
Efficient and Effective Express via Contextual Cooperative Reinforcement Learning 作者:Yexin Li , Yu Zheng , Qiang Yang 近年来,物流快递服务覆盖了越来越多的城市,不仅推动了线上购物的普及,也给城市生活带来了极大的便利。 当对物流的需求呈逐步增长的时候,运营者通常通过增加快递员的数量来完成日益增长的配送件任务,但这种方式由于对快递员的管理调度比较欠缺,从而造成劳动力的浪费,并且不能从根本上解决送取件效率低下的问题。 因此我们提出了一个基于强化学习的优化模型,来实现快递员的动态调度管理,从而达到只利用一部分现有快递员来高效完成每天的大量送取件任务的目的。 在一个物流系统中,通常包含两类任务: 一是配送到达配送站的各个包裹到指定地点; 二是前往客户实时下单地点收取包裹。即我们平时所说的送件和收件。 基于此,我们本次所研究的优化模型包括两个步骤: 一是到达配送站的包裹如何分配给每个快递员; 二是从配送站出发的快递员,该如何实时规划他们的工作路径。 要优化上面的两个步骤,使得快递员每天能完成尽可能多的任务,并不是一个容易的问题,需要解决的挑战难点有三个: 第一个难点是,物流快递系统非常大,并且是随时间不断动态变化的。要同时管理调度大量的快递员来完成每天大量的送取件任务非常困难。 第二个难点是,在完成第一个步骤时,即如何在配送站分配包裹给每个快递员,我们需要基于实际情况考虑多个因素:分配给同一个快递员的包裹有相近的目的地;分配包裹时需要考虑将来可能产生的取件任务;各个快递员最好有大致相同的任务量,以免造成劳动力的浪费或工作过量的情况。 第三个难点是,对于第二个步骤,即如何实时规划每个快递员的作业路线,由于物流系统的动态性质,以及快递员作业时的一些随机因素,再加上我们的目标是使得在长时间内完成的总送取件任务数最大,这些都使得传统的最优化模型并不能很好的解决这个问题。 解决方案 针对以上难点,本文提出了一个基于强化学习的优化模型。针对第一个难点,我们先将城市划分成了多个独立的片区,然后分别管理每个片区内的快递员。 这样做的原因有两个: 第一,可以很大程度上降低问题的复杂度;第二, 位于城市中距离较远的两个片区中的快递员并不会有协同合作, 所以同时考虑整个城市并没有实际操作上的必要性。 城市片区的划分是基于已有的Connected Component Detection方法来完成的,最后得到的各个片区满足相互独立的性质。 如图所示,其中每个颜色表示一个独立的片区,每个片区有一些快递员在片区内作业来完成送取件任务。
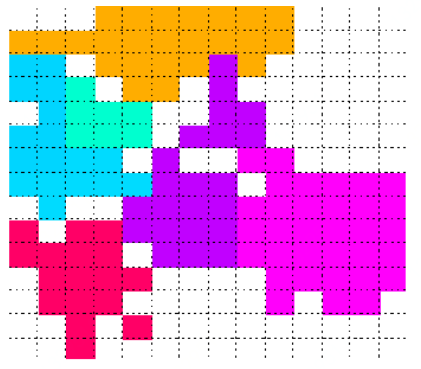 针对第二个难点,我们提出了一个名为Balanced Delivery Service Burden (BDSB)的聚类方法,即对当前片区内的所有包裹,基于它们的目的地来做聚类,得到的每一类包裹分配给同一个快递员。
针对第三个难点,我们提出了Contextual Cooperative Reinforcement Learning (CCRL) 优化模型,这是一个基于multi-agent 强化学习理论的模型。通过CCRL我们可以对每个片区学习得到一个快递员的指导策略,来实时规划各片区内的快递员作业路线,从而达到最大化长时间内完成的总送取件任务数量的目的。
本文根据历史物流数据设计了一个物流系统的仿真器,然后在仿真器中训练以及验证提出的算法模型。
论文原文链接:
http://urban-computing.com/pdf/yexinKDD2019.pdf
针对第二个难点,我们提出了一个名为Balanced Delivery Service Burden (BDSB)的聚类方法,即对当前片区内的所有包裹,基于它们的目的地来做聚类,得到的每一类包裹分配给同一个快递员。
针对第三个难点,我们提出了Contextual Cooperative Reinforcement Learning (CCRL) 优化模型,这是一个基于multi-agent 强化学习理论的模型。通过CCRL我们可以对每个片区学习得到一个快递员的指导策略,来实时规划各片区内的快递员作业路线,从而达到最大化长时间内完成的总送取件任务数量的目的。
本文根据历史物流数据设计了一个物流系统的仿真器,然后在仿真器中训练以及验证提出的算法模型。
论文原文链接:
http://urban-computing.com/pdf/yexinKDD2019.pdf
UrbanFM: Inferring Fine-Grained Urban Flows
作者:Yuxuan Liang, Kun Ouyang, Lin Jing, Sijie Ruan, Ye Liu, Junbo Zhang,David S. Rosenblum,Yu Zheng 近年来,城市人流量监控系统在智慧城市当中扮演着重要的角色。然而,细粒度的监控系统需要部署大规模的设备和传感器,这意味着系统维护需要大量的资金支持。 于是,京东城市联合西安电子科技大学和新加坡国立大学提出了一种基于深度神经网络的模型UrbanFM (Urban Flow Magnifier),能够利用粗粒度城市人流量数据准确地还原细粒度人流量数据,从而减少设备维护成本。 细粒度的城市流量监控系统是现代智慧城市信息系统中的一个关键组件,为城市的长期规划,实时交通管理等决策提供了基础的信息支撑。 这些流量监控系统的传感部分从路沿的监控摄像头到埋在地下的磁感线圈,再到各大运营商的信号基站,都在无时无刻为智慧城市的大脑服务。它们就好像是城市的眼睛,将整个城市的实时流量传输到控制中心,为大脑中央的管理人员提供一个管理城市的蓝图。
