Abstract
神经网络对语言和视觉的最新见解已经成功地应用于简单的单图像视觉问题回答。然而,为了解决诸如个人照片等多媒体收藏中的现实问题,我们必须用一系列照片或视频来观察整个收藏。当回答来自大量集合的问题时,一个自然的问题是识别支持答案的片段。在本文中,我们描述了一种新的神经网络,称为焦点视觉文本注意网络(FVTA),用于视觉问题回答中的集体推理,其中视觉和文本序列信息,例如图像和文本元数据都被呈现。FVTA引入了一种端到端的方法,该方法利用分层过程来动态地确定在顺序数据中关注什么媒体和什么时间来回答问题。FVTA不仅能很好地回答问题,而且能提供系统结果得到答案所依据的理由。
1. Introduction
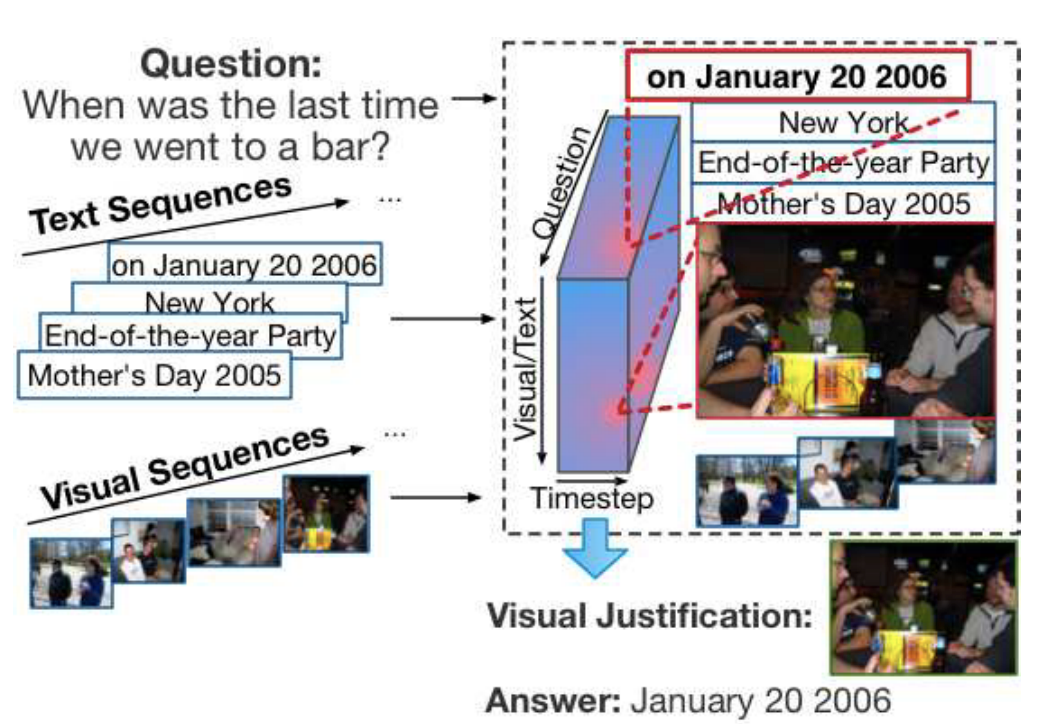
从VQA延伸到单个图像,本文考虑以下问题:假设一个用户的照片和视频按其创建时间的顺序组织。一些照片或视频可能与元标签或注释(如时间、GPS、标题、评论和有意义的标题)相关联。我们有兴趣训练一个模型来回答关于这些图像和文本的问题,例如,“我上次去酒吧是什么时候?”或者“我儿子在2017年万圣节晚宴后做了什么?”
