欢迎来到自动驾驶汽车的第五部分,并与Carla、Python和TensorFlow加强学习。
现在我们已经有了环境和代理,我们只需要添加更多的逻辑将它们连接在一起,这是我们接下来要做的。
首先,我们将从强化学习教程中复制粘贴修改后的张量板类:
from keras.callbacks import TensorBoard
...
# Own Tensorboard class
class ModifiedTensorBoard(TensorBoard):
# Overriding init to set initial step and writer (we want one log file for all .fit() calls)
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.step = 1
self.writer = tf.summary.FileWriter(self.log_dir)
# Overriding this method to stop creating default log writer
def set_model(self, model):
pass
# Overrided, saves logs with our step number
# (otherwise every .fit() will start writing from 0th step)
def on_epoch_end(self, epoch, logs=None):
self.update_stats(**logs)
# Overrided
# We train for one batch only, no need to save anything at epoch end
def on_batch_end(self, batch, logs=None):
pass
# Overrided, so won't close writer
def on_train_end(self, _):
pass
# Custom method for saving own metrics
# Creates writer, writes custom metrics and closes writer
def update_stats(self, **stats):
self._write_logs(stats, self.step)
提醒一下,上面的代码只是为了简化TensorFlow/TensorBoard所做的日志量。通常,每个配置都有一个日志文件,每个步骤都有一个数据点,这很快就变得非常荒谬,随着强化学习(在哪里适合每个步骤!)
让我们添加以下导入:
import tensorflow as tf
import keras.backend.tensorflow_backend as backend
from threading import Thread
在那之后,我们将去我们的脚本底部和:
if __name__ == '__main__':
FPS = 60
# For stats
ep_rewards = [-200]
# For more repetitive results
random.seed(1)
np.random.seed(1)
tf.set_random_seed(1)
# Memory fraction, used mostly when trai8ning multiple agents
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=MEMORY_FRACTION)
backend.set_session(tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)))
# Create models folder
if not os.path.isdir('models'):
os.makedirs('models')
# Create agent and environment
agent = DQNAgent()
env = CarEnv()
首先,我们设置一些FPS值(每秒帧数)。当我们开始的时候,我们会有很高的,这意味着我们很有可能随机选择一个行动,而不是用我们的神经网络预测它。随机选择要比预测操作快得多,所以我们可以通过设置某种一般FPS来任意延迟这一过程。当epsilon为0时,你应该将其设置为你实际的FPS。我们将为可重复的结果设置随机种子,然后指定GPU内存比例。您可能不需要这样做,但我的RTX Titan似乎有问题,至少在Windows上,当它试图分配尽可能多的内存时,运行耗尽。
接下来,我们将创建模型目录(如果它还不存在的话),这就是我们的模型的位置。然后创建代理和环境类。
# Start training thread and wait for training to be initialized
trainer_thread = Thread(target=agent.train_in_loop, daemon=True)
trainer_thread.start()
while not agent.training_initialized:
time.sleep(0.01)
开始训练线程,并等待训练被初始化,正如评论所说的!
# Initialize predictions - forst prediction takes longer as of initialization that has to be done
# It's better to do a first prediction then before we start iterating over episode steps
agent.get_qs(np.ones((env.im_height, env.im_width, 3)))
现在,我们准备开始迭代,不管我们设置了多少集:
# Iterate over episodes
for episode in tqdm(range(1, EPISODES + 1), ascii=True, unit='episodes'):
#try:
env.collision_hist = []
# Update tensorboard step every episode
agent.tensorboard.step = episode
# Restarting episode - reset episode reward and step number
episode_reward = 0
step = 1
# Reset environment and get initial state
current_state = env.reset()
