如果用于分割,这个任务又可以叫做Cross-view Semantic Segmentation跨视角语义分割,从第一视角的 2D 图像(First-view Observation)得到俯视语义图(Top-down-view Semantic Map)的过程称作跨视角语义分割.如果用于检测,那就是bev感知。
Predicting Semantic Map Representations from Images using Pyramid Occupancy Networks(PON)
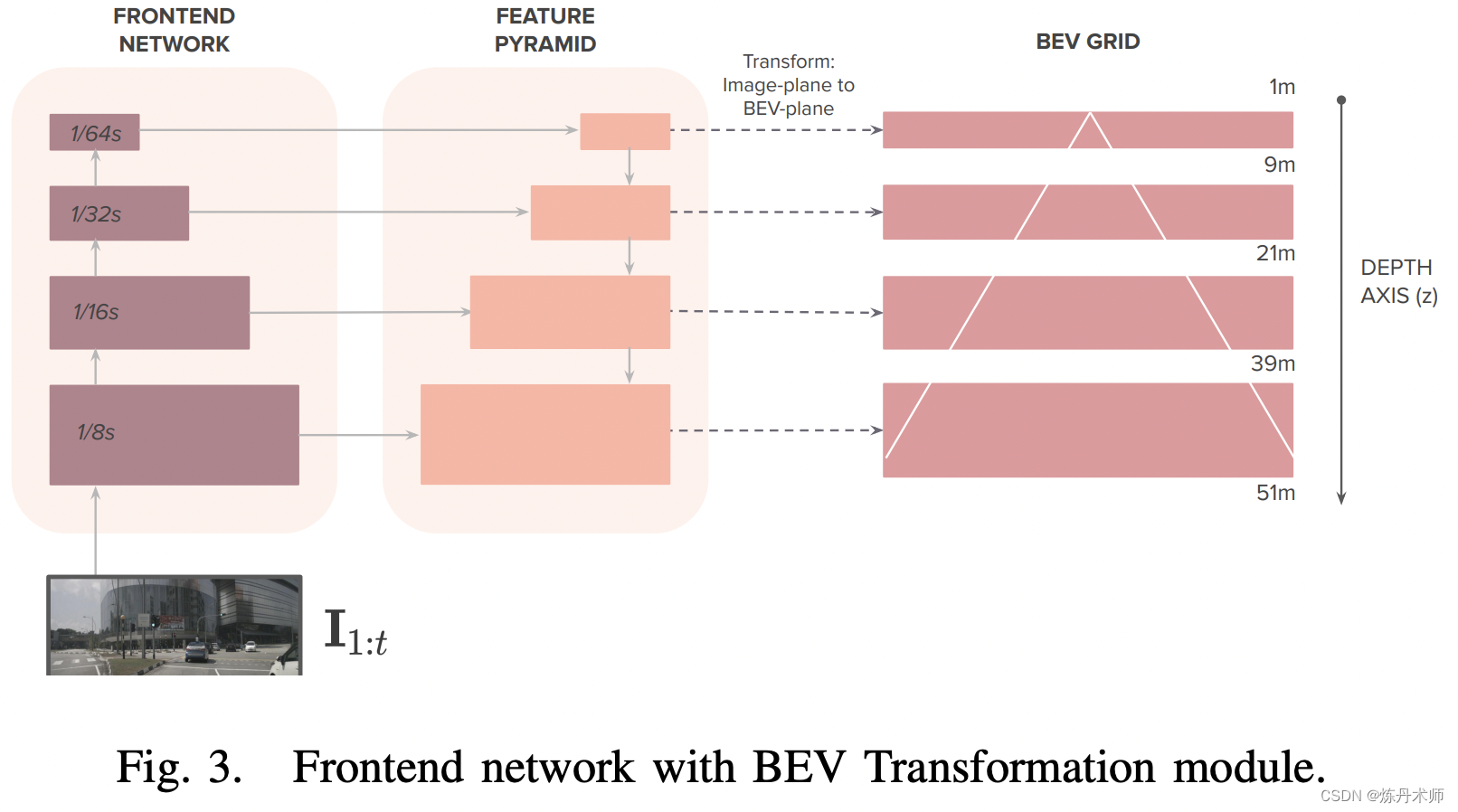
提出了一个dense transformer(并非self attention的transformer, 只是MLP结构)的网络结构用于将2D图转换成BEV