解决上述问题有两个挑战。首先,输入是以非结构化形式提供的。这个问题与视频或图像形式的多个序列相关联。这些序列在时间上是有序的,并且每个序列包含多个时间步长。每次都有可视数据、文本注释和其他元数据。在本文中,我们称之为格式可视文本序列数据。请注意,并不是所有的照片和视频都有注释,这需要一个健壮的方法来利用一致可用的多模式数据。
第二个挑战除了基于序列数据的直接回答之外,还需要可解释的理由。为了给用户提供大量的照片和视频,一个自然的要求是识别支持答案的证据。如图1所示的一个示例问题是“我最后一次去酒吧是什么时候?”从用户的角度来看,一个好的质量保证系统不仅应该给出一个明确的答案(例如,2016年1月20日),还应该提供输入序列中的证据图像或文本片段来证明推理过程。考虑到不完美的VQA模型,人类通常想要验证答案。对于单个图像,检查过程可能是微不足道的,但是检查每个图像和完整的文本单词可能会花费大量的时间。
为了解决这两个挑战,作者提出了一个序列数据的焦点视觉文本注意模型。模型是由人类的推理过程驱动的。为了回答一个问题,人类会首先快速浏览输入,然后关注视觉文本序列中的几个小的时间区域,从而得出答案。事实上,统计数据表明,平均而言,略读后,人类只需要1.5张图片就能回答一个问题。受这一过程的启发,FVTA首先学习将相关信息定位在输入序列的几个小的、时间上连续的区域内,并学习基于从这些区域汇集的跨模态统计推断答案。FVTA提出了一种新的核来计算注意张量,该核联合建模了三个来源中的潜在信息:1)问题中的回答信号词,2)序列中的时间相关性,以及3)文本和图像之间的跨模态交互。FVTA注意允许通过注意核心在几个小的、连续的文本和图像子序列上学习的集体推理。它还可以产生一个证据图像/文本列表来证明推理。如图1所示,突出显示的立方体是所提出的FVTA中的高激活区域。
2. Related Work
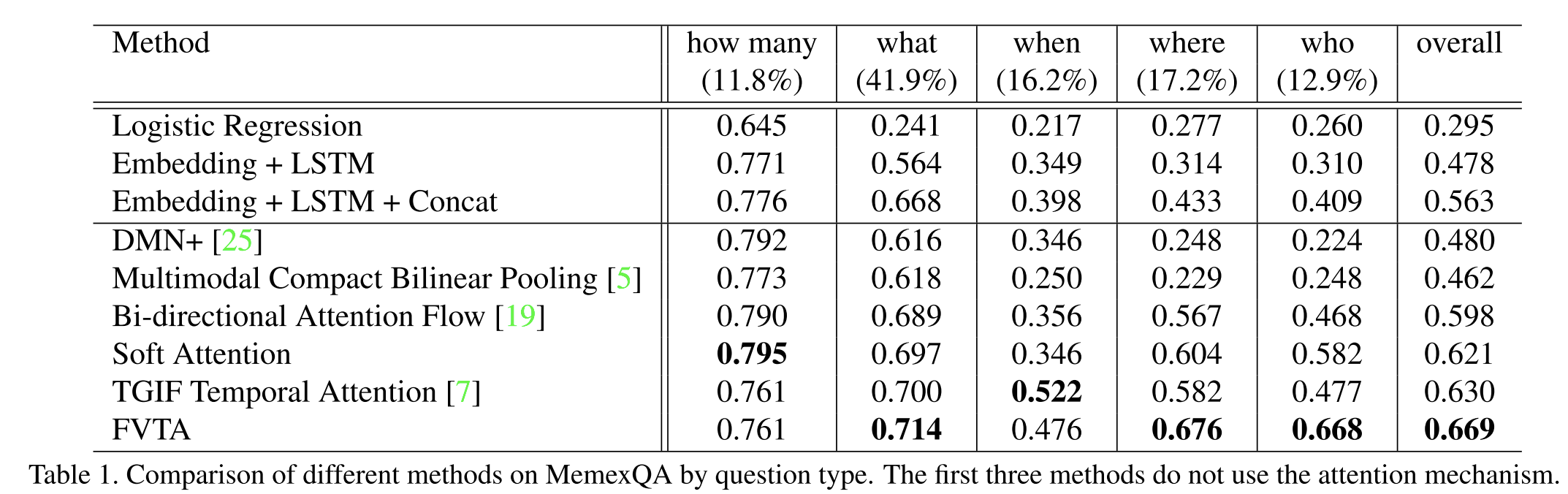