 ▲1.1 城市人流监控案例
然而,维持细粒度的监控系统的成本不容小觑,考虑到我们需要在城市的大量区域部署这些传感器,最终系统的传感器量级可能会是十万乃至百万级别的。维护这样大量的传感器将需要耗费我们大量的人力以及能源。考虑到全球智慧城市的兴起,这样的人力物力消耗将会更大,甚至可能会阻碍全球的进一步智慧化。
▲1.1 城市人流监控案例
然而,维持细粒度的监控系统的成本不容小觑,考虑到我们需要在城市的大量区域部署这些传感器,最终系统的传感器量级可能会是十万乃至百万级别的。维护这样大量的传感器将需要耗费我们大量的人力以及能源。考虑到全球智慧城市的兴起,这样的人力物力消耗将会更大,甚至可能会阻碍全球的进一步智慧化。
为了减少维护成本,一个简单的想法是减少传感器的数量,但是这样也会降低监控系统的粒度进而降低可用性。于是我们提出一个新的想法:“能不能减少监控系统中传感器的数量,但是却不改变系统所能获取到的信息粒度和精度?” 根据以上想法,我们先将整个城市进行栅格化划分,每个格子代表城市中的一个区域。很明显,根据不同的划分方式我们能得到不同粒度的城市人流量数据。例如,图1.2(b)展示了原有的细粒度某一时刻北京的城市流量图,而图1.2(a)是传感器减少后对应时刻的粗粒度城市流量图。图中的每一个格子的颜色(热度值)代表某一时刻该点的流量。我们的目标就是通过粗粒度的城市人流量数据来推断细粒度的人流量数据。 即给定一个特定的放大倍数和粗粒度人流量图,来推断该时刻对应的细粒度人流量图。
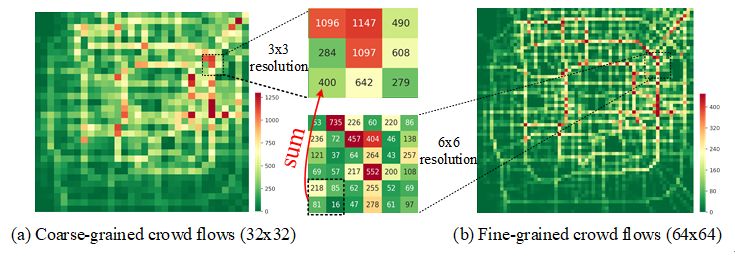 ▲1.2 不同粒度城市人流量示例
然而,推断细粒度的城市人流量需要考虑以下两个难点:首先,粗粒度流量图与对应的细粒度流量图之间具有空间结构性关系。从图中可以看到,粗粒度的流量图中每一个大区域(super-region)是由细粒度的几个小区域(sub-region)组成的,有着空间层次性。在同一时刻中,粗粒度图的每个大区域的流量等于所有构成该区域的小区域人流量的总和,如图样例所示。
所以,我们需要把这种空间层次性反映在我们的模型架构中。此外,不同区域之间也会有空间关联性,比如邻近区域的流量应该是相似的,而空间特征类似的区域流量也会相似。因此,我们需要考虑到空间上的层次性与关联性来进行模型设计。
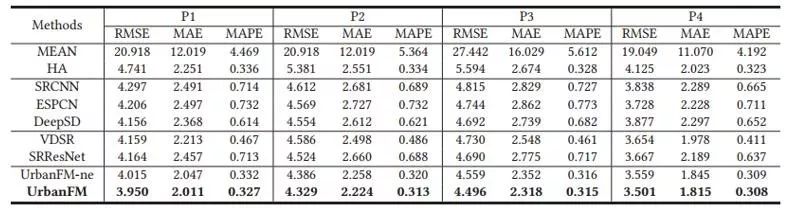
其次,除了城市人流量本身信息,我们还需要考虑外部因素的影响。通常来说,这些外部因素包括天气,时间,节假日等。比如,图1.3(a)展示了北京的一个核心区域,我们可以将这个核心区域看成粗粒度的大区域,进一步地将该区域划分为6*6个细粒度的小区域。每个小区域对应的地理属性(例如2级路段数目、景点数目等)也在图1.3(a)当中示出。
我们可以根据这些地理属性将该核心区域分为住宅区、办公区和游客景点等。之后,我们在图1.3(b)到(e)中绘出了不同外部因素条件下,该核心区域对应细粒度小区域的分布密度图。将图1.3(b)和1.3(d)对比可以看出,工作日雷暴雨的时候,人们会倾向于留在室内办公区而不是出门在外;再比如,将图1.3(b)和1.3(c)对比可以看出,人们在周末早上会倾向于公园里游玩而不是去公司上班。
单独来看,这些外部因素会对我们推断细粒度城市人流量有不可忽视的影响。而且,这些因素还可能因为互相耦合而增加我们分析这些影响的难度。所以,如何考虑到外部因素的影响成为了挑战之一。
▲1.2 不同粒度城市人流量示例
然而,推断细粒度的城市人流量需要考虑以下两个难点:首先,粗粒度流量图与对应的细粒度流量图之间具有空间结构性关系。从图中可以看到,粗粒度的流量图中每一个大区域(super-region)是由细粒度的几个小区域(sub-region)组成的,有着空间层次性。在同一时刻中,粗粒度图的每个大区域的流量等于所有构成该区域的小区域人流量的总和,如图样例所示。
所以,我们需要把这种空间层次性反映在我们的模型架构中。此外,不同区域之间也会有空间关联性,比如邻近区域的流量应该是相似的,而空间特征类似的区域流量也会相似。因此,我们需要考虑到空间上的层次性与关联性来进行模型设计。
其次,除了城市人流量本身信息,我们还需要考虑外部因素的影响。通常来说,这些外部因素包括天气,时间,节假日等。比如,图1.3(a)展示了北京的一个核心区域,我们可以将这个核心区域看成粗粒度的大区域,进一步地将该区域划分为6*6个细粒度的小区域。每个小区域对应的地理属性(例如2级路段数目、景点数目等)也在图1.3(a)当中示出。
我们可以根据这些地理属性将该核心区域分为住宅区、办公区和游客景点等。之后,我们在图1.3(b)到(e)中绘出了不同外部因素条件下,该核心区域对应细粒度小区域的分布密度图。将图1.3(b)和1.3(d)对比可以看出,工作日雷暴雨的时候,人们会倾向于留在室内办公区而不是出门在外;再比如,将图1.3(b)和1.3(c)对比可以看出,人们在周末早上会倾向于公园里游玩而不是去公司上班。
单独来看,这些外部因素会对我们推断细粒度城市人流量有不可忽视的影响。而且,这些因素还可能因为互相耦合而增加我们分析这些影响的难度。所以,如何考虑到外部因素的影响成为了挑战之一。
