交流群 | 进“传感器群/滑板底盘群”请加微信号:xsh041388
交流群 | 进“汽车基础软件群”请加微信号:ckc1087
备注信息:群名称 + 真实姓名、公司、岗位
接下来,我们将陆续发布5篇仿真主题的文章。严格意义上说,这是笔者的一系列学习笔记。
对自动驾驶仿真中的很多知识点(排名第一的就是“用真实道路数据做仿真”),笔者已经好奇了两年多时间,但此前一直没有机会学习。今年4月份的疫情期间,偶尔得到了一次跟某仿真公司创始人闲聊的机会,笔者便趁机向其请教了许多问题。
此后,为交叉验证,笔者又陆陆续续向近20位在自动驾驶仿真业务一线的专家请教。
对本系列学习笔记提供支持的专家包括但不限于智行众维CEO安宏伟、深信科创创始人杨子江、智行众维CTO李月、51 World CTO 鲍世强及毫末智行和轻舟智航、车右智能的仿真专家等。在此表示感谢。
一.场景来源——从合成数据到真实道路数据
据公众号“车路慢慢”的作者李慢慢及智行众维CTO李月介绍,仿真测试场景的来源,大体上可以有2种思路:
第一种思路是由德国PEGASUS项目提出的功能场景-逻辑场景-具体场景三层体系:1)、通过真实道路数据采集和理论分析等方式,得到不同的场景类型(即功能场景);2)、再分析出这些不同场景类型中的关键参数,并通过真实数据统计和理论分析等方法得到这些关键参数的分布范围(即逻辑场景);3)、最后选取其中一组参数的取值作为一个测试场景(即具体场景)。
如下图所示:
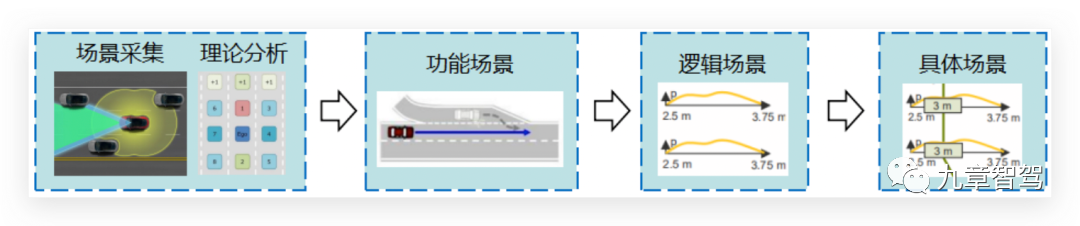
举个例子,功能场景可以描述为,“自车(被测车)在当前车道运行,在自车前方有前车加速运行,自车跟随前车行驶。” 逻辑场景则提炼出关键场景参数,并赋予场景参数特定的取值范围,如以上描述的场景可提取自车车速、前车车速以及加速度、自车与前车距离等参数,每个参数都有一定的取值范围和分布特性,参数之间可能还存在相关性。具体场景则需要选取特定的场景参数值,组成场景参数向量,并通过具体的场景语言表示。
这其实就是通常所说的“虚拟搭建/用算法生成的场景”,尽管对场景的理解仍来自于真实道路场景,但实践中更多地是基于这种理解在软件里面“人为地拟定”一个行驶轨迹、一组场景,因而,这种场景背后的数据也被称为“合成数据”。
在实操中,这种思路面临的主要挑战是,仿真工程师对车辆的正常驾驶场景的理解是否足够深。如果工程师不理解场景,任性地去“拟定”出一个场景,那当然是不能用的。
第二种思路是:采集自动驾驶车辆预定工作区域内的交通流量数据,并将这些数据输入交通仿真工具中产生交通流,并使用该交通流充当自动驾驶车辆的“周围交通车辆”,实现测试场景的自动生成。
据深信科创创始人杨子江介绍,为确保能获得比较准确的“真值”,通常,工程采集车上的传感器配置要比普通的自动驾驶汽车高许多,如定位系统会采用20W以上的设备以及高线束的激光雷达,产生的数据会更加精确。
UberACT前首席科学家Raquel Urtasun创办的仿真公司Waabi,据说无需激光雷达等高精度的传感器,直接用摄像头收集的数据来做仿真。
用真实道路数据做仿真,最大的优势是,场景的多样性不会受限于工程师对场景的理解不足,因而,更容易将那些“谁也想不到”的未知场景给“打捞”出来。
此外,某自动驾驶公司仿真负责人说:为了提高仿真的真实度,后面大家就会尽可能地少采用合成数据,多采用真实道路数据。实际上现在的仿真已经在往这个方向发展了——真实数据和模块越来越多了。
不过,有一线仿真实践的工程师们普遍反映,这一思路过于理想化。具体地说,用真实道路数据做仿真,存在如下几点局限性——
1.数据需要做人工校核
实际上,传感器采集到的数据并不能直接用于仿真——数据类型及格式需要转换,有很多无效数据需要清洗,也要从中辨别出有效的场景,某些特定的要素需要进行标注,不同传感器之间的数据需要实时同步和融合等等。
