作者只是一个小白,最近希望能提升自己的代码水平,所以开始刷leetcode。写博客是为了整理自己的学习内容,难免会出错。如果有大大发现,非常欢迎指正哦!
目录
题目:1、两数之和
题解
方法一:双重for循环,暴力枚举
1、自己的代码
2、代码一
方法二:哈希表
第一次检测
第一次存储
第二次检测
第二次存储
第三次检测
第三次存储
第四次检测
其他
1、为什么给htable分配的是256个hnode的空间?
2、红框中的temp为什么不用先分配空间呢?
题目:1、两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。
你可以按任意顺序返回答案。
示例 :
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] ==9 ,返回 [0, 1] 。
题解
方法一:双重for循环,暴力枚举
这个思路比较简单,就不赘述,直接上代码了。
1、自己的代码
执行用时:96ms
排名:超过32%提交记录
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* twoSum(int* nums, int numsSize, int target, int* returnSize){
int i,j;
for(i=0;i<numsSize;++i)
{
for(j=i+1;j<numsSize;++j)
{
if(nums[i]+nums[j]==target)
{
int* ret=(int*)malloc(sizeof(int)*2);
ret[0]=i,ret[1]=j;
*returnSize=2;
return ret;
}
}
}
*returnSize=0;
return NULL;
}
2、代码一
执行用时:60ms
排名:超过85%提交记录
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* twoSum(int* nums, int numsSize, int target, int* returnSize){
int a,b=0;
int* ret = malloc(sizeof(int) * 2);
for(int i=0;i<numsSize-1;++i){
int m=target-nums[i];
for(int j=i+1;j<numsSize;++j){
if(nums[j]==m){
ret[0]=i;
ret[1]=j;
*returnSize=2;
return ret;
}
}
}
*returnSize=0;
return NULL;
}60ms的是暴力解法中最快的。那我差在哪里呢?
很明显,我在循环里堆了很多不必要的东西。如果把分配空间这一句放到外面,时间马上降到76ms;再把两数之和的运算放在第二重循环外,时间就降到68ms。代码如下:
执行用时:68ms
排名:超过83.5%提交记录
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
int* twoSum(int* nums, int numsSize, int target, int* returnSize){
int i,j;
int* ret=(int*)malloc(sizeof(int)*2);
for(i=0;i<numsSize;++i)
{
int m=target-nums[i];
for(j=i+1;j<numsSize;++j)
{
if(nums[j]==m)
{
ret[0]=i,ret[1]=j;
*returnSize=2;
return ret;
}
}
}
*returnSize=0;
return NULL;
}这时候我很奇怪,因为我觉得这时的代码应该和代码一是一样的了,可为什么会慢8ms呢?于是我用代码一测了几次,时间都是64ms或者68ms。所以可能是测试的例子变了吧。
方法二:哈希表
具体哈希表的介绍可以查看这篇博客:数据结构 Hash表
我个人的理解是将一串数据存储到哈希表,每一个数据至少需要有两个属性:index和val。index代表数据存储在表中的位置,是根据数据本身的值val通过一定的方式计算出来的,所以如果知道数据的值,就可以直接得到数据存储的位置,而不用一个一个去找,时间复杂度就从降到
。
以下是大佬用哈希表写的代码:
执行用时:0ms
排名:超过100%提交记录
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
struct hnode
{
int val;
int index;
struct hnode *next;
};
int* twoSum(int* nums, int numsSize, int target, int* returnSize){
struct hnode **htable, *temp;
int key, index, sum;
int *result;
htable = malloc(256 * sizeof(struct hnode*));
memset(htable, 0, 256 * sizeof(struct hnode*));
result = (int*)malloc(2 * sizeof(int));
result[0] = 0;
result[1] = 0;
*returnSize = 2;
for (index = 0; index < numsSize; index++)
{
sum = target - nums[index];//我们的目标就是要找到sum这个值存在哪里
key = sum & 0xff;//sum这个值要存储也是存储在htable中key这个位置
temp = htable[key];//temp取出htable[key]中的内容
while (temp != NULL)//如果temp中有内容,因为可能存在数据冲突,仍要继续检查存储的数据的值是我们需要的,而不能直接返回结果
{
if (temp->val == sum)//是我们的需要的,则返回结果
{
result[0] = temp->index;
result[1] = index;
return result;
}
else
{
temp = temp->next;//如果不是我们需要的,就找该位置存储的其他数据
}
}
key = nums[index] & 0xff;//此处往下6行是将没有找到匹配成功的数据存入htable中
temp = malloc(sizeof(struct hnode));
temp->val = nums[index];
temp->index = index;
temp->next = htable[key];//这是将表中之前该位置存储的数据取出来,方便我们下一句将该位置的数据连同这一次的数据,整体存入htable中
htable[key] = temp;
}
return result;
}C中已经有写好uthash.h的头文件,我们可以很方便地直接构建哈希表。有需要的大家可以去github下载:uthash.h
但这块代码没有用uthash.h,而是自己构建了一个哈希表。让我们来看看吧!