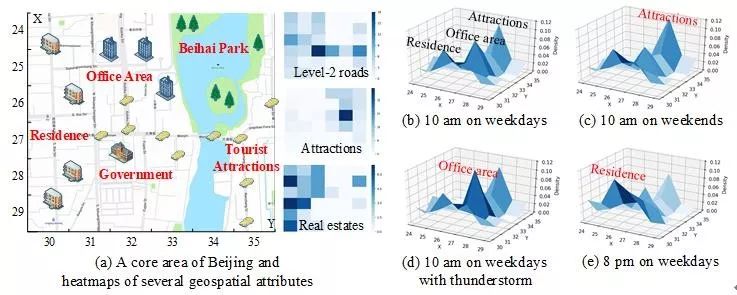 ▲图1.3 外部因素的影响示例
▲图1.3 外部因素的影响示例
解决方案
从本质来看,推断细粒度的城市人流量是一个以低信息熵的输入推导并恢复高信息熵的输出的问题,这和图像超分辨率是很相似的。然而,图像超分辨率相关算法并不能考虑到以上提及的难点与挑战。借鉴了图像复原(包括超分辨率、去噪等)的核心思想,即空间特征提取-高层特征抽象-根据高层信息重建的范式,我们提出了一个基于深度神经网络的模型UrbanFM。 该模型能同时考虑到空间结构性以及外部因素的影响,基于粗粒度的城市流量数据来实时推断细粒度的城市人流量。该模型的框架如图1.4所示,此时放大倍数。拆解来看,主要分为推断网络(Inference Network)和外部因素融合网络(External Factor Fusion)两个部分。
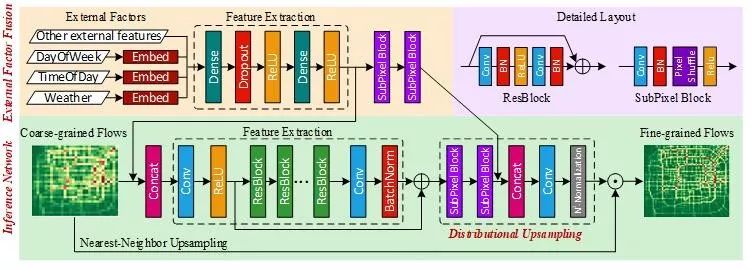 ▲ 图1.4 UrbanFM整体框架
▲ 图1.4 UrbanFM整体框架
推断网络是模型的主网络。首先,它将粗粒度流量图作为输入,使用残差网络(ResNet)进行特征提取,同时能考虑到区域之间的空间关联性。之后,将提取出的高阶特征进行分配上采样(distributional upsampling)来得到每个粗粒度大区域对应的细粒度小区域的分布矩阵。最后,将原始粗粒度流量图和分布矩阵进行按位相乘即可得到细粒度流量图。 其中,分配上采样是核心模块,能够很好的考虑到粗粒度和细粒度人流量图之间的空间层次性关系。 具体来说,分配上采样模块先使用Subpixel块对原始粗粒度图提取的高阶信息进行上采样,将特征图的尺寸放大倍得到细粒度的特征图;再使用一个卷积层和提出的N2归一化层将放大后的特征图转化为分布矩阵。这里的N2归一化层相比于直接使用损失函数约束空间层次性有几大优势。 它是一个无参数层,没有给网络带来额外开销,并且易于实现(如图1.5所示)。在实验中,我们也发现使用N2归一化层比使用损失函数约束空间层次性的效果要好很多。
 ▲图1.5 N2归一化层的实现
此外,我们还设计了外部因素融合模块来综合考虑所有的外部因素的影响,从而来提升推断的准确率。外部因素分为离散变量和连续变量。对于离散变量,我们将它们分别进行向量嵌入(embedding)。之后,我们将所有嵌入向量和连续变量拼接作为卷积神经网络的输入来提取高阶表示。最后,将该高阶表示分别在推断网络的不同位置进行融合,如图1.4所示。
实验结果
我们使用了四个不同时间段的北京的人流量数据进行了多角度的实验来验证模型的性能。此外,为了探究模型的适应性,我们也使用了一个局部区域(北京欢乐谷主题公园)的人流量数据进行了模型验证。数据集的细节如图1.6所示。
▲图1.5 N2归一化层的实现
此外,我们还设计了外部因素融合模块来综合考虑所有的外部因素的影响,从而来提升推断的准确率。外部因素分为离散变量和连续变量。对于离散变量,我们将它们分别进行向量嵌入(embedding)。之后,我们将所有嵌入向量和连续变量拼接作为卷积神经网络的输入来提取高阶表示。最后,将该高阶表示分别在推断网络的不同位置进行融合,如图1.4所示。
实验结果
我们使用了四个不同时间段的北京的人流量数据进行了多角度的实验来验证模型的性能。此外,为了探究模型的适应性,我们也使用了一个局部区域(北京欢乐谷主题公园)的人流量数据进行了模型验证。数据集的细节如图1.6所示。
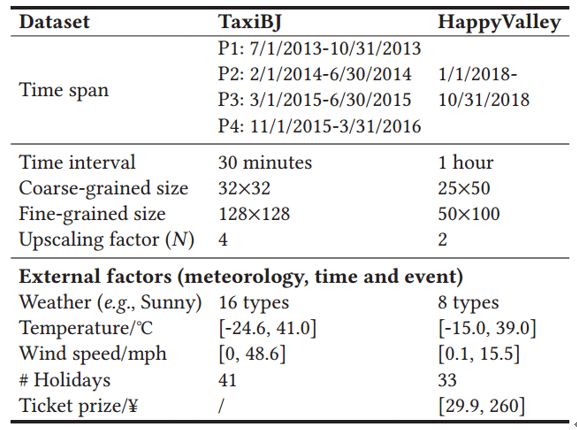 ▲图1.6 数据集细节
通过实验结果可以发现,与领域内领先算法相比,UrbanFM在北京四个时间段的推断结果的均方根误差,平均绝对误差以及平均绝对相对误差上的性能表现均有明显提升。
▲图1.6 数据集细节
通过实验结果可以发现,与领域内领先算法相比,UrbanFM在北京四个时间段的推断结果的均方根误差,平均绝对误差以及平均绝对相对误差上的性能表现均有明显提升。
 除了性能表现上的提升之外,我们还能通过对distributional upsampling模块输出进行可视化来观察外部因素对实际推断的影响。为此,我们选取了位于北京大学附近的一个大区域作为代表,以时间为影响自变量,将7:00到21:00时间段内该区域内对于4*4的小区域的流量分布展示在图1.7的GIF中。该区域的左上方是实验室和办公区,中间是餐饮区,下方是住宅区。
除了性能表现上的提升之外,我们还能通过对distributional upsampling模块输出进行可视化来观察外部因素对实际推断的影响。为此,我们选取了位于北京大学附近的一个大区域作为代表,以时间为影响自变量,将7:00到21:00时间段内该区域内对于4*4的小区域的流量分布展示在图1.7的GIF中。该区域的左上方是实验室和办公区,中间是餐饮区,下方是住宅区。
 实验区域
实验区域

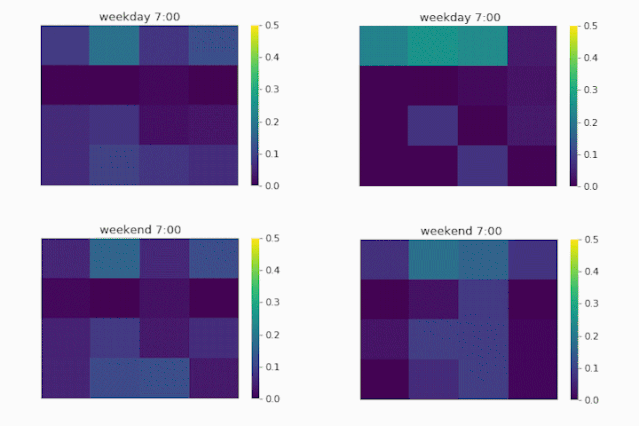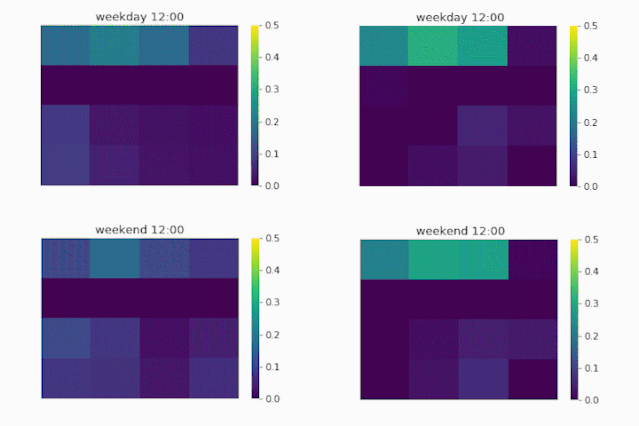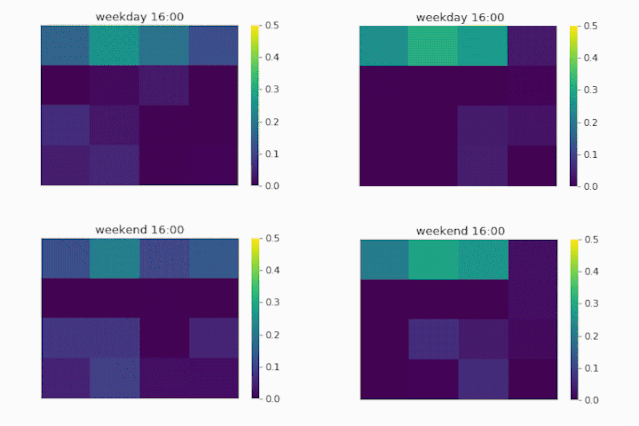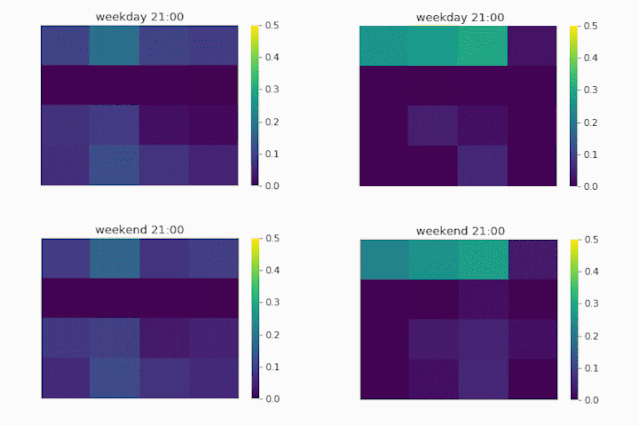 ▲图1.7 流量分布矩阵可视化