https://githubhelp.com/tom-roddick/mono-semantic-maps
code:https://github.com/tom-roddick/mono-semantic-maps
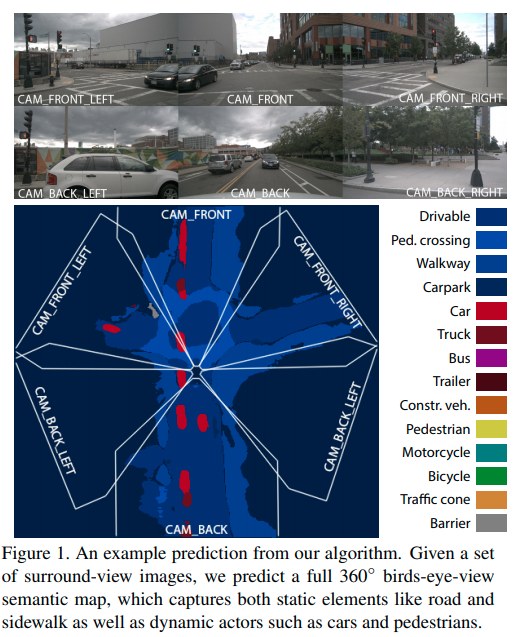
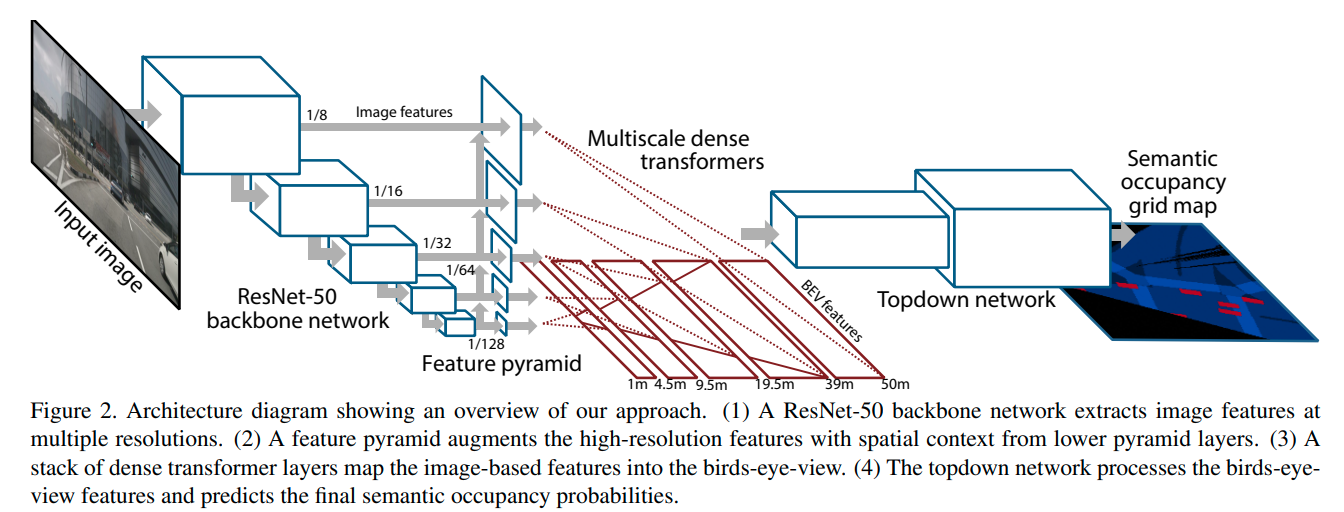
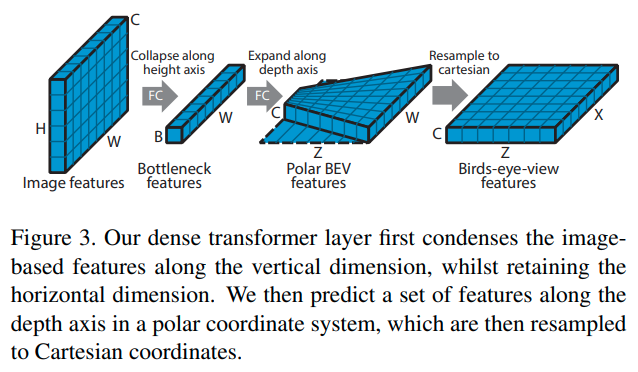
https://githubhelp.com/tom-roddick/mono-semantic-maps
Bird’s-Eye-View Panoptic Segmentation Using Monocular Frontal View Images