struct hnode
{
int val;
int index;
struct hnode *next;
};hnode就是一张存放数据的表格,val是存放数据的值,index是代表数据存储的位置,而next相当于在发生冲突的时候,多一块空间存储发生冲突的数据。
key = sum & 0xff;而这边计算存储位置的方法是取数据的二进制的后8位。
要理解代码,最好是举个例子看看。为了能实现哈希表中数据存储冲突,方便选取数据,所以我代码里把0xff改成0xf,即只取数据二进制的后4位。
nums = [2,18,34,7],target = 9
第一次检测
index = 0,key = 7,sum = 7
temp为空,所以直接跳过while循环。
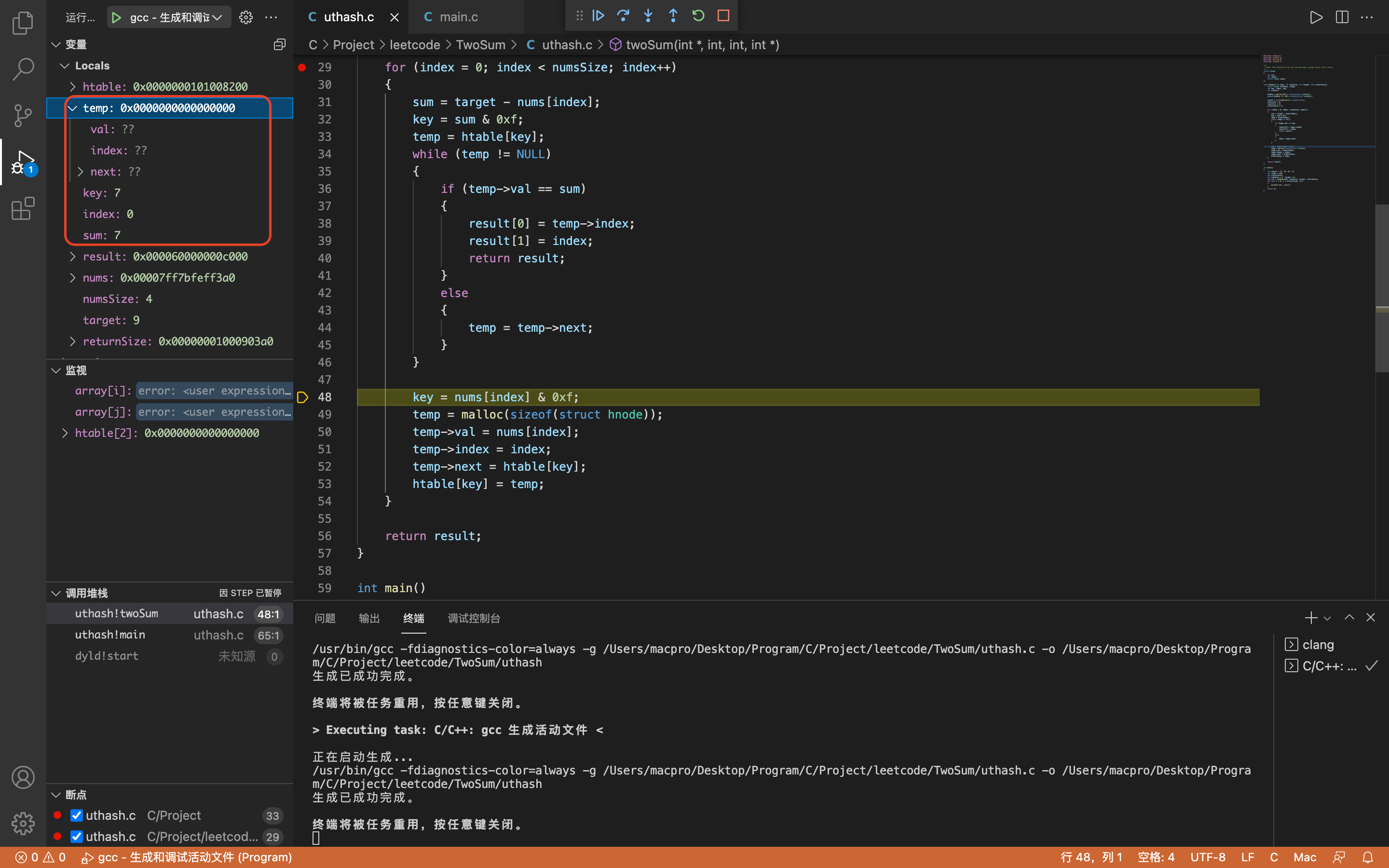
第一次存储