首先我们看到工作日的流量图(第一行)。从图中可以看到,当模型没能考虑时间的影响时(UrbanFM_ne, ne 意为no external),所推断出来的流量分布近乎于不变,即从早到晚的流量分布权重一直都集中在办公区域,而这显然是符合我们的经验直觉的。
而当我们的模型把时间的因素给考虑进来后(UrbanFM),可以看到早上的办公区域的分布首先是较低的,并随着时间的推移,住宿区的人流量开始降低,办公区的流量开始增大, 并在10-11点到达顶峰;这样流量分布一直平稳维持直到下午6点的下班时间,随后办公区域流量开始减少,人口开始回流到住宿区。
而对比到周末的流量分布(第二行),可以看到周末时UrbanFM模型对办公区区域的所推断的流量分布显著地少于工作日时。这和我们的直觉吻合,即,人们一般在工作日的白天工作而在晚上以及周末时回家休息。
因此,这样的动态可视化不仅强调了外部因素对于我们进行细粒度流量推断的影响,还提高了我们深度学习模型的可解释性,这样的可解释性可以让我们更直观地观察以及分析不同因素对不同地区的流量分布的影响,为后续的管理和决策提供有力的支持。
关于更多的技术细节,更多的对模型的量化评估以及更多的可视化分析,欢迎读者们关注我们的paper以及我们的github。
参考资料:
[1] UrbanFM: Inferring Fine-Grained Urban Flows (KDD, 2019)
Link:https://www.comp.nus.edu.sg/~david/Publications/kdd2019-preprint.pdf
论文原文链接:
http://urban-computing.com/pdf/yuxuanUrbanFMKDD2019.pdf
Urban Traffic Prediction from Spatio-Temporal Data Using Deep Meta Learning
作者:Zheyi Pan, Yuxuan Liang, Weifeng Wang, Yong Yu,
Yu Zheng, Junbo Zhang
▲图1.7 流量分布矩阵可视化
首先我们看到工作日的流量图(第一行)。从图中可以看到,当模型没能考虑时间的影响时(UrbanFM_ne, ne 意为no external),所推断出来的流量分布近乎于不变,即从早到晚的流量分布权重一直都集中在办公区域,而这显然是符合我们的经验直觉的。
而当我们的模型把时间的因素给考虑进来后(UrbanFM),可以看到早上的办公区域的分布首先是较低的,并随着时间的推移,住宿区的人流量开始降低,办公区的流量开始增大, 并在10-11点到达顶峰;这样流量分布一直平稳维持直到下午6点的下班时间,随后办公区域流量开始减少,人口开始回流到住宿区。
而对比到周末的流量分布(第二行),可以看到周末时UrbanFM模型对办公区区域的所推断的流量分布显著地少于工作日时。这和我们的直觉吻合,即,人们一般在工作日的白天工作而在晚上以及周末时回家休息。
因此,这样的动态可视化不仅强调了外部因素对于我们进行细粒度流量推断的影响,还提高了我们深度学习模型的可解释性,这样的可解释性可以让我们更直观地观察以及分析不同因素对不同地区的流量分布的影响,为后续的管理和决策提供有力的支持。
关于更多的技术细节,更多的对模型的量化评估以及更多的可视化分析,欢迎读者们关注我们的paper以及我们的github。
参考资料:
[1] UrbanFM: Inferring Fine-Grained Urban Flows (KDD, 2019)
Link:https://www.comp.nus.edu.sg/~david/Publications/kdd2019-preprint.pdf
论文原文链接:
http://urban-computing.com/pdf/yuxuanUrbanFMKDD2019.pdf
Urban Traffic Prediction from Spatio-Temporal Data Using Deep Meta Learning
作者:Zheyi Pan, Yuxuan Liang, Weifeng Wang, Yong Yu,
Yu Zheng, Junbo Zhang
城市交通预测是城市计算领域中一个非常重要的研究课题,准确的交通预测可以帮助我们更好地理解城市交通,给交通系统的改进提供思路,同时也能对民众提供及时的城市交通预警。 然而,准确的城市交通预测需解决以下两个挑战: 1) 交通数据间复杂的时空相关性,即一个地点的交通状况会影响其未来一段时间内的交通,也会影响其周围区域的交通。 如图2.1(a)所示,当地点S3发生交通事故时,可能导致它相邻的地点S1,S2,S4堵车;当地点S4有重大事件发生时(例如,演唱会),将有大量的人群涌向S4,从而影响S4未来一段时间的交通状态。 2) 不同地点间,数据的时空相关性是多样的,并且这样的相关性取决于地理信息,如地点周围的兴趣点,路网结构等。 如图2.1(b)区域R1、R2和R3拥有不同的POI分布和路网结构。其中,R1、R3有较多的办公楼,表示工作区,而R2有较多的住宅,表示一个住宅区。如图2.1(c)所示,这些区域的POI分布、路网结构不同,导致,R1、R2、R3三个区域的流入人流量趋势各不相同。 但同时,由于R1与R3的POI分布较相似,它们的流量趋势呈现出一定的相似性。因此,交通预测的核心挑战就是建模交通数据中的时空相关性和地理信息对时空相关性的影响。