正常情况下,自动驾驶车辆的感知数据无需经过人工校核,而是直接给到决策算法,但如果是做仿真,对感知数据的人工校核就是必不可少的步骤。
2. 逆向过程的实现难度比正向过程大
某无人驾驶卡车公司仿真工程师说:用合成数据做仿真,是一个正向的过程,即你先知道自己需要去做哪些测试,然后再自己主动去设计这样一个场景;用真实数据做仿真是一个逆向的过程,即你先遇到一个问题,然后再去解决这个问题。两者相比较,后者的难度要大得多。
3.无法解决交互问题
复睿微电子负责人Jame Zhang在一次公开分享中提到,WorldSim(用虚拟数据做仿真)像在玩游戏,而LogoSim(用真实道路数据做仿真)则更像是电影,你只能看,没法参与,因此,LogoSim天然没法解决交互性的问题。
4.无法做闭环
复睿微电子负责人Jame Zhang还提到了这两种仿真方法的另一个区别:使用真实道路数据做回放,能采集的片段永远是有限的,经常是,采集开始的时候,危险可能已经发生了一段时间了,之前的数据你很难获得了,但如果用虚拟数据(合成数据),就无需面对这个问题。
某主机厂的仿真负责人说:“上述专家表述的是采集的过程。的确,考虑到采集设备的容量以及有效场景的定义,采集打点的场景都是有长度的,一般都是功能触发前后一段时间,尤其是触发前的缓存不会特别长。另一方面,在数据采集后用来回灌的时候,则只能是功能触发前的场景是有效的,而功能触发后的真实场景却是无效的。”
这位主机厂的专家说:真实道路数据用来训练感知算法是可以的,但要测试整个算法链路的话,还是得依赖合成场景数据。
不过,这位主机厂的仿真主管最后也强调:“所谓的‘没法实现闭环’也是相对的,已经有供应商可以把采集到的场景里面的元素都完成参数化,这样就可以闭环了,但这种设备的价格是非常昂贵的。”
5.数据的真实度仍然难以保障
用真实交通流数据做仿真,也被称为“回灌”。
据深信科创创始人杨子江介绍,“回灌”需要用到核心技术有两个:一个是在仿真环境中还原路采数据的路网结构,二是将路采数据中的动态交通参与者(行人,车辆等)在不同坐标系下的位姿信息映射到仿真世界路网下的全局坐标系中。
这个过程中需要使用的工具有SUMO或openScenario——用于读入交通参与者的位点信息。
某主机厂仿真专家说:“原始数据的回灌也不能保证百分之百真实,因为在将原始数据注入仿真平台后,还得加上车辆动力学仿真。但如此一来,场景是否还与真实道路上的场景一致,就不好说了。”
究其原因,现有的交通流仿真软件往往还存在如下几大缺陷:
生成的交通流不够保真,往往只支持车辆轨迹导入,而车辆间的双向交互不够真实;
仿真模块(自车)和交通流模块(其他道路参与者)之间的数据传输接口受限(如路网格式不同,需要路网匹配),第三方可操作性有限;
基于规则的交通流模型是面向交通效率评价的,可能会出现过于简化的问题(往往采用一维模型,假设设立是沿着中心线行驶的,较少考虑横向影响),难以满足交互安全评价的需求。
某Tier 1的仿真工程师说,用真实交通流数据生成仿真场景,如何选择交通流模型(比如跟驰模型、换道模型怎么定义)、如何定义交通流仿真模块接口都是有相当难度的。同时,来自自车的数据和其他道路使用者的数据如何做好时间同步,也会是一个很大的问题。
6.数据的通用程度低、泛化难度大
智行众维CEO安宏伟和CTO李月都特别提到了仿真数据的“通用性”问题。所谓数据通用性,即指车辆及场景的参数是可以调整的。比如,在数据是用一辆轿车去采集的,摄像头的视角很低,但在变成仿真场景之后,摄像头的的视角可以调高,这组数据可以用于卡车模型的测试。
如果场景是虚拟搭建/算法生成的,各参数可根据需要任意调整;那么,如果场景是基于真实道路数据的呢?