key = 2,temp->val = 2,temp->index = 0,temp->next = NULL
htable[2]->val = 2,htable[2]->index = 0,htable[2]->next = NULL
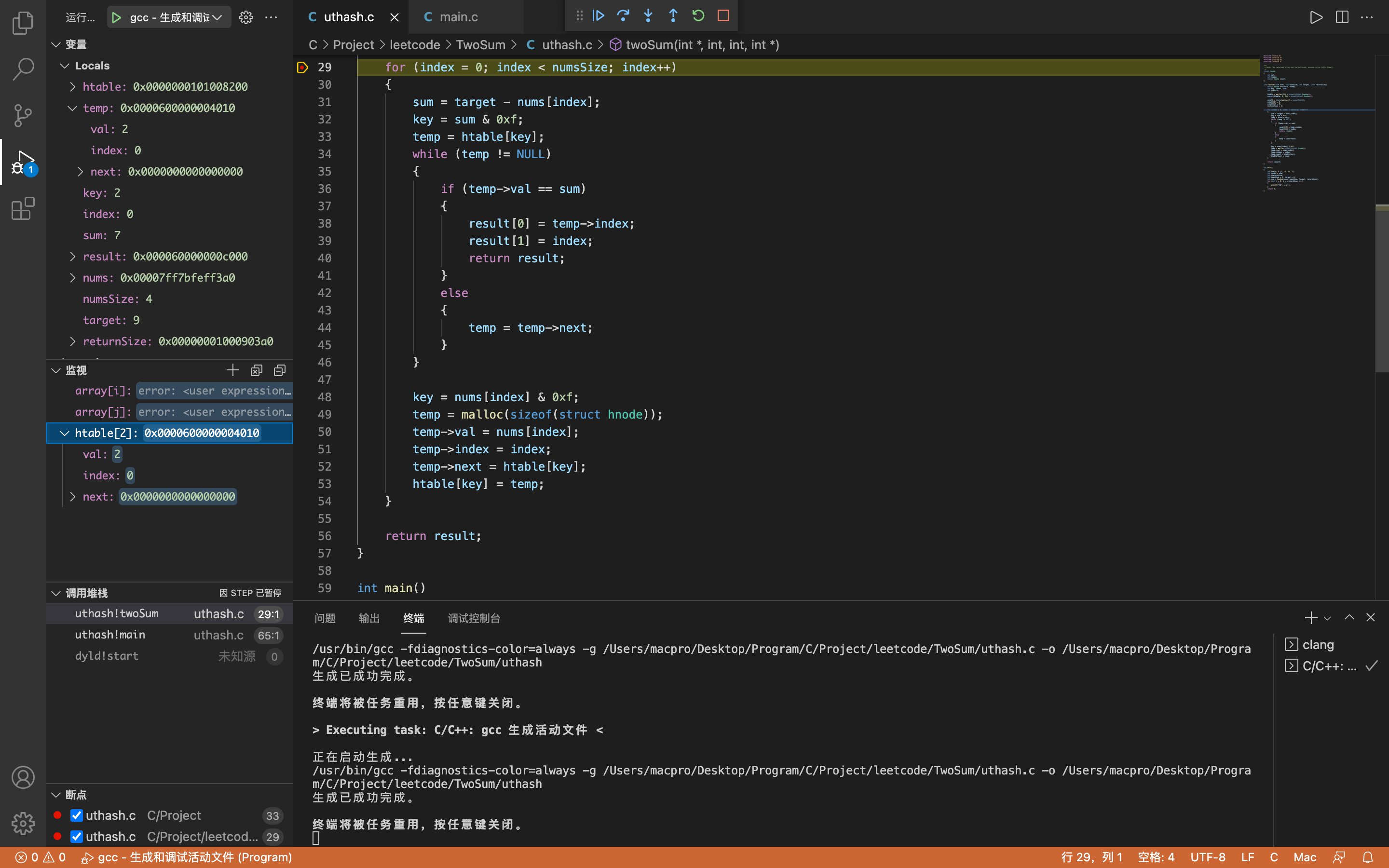
第二次检测
index = 1,key = 7,sum = -9
temp为空,所以直接跳过while循环。
第二次存储
key = 2,temp->val = 18,temp->index = 1,temp->next.val = 2,temp->next.index = 0(第一次存储的数据)
(我不知道temp->next.val这种表达方式对不对,如果有大大知道,欢迎教教我)
htable[2]->val = 18,htable[2]->index = 1,htable[2]->next.val = 