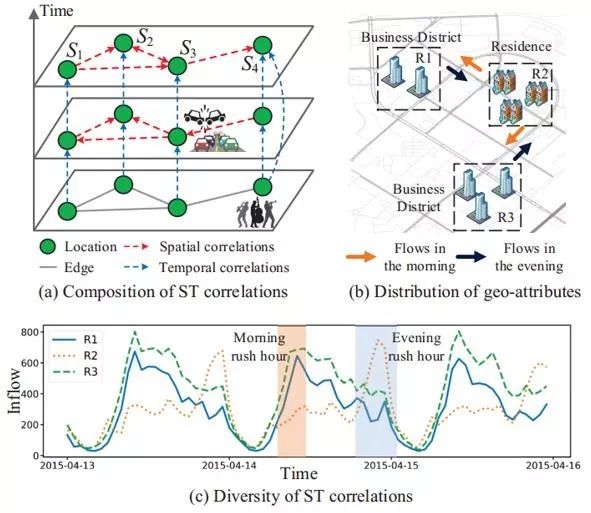 ▲图2.1 城市交通预测的挑战
▲图2.1 城市交通预测的挑战
解决方案 为了能在一般化的非规则空间结构上(如路网)预测未来交通,我们首先需要将交通的关联模式抽象成图结构。其中,每个点表示的地图上的地点,而边表示的是两个地点间的关联。接下来,我们提出参数生成的方式,来建模地理信息对时空相关性的影响。如图2.2所示,我们用一个模型从节点的地理特征中,学习节点和边的特性,而后用这些特性,进而学习时间、空间的关联性模型。最后用学到的模型进行交通预测。
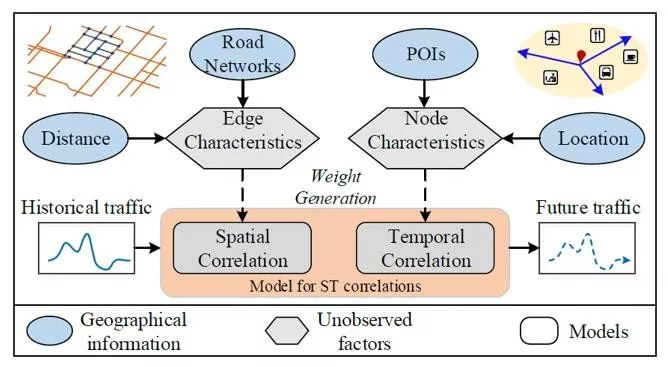 ▲图2.2
为此,我们引入sequence-to-sequence架构,如图2.3所示,其中包含:
▲图2.2
为此,我们引入sequence-to-sequence架构,如图2.3所示,其中包含:
1. 循环神经网络(RNN),将交通数据编码映射到高维的空间,学习高维特征。 2. 元知识学习器(Meta-Knowledge Learner)。 如图2.3(b)我们用两个元知识学习器,分别从点和边的地理信息中学习点元知识(Node meta knowledge,NMK)和边元知识(Edge metaknowledge,EMK),用于生成模型的参数。 3. 基于元学习的图注意力网络(Meta-GAT)。 该网络接收RNN的输出,用于建模多样的空间关联。由于在图结构中,不同的边所描述的空间相关性取决于这条边的特征属性,所以,我们用一个元学习器从地理信息的元知识中学习GAT模型(图2.3(c))。 4. 基于元学习的循环神经网络(Meta-RNN)。 该网络接收Meta-GAT的输出,用于建模多样的时间关联性。我们从每个节点地理信息的元知识中学习RNN的参数,来对多样的时间相关性建模(图2.3(d))。
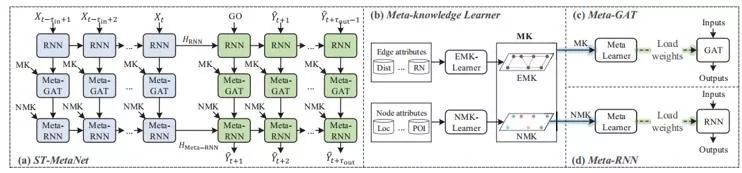 ▲图2.3
▲图2.3
实验结果 最后,我们使用出租车流量预测和道路车辆速度预测这两个真实的任务来验证模型的性能。如表 2.4 所示,从MAE和RMSE这两个指标上看,我们的模型在使用更少参数的情况下,都要优于之前最好的结果。
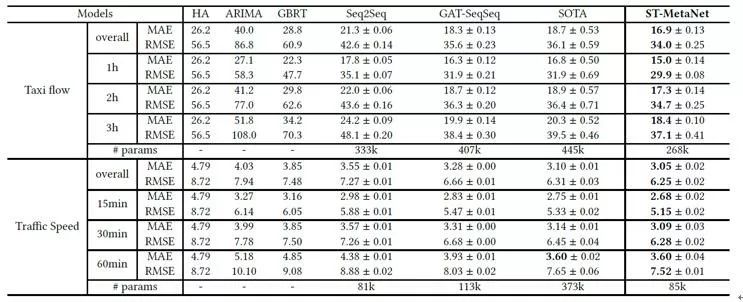 ▲表2.4
同时我们测试了各个模块的提升效果。如
图2.5
所示,在基准模型基础上,每加上一个模块,模型都能取得更好的结果。应用上所有模块后,模型的预测准确率最高。
▲表2.4
同时我们测试了各个模块的提升效果。如
图2.5
所示,在基准模型基础上,每加上一个模块,模型都能取得更好的结果。应用上所有模块后,模型的预测准确率最高。
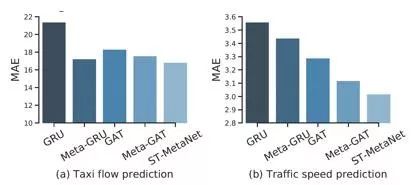 ▲图2.5
▲图2.5
为了进一步说明深度元学习的有效性,我们对模型所学习到的点元知识进行评估。对于每个节点,其元知识是表征该节点特性的嵌入向量。一组好的嵌入向量需要能表征节点之间的相似度。 为此,我们在节点的嵌入空间下(Embedding space),找到每个节点的k邻近节点。然后,用交通数据的测试集计算每个节点和其k临近节点的平均相似度。这里我们选用两种序列相似度指标:Pearson相关性(CORR)和一阶时间相关性(CORT),这两个值越大,表示相似度越高。如图2.6所示,用元学习方法学到的嵌入空间,每个节点与其周围节点的相似度明显高于在非元学习方法的嵌入空间下节点与其邻近节点的相似度。
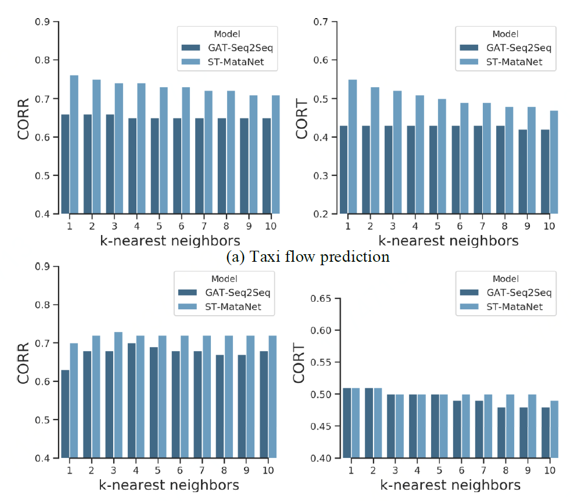 图2.6
图2.6
最后,我们用一个实例来展现元学习的优势。在出租车流量预测任务中,我们选取3个典型的区域:永泰园、中关村和三元桥,分别对应于住宅区、办公区和交通枢纽。然后,我们在嵌入空间下,分别找到它们最近的节点,并且将所有节点所对应的交通流量画在图上。图2.7(a)展现的是非元学习下,每个区域和它在嵌入空间下相邻区域的流量比较。可以发现,在该嵌入空间下,节点和其相邻点并不相似。而图2.7(b)展现的是元学习下的结果,对于每个区域,其嵌入空间下相邻的区域都跟它有非常相似的流量趋势,进而说明了元学习方法的有效性。
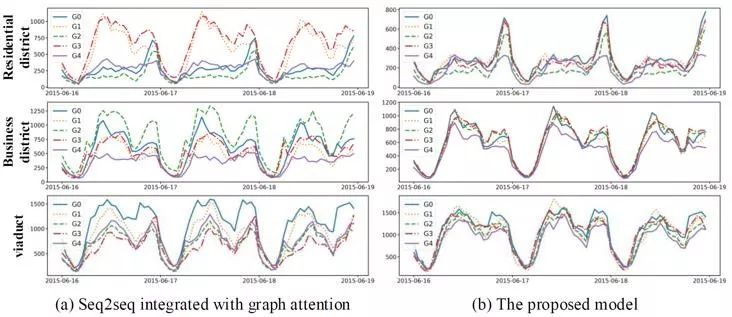 图2.7
图2.7
http://urban-computing.com/pdf/kdd_2019_camera_ready_ST_MetaNet.pdf
TrajGuard: A Comprehensive Trajectory Copyright Protection Scheme 作者:Zheyi Pan, Jie Bao, Weinan Zhang, Yong Yu, Yu Zheng 轨迹数据记录了人们活动的大量信息,在城市各个场景中被广泛使用,如交通预测,兴趣点推荐等等,因此很多公司或科研机构向他人公开或售卖数据。但由于轨迹中包含非常多敏感而有价值的信息,所以有必要构建一种机制来有效监管轨迹信息的共享和传播,来识别其他恶意用户的二次售卖行为,阻止他们非法获利。 然而,由于恶意用户可以修改轨迹数据后发布或售卖,如何在数据被篡改后依然识别数据的版权方,是一个很大的挑战。
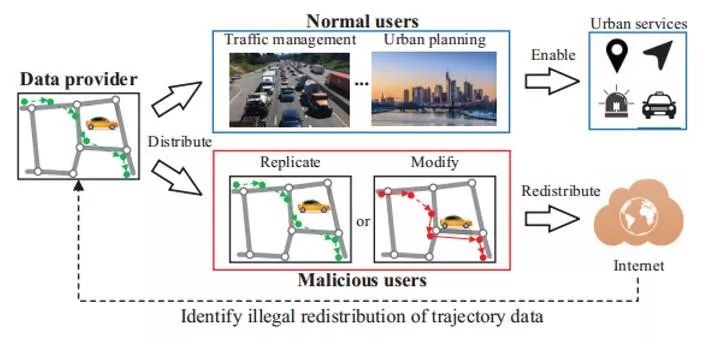 图3.1 轨迹数据的版权保护