Visual Question Answering由于对基于视频的问答数据集进行标注的成本很高,一些研究通过收集在线视频和描述来生成问答数据集,而最近的一项研究考虑使用动画GIFs来回答问题。这项工作在两个方面不同于现有的基于视频的问答:(1)基于视频的问答是基于单个视频回答问题,而我们的工作可以处理一般的可视文本序列,其中一个用户可能有多个视频或相册。(2)大多数现有的基于视频的质量保证方法将一个带有文本的视频序列映射到一个上下文特征向量中,而这篇文章通过在每个时间步建模查询和序列数据之间的相关性来探索一个更细粒度的模型。为此,我们在MemexQA数据集[9]上进行了实验。MemexQA中的序列数据包含多种形式,包括标题、时间戳、全球定位系统和可视内容,这使得它成为可视文本序列数据质量保证研究的理想测试平台。与[9]中的模型不同,我们的方法还使用答案选项的文本嵌入作为回答问题的输入。
Attention Mechanism.这项工作可以被视为一个新的关注模型,为多个可变长度的顺序输入,不仅考虑到视觉文本信息,还考虑到时间的依赖性。我们的工作扩展了以往的研究使用注意模型的图像质量保证。我们的方法和经典注意模型之间的一个关键区别在于,我们在每个时间步跨多个序列对相关性进行建模。VQA现有的注意力机制主要集中在图像的空间区域内或单个序列内的注意力,因此,可能没有充分利用多序列和多时间步长的性质。模型注意力被应用于三维张量,而经典的软注意力模型被应用于向量或矩阵。
3. Approach
3.1. Problem Formulation
将问题定义为,一共有M个单词,
,每个单词在词汇表中都是一个整数索引。定义的上下文可视文本序列
,
,
代表一个图片,
代表图片对应的文字,文字中第i个单词表示为
,答案是一个数字
,单词表一共有L个单词,给定n个问题,和对应的上下文序列,训练一个模型最大化下列的函数:
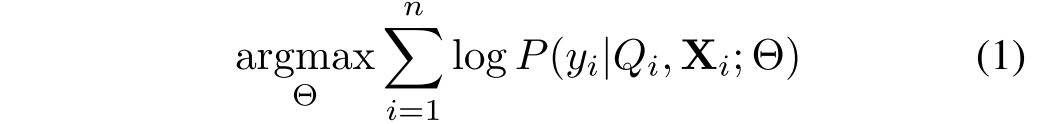
其中代表模型的参数,给出了输入的视文序列
,
,通过注意模型得到了一个良好的联合表示。注意FVTA,该模型分别考虑了图像和文本序列的顺序依赖性和跨模式的视文本相关性。同时,计算出的输入序列上的注意权值可以用来推导出有意义的理由。
3.2. Network Architecture
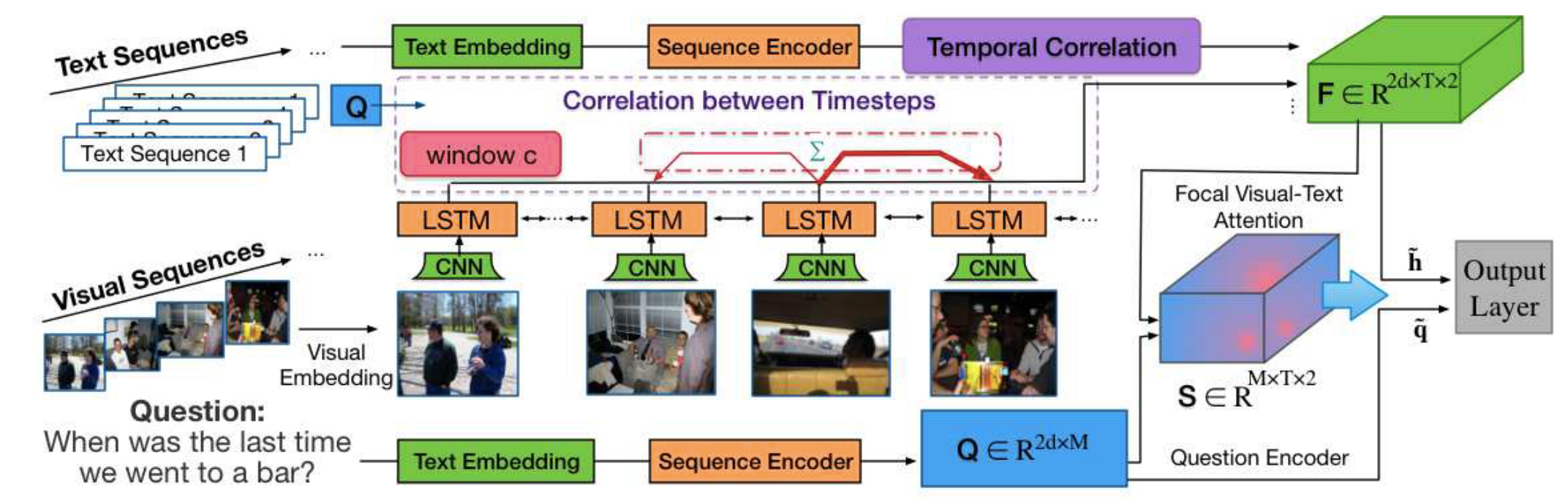
整个模型包括以下层:
