
github代码
0. 摘要
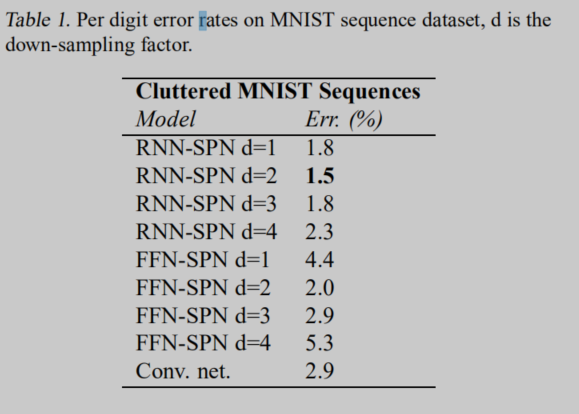
我们将STN与RNN结合,提出了RNN-STN模型,并用该模型进行MNIST手写数字识别。该模型单数字的错误在1.5%,相比之下CNN的错误率在2.9%,STN的错误率为2.0%。 STN能输出放大、旋转和倾斜的输入图像。 我们研究了STN的不同下采样因子(输入和输出像素比),表明RNN-STN模型能够在不恶化性能的情况下对输入图像进行下采样。在RNN-STN中的下采样可以被认为是自适应下采样,以最小化感兴趣区域的信息丢失。 我们将RNN-STN的优越性能归因于它可以处理一系列感兴趣的区域。
1. Intro
前面废话很多,大意就是原有的STN是将整幅图像一起处理,而RNN-STN能依次处理输入图像中的各个数字。
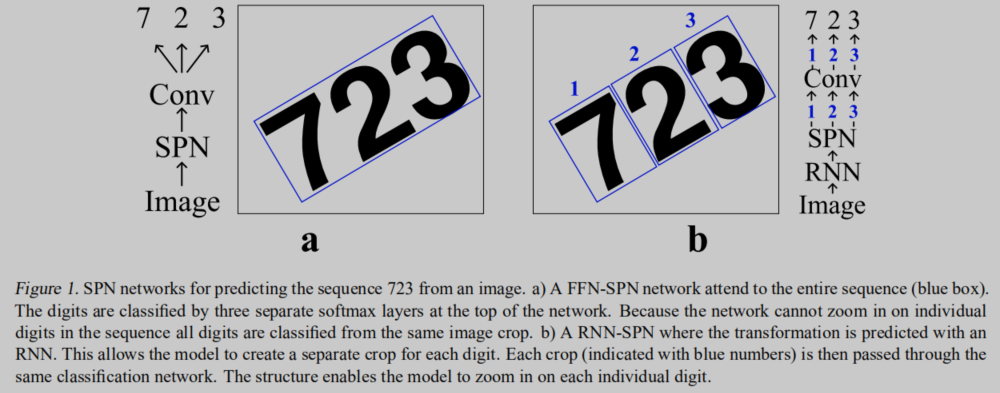
通过运行多个步骤的递归,并调整上一个时间步骤上的每个转换,RNN-SPN模型可以顺序地处理包含每个感兴趣元素的图像部分,并且只使用相关信息进行分类。 由于这些区域通常很小,我们实验迫使RNN-SPN对可以认为是自适应下采样的图像进行下采样,从而保持感兴趣区域的分辨率(几乎)不变。
2. Related Work
Gregor et al. 2015 提出STN
Ba et al. 2014 and Sermanet et al.将可微分模块引入RNN,并用于图像分类
Xu et al., 2015将视觉注意力模型引入encoder-decoder结构
3. Spatial Transformer Network
I
I
I是输入图,shape为
H
×
W
×
C
H times W times C
H×W×C。
localization network
f
l
o
c
f_{loc}
floc预测仿射矩阵。
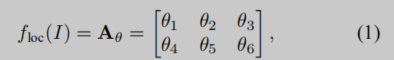
输出grid为
G
∈
R
h
×
w
G in {R^{h times w}}
G∈Rh×w。
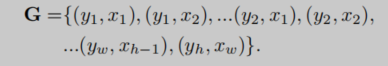
将仿射变换应用于
G
G
G产生一个图像
S
S
S,它告诉如何从
I
I
I中选择点并将它们映射回
G
G
G。
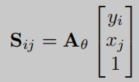
在原图上进行采样就能得到输出。
3.1. Down-sampling
我们可以通过改变h和w来改变采样点的数量。 如果h和w小于H和W,则会将输入降采样到STN。设置一个参数
d
d
d,
d
>
1
d>1
d>1将会进行下采样。在原图上的采样点数为
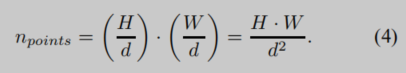
3.2. RNN-SPN
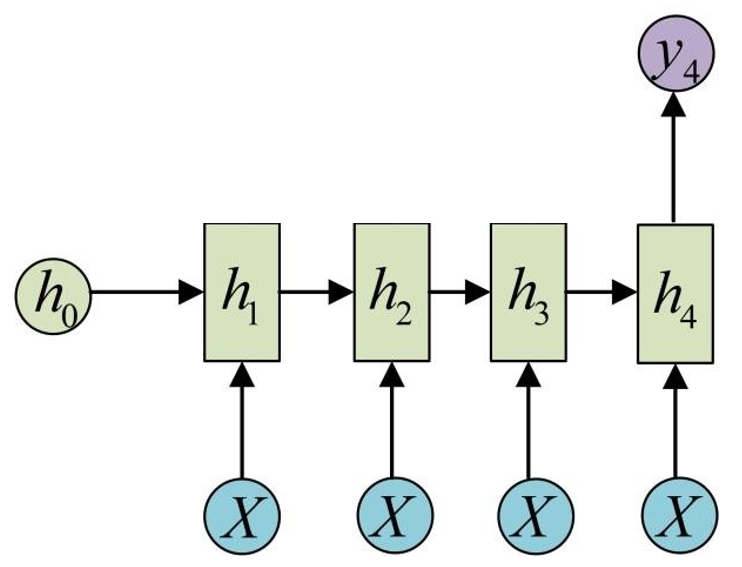
在原来的STN中localization network是前向传播的,我们修改这个模型使之能利用RNN进行预测。RNN的一些常用结构可以参见这个链接。
这里采用的RNN是单输入,且输入不变,单输出的模型。