# Reset flag and start iterating until episode ends
done = False
episode_start = time.time()
我们的环境的一些初始值,现在我们可以运行了。基本上,一个环境会一直运行直到它完成,所以我们可以使用一个While True循环并在我们的done标志上中断。
在游戏过程中,我们要么采取随机行动,要么根据代理模型确定当前行动:
# Play for given number of seconds only
while True:
# This part stays mostly the same, the change is to query a model for Q values
if np.random.random() > epsilon:
# Get action from Q table
action = np.argmax(agent.get_qs(current_state))
else:
# Get random action
action = np.random.randint(0, 3)
# This takes no time, so we add a delay matching 60 FPS (prediction above takes longer)
time.sleep(1/FPS)
现在,我们将从环境的.step()方法中获取信息,该方法将我们的action作为参数:
new_state, reward, done, _ = env.step(action)
# Transform new continous state to new discrete state and count reward
episode_reward += reward
# Every step we update replay memory
agent.update_replay_memory((current_state, action, reward, new_state, done))
current_state = new_state
step += 1
if done:
break
一旦我们完成了,我们需要做什么?首先,我们需要摆脱演员:
# End of episode - destroy agents
for actor in env.actor_list:
actor.destroy()
现在,对于一些具有良好奖励的统计数据+保存模型(或任何其他你决定设置为if语句的规则):
# Append episode reward to a list and log stats (every given number of episodes)
ep_rewards.append(episode_reward)
if not episode % AGGREGATE_STATS_EVERY or episode == 1:
average_reward = sum(ep_rewards[-AGGREGATE_STATS_EVERY:])/len(ep_rewards[-AGGREGATE_STATS_EVERY:])
min_reward = min(ep_rewards[-AGGREGATE_STATS_EVERY:])
max_reward = max(ep_rewards[-AGGREGATE_STATS_EVERY:])
agent.tensorboard.update_stats(reward_avg=average_reward, reward_min=min_reward, reward_max=max_reward, epsilon=epsilon)
# Save model, but only when min reward is greater or equal a set value
if min_reward >= MIN_REWARD:
agent.model.save(f'models/{MODEL_NAME}__{max_reward:_>7.2f}max_{average_reward:_>7.2f}avg_{min_reward:_>7.2f}min__{int(time.time())}.model')
接下来让epsilon衰减:
# Decay epsilon
if epsilon > MIN_EPSILON:
epsilon *= EPSILON_DECAY
epsilon = max(MIN_EPSILON, epsilon)
最后,如果我们已经迭代了所有的目标章节,我们就可以退出了:
# Set termination flag for training thread and wait for it to finish
agent.terminate = True
trainer_thread.join()
agent.model.save(f'models/{MODEL_NAME}__{max_reward:_>7.2f}max_{average_reward:_>7.2f}avg_{min_reward:_>7.2f}min__{int(time.time())}.model')
让我们继续播放它,它将播放100集。在泰坦RTX上100集需要17分钟。
你应该有一些日志文件,我们来看看。
tensorboard --logdir=logs/
根据您的操作系统,您需要导航到的内容可能会有所不同。在linux上,无论它告诉您什么(应该在控制台输出中给您一个URL)都应该足够了,可能127.0.0.1:6006也可以工作。在windows上,我发现唯一适合我的是localhost:6006。无论你做什么都要去那里!无论如何,一旦那里,我们可以搜索匹配以下正则表达式的标签:w(任何字母),并看到所有的图形在一起。对我来说,我有:
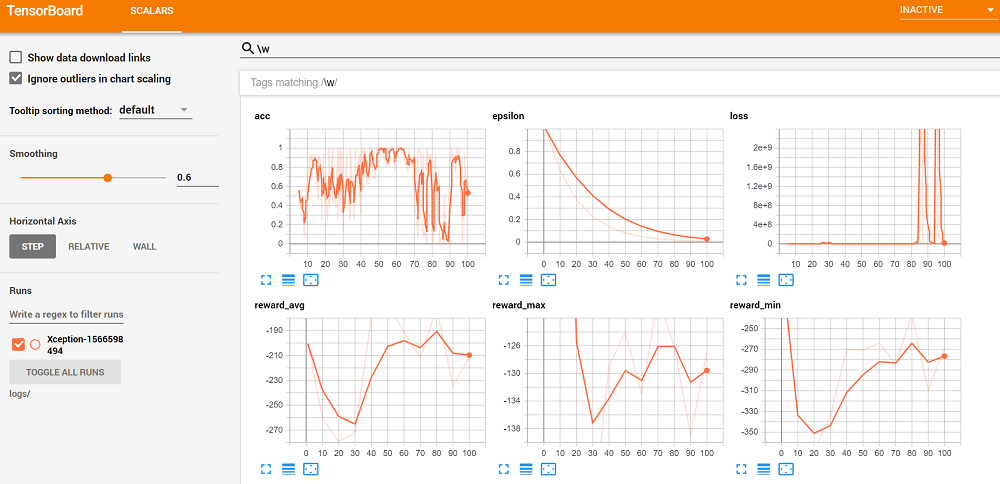
所以,不足为奇的是,我们并没有在100集节目中突然学会如何成为一名出色的司机(从我们的平均回报来看),所以我们可能应该取消那些投资会议,以推介下一家价值数十亿美元的自动驾驶汽车初创公司。
我忘记添加模型了。保存到我第一次测试时的代码中,所以我最终再次运行。这一次,我得到了更好看的结果。主要注意损失是如何从爆炸中恢复过来的。
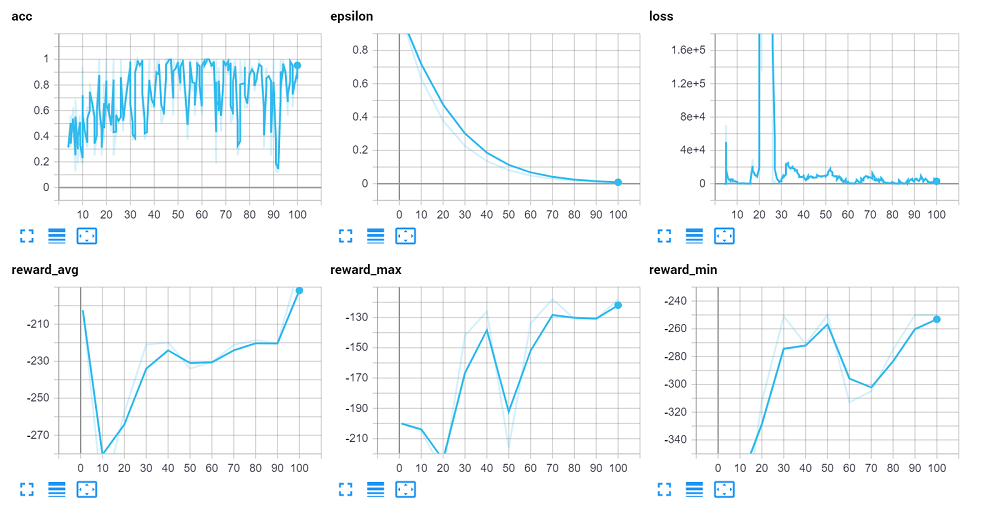
现在,我们只拍了100集。我想我们需要10万集才能看到像样的东西,前提是我们的其他问题也都解决了。也就是说,“看到”您实际的代理运行是有帮助的。所以这里有一个快速的脚本,只是播放和看到你的模型在行动:
import random
from collections import deque
import numpy as np