Visual-Text Embedding 每个图像或视频帧都用预先训练的卷积神经网络编码。单词级和字符级嵌入都被用来表示文本和问题中的单词。
Sequence Encoder 使用独立的LSTM网络分别对视觉和文本序列进行编码,以捕获每个序列中的时间相关性。LSTM单元的输入是由前一层产生的图像/文本嵌入。LSTM的隐藏单元的数量表示为d。问题Q表示为矩阵,是由双向LSTM每一步的输出连接生成的。M是每个问题最多的单词数。相似的,图片或者文本被表示
,其中T是序列的最大长度。
Focal Visual-Text Attention FVTA是实现所提出的注意机制的一个新层。它表示一个网络层,该层对问题和多维上下文之间的相关性进行建模,并将汇总后的输入输出到最终的输出层,和
。
Output Layer 在使用FVTA注意力总结输入之后,使用前馈层来获得候选答案。对于多项选择题,任务是根据上下文和问题从几个候选选项中选择一个答案。假设k表示候选答案的数量,使用双向LSTM对每个答案选择进行编码,并使用最后一个隐藏状态作为答案的表示,将上下文表示
和问题表示
连接k次,得到新的
和
来计算最后k个答案的概率,在实践中,发现下面的简单公式比完全连接层或直接连接更有效。
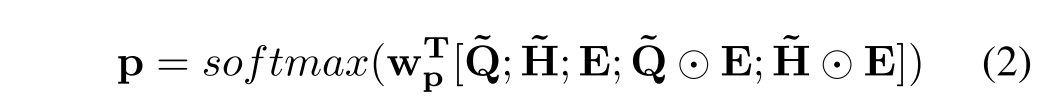
其中,符号[·;·]表示沿最后一个维度的两个矩阵的连接。⊙是元素级的乘法,是要学习的权重向量,p是分类概率的向量。在获得答案概率后,利用交叉熵损失函数对模型进行端到端的训练。
4. Focal Visual-Text Attention
首先介绍了视觉特征和文本特征之间的相似度度量,然后讨论了如何构造同时捕获序列内相关性和序列间相互作用的注意张量。
4.1. Similarity between visual and text features
为了计算不同模态(即视觉和文本)之间的相似性,首先用具有相同隐藏状态大小的LSTM网络对每个模态进行编码。然后测量这些隐藏状态变量之间的差异。采用文本序列匹配的研究,聚集余弦相似性和欧几里德距离来比较特征。此外,我们选择保留向量信息,而不是在运算后求和。向量表示可以用作学习模型的输入,学习模型的内积表示这些特征之间的相似性。更具体地,使用下面的等式来计算两个隐藏状态向量v1和v2之间的相似性表示。结果是一个两倍于隐藏大小的向量
