员
- 被声明为local的数据成员和方法只能对自己可见,对外部和子类都不可见;对声明为protected的数据成员和方法,对外部不可见,对自身和子类可见。
关于子类对象与父类对象的赋值问题:
- 子类对象是父类对象的有效表示,可以赋值给父类对象;
- 父类对象可以通过$cast的方式尝试给子类对象赋值,并判定是否赋值合法
在访问对象的过程中一般要遵循下面的规则:
- 通过父类的对象去引用子类中重写的属性和方法,结果只会调用父类的属性和方法
- 通过子类对象可以直接访问重写的属性和方法
- 在子类的扩展过程中,新增的属性和方法(包括重写的)对父类是不可见的(不可见就是父类不知道子类进行了重写)
- 子类可以通过super操作符访问父类中的属性和方法,以区分于本身重写的属性和方法
如果想子类中的重写的属性和方法在父类中可见,这时候可以用虚方法(virtual)。虚方法可以重写其所有基类中的方法,然而普通的方法被重写后只能在本身及其派生出的子类中有效
7、SV中的多态
所谓多态,当一个类派生出子类的时候,基类中的一些方法可能需要被重写,对象中的类型来决定调用方法的实现方式,通常这是一个动态的过程,动态的选择方法的实现方式叫多态。
封装可以隐藏实现细节,使代码模块化,继承可以扩展已经存在的代码模块,目的都是为了代码重用。而多态是为了实现接口的重用。
实际上虚方法(virtual)与重写的实现就是多态。这个的前提是虚方法的使用,声明父类句柄,既可以指向父类对象也可以指向子类对象,当句柄指向父类对象的时候调用的是父类的方法,当指向子类对象的时候调用的是子类的方法,因此,当父类的句柄指向不同的子类对象的时候,虚方法就表现出了不同的实现方法,呈现多态。
虚方法:
- 类中的方法可以在定义的时候通过添加virtual关键字来声明一个虚方法,虚方法是一个基本的多态性结构
- 虚方法为具体的实现提供一个原型,也就是在派生类中,重写该方法的时候必须采用一致的参数和返回值
- 虚方法可以重写其所有基类中的方法,然而普通的方法被重写后只能在本身及其派生类中有效
- 每个类的继承关系只有一个虚方法的实现,而且是在最后一个派生类中
最后
以上就是难过枕头最近收集整理的关于数字IC验证基础知识汇总一、SV基础二、UVM基础三、验证通识/思想的全部内容,更多相关数字IC验证基础知识汇总一、SV基础二、UVM基础三、验证通识/思想内容请搜索靠谱客的其他文章。








发表评论 取消回复