某工具链公司的仿真负责人说,在用真实道路数据做仿真的情况下,一旦传感器的位置或者型号有变更,这一组数据的价值就降低,甚至会“作废”。
轻舟智航的仿真专家说,也可以用神经网络对真实道路数据做调参,这种调参的智能化程度会更高一些,但可控性会比较弱。
用真实交通流数据做仿真,又称为“回灌”,而回灌又可分两种,直接回灌和模型回灌——
所谓“直接回灌”,是指对传感器数据不做处理直接喂给算法,在这种模式下,车辆及场景的参数是不可调整的,用某款车型采的数据,就只能用于同款车型的仿真测试;
“模型回灌”,则是指先将场景数据抽象化、模型化,用一组数学公式将其表达出来,在这个数学公式里面,车辆及场景的参数都是可调的。
按李月的说法,直接回灌是无需用到数学模型的,“比较简单,基本上,只要有大数据能力都能做到”,但在他们的模型回灌方案中,不管是传感器模型还是车辆的行驶轨迹、车速,都是要通过数学公式来完成的。
模型回灌的技术门槛很高,成本也不低, 一位仿真工程师说:“要把传感器录制的数据转换成仿真数据,数据解析的过程非常难。因此,当前,这一技术主要停留在PR层面上。在实践中,各家的仿真测试都是以算法生成的场景为主,以采自真实道路集的场景为补充。”
某自动驾驶公司仿真负责人说:用真实交通流的数据做仿真,目前还是很前沿的技术,这些数据的调参难度很大(仅可在一个很小的范围内调参)。因为路采的都是一堆日志、一条条的记录,它记录的是这个车第一秒第二秒怎么运行的,而不像人工编辑的一些场景是由一系列的公式组成的。
这位仿真专家说,模型回灌存在的最大挑战是:在场景比较复杂的情况下,要将场景用公式表达的难度极高,这个过程是可以通过自动化的方式来实现的,但最终做出来的场景能不能用也是个问题。
Waymo在2020年公布了的“通过将传感器收集到的数据直接生成逼真的图像信息来做仿真”的ChauffeurNet,其实就是在云端用神经网络将原始道路数据转换成数学模型,然后做模型回灌。但一位在硅谷多年的仿真专家说,这个还停留在试验阶段,距离成为真正的产品还有一段时间。
这位仿真专家说,比回灌更有意义的是引入机器学习或强化学习。具体地说,仿真系统在充分学习各类交通参与者行为习惯的基础上训练出一些自己的逻辑,并将这些逻辑公式化,然后,在这些公式中调参。
不过,智行众维CTO李月和副总经理冯宗磊的说法是,他们目前已经能够实现模型回灌了。
冯宗磊认为,一个仿真公司是否具备做模型回灌的能力,这主要取决于他们所使用的工具及场景管理能力。
“场景管理中,切片是非常重要的一环——不是所有的数据都是有效的,比如,1小时的数据中,真正有效的可能只有不到5分钟,在做场景管理的时候,仿真公司需要将有效的部分切出来,这个过程便被称为‘切片’。
“切片完成后,仿真公司还需做一个相应的带语义信息的管理环境(比如哪个是行人、哪个是十字路口),方便下次去筛选。具体地说,需要先对数据切片做分类,然后再做动态目标列表的精修,精修完之后再导入到仿真环境的模型里去,如此一来,模型就有相应的语义信息了。有了语义信息,就可以调参了,然后,数据就可以复用了。
“多数公司基于真实交通流的数据之所以不能调参,是因为他们没有做好场景管理。”
深信科创创始人杨子江说:“如果要将路采数据泛化,并且要保持数据的真实性,可以在场景初始化以及开始阶段回放路采数据,在某一时刻由smart-npc模型来接管道路中的背景车辆,使背景车辆不会按照路采数据运行。smart-npc接管后通过把泛化后的场景记录下来,以做到泛化后的关键场景可回放。”
某主机厂的仿真工程师认为,模型回灌尽管听上去“不明觉厉”,但实际上“必要性不大”。原因是:将数据模型化与回灌的初衷不符——回灌的初衷是想要真实的数据,但既然模型化了,参数可调了,就不是最真实的了;费时费力,数据格式转换非常麻烦,费力不讨好。
这位工程师说:“既然你想要更多场景,那直接用仿真器大规模生成泛化场景就行了啊,大可不必走真实数据模型化这条路。”
对此,冯宗磊的回应是:
“用算法直接生成场景,这在开发的早期当然是没问题的,但局限性也很明显——那些工程师们‘想不到’的场景怎么办?真实的交通状况千变万化,你的想象力不可能穷举所有。
“更关键的是,在工程师想象出的场景中,目标物之间的交互关系往往是不自然的。比如前方有车辆插入,它是以多大的角度插入?在距离你10米时还是5米时插入?在用算法生成场景的实践中,场景参数的制定往往带有非常的大主观性、随意性,工程师拍脑袋想出了一组参数注入模型,但这组参数是否具有代表性呢?”