2,htable[2]->next.index = 0(第一次存储的数据)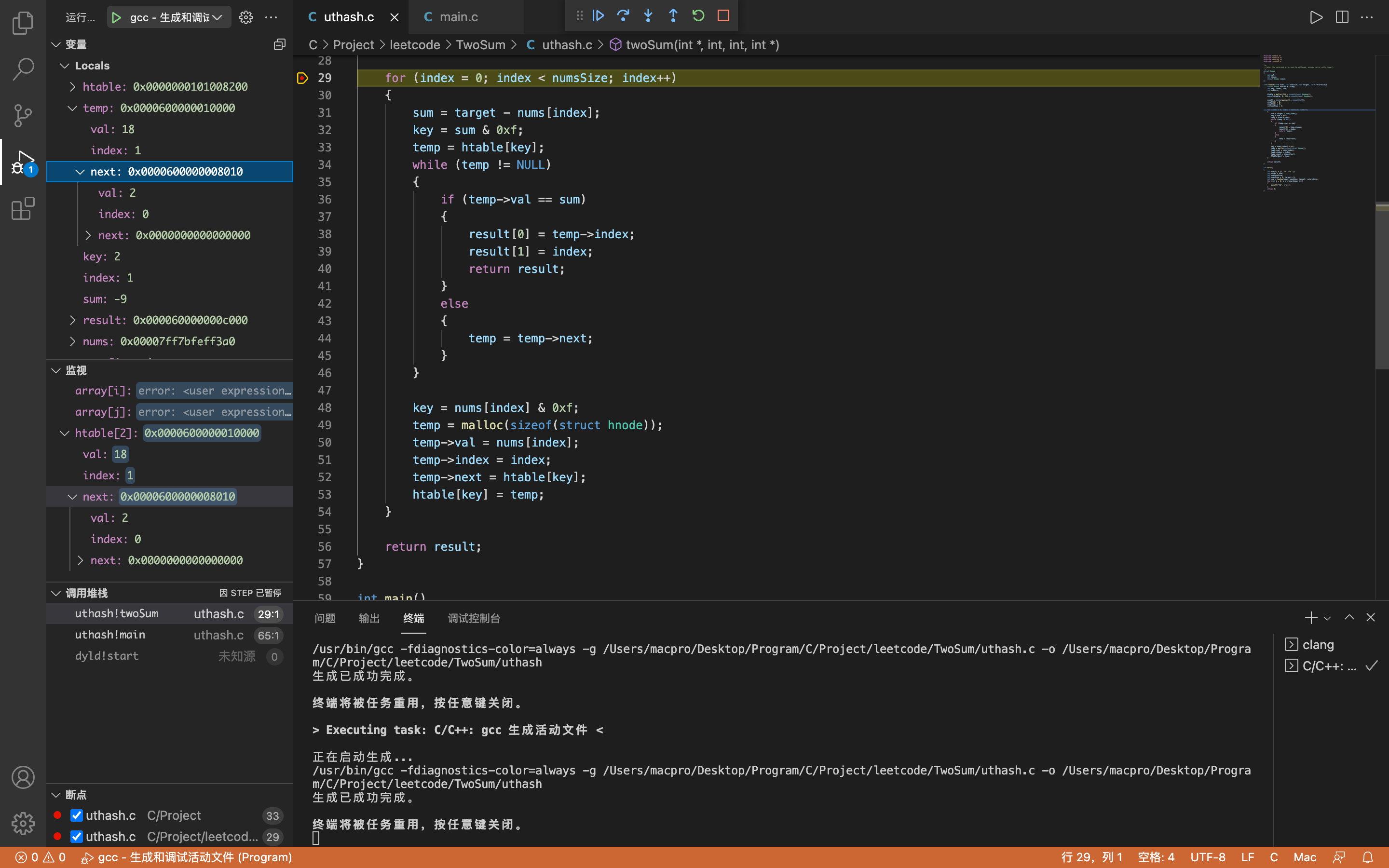
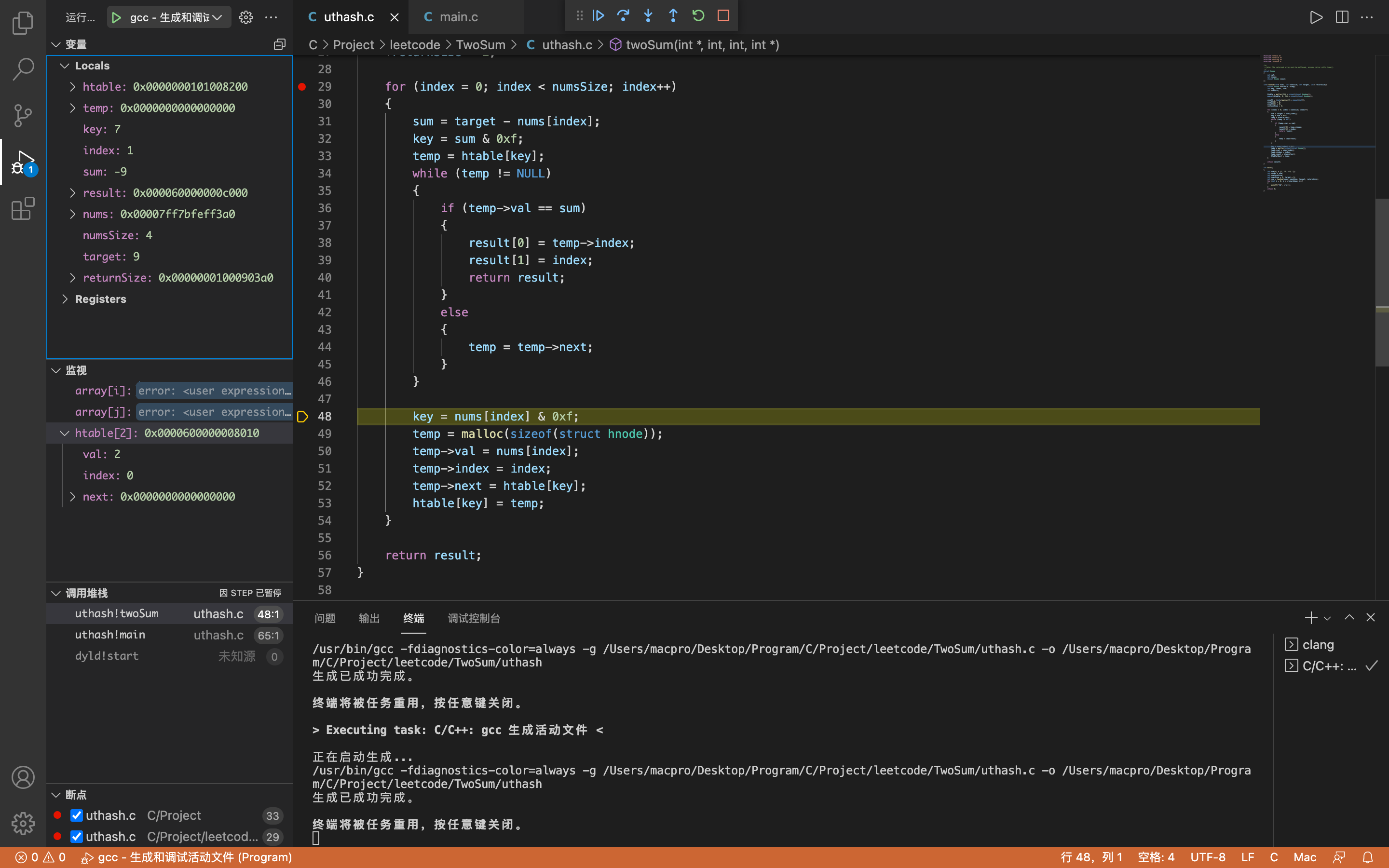
第三次检测
index = 2,key = 7,sum = -25
temp为空,所以直接跳过while循环。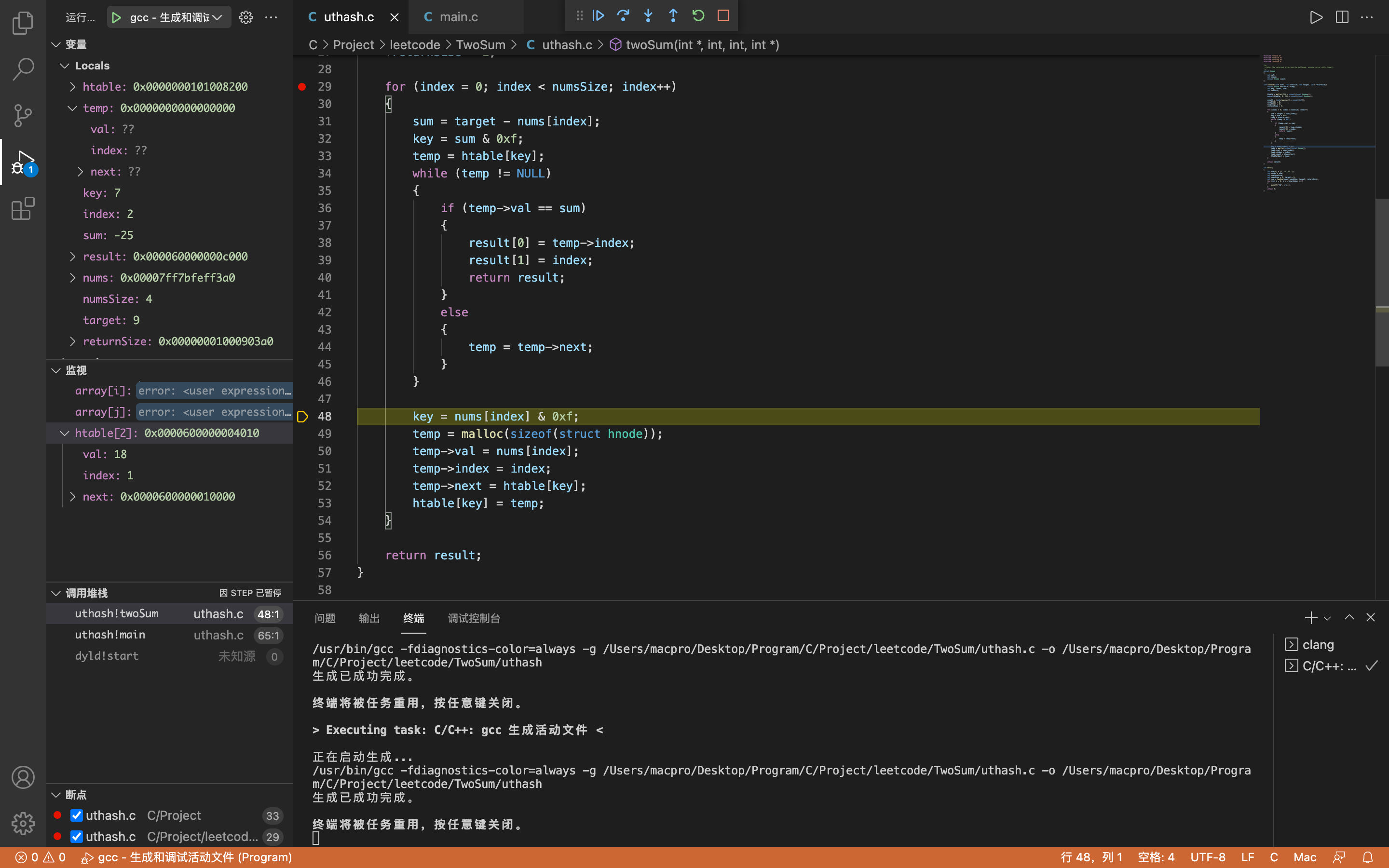
第三次存储
key = 3,temp->val = 34,temp->index = 2,temp->next.val = 18,temp->next.index = 1(第二次存储的数据),temp->next ->next.val = 2,temp->next->next.index = 0(第一次存储的数据)