用到了上一篇方法中的dense transformer
https://zhuanlan.zhihu.com/p/415109656
项目主页: http://panoptic-bev.cs.uni-freiburg.de/
code:https://github.com/robot-learning-freiburg/PanopticBEV

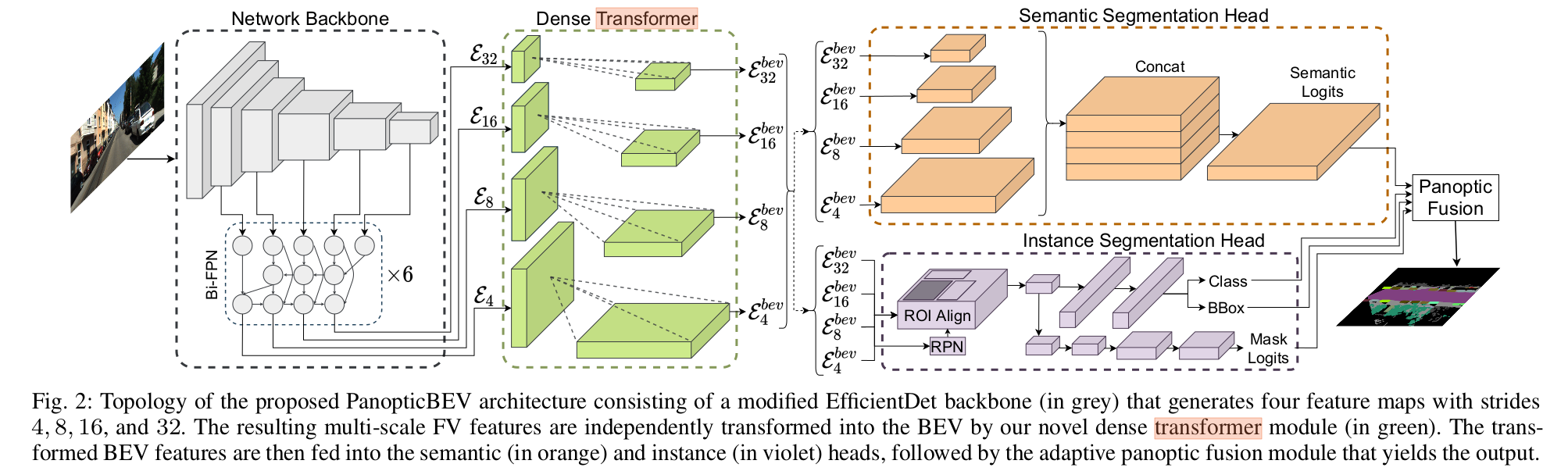
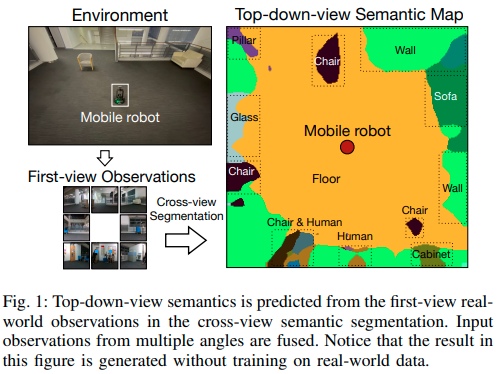
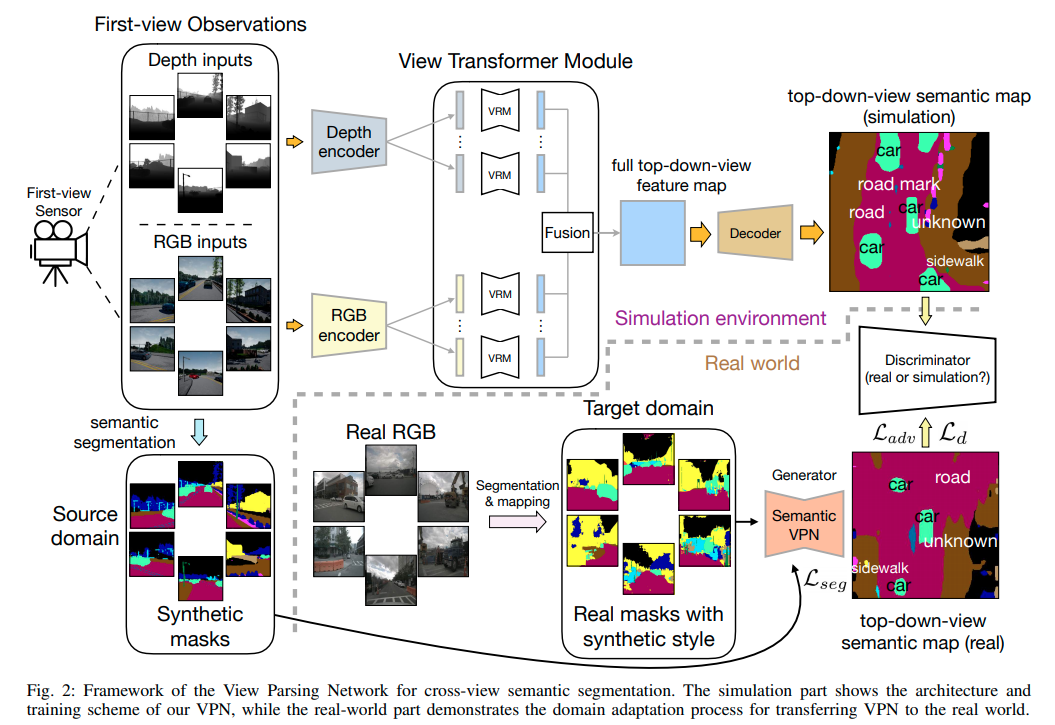
Cross-View Semantic Segmentation for Sensing Surroundings(VPN)
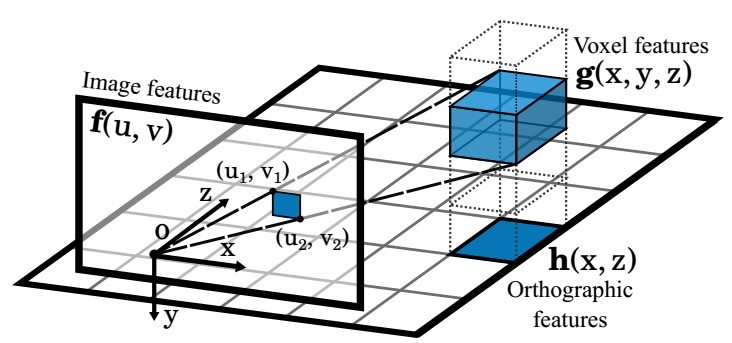