冯宗磊认为,在无人驾驶还处于Demo阶段时,靠算法生成的虚拟场景能满足需求,但在前装量产时代,基于大规模的自然驾驶数据(真实交通流数据)来做场景泛化,还是很有必要的。
据一位跟Momenta有过接触的人士说:“Momenta已经具备了用真实道路数据做场景泛化(调参)的能力,但他们的技术只给自己用,不对外。”
51 World车载仿真负责人鲍世强,认为,自然驾驶数据做泛化目前还比较前瞻,但未来肯定会成为很重要的方向,因此,他们也在探索。
总结:两种路线相互渗透,界限越来越模糊
复睿微仿真负责人James Zhang在前段时间的一段分享中提到,特斯拉的仿真有两种方法:场景完全虚拟(算法生成)的叫 WorldSim,将真实数据回放给算法看的叫LogSim,“但WorldSim中的路网也是在对来自真实道路的数据做自动标准的基础上生成的,因此,WorldSim与LogSim的界限越来越模糊”。
轻舟智航的仿真专家说:“真实场景数据转化为标准格式化数据后,可通过规则去进行赴泛化,从而产生更有价值的仿真场景。”
51 World 车载仿真业务负责人鲍世强也认为,未来的趋势是,用真实道路数据做仿真和用算法生成的数据做仿真这两种路线会相互渗透。
鲍世强说:“一方面,用算法生成场景,也依赖于工程师对真实道路场景的理解,对真实场景的理解越透彻,建模就越能接近真实。另一方面,用真实道路数据做场景,也需要对数据做切片、提取(将有效部分筛选出来),再设定参数、触发规则,再做精细化的分类,然后可以将它们逻辑化、公式化。”
二.场景泛化与场景提取
上面几段反复提到的对场景数据做“调参”,又被称为“场景泛化”——通常主要指对虚拟搭建的场景做泛化。用某主机厂系统工程师的话说,场景泛化的优势是,我们可以“凭空造”一些现实世界当中从来都没有过的场景。
一个仿真公司的场景泛化能力越强,对某个场景调参后得到的可用场景的数量就越多,因此,场景泛化能力也是仿真公司的一项关键竞争力。
不过,轻舟智航的算法专家说,场景泛化可以通过数学模型、机器学习等方法去实现,但关键的问题是如何保证泛化的场景是真实、而且更加有价值。
决定一个公司的场景泛化能力强或者弱的关键要素有哪些?