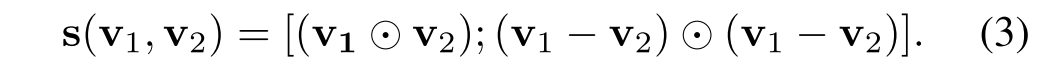
4.2. Intra-sequence temporal dependency
视觉文本关注层设计为让模型根据问题的每个单词选择相关的视觉文本区域或时间步。这种精细的注意力一般来说是不容易学习的。同时,视觉文本序列输入的大多数答案可能在受到约束和限制到一个很短的时间段。学习这种称为焦点语境表征的局部表征,以强调基于问题的相关语境状态。
首先,引入一个时间相关矩阵,一个对称矩阵,其中每个元素
测量上下文的第i步和第j步之间的相关性,
表示H中的第i个时间步的可视化/文本表示,为了表示方便,:是一个切片操作符,用于从某一维度中提取所有元素。例如,
表示视觉序列的第i个时间步的向量表示。这里我们表示最后一个索引1表示视觉的,第二个表示文本的形式。每个条目
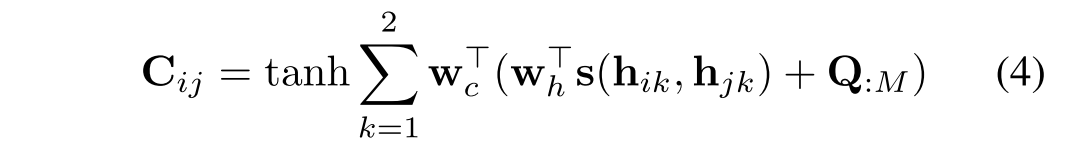
其中 ,
是模型的参数。时间相关矩阵捕获问题、图像和文本序列的时间依赖关系。
为了允许模型基于问题捕获时间步骤之间的上下文,我们引入时间信息池来连接相邻的时间隐藏状态,如果它们与问题相关的话。例如,它可以捕捉“晚餐”时刻和“去跳舞”时刻之间的相关性,给出的问题是“在本的生日晚餐后我们做了什么?”。形式上,给定时间相关矩阵C和上下文表示H,我们引入一个时间聚焦池函数g来获得聚焦表示,每个向量条目
,
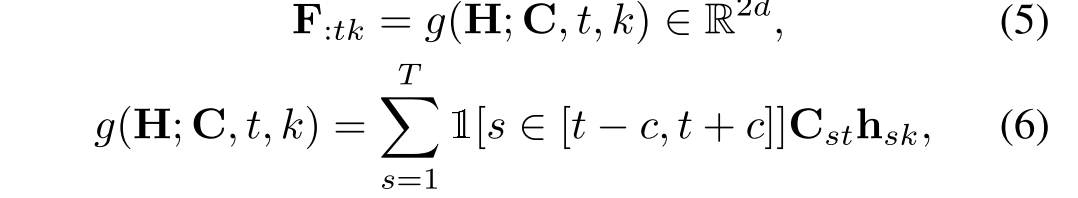
其中 是表示第t步时视觉(k = 1)或文本(k = 2)的焦点上下文。1是指标函数。c表示时间窗口的大小)这是端到端的学习与其他参数。我们将模型限制在几个可学习窗口大小为2c + 1的小时间上下文窗口上。
4.3. Cross Sequence Interaction
引入注意机制来捕捉视觉序列和文本序列之间的重要关联。我们将注意力集中在焦点语境表征上,以总结回答问题的重要信息。我们基于问题的每个单词和可视文本序列的每个时间步之间的相关张量获得注意力权重。每个时间步的注意力只考虑上下文和问题,不依赖于前一个时间步的注意力。使用这种无记忆注意力机制的直觉是,它简化了注意力,让模型专注于学习上下文和问题之间的相关性。这种机制已经被证明在回答文本问题中是有用的。首先在输入问题与焦点上下文表示F之间计算一个内核张量,其中内核