htable[2]->val = 34,htable[2]->index = 2,htable[2]->next.val = 18,htable[2]->next.index = 1(第二次存储的数据),htable[2]->next->next.val = 2,htable[2]->next->next.index = 0(第一次存储的数据)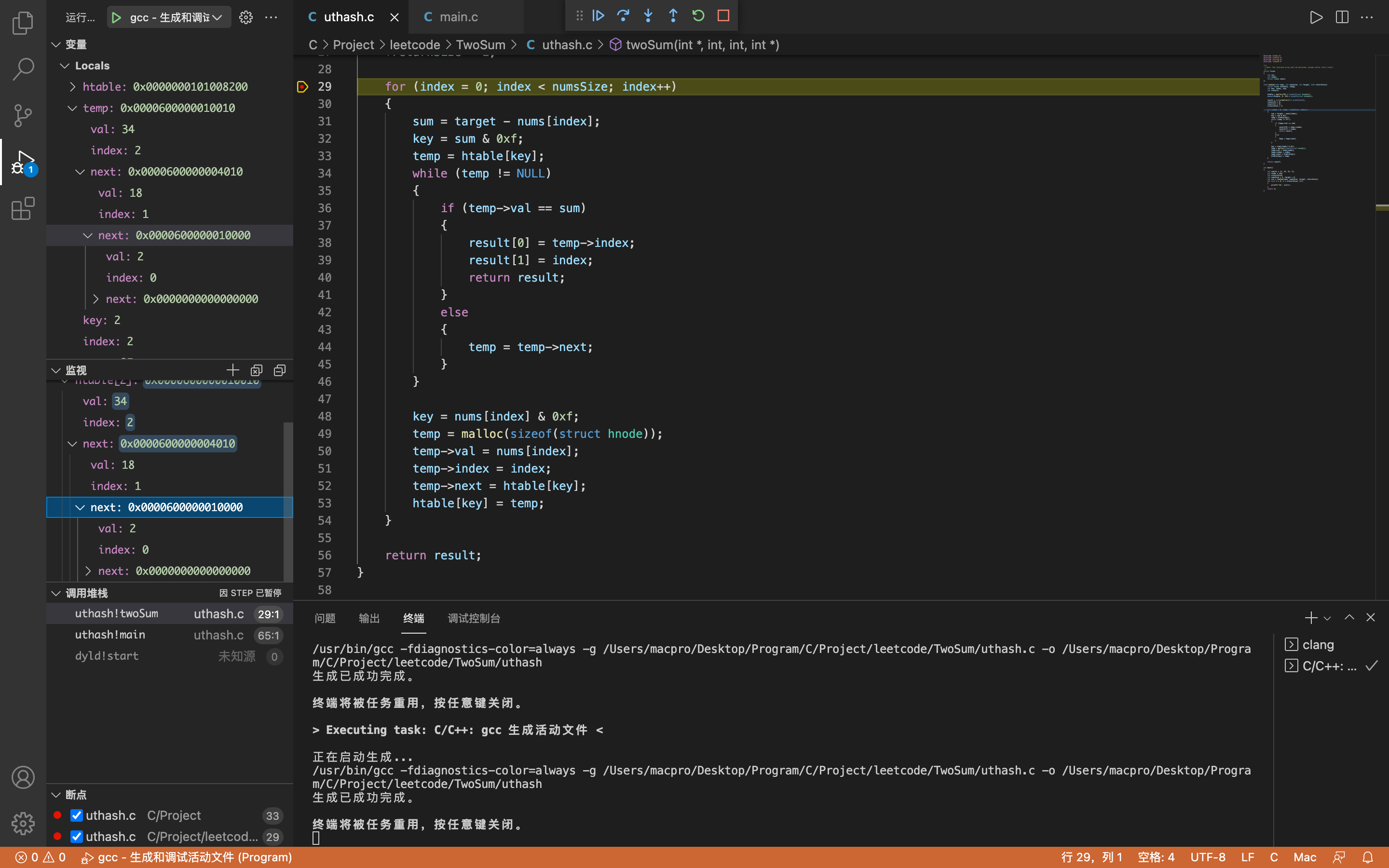
第四次检测
index = 3,key = 2,sum = 2
temp取得htable[2]中的内容,不为空,进入while循环。temp->val = 34,temp->index = 2(即第三次存储的数据)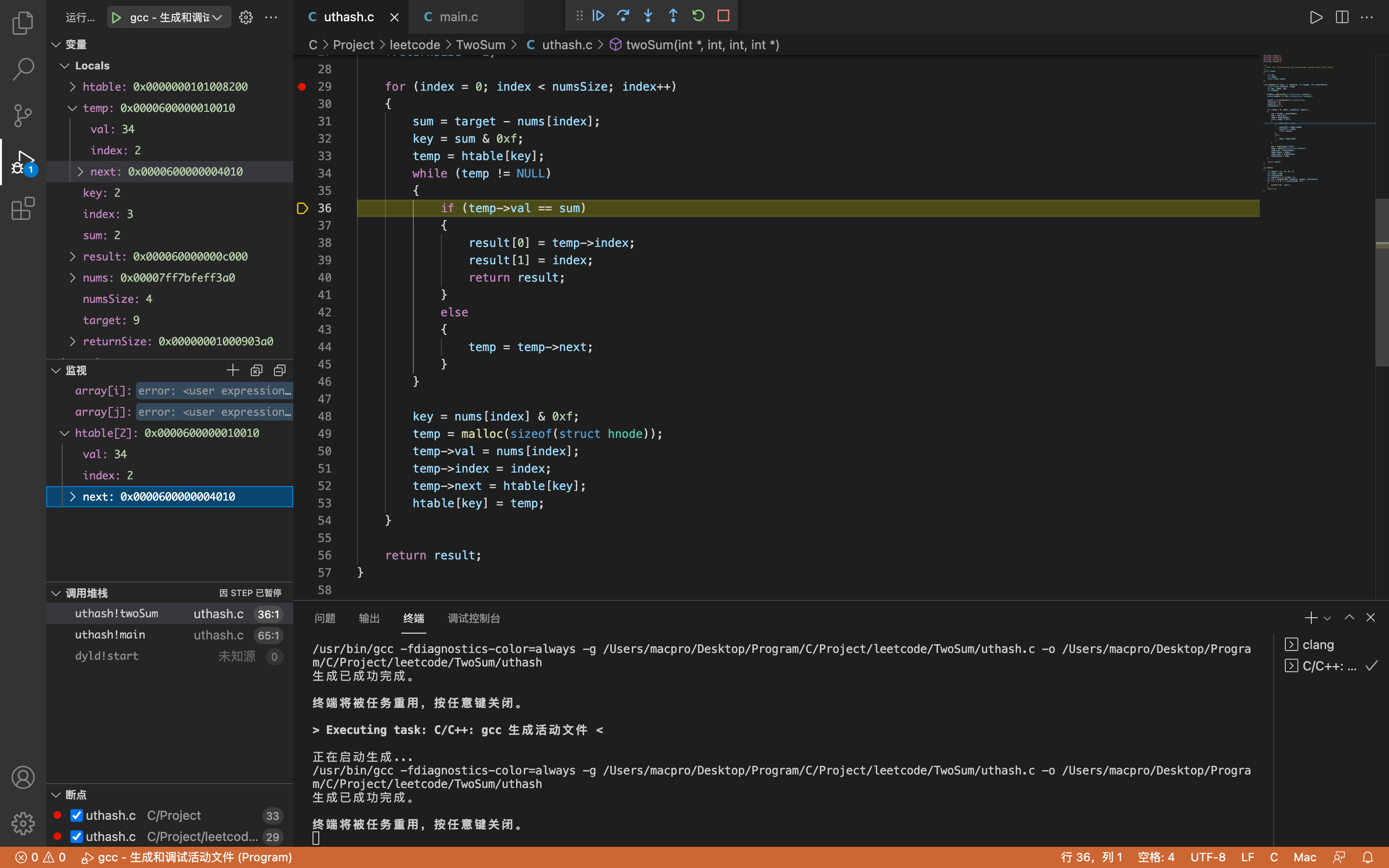
因为temp->val = 34,sum = 2,所以temp->val != sum,所以执行temp = temp->next这一语句。