公式如下:
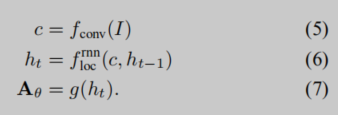
其中
g
g
g是前向传播网络。此处RNN的隐藏状态在每个时间步长上产生仿射变换。
4. Experiments
我们在一个带有噪声的MNIST数字序列数据集上测试模型。 数据集是通过在大小为100×100像素的画布上放置3个随机MNIST数字来创建的。通过在画布上随机采样y位置来放置第一位数字。根据整个序列随机抽样的x位置必须符合画布,并且数字是不重叠的。随后的数字是通过跟踪从±45◦取样的斜率来放置的。最后,通过随机放置8个大小为9×9像素的补丁,从原始的MNIST数字中采样,图像是杂乱的。 对于测试、验证和训练集,我们从原始MNIST数据集中的相应集合中采样。我们创建了60000个用于培训的示例,10000个用于验证,10000个用于测试。 图3显示了生成序列的示例。
作为一个基线模型,我们训练了一个FNN-STN与STN层紧随其后的输入。 分类网络有4层conv-maxpool-dropout层,然后是一个完全连接的层,有400个单元,finally是序列中每个位置的一个单独的softmax层。卷积层有96个滤波器,大小为3×3,整流线性单元用于卷积层和完全连接层的非线性。 为了进行比较,我们进一步训练了一个类似于FFN-STN中使用的分类网络的纯卷积网络。
RNN-STN使用一个门控递归单元(GRU)(Chung等人,2014年),有256个单元。 GRU运行3个时间步骤。 在每个时间步骤中,GRU单元使用 c c c作为输入。 我们应用一个线性层将 h t h_t ht转换为 A θ t A_theta ^t Aθt。 在RNNSPN之后是一个类似于FFN-SPN模型中使用的网络的分类卷积网络,除了卷积层只有32个滤波器。
5. Results
略。

6.结论
我们已经证明,SPN可以与RNN相结合来分类序列。 结合RNN和SPN创建了一个比FFN-SPN更好的分类序列的模型。 RNN-SPN模型能够处理序列中的每个元素,这是FFN-SPN网络无法做到的。 与DRAW网络相比,RNN-SPN模型的主要优点是SPN注意力更快地训练。 与(Mnih等人,2014年)的模型相比,我们的模型是端到端可训练的反向传播。 在这项工作中,我们已经实现了一个简单的RNN-SPN模型,未来的工作包括允许每个数字多次一瞥,并使用当前一瞥作为RNN网络的输入。
最后
以上就是迷人小馒头最近收集整理的关于[论文翻译]Recurrent Spatial Transformer Networks(RNN-STN)的全部内容,更多相关[论文翻译]Recurrent内容请搜索靠谱客的其他文章。
![[上下文建模系列]Inside-outside net](https://www.shuijiaxian.com/files_image/reation/bcimg12.png)



![[论文翻译]Recurrent Spatial Transformer Networks(RNN-STN)](https://www.shuijiaxian.com/files_image/reation/bcimg16.png)



发表评论 取消回复