Orthographic Feature Transform for Monocular 3D(OFT)
https://zhuanlan.zhihu.com/p/60117934
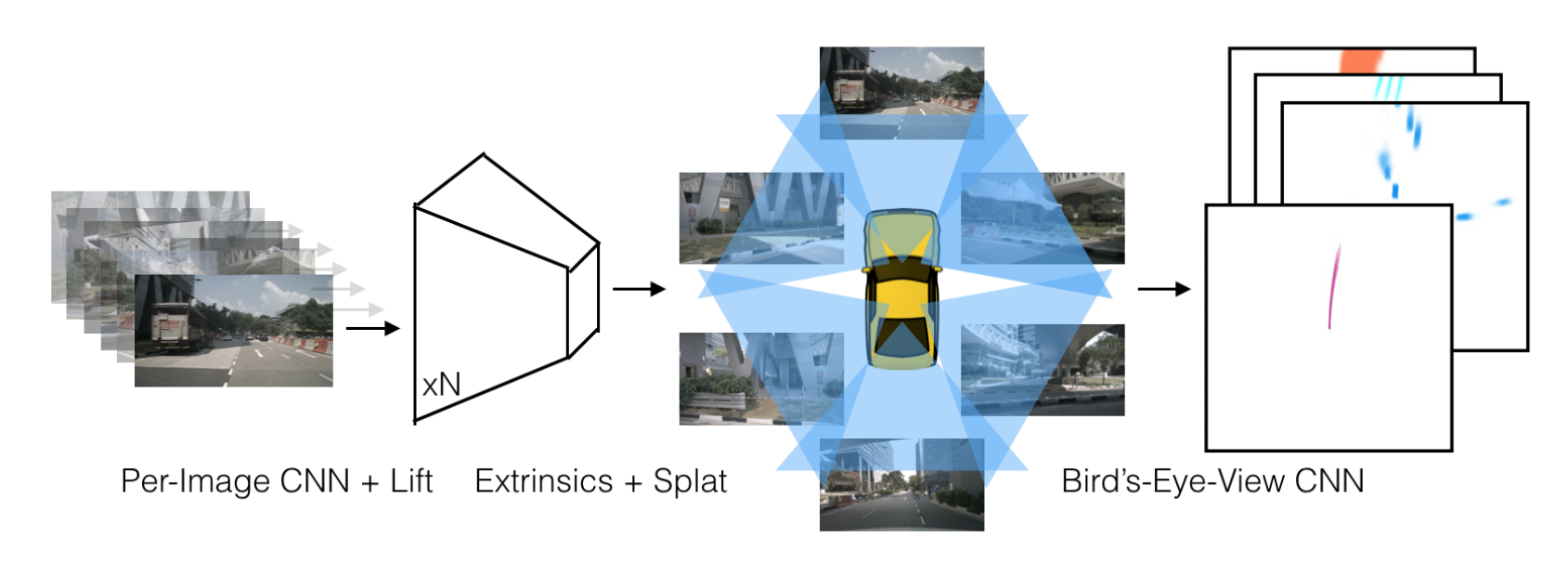
Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
code : https://github.com/nv-tlabs/lift-splat-shoot.git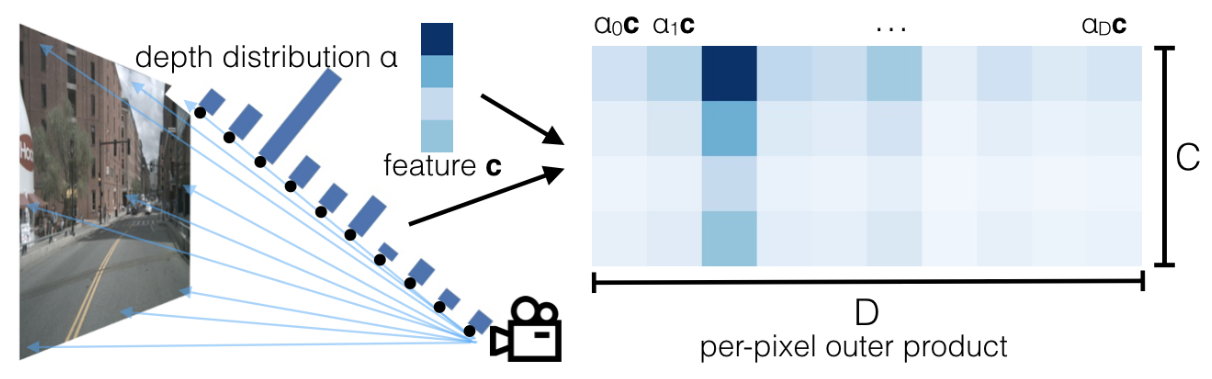
MonoLayout: Amodal Scene Layout from a single image