深信科创创始人杨子江认为,场景泛化中有一个很大的难点是,如何将轨迹抽象为更高级别的语义,用一形式化的描述语言来表达。
某Tier 1仿真工程师说:主要看该公司所采用的仿真工具是用什么语言(比如openscenario)来描述不同的交通场景的,这门语言对交通环境中各个层次的定义是否合理(可表示需要的细节,同时又具备可拓展性)。
针对功能场景、逻辑场景以及具体场景都有相应的场景语言:如针对前两者,有M-SDL等高级场景语言;针对后者有OpenSCENARIO、GeoScenario等。
还有一个层面可能是对干扰行为的仿真,对各种驾驶行为、驾驶“性格”的泛化程度。
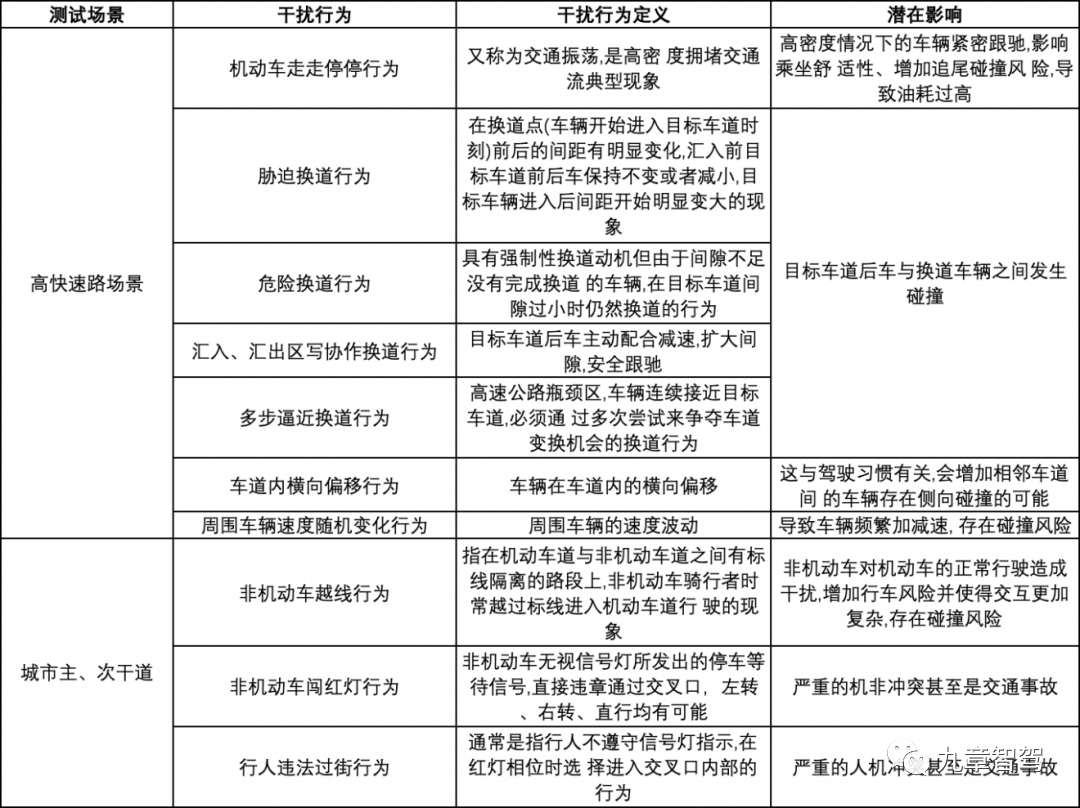
△图表摘自孙剑、田野、余荣杰所著《自动驾驶虚拟仿真测试评价理论与方法》一书
深信科技创始人杨子江说:“基于交通流的泛化和驾驶员的智能化,如果模型足够好,由于随机因子的存在,场景运行10次,就相当于泛化了10个。”
不过,智行众维CTO李月认为,不能为了泛化而泛化。“我们一定要对被测的功能有深刻的理解,然后再去设计泛化方案,而不是为了泛化而泛化,更不能漫无边际地去泛化。场景泛化虽然是虚拟,但也要尊重现实。”
另外一位仿真专家也说:“说到底,仿真还是要为测试服务的,我们是已经在路上遇到了一个问题,然后看如何通过仿真解决,而不是说我先有了一个仿真的技术,然后看用在什么问题上吧?”