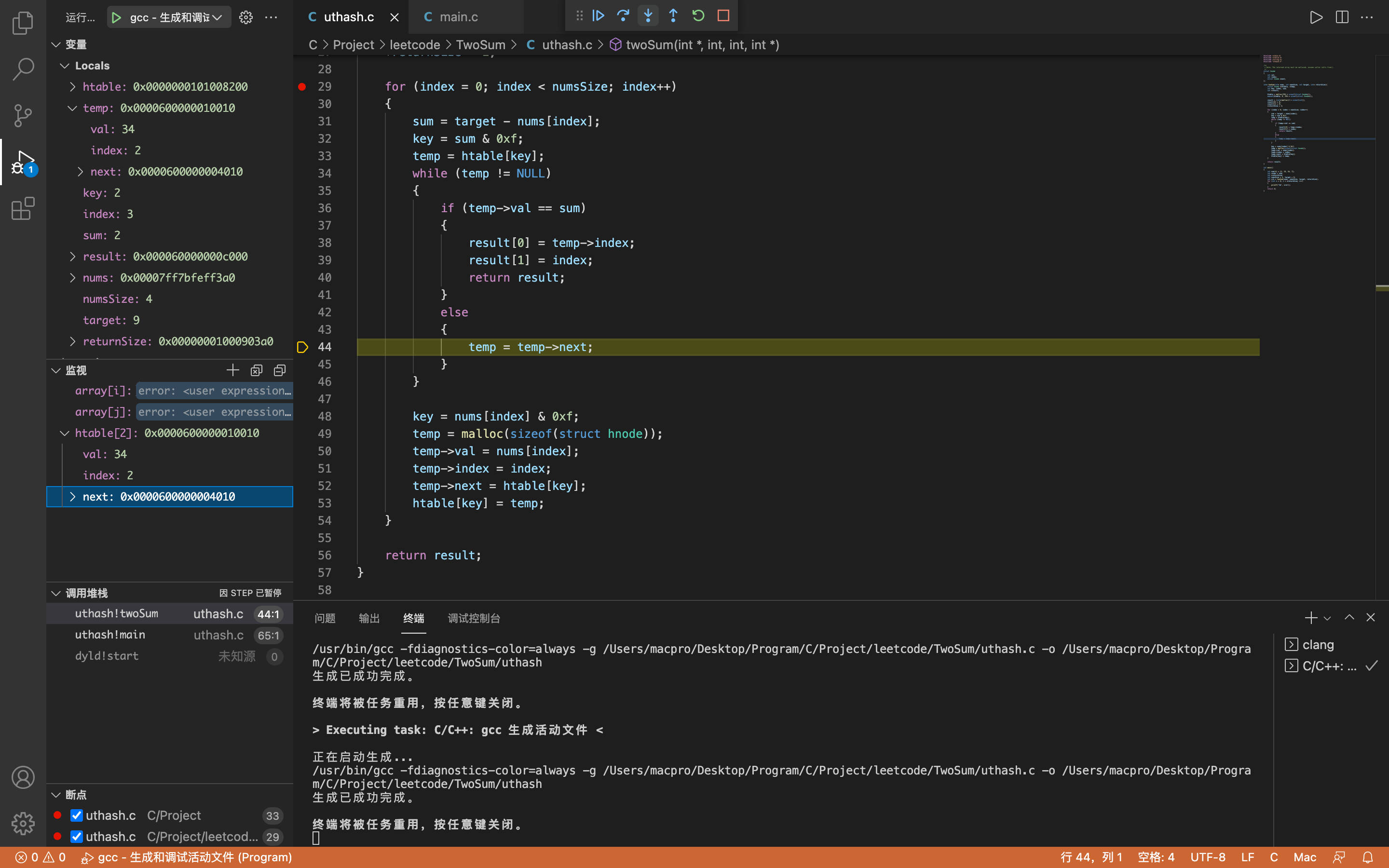
此时temp->val = 18, temp->index = 1(即第二次存储的数据)
temp不为空,进入while循环。
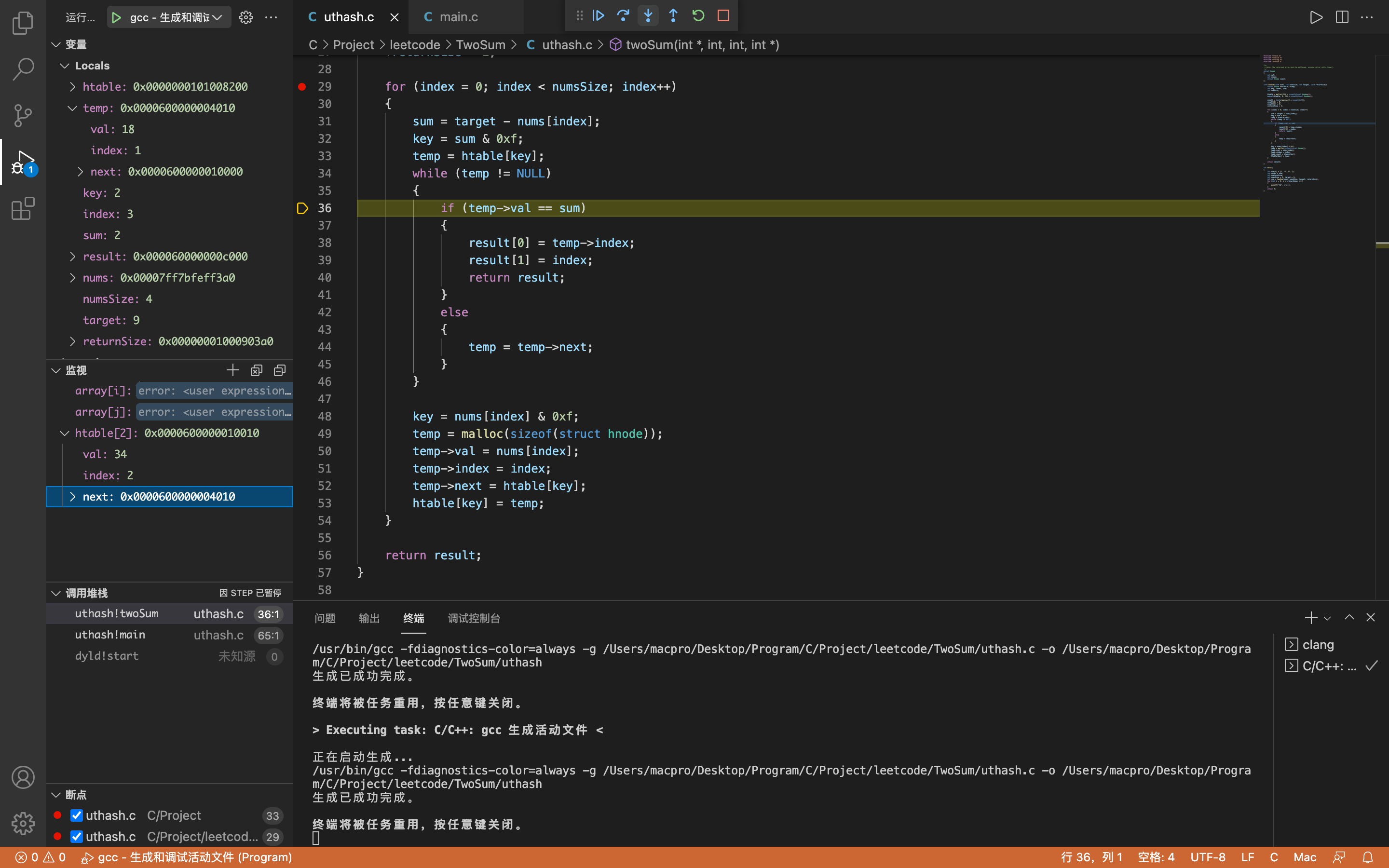
同样因为temp->val != sum,所以执行temp = temp->next语句。
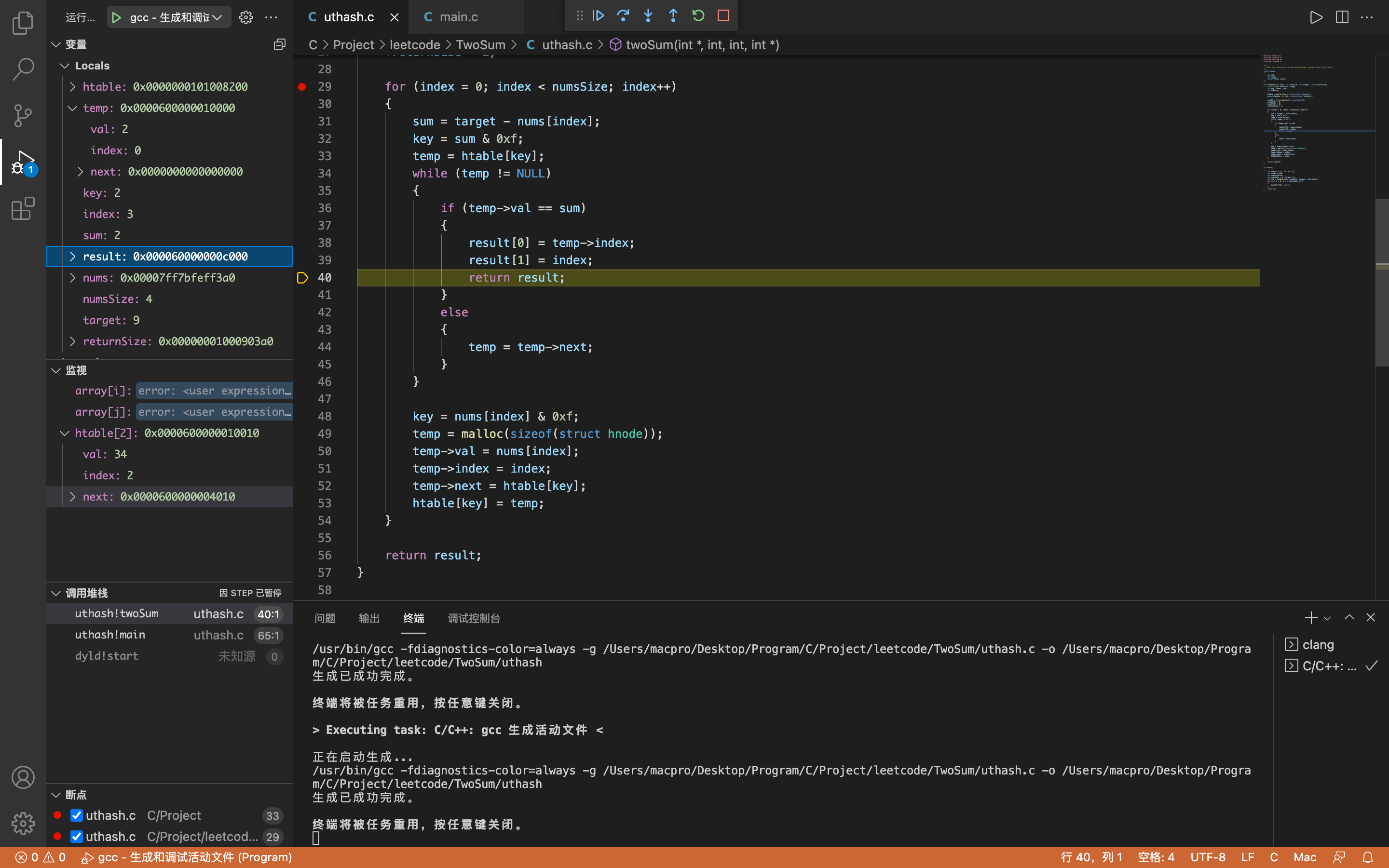
temp->val = 2,temp->index = 0(即第一次存储的数据)
因为temp->val == sum,所以返回result,程序结束。
其他
1、为什么给htable分配的是256个hnode的空间?
htable = malloc(256 * sizeof(struct hnode*));
