在攻击树的基础上生成简化版的转移矩阵,随后基于深度强化学习来自动化给出渗透测试策略,未来可以根据该策略自动调用渗透测试工具来完成攻击。
Automated Penetration Testing Using Deep Reinforcement Learning
笔记作者:z3r0yu
论文作者:Z.Hu, R.Beuran, Y.Tan @ 日本-先端科学技術研究所 JAIST
项目链接:https://github.com/crond-jaist/AutoPentest-DRL
论文来源:2020 IEEE European Symposium on Security and Privacy Workshops
0x01 主要内容
在攻击树的基础上生成简化版的转移矩阵,随后基于深度强化学习来自动化给出渗透测试策略,未来可以根据该策略自动调用渗透测试工具来完成攻击。
PS: 深度强化学习(DRL,deep reinforcement learning)是深度学习与强化学习相结合的产物,它集成了深度学习在视觉等感知问题上强大的理解能力,以及强化学习的决策能力,实现了端到端学习。深度强化学习的出现使得强化学习技术真正走向实用,得以解决现实场景中的复杂问题。
主要方法:
-
使用Shodan搜索引擎来收集相关的服务器数据,以建立一个现实的网络拓扑结构
-
采用多主机多阶段漏洞分析(MulVAL)来生成该拓扑结构的攻击树
-
使用传统的搜索算法(深度优先搜索)来发现该树中所有可能的攻击路径,并根据深度强化学习算法的需要建立一个矩阵表示
-
采用深度强化学习网络(DQN)方法,以0.86的准确率从可能的候选者中发现最容易利用的攻击路径
个人思考: 为什么要进行自动化的渗透测试?
-
渗透测试的流程基本固定: 信息收集 -> 漏洞利用 -> 渗透系统
-
上述过程费力、费时、复杂的工作,需要大量的隐性知识,不容易被形式化,而且还容易出现人为错误
-
所以,自动化渗透测试一方面可以使攻击进行的更加快速,另一方面可以规范操作者的行为,减少在实际情况中犯错的出现
现有工作:
- Core IMPACT 商业工具,一种根据目标系统生成模型来进行攻击的框架,基于Metric-FF系统的变种来生成攻击方案。
PS:
(1) Metric-FF是一个领域无关智能规划系统。该系统是FF规划器(结合动作描述语言ADL)的扩展,增加了对数值状态变量(numerical state variables)的支持,更加准确的说是增加了对PDDL 2.1 第2层特性的子集的支持。Metric-FF使用C语言开发,它参加了2002年第3届国际智能规划竞赛IPC,具有非常有竞争力的性能表现。
(2) Blackbox是由Henry Kautz开发的一个可满足性智能规划系统,该系统首先将STRIPS型问题转化为布尔可满足性问题(Boolean satisfiability problems),然后使用各种先进的可满足性引擎(satisfiability engines)来求解问题。Blackbox的前端采用的是系统graphplan的修改版本。Blackbox非常具有灵活性,可以指定多种规划求解引擎来进行问题求解,所以Blackbox具有可以在非常大范围种类的规划问题上有效运行的能力。
(3) LPG (Local search for Planning Graphs)是一个基于局部搜索和规划图的规划器,它兼容PDDL2.1。该规划器既能处理规划产生(plan generation)问题,也能处理规划修改(plan adaptation)问题。LPG的搜索空间包含动作图(action graphs)、规划图中表示局部规划的特定子图。
引用:人机混合智能规划平台PS: PDDL2.1是一种支持时态规划和度量规划的语言 。引用: [时态规划综述及研究现状](http://www.x ml-data.org/GDGYDXXB/html/1615527673997-884046199.htm)
-
1999年Schneier提出了一种对特定系统的安全威胁进行建模的方法,并以树状结构的形式表示对它的攻击,通过分析攻击树,来更好地了解每种攻击方法之间的关系。
-
2018年Yousefi应用强化学习(RL)来分析攻击树,它使用Q-learning来发现攻击路径,但它仍然存在行动空间和样本空间太小的问题。
-