前文提到的一位仿真专家称,据他了解,目前还没有多少公司能真正做到场景泛化的自化,在大多数情况下,调参都是靠人工来完成的。“场景泛化能力,尽管很重要,但现阶段,还没有哪个公司真能做得很好。”
51 World车载仿真业务负责人鲍世强认为,做场景泛化,最重要的是要对自动驾驶仿真测试需要什么样的场景有一个深刻的理解。事实上,现在的问题不是生成的场景太少,实在是太多,而且有很多并不会真实发生,算不上有效的测试场景,这就是对需求理解不到位造成的。
有专家称,第三方仿真公司面临的最大挑战是,由于自己并没有亲自上阵做自动驾驶,因而对自动驾驶究竟需要什么样的仿真理解是不足的。
而那些有能力、对仿真需求理解比较深入的L4级自动驾驶公司,其实并没有足够的动力把场景泛化做得非常深入。因为,Robotaxi通常只在某个城市的一个很小的区域里跑,他们只要采集这一个区域的场景数据做训练和测试就行了,没有太大的必要去泛化出很多他们在相当长一段时间内都不会接触的场景。
鲍世强认为,蔚小理这些主机厂,真实道路数据比较多,对场景泛化也没有太强的需求。相反,对这些公司来说,比场景泛化更迫切的,是对场景做精细化分类管理,筛选出真正有效的场景。
轻舟智航的仿真专家也认为,随着车队规模的增加、来自真实道路的数据规模急剧膨胀,对仿真公司来说,如何充分挖掘出这些数据中的有效场景确实比做场景泛化重要得多。“我们也许会探索出智能化程度更高的泛化手段,能更快地对算法做大规模验证。”
杨子江说:“针对参数层面的泛化,例如车道数量、交通参与者的种类数量、天气,以及速度、TTC等关键参数,各家产生泛化场景的能力都差不多,但场景泛化能力的核心在于如何识别有效场景,过滤无效场景(包括重复的、不合理的);而场景识别的难点在于,复杂场景需要识别多个对象之间相互关系。”
上述几位提到的“识别有效场景,过滤无效场景”,又被称为“场景提取”。
场景提取的前提是,先搞清楚究竟什么是“有效场景”。据几位仿真专家介绍,除法律规定应当测试的场景外,有效场景还包括如下两类:做系统正向设计时,工程师根据算法的开发需求定义的场景;测试中被挖掘出的那些“算法搞不定”的场景。
当然,有效和无效都是相对的,这跟公司的发展阶段、算法的成熟阶段有关——原则上,随着算法的成熟、问题的解决,很多原来的有效场景都会成为无效场景。
那大家是如何高效地筛选出有效场景的?
学术界有一种设想是:在感知算法里面设定一些熵值,当场景的复杂度超过了这些值,感知算法就把改场景标记为一个有效的场景。但这个熵值怎么设,存在很大挑战。
某仿真公司采用的是“排除法”,即如果一个原本表现非常好的算法在某一些泛化场景中“问题频发”,那这个场景大概率就是“无效场景”,可以排除了。
某主机厂的系统工程师说:“目前还没有很好的做场景筛选的方法。如果吃不准,那就放到云仿真上去算,总归是能算出来这些极限场景,然后再拿这些极限条件在自己的HIL台架上或者VIL台架上做验证,那么效率就会高很多”。
本文写作中引用了大量来自微信公众号“车路慢慢”的干货知识。 该公众号的作者李慢慢是仿真工程师,该号聚焦于仿真专业知识的梳理,推荐对这个赛道感兴趣的朋友关注。

参考资料:
自动驾驶仿真超全综述:从仿真场景、系统到评价
https://zhuanlan.zhihu.com/p/321771761
写在最后
关于投稿
如果您有兴趣给《九章智驾》投稿(“知识积累整理”类型文章),请扫描右方二维码,添加工作人员微信。

注:加微信时务必备注您的真实姓名、公司、现岗位
以及意向岗位等信息,谢谢!
“知识积累”类稿件质量要求:
A:信息密度高于绝大多数券商的绝大多数报告,不低于《九章智驾》的平均水平;
B:信息要高度稀缺,需要80%以上的信息是在其他媒体上看不到的,如果基于公开信息,需有特别牛逼的独家观点才行。多谢理解与支持。
推荐阅读:
◆九章 - 2021年度文章大合集
◆当候选人说“看好自动驾驶产业的前景”时,我会心存警惕——九章智驾创业一周年回顾(上)
◆数据收集得不够多、算法迭代得不够快,就“没人喜欢我”————九章智驾创业一周年回顾(下)
◆车辆控制中的“实时性”及其影响因素
◆激光雷达:905与1550的战争
◆“舱驾融合”技术发展趋势分析
◆揭开自动驾驶在机场场景的商业化现状、挑战及趋势
最后
以上就是眯眯眼板栗最近收集整理的关于自动驾驶科普文之一:场景来源、场景泛化及提取的全部内容,更多相关自动驾驶科普文之一内容请搜索靠谱客的其他文章。








发表评论 取消回复