memset(htable, 0, 256 * sizeof(struct hnode*));因为这边计算数据存储位置的方法是:
key = sum & 0xff;相当于取数据后8位,那么key的数量最多就是=256个,所以分配256个hnode的空间就够了。
另外memset的作用是给htable赋值,在这边的作用是初始化为0。具体用法可以参考:memset()函数及其作用
另外,如果memset这句不写的话,在vscode里跑不会出问题,但在leetcode中会报错:
Line 31: Char 21: runtime error: member access within misaligned address 0xbebebebebebebebe for type 'struct hnode', which requires 8 byte alignment [solution.c] 0xbebebebebebebebe: note: pointer points here <memory cannot be printed>
这一点我还没有想明白...
2、红框中的temp为什么不用先分配空间呢?
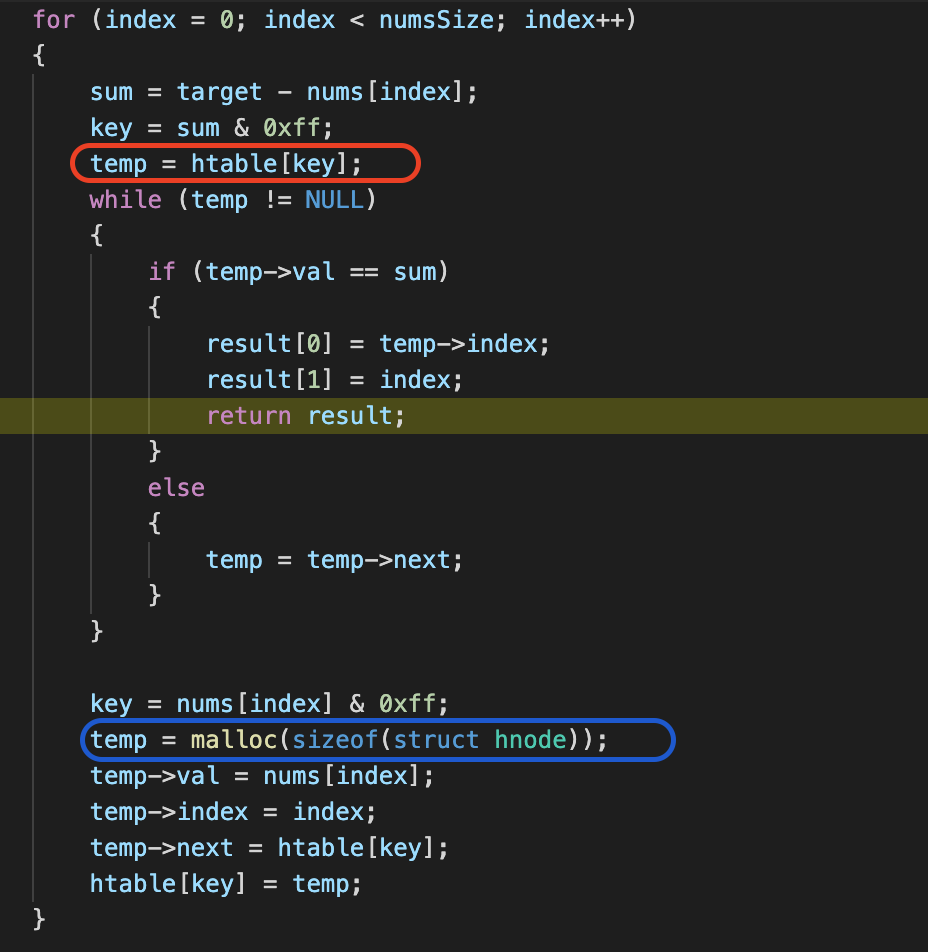
为什么红框中temp之前没有分配空间操作,像malloc什么的,就可以直接进行赋值,而蓝框处temp之前已经赋过值了,还要分配空间呢?
最后
以上就是纯真跳跳糖最近收集整理的关于LeetCode 1、两数之和(C)题目:1、两数之和题解 其他的全部内容,更多相关LeetCode内容请搜索靠谱客的其他文章。



![阶乘和(C++实现)[NOIP1998P2]阶乘和](https://www.shuijiaxian.com/files_image/reation/bcimg20.png)




发表评论 取消回复