另外,由于轨迹数据敏感,没有公认的第三方机构能够存储所有轨迹数据来监管数据的版权信息,导致版权信息的真实性难以验证。
解决方案
为了解决以上问题,我们提出了一个去中心化的轨迹版权保护方案。该方案将版权信息嵌入到轨迹数据中,使之能够有效抵御恶意用户的攻击(即在被恶意用户篡改轨迹数据的情况下,依然能识别出轨迹数据所包含的版权信息)。
同时,该方案能够追踪所有的交易记录和版权信息,使任何一笔轨迹交易记录和已嵌入的版权信息能够被验证。
该版权保护方案主要包含三个部分:1)将原始轨迹在时空网格上切分成若干段子轨迹,并将用户的版权信息嵌入到每条子轨迹中;2)对于每一条子轨迹,我们通过调节该轨迹的重心距来嵌入版权信息;3)用一个区块链去中心化地维护所有轨迹数据交易的版权信息,使得在没有将数据交给第三方机构的前提下,方案能够验证交易记录和版权信息的真实性。
图3.1 轨迹数据的版权保护
另外,由于轨迹数据敏感,没有公认的第三方机构能够存储所有轨迹数据来监管数据的版权信息,导致版权信息的真实性难以验证。
解决方案
为了解决以上问题,我们提出了一个去中心化的轨迹版权保护方案。该方案将版权信息嵌入到轨迹数据中,使之能够有效抵御恶意用户的攻击(即在被恶意用户篡改轨迹数据的情况下,依然能识别出轨迹数据所包含的版权信息)。
同时,该方案能够追踪所有的交易记录和版权信息,使任何一笔轨迹交易记录和已嵌入的版权信息能够被验证。
该版权保护方案主要包含三个部分:1)将原始轨迹在时空网格上切分成若干段子轨迹,并将用户的版权信息嵌入到每条子轨迹中;2)对于每一条子轨迹,我们通过调节该轨迹的重心距来嵌入版权信息;3)用一个区块链去中心化地维护所有轨迹数据交易的版权信息,使得在没有将数据交给第三方机构的前提下,方案能够验证交易记录和版权信息的真实性。
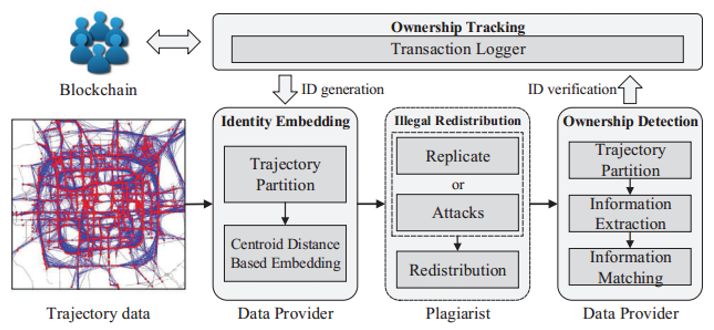 图3.2. TrajGuard系统框架
图3.2. TrajGuard系统框架
我们在两个真实的轨迹数据上测试了我们的方案,实验结果能够充分验证该方案的有效性。 论文原文链接: http://urban-computing.com/pdf/kdd_2019_camera_ready_TrajGuard.pdf
Unifying Inter-region Autocorrelation and Intra-region Structures for Spatial Embedding via Collective Adversarial 作者:Yunchao Zhang, Yanjie Fu, Pengyang Wang, Xianli Li, Yu Zheng 无监督地理表征学习主要借助地块内部一些有效的地理特征以及一些结构化的数据来进行地块的辨别。 已有的一些工作主要借助图表征学习将每个地块看作一个图节点或者一张图来进行学习;这样的方法很难同时周全地考虑到区域内部的一些结构特征和区域间的空间相关性。 于是,京东城市联合密苏里科技大学和南京大学提出了一种基于无监督协同对抗学习的模型CGAL(Collective Graph-regularized dual-adversarial Learning)来同时建模区域内的结构特征和区域间的自相关性进行地理区域的表征学习。 背景介绍 城市的地块表征学习主要为了融合学习城市内的多源异构的特征数据来进行地块的辨别,这些表征同时也可以帮助更好的理解城市的结构和动态变化过程,帮助区域规划,提高城市的管理效率。 但同时,城市中的很多数据都是没有标签的,这对很多真实的应用场景带来很大的挑战。为此,本文采用深度无监督学习模型来探索地理表征的学习。同时为了保存学习时地块内部和地块之间的一些特征和相关性,模型构建了多种结构化的特征,采用基于自动编码器的监督协同学习对抗网络进行表征的学习。 问题描述 本文首先将城市划分成很对个地块区域
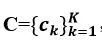 ,每个地块内部有很多建筑,POIs分布,路网,打卡文本信息,人口流量信息等。对于每个区域,可以将内部的每一个类别的POI当做一个节点来构造多个图结构特征
,每个地块内部有很多建筑,POIs分布,路网,打卡文本信息,人口流量信息等。对于每个区域,可以将内部的每一个类别的POI当做一个节点来构造多个图结构特征
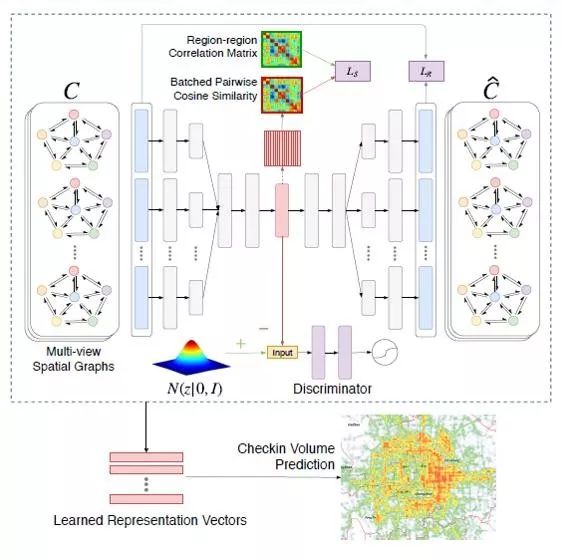 ▲图4.1:CGAL整体模型框架
▲图4.1:CGAL整体模型框架
整个模型框架主要包含三个部分:(1)对每个区域构建多视角图特征;(2)利用无监督协同图正则对抗编码-解码网络进行地块区域的表征学习;(3)学习得到的区域表征在人口流量预测任务上的应用。 首先,在每个地块区域内部构造多视角图结构特征,比如,每一类POI当做一个节点,可以计算每一类POI之间的平均距离,得到一张图,同时每一类POI之间转移的人口流量可以用来构建另一张图。
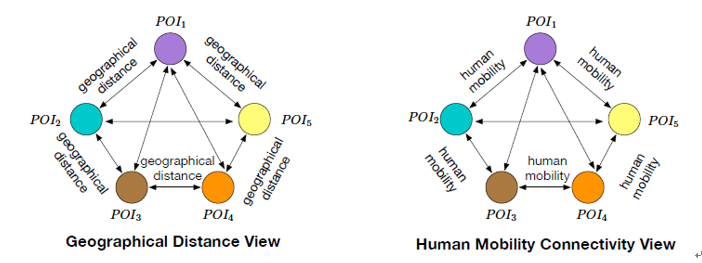 ▲多视角特征图构建
然后,我们提出协同图正则对抗自编码网络来联合学习区域内的特征和区域间的关系特征,具体地,对于每个区域,输入为内部构建的多个图结构特征(地理距离图、人口流量图),一种集成编码方法将多视角特征聚集学习得到一个隐含的表征向量,然后分解拆开映射得到原始的多视角输入。
与此同时,在中间的隐含表征层,模型提出了利用对偶对抗学习的方法进行隐含表征向量的正则化,该部分包含两部分对抗网络:
