- ???? 个人主页: 同学来啦
- ???? 版权: 本文由【同学来啦】原创、在CSDN首发、需要转载请联系博主
- ???? 如果文章对你有帮助,欢迎关注、点赞、收藏和订阅专栏哦
文章目录
- ???? 一、ChatGPT简要介绍
- ???? 二、ChatGPT有哪些改进?
- ???? 三、ChatGPT性能提升
- ???? 1、性能表现
- ???? 2、实现路径
- ???? 2.1 Transformer结构区别
- ???? 2.2 模型量级提升
- ???? 2.3 基于人类反馈的强化学习
- ???? 四、OpenAI追求特点
???? 一、ChatGPT简要介绍
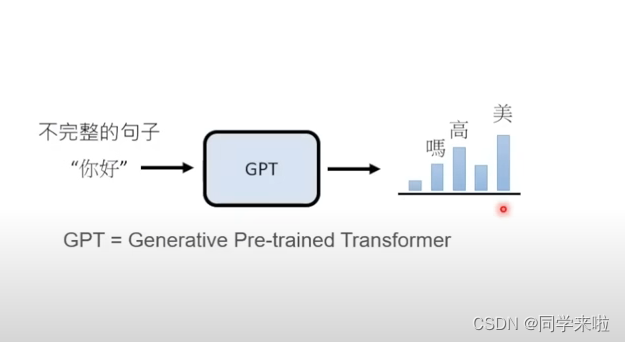
ChatGPT是美国OpenAI公司研发的大参数预训练生成语言模型,是一款通用的自然语言生成模型,其中GPT “生成性预先训练转换器”(generative pretrained transformer)的缩写。该模型被互联网巨大的语料库训练之后,其可以根据你输入的文字内容来生成对应的文字回答,即为常见的聊天问答模式。

语言模型的工作方式是对语言文本进行概率建模,用来预测下一段输出内容的概率,形式上有些类似于文字接龙游戏。比如输入的内容是“你好”,模型可能就会在可能的结果中选出概率最高的那一个,用来生成下一部分的内容。

???? 二、ChatGPT有哪些改进?
ChatGPT之所以有如此强烈的反响,很大程度上是因为其在语言能力上的显著提升。ChatGPT相比于其他聊天机器人,主要表现在以下几个方面:
- 1️⃣对于用户实际意图的理解有明显提升。对于使用过类似聊天机器人或者自动客服的同学,应该经常会遇到机器人兜圈子甚至答非所问的情况,用户体验感较差。ChatGPT在该方面有了显著提升,具有更加良好的用户体验。
- 2️⃣具有非常强的上下文衔接能力。对于我们用户而言,用户不仅可以问一个问题,而且可以通过不断追加提问的方式,让其不断改进回答内容,最终达到用户期待的理想效果。
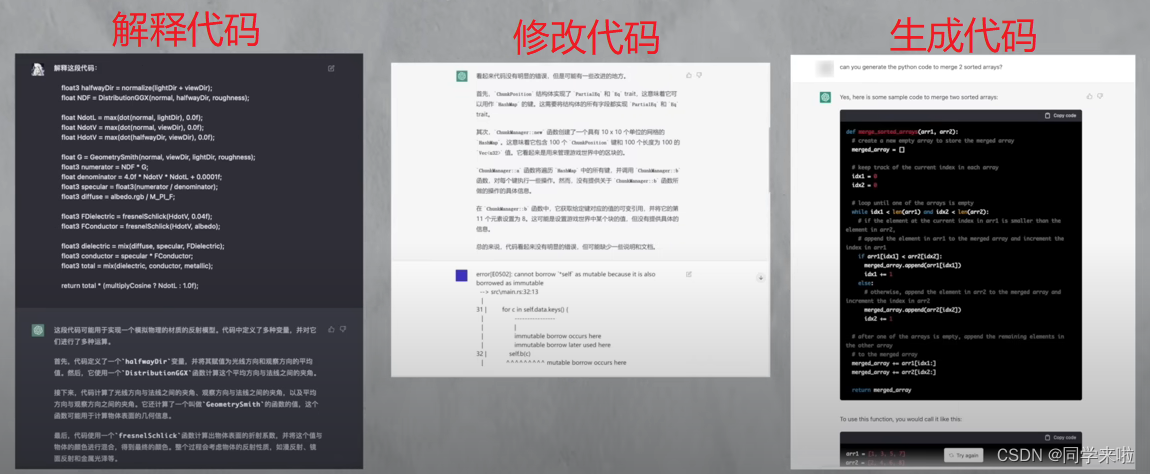
- 3️⃣更强的对知识和逻辑的理解能力。当遇到某个问题,其不仅给出一个完整的回答,并且对追加细节也可以很好的解答。(这种兼容大量知识且富含逻辑的能力非常适合编程,目前网上已有很多如何解释、修改甚至生成完整代码的案例,具体详见下图。)
???? 三、ChatGPT性能提升
???? 1、性能表现
截止目前尚未发现ChatGPT的公开论文(如有请指出),但可以明确的是ChatGPT与Open AI此前发布的InstructGPT具有非常接近的姊妹关系,两个模型的训练过程也非常接近,因此InstructGPT有较为可靠的参考价值。