中的每个条目对所讨论的第m个单词和第t个时间步长上的模态k(图像或文本单词)之间的相关性进行建模。让
表示
在第t步时对于视觉或文本的焦点上下文表示。S中的每个条目
的计算方法如下
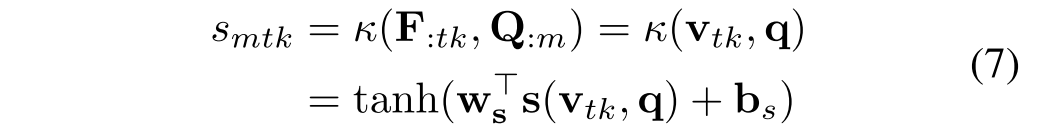
κ是一个函数来计算和上下文和问题之间的关系,是需要学习的参数,
是偏置。s是相似性函数,使用这样的相似性表示,因为他们捕获了余弦相似度和欧几里得距离信息。得到了图文序列注意矩阵
,
,矢量图形文字的关注
,
。其中softmax操作应用于第一个维度。利用最大函数
对高维张量的第一维进行约简。
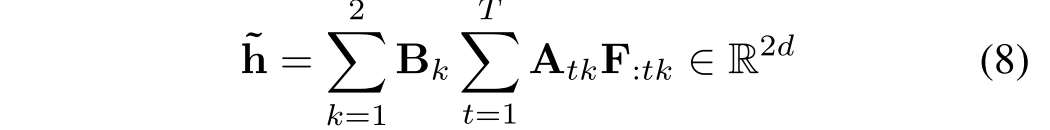
视觉文本注意是基于问题和焦点上下文注意之间的相关性来计算的,这与我们的观察一致,即问题通常为答案提供有限时间窗口的约束。同样,我们计算问题注意力 ,
,总结的问题向量由下式给出:
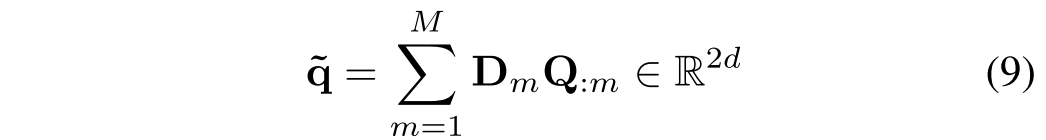
算法1总结了计算建议的FVTA注意力的步骤。为了获得最终的上下文表示,首先分别为视觉序列和文本序列总结焦点上下文表示,使用序列内注意强调最重要的信息。然后,根据序列间的重要性对序列向量表示进行求和,得到最终的表示。图3示出了FVT注意张量和一维软注意向量之间的差异。这两种机制都计算注意力,但FVTA同时考虑了视觉文本序列内相关性和跨序列交互作用。



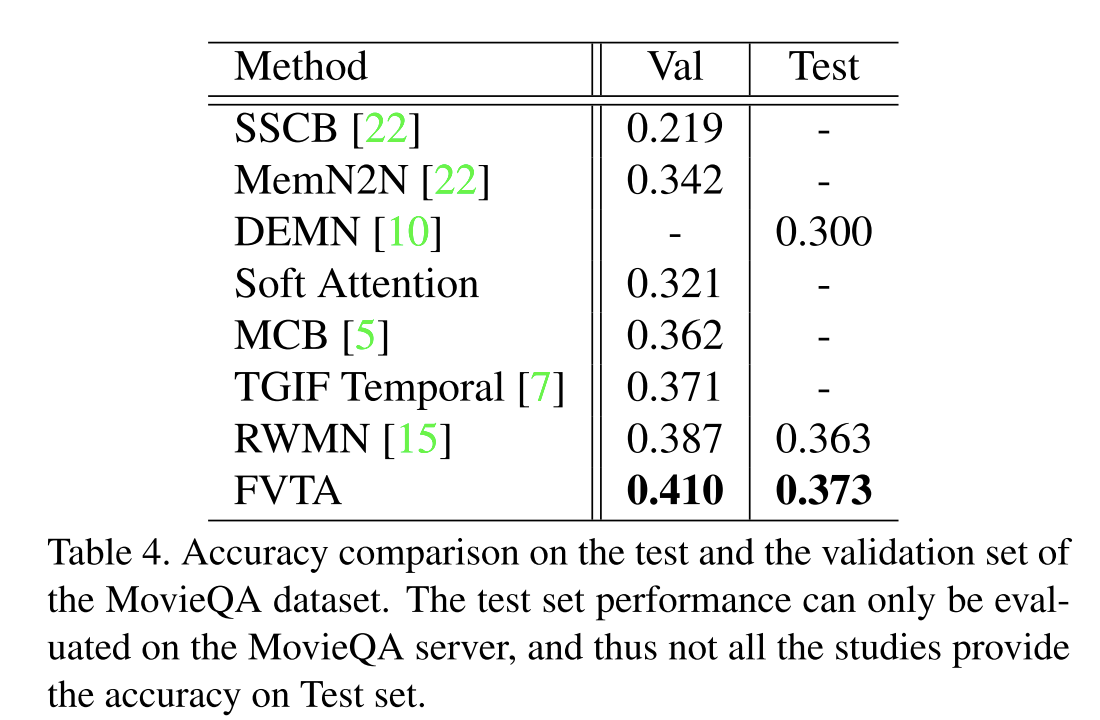


最后
以上就是痴情毛巾最近收集整理的关于Focal Visual-Text Attention for Visual Question Answering论文笔记Abstract1. Introduction 2. Related Work3. Approach4. Focal Visual-Text Attention的全部内容,更多相关Focal内容请搜索靠谱客的其他文章。








发表评论 取消回复