import cv2
import time
import tensorflow as tf
import keras.backend.tensorflow_backend as backend
from keras.models import load_model
from tutorial5_code import CarEnv, MEMORY_FRACTION
MODEL_PATH = 'models/Xception__-118.00max_-179.10avg_-250.00min__1566603992.model'
if __name__ == '__main__':
# Memory fraction
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=MEMORY_FRACTION)
backend.set_session(tf.Session(config=tf.ConfigProto(gpu_options=gpu_options)))
# Load the model
model = load_model(MODEL_PATH)
# Create environment
env = CarEnv()
# For agent speed measurements - keeps last 60 frametimes
fps_counter = deque(maxlen=60)
# Initialize predictions - first prediction takes longer as of initialization that has to be done
# It's better to do a first prediction then before we start iterating over episode steps
model.predict(np.ones((1, env.im_height, env.im_width, 3)))
# Loop over episodes
while True:
print('Restarting episode')
# Reset environment and get initial state
current_state = env.reset()
env.collision_hist = []
done = False
# Loop over steps
while True:
# For FPS counter
step_start = time.time()
# Show current frame
cv2.imshow(f'Agent - preview', current_state)
cv2.waitKey(1)
# Predict an action based on current observation space
qs = model.predict(np.array(current_state).reshape(-1, *current_state.shape)/255)[0]
action = np.argmax(qs)
# Step environment (additional flag informs environment to not break an episode by time limit)
new_state, reward, done, _ = env.step(action)
# Set current step for next loop iteration
current_state = new_state
# If done - agent crashed, break an episode
if done:
break
# Measure step time, append to a deque, then print mean FPS for last 60 frames, q values and taken action
frame_time = time.time() - step_start
fps_counter.append(frame_time)
print(f'Agent: {len(fps_counter)/sum(fps_counter):>4.1f} FPS | Action: [{qs[0]:>5.2f}, {qs[1]:>5.2f}, {qs[2]:>5.2f}] {action}')
# Destroy an actor at end of episode
for actor in env.actor_list:
actor.destroy()
将导入tutorial5_code重命名为RL代理/env/培训器脚本,然后修改MODEL_PATH = 'models/Xception__-118.00max_-179.10avg_-250.00min__1566603992。你使用的模型,因为你的模型名将与我的不同。
我需要再次强调,这只是100集。但是,我们可以看到代理只学会了做一件事。Agent可能只学习做一件事,因为你的Q值实际上是静态的(模型输出相同的Q值,不管输入),或者,就像我们的例子,它们都是变化的,只是右转总是更高。
我在这里看到的另一件事是,有时左转比直转高,有时直转比左转高。所以还是有希望的。我在《侠盗猎车手5》系列的自动驾驶汽车中学到的一件事是,你可以添加一个输出层权重。
例如,在play脚本中,你可以这样修改qs:
qs = model.predict(np.array(current_state).reshape(-1, *current_state.shape)/255)[0]
qs *= [0.975, 1, 0.92]
action = np.argmax(qs)
这是网络的最后一层。再说一遍,这对100集的模型没有帮助。我们发现的下一件事是,保持奖励为-1和正1可能会更好。没有更多的-200。我们发现这可能会破坏Q值,而这似乎会破坏损失并导致混乱。我们甚至可以做进一步的剪辑。
我们所做的下一个改变是将我们的神经网络简化为一个2-3层的CNN,每个CNN有64-256个功能。还不确定,但越简单越好,需要学习的参数越少。对于完全监督学习,我认为更多的参数更有效,因为一切都是“基本事实”。对于强化学习,我认为对于人工智能来说,要想让自己从愚蠢的洞穴中解脱出来太难了,因为它一开始要尝试训练成千上万的重量。
无论如何,这就是本教程的全部内容。在下一篇教程中,我将为您带来一个工作模型,并告诉您我是如何做到的。
最后
以上就是缥缈毛豆最近收集整理的关于使用 Carla 和 Python 的自动驾驶汽车第 4 部分 —— 强化学习Action的全部内容,更多相关使用内容请搜索靠谱客的其他文章。








发表评论 取消回复