在OpenAI关于InstrcutGPT的论文中,可以找到一些直观优势的量化分析,InstrcutGPT对比GPT-3模型有如下特点:
- 1️⃣71%~88%的情况下,InstrcutGPT生成的回答要比GPT-3模型的回答更加符合训练人员的喜好。
- 2️⃣在回答真实程度上更加可靠,编造的概率从GPT-3的41%下降到InstrcutGPT的21%。
- 3️⃣InstrcutGPT产生有毒回答的概率减小了25%。
???? 2、实现路径
为何ChatGPT可以做到如此出色的效果?让我们把视角稍微拉远一些,看看该款模型近几年的发展历史。
从演进关系来看,ChatGPT是OpenAI的另一款模型,InstrcutGPT的姊妹版本,其基于InstrcutGPT做了一些调整。具体的发展路线如下:

限于篇幅和实际情况,本文无法对每篇文章进行解析,重点提一下几个有意思的决定和突破。
???? 2.1 Transformer结构区别
对于从Transformer结构上分支出来的BERT和GPT,有一点不同是来自于Transformer的结构区别。BERT使用的是Transformer的Encoder组件,Encoder组件在计算某个位置时会关注文章的上下文信息;而GPT使用的是Transformer的decoder组件,decoder组件在计算某个位置时只关注文章的上文信息。
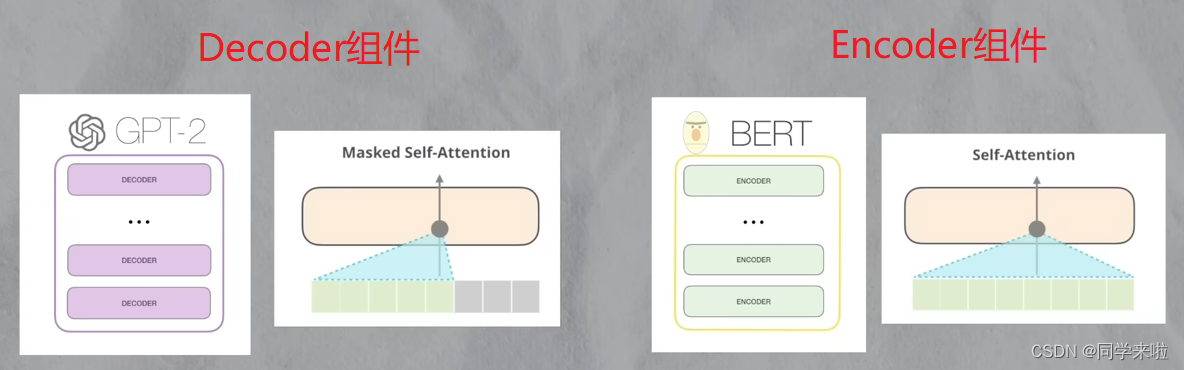
- BERT在结构上对上下文的理解会更强,更适合嵌入式表达,即填空式的任务(比如完形填空)。
- GPT在结构上更适合只有上文而完全不知道下文的任务,即根据上文推测下文(比如对话聊天)。
???? 2.2 模型量级提升
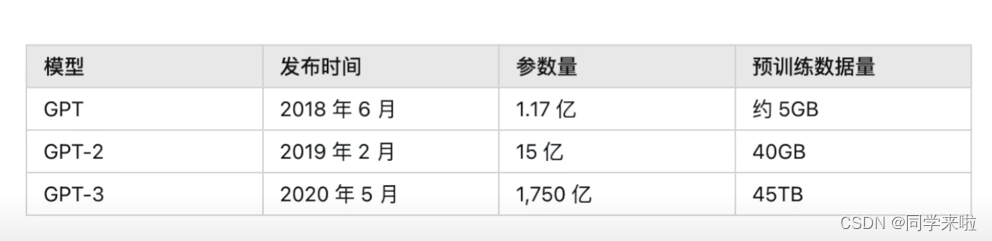
一个有趣的突破是来自于模型量级上提升。从GPT-1到GPT-3,模型参数量从1.17亿到15亿,再到1750亿。GPT-3相比于同类型的语言模型参数量增加了10倍以上。训练数据量也由从 GPT 的 5GB,增加到GPT-2的40GB,再到GPT-3的45TB。
在方向上,OpenAI并未追求在特定类型任务上的表现,而是不断增强模型的泛化能力。因而就对训练数据量和参数量提出来更高的要求。伴随着巨大参数量的是巨大的训练成本,GPT-3的训练费用也达到了惊人的1200万美元,