code:https://github.com/hbutsuak95/monolayout?fileGuid=3X8QJDGGJPXyQgW9
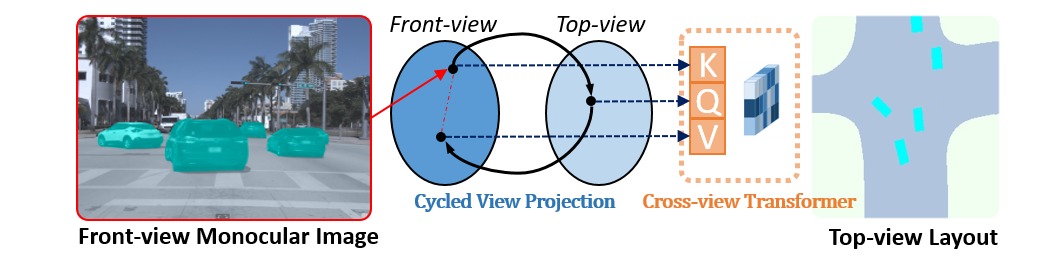
Projecting Your View Attentively: Monocular Road Scene Layout Estimation via Cross-view Transformation
code:https://github.com/JonDoe-297/cross-view
Structured Bird’s-Eye-View Traffic Scene Understanding from Onboard Images
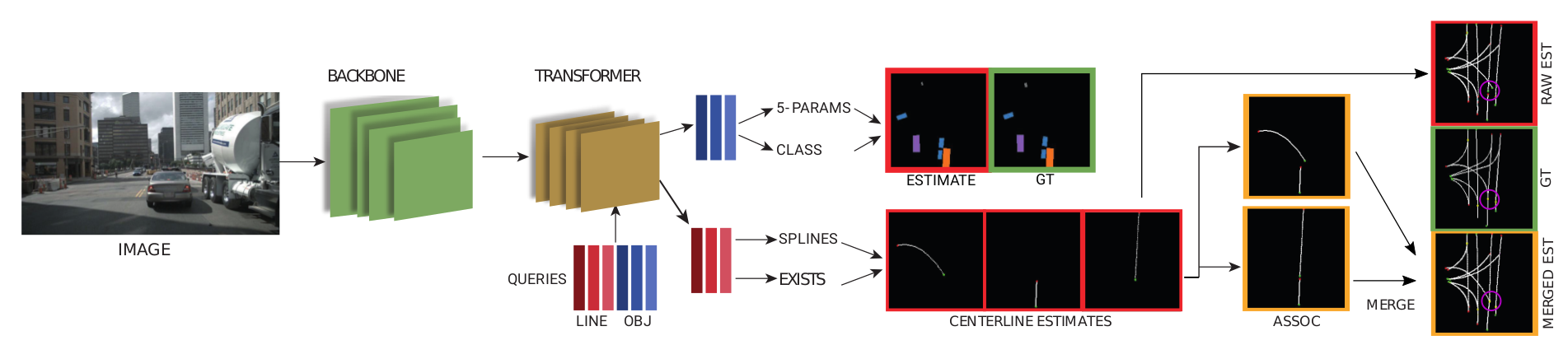