(1)利用KL divergence最小化学习得到的后验分布(隐含向量的分布)与先验概率的分布距离,得到基本的生成对抗网络(GAN)的目标函数表达式,不同于传统的GAN,这里是让隐含特征分布逼近设置的一个先验概率分布。
▲多视角特征图构建
然后,我们提出协同图正则对抗自编码网络来联合学习区域内的特征和区域间的关系特征,具体地,对于每个区域,输入为内部构建的多个图结构特征(地理距离图、人口流量图),一种集成编码方法将多视角特征聚集学习得到一个隐含的表征向量,然后分解拆开映射得到原始的多视角输入。
与此同时,在中间的隐含表征层,模型提出了利用对偶对抗学习的方法进行隐含表征向量的正则化,该部分包含两部分对抗网络:
(1)利用KL divergence最小化学习得到的后验分布(隐含向量的分布)与先验概率的分布距离,得到基本的生成对抗网络(GAN)的目标函数表达式,不同于传统的GAN,这里是让隐含特征分布逼近设置的一个先验概率分布。
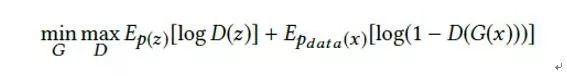 (2)利用另外一个生成对抗网络进行隐含向量自相关性的约束正则,任意两个区域学习得到的隐含向量可以计算得到一个cosine相似度,将这个相似度矩阵和利用已有数据特征计算得到的相似度矩阵进行逼近。
(2)利用另外一个生成对抗网络进行隐含向量自相关性的约束正则,任意两个区域学习得到的隐含向量可以计算得到一个cosine相似度,将这个相似度矩阵和利用已有数据特征计算得到的相似度矩阵进行逼近。
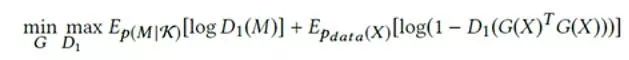 最后正则化部分的目标函数如下,编码器作为公用的一个Generator,加上两个不同的Discriminator,再加上Decoder的还原输入部分的loss 进行参数的交替迭代优化学习:
最后正则化部分的目标函数如下,编码器作为公用的一个Generator,加上两个不同的Discriminator,再加上Decoder的还原输入部分的loss 进行参数的交替迭代优化学习:
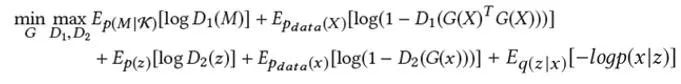 最后,每个区域都能学习得到一个保存了区域内部特征属性和区域间相关性的隐含表征,利用该表征对区域的人口流入数量进行预测。
最后,每个区域都能学习得到一个保存了区域内部特征属性和区域间相关性的隐含表征,利用该表征对区域的人口流入数量进行预测。
实验结果 文章利用学习得到的每个地块表征,建立一个简单的线性回归模型来进行地块的流行度预测,地块流行度根据地块流入人口量计算得到,流量越大,流行度越高。 通过在真实的数据集上进行实验比较,文章提出的CGAL模型比几个流行的模型效果都有更好的提升。
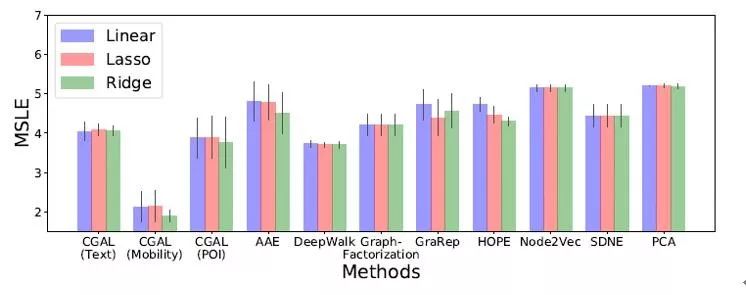 ▲图4.3:CGAL模型与其他模型的实验性能比较
同时,通过对输入的图特征数量的改变,发现多视角的图特征作为输入相较于单视角的图特征能有更好的模型效果,这也验证了构造更多有效的特征信息能够为地块的表征学习带来更多有用的帮助。
▲图4.3:CGAL模型与其他模型的实验性能比较
同时,通过对输入的图特征数量的改变,发现多视角的图特征作为输入相较于单视角的图特征能有更好的模型效果,这也验证了构造更多有效的特征信息能够为地块的表征学习带来更多有用的帮助。
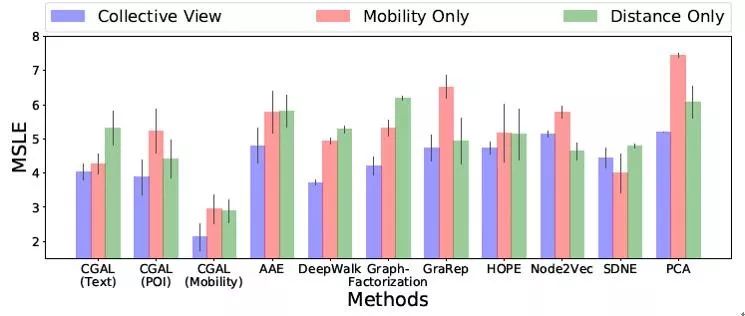 ▲图4.4:多视角特征与单视角特征的实验效果比较
在隐含表征层,当使用人口流动计算得到的相似度进行约束正则时,模型性能效果比使用文本数据和POI数据计算得到的相似度要更好,表明实际的人口流量预测任务与已有的人口流动数据更加相关。
与此同时,利用对偶对抗网络进行隐含表征层的共同约束正则相比于使用单个对抗网络有着更好的实验性能,这也验证了模型提出的在学习地块区域表征时应该同时考虑区域内部的特征和区域之间的相关性这一想法的合理性。
▲图4.4:多视角特征与单视角特征的实验效果比较
在隐含表征层,当使用人口流动计算得到的相似度进行约束正则时,模型性能效果比使用文本数据和POI数据计算得到的相似度要更好,表明实际的人口流量预测任务与已有的人口流动数据更加相关。
与此同时,利用对偶对抗网络进行隐含表征层的共同约束正则相比于使用单个对抗网络有着更好的实验性能,这也验证了模型提出的在学习地块区域表征时应该同时考虑区域内部的特征和区域之间的相关性这一想法的合理性。
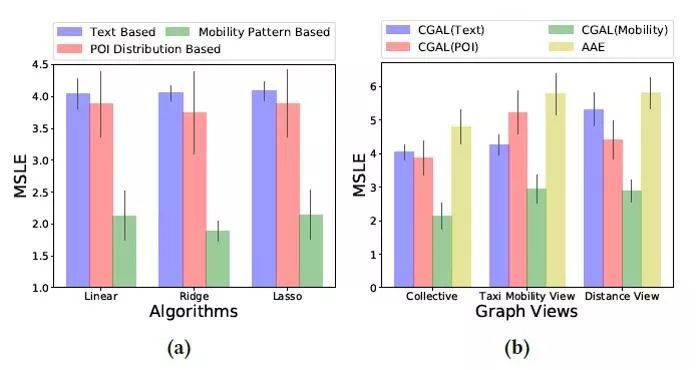 ▲图4.5:使用不同相似指标和不同数量对抗网络的实验效果比较
参考资料
[1] Unifying Inter-region Autocorrelation and Intra-region Structures for Spatial Embedding via Collective Adversarial Learning
[2] Ensemble-Spotting: Ranking Urban Vibrancy via POI Embedding with Multi-view Spatial Graphs
论文原文链接:
http://urban-computing.com/pdf/yunchao.pdf