???? 2.3 基于人类反馈的强化学习
从GPT-3到 InstrcutGPT的一个有趣改进是引入了人类的反馈。引自OpenAI论文的说法,在InstrcutGPT之前,大部分大规模语言模型的目标都是基于上一个输入片段token来推测下一个输出片段,然而这个目标和用户的意图是不一致的,用户的意图是让语言模型能够有用并且安全地遵循用户的指令。此处的指令也就是InstrcutGPT名字的来源,也呼应了ChatGPT的最大优势,即对用户意图的理解。

为了达到该目的,引入了人类老师(即标记人员),通过标记人员的人工标记来训练出一个反馈模型,该反馈模型再去训练GPT-3。之所以没有让标记人员直接训练GPT-3,可能是由于数据量过大的原因。该反馈模型就像是被抽象出来的人类意志可以用来激励GPT-3的训练,整个训练方法即为基于人类反馈的强化学习。

???? 四、OpenAI追求特点
OpenAI追求的特点:
- ????Decoder 结构:适合问答模式;
- ????通用模型:避免在早期架构和训练阶段为特定任务做调优;
- ????巨量数据和参数:模型知识储备丰富;
- ????连续对话的能力:具备强大上下文对话能力(基本原理如下)。
上下文对话原理:
语言模型生成回答的方式是基于一个个token(单词),ChatGPT生成一句话的回答是从第一个词开始,重复把问题以及当前生成的所有内容再作为下一次的输入,生成下一个token,直到生成完整的回答。

既然一句话是基于前面所有上文的一个个词生成的,同样的原理也可以把之前的对话作为下一次问题的输入,这样下一次的回答就可以包含之前对话的上下文。由于GPT-3 API里面,单次交互最多支持4000多个token,猜测Chat GPT估计也是4000个token左右。
最后
以上就是难过悟空最近收集整理的关于ChatGPT简要解读(一) - 原理分析与性能提升篇???? 一、ChatGPT简要介绍???? 二、ChatGPT有哪些改进????? 三、ChatGPT性能提升???? 四、OpenAI追求特点的全部内容,更多相关ChatGPT简要解读(一)内容请搜索靠谱客的其他文章。








发表评论 取消回复