https://github.com/ybarancan/STSU
Translating Images into Maps
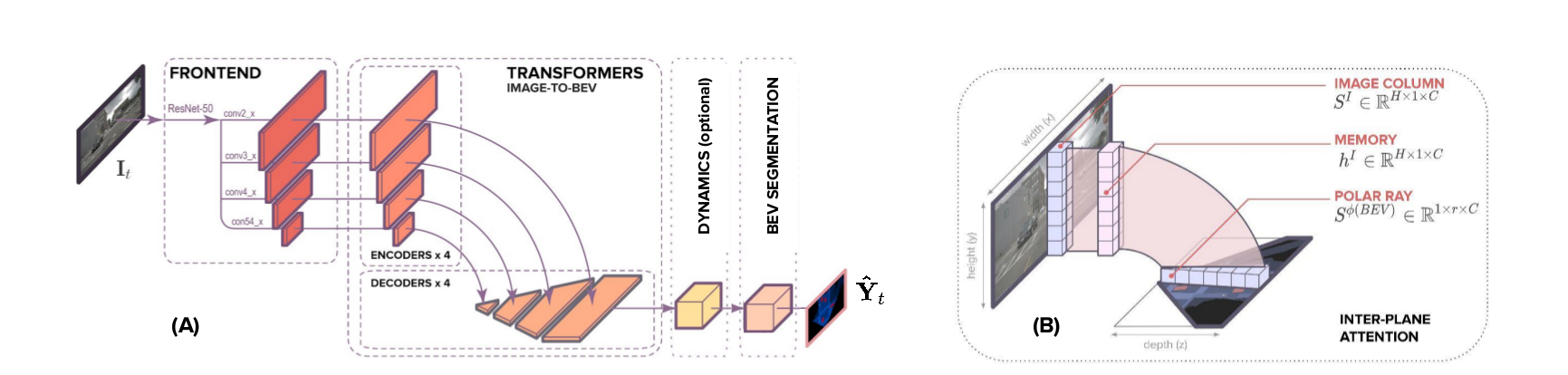
https://github.com/avishkarsaha/translating-images-into-maps
和Predicting Semantic Map Representations from Images using Pyramid Occupancy Networks思想差不多,图像竖直方向有全局深度信息.
Learning to Look around Objects for Top-View Representations of Outdoor Scenes
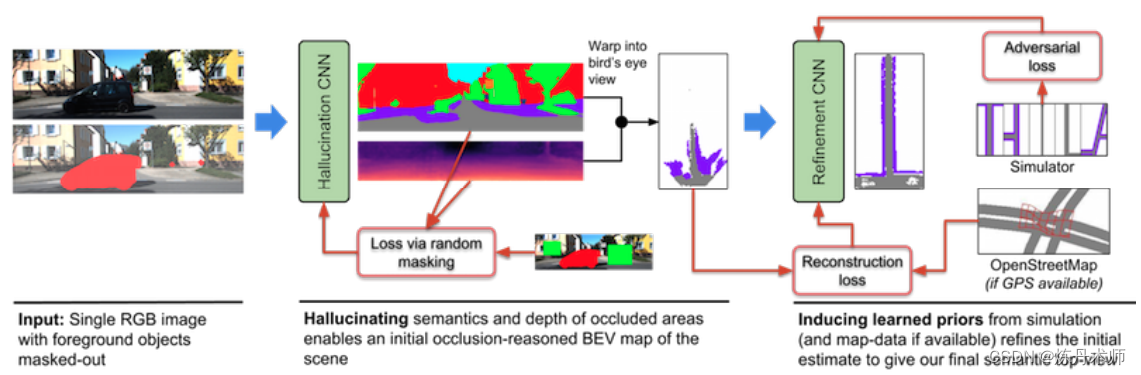