Deep Uncertainty Quantification: A Machine Learning Approach for Weather Forecasting
作者:Bin Wang, Jie Lu, Zheng Yan, Huaishao Luo, Tianrui Li, Yu Zheng, Guangquan Zhang
天气预报无时无刻不在影响着我们真实世界中的生活和感受。精准的天气预报可为居民出行、粮食储藏、能源预测、产能优化、交通导流、航空航海等诸军民需求提供更精准的天气预报以供于决策支持。
传统的数值天气预报NWP方法受初始化随机性的影响,预报往往存在较大偏差;而完全基于历史数据驱动的机器学习方法则易受数据噪声的干扰。如何针对气象要素复杂性、不确定性进行有效建模和准确预报,成为一个极具挑战性的问题。
解决方案
本文基于序列到序列的深度学习模型,设计了融合多源信息的神经网络模型DUQ,有效融合了NWP、历史观测、气象站和时刻信息;针对气象要素的高度不确定性,设计了具备不确定性量化功能的似然损失函数NLE,用于训练深度学习模型。
▲图4.5:使用不同相似指标和不同数量对抗网络的实验效果比较
参考资料
[1] Unifying Inter-region Autocorrelation and Intra-region Structures for Spatial Embedding via Collective Adversarial Learning
[2] Ensemble-Spotting: Ranking Urban Vibrancy via POI Embedding with Multi-view Spatial Graphs
论文原文链接:
http://urban-computing.com/pdf/yunchao.pdf
Deep Uncertainty Quantification: A Machine Learning Approach for Weather Forecasting
作者:Bin Wang, Jie Lu, Zheng Yan, Huaishao Luo, Tianrui Li, Yu Zheng, Guangquan Zhang
天气预报无时无刻不在影响着我们真实世界中的生活和感受。精准的天气预报可为居民出行、粮食储藏、能源预测、产能优化、交通导流、航空航海等诸军民需求提供更精准的天气预报以供于决策支持。
传统的数值天气预报NWP方法受初始化随机性的影响,预报往往存在较大偏差;而完全基于历史数据驱动的机器学习方法则易受数据噪声的干扰。如何针对气象要素复杂性、不确定性进行有效建模和准确预报,成为一个极具挑战性的问题。
解决方案
本文基于序列到序列的深度学习模型,设计了融合多源信息的神经网络模型DUQ,有效融合了NWP、历史观测、气象站和时刻信息;针对气象要素的高度不确定性,设计了具备不确定性量化功能的似然损失函数NLE,用于训练深度学习模型。
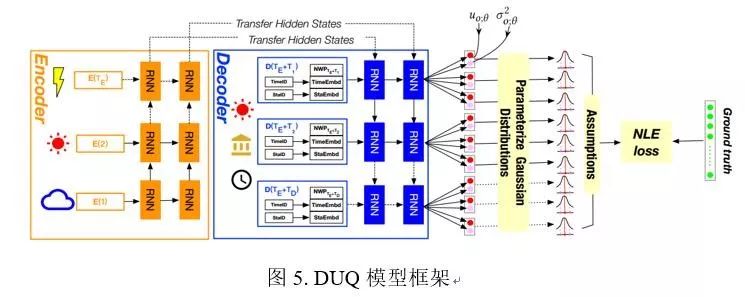 图5. DUQ模型框架
图5. DUQ模型框架
所设计的深度学习方法不仅能够更准确地进行气象要素单值预报,也可以对气象变化范围进行区间预报。连续9天的天气预报实验结果如下表所示,与传统的数值天气预报方法相比,该方法能够降低51.28%的预报误差。
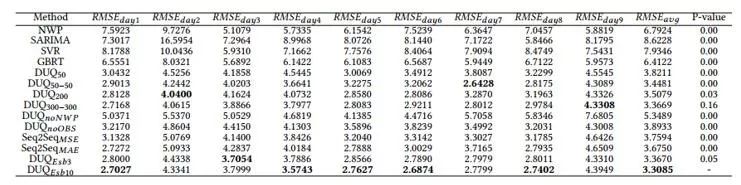 同时,本研究首次汇报了一个重要实验观测:采用所设计的NLE似然损失可以获得比MAE、MSE结合Dropout、L1和L2正则方法更高的泛化精度。该现象在以往研究中从未被提及,值得进一步深入分析和研究。
同时,本研究首次汇报了一个重要实验观测:采用所设计的NLE似然损失可以获得比MAE、MSE结合Dropout、L1和L2正则方法更高的泛化精度。该现象在以往研究中从未被提及,值得进一步深入分析和研究。
论文原文链接: http://urban-computing.com/pdf/kdd19-BinWang.pdf
(*本文为 AI科技大本营转载文章,转载请联系原作者)
社群福利
扫码添加小助手,回复:大会,加入2019 AI开发者大会福利群,每周一、三、五更新技术福利,还有不定期的抽奖活动~

◆
精彩推荐
◆

60+技术大咖与你相约 2019 AI ProCon!大会早鸟票已售罄,优惠票速抢进行中......2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
推荐阅读
通俗易懂:图解10大CNN网络架构
BERT的成功是否依赖于虚假相关的统计线索
AI+DevOps正当时
5天破10亿的哪吒,为啥这么火,Python来分析
5G+AI重新定义生老病死
如何从零开始设计一颗芯片?
在其他国家被揭穿骗子又盯上非洲? 这几个骗子公司可把非洲人民坑苦了…
国内首款 5G 机型开售;Google Chrome 大部分插件无人用;Firefox 69 Beta 9 发布
 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢
最后
以上就是过时蜜粉最近收集整理的关于AI和大数据如何落地智能城市?京东城市这6篇论文必读 | KDD 2019的全部内容,更多相关AI和大数据如何落地智能城市?京东城市这6篇论文必读内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复