Monocular Semantic Occupancy Grid Mapping with Convolutional Variational Encoder-Decoder Networks

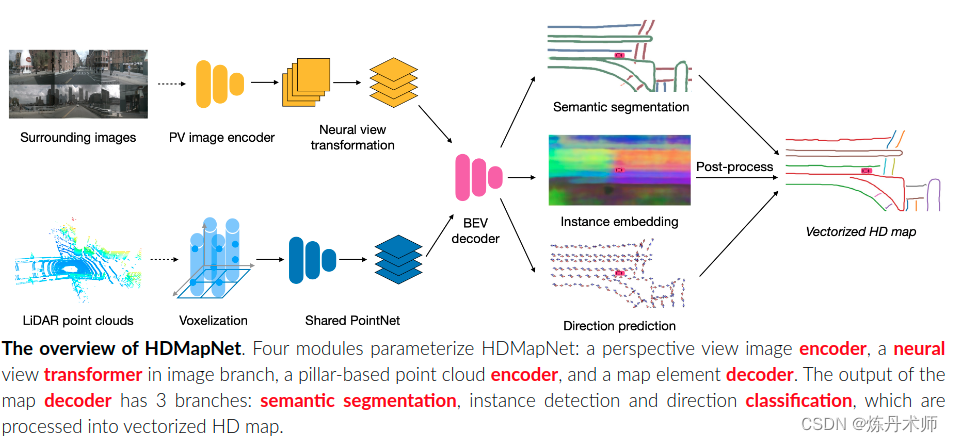
HDMapNet: An Online HD Map Construction and Evaluation Framework
https://zhuanlan.zhihu.com/p/414420432
Cross-view Transformers for real-time Map-view Semantic Segmentation
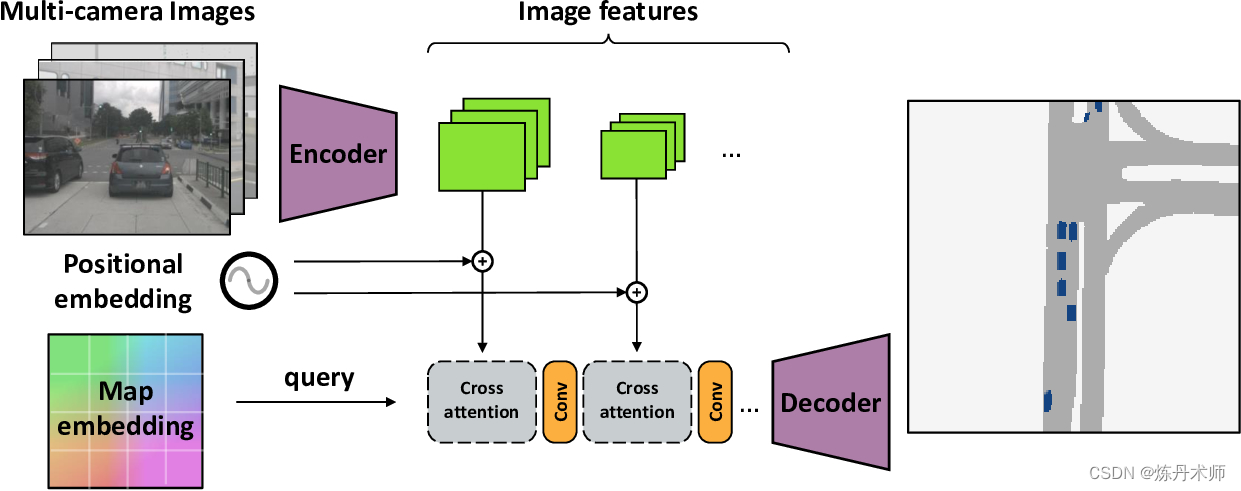
https://github.com/bradyz/cross_view_transformers
Enabling spatio-temporal aggregation in Birds-Eye-View Vehicle Estimation
BEV和Pseudo-Lidar
https://blog.csdn.net/qq_44902479/article/details/125232746
最后
以上就是爱撒娇毛衣最近收集整理的关于图像到BEV转换的全部内容,更多相关图像到BEV转换内容请搜索靠谱客的其他文章。







![[上下文建模系列]Inside-outside net](https://www.shuijiaxian.com/files_image/reation/bcimg12.png)
发表评论 取消回复