2020年此文采用与强化学习相比,更适合分析攻击树的深度强化学习(DRL)方法,因为它结合了深度学习和强化学习,并采用了试错法来找出最优解。
0x02 背景知识
A. Shodan
互联网连接设备的在线搜索引擎,此研究Shodan来收集所需的信息,以建立真实的网络拓扑结构。之后使用这些网络拓扑信息将被用来作为下面介绍的MulVAL算法的输入。
B. 攻击树
1)攻击树模型: 表达攻击行为和攻击步骤之间的相互依存关系,具有实现攻击过程的正规化和文档化功能的模型。树的每个节点代表一个攻击行为或一个子目标,根节点代表攻击的最终目标。每个子节点代表一个攻击行为或一个子目标,在父节点被攻击之前应该完成。
攻击树的节点分为 “AND “节点和 “OR “节点。标签 “AND “意味着一个节点只有在所有子节点被攻击后才能被攻击。标签 “OR “表示,只要有一个子节点被攻击,父节点也可以被攻击。在图1中,展示了 “AND “和 “OR “这两种可能的节点类型的图形和文字表述。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kuWI4Vtp-1632838134261)(https://www.shuijiaxian.com/files_image/20230308/133801292246.png)]
2)MulVAL: MulVAL是一个开源工具,用于生成与给定网络拓扑结构相对应的实际攻击树。根据网络拓扑结构的特性,已经证明攻击树生成算法的复杂度在 O( n^2 ) 和 O( n^3 ) 之间,因此对于有几十台主机的典型中小型公司网络是合理的。在此框架中,MulVAL被用来为一个给定的输入网络拓扑结构找到所有可能的路径,根据发现的所有可能的路径建立一个矩阵,然后使用深度优先搜索(DFS)算法对其进行简化,使其更适合用于DRL算法。
PS: MulVAL 使用 Datalog 语言作为模型语言(包括漏洞描述,规则描述,配置描述,权限系统等)。其将 Nessus/OVAL 扫描器报告、防火墙管理工具提供的网络拓扑信息、网络管理员提供的网络管理策略等转化为 Datalog 语言的事实作为输入,交由内部的推导引擎进行攻击过程推导。推导引擎由 Datalog 规则组成,这些规则捕获操作系统行为和网络中各个组件的交互。最后由可视化工具将推导引擎得到的攻击树可视化形成攻击图。
除此之外,还有TVA (topological vulnerability analysis) ,一种具有多项式级时间复杂度的攻击图生成工具,可用于对网络渗透进行自动化分析,其输出结果为由攻击步骤和攻击条件构成的状态攻击图。该工具需要通过手工输入建立规则库。同时该工具未能解决状态攻击图固有的状态爆炸问题,在复杂网络中生成的攻击图极大,不利于分析。复杂度为O(n^2)
NetSPA (network security planning architecture) 由 Lippmann 提出,是一种基于图论的攻击图生成工具。目前,该工具已得到美国政府支持,成为一款商业软件。该工具使用防火墙规则和漏洞扫描 结果构建网络模型,并依此计算网络可达性和攻击 路径。由于缺少攻击模式学习功能,其规则库的建立需要依赖于手工输入。生成的攻击图中包含环 路,不利于使用者理解。复杂度为O(nlogn)。由于展示的攻击图不够直观,在 NetSPA 的基础上又推出了 NAVIGATOR 和 GARNET 两款增强图像显示效果的工具。
引用:攻击图技术 Attack Graph Technique (mekakuactor.cn)
C. Reinforcement Learning
强化学习(RL)是一种将环境状态映射到行动的学习方法,从而使代理在与环境互动的过程中获得最大的累积奖励。作为一种交互式学习方法,RL的主要特点是试错和延迟回报。RL代理试图确定能够提供与任何给定环境状态相对应的行动的策略,其最终目标是发现一个最佳策略,以便获得最大的累积奖励。
图2显示了代理和环境之间的互动过程。在每个时间步骤t,代理观察环境以获得状态St,然后执行行动At。环境产生新的状态St+1和奖励Rt,取决于At。这样一个过程可以用马尔科夫决策过程(MDP)来描述。一个MDP分为4个部分,也称为四边形,用(S, A, P, R)表示,其中S代表状态集;A代表行动集;P(s’|s,a)代表在状态s中采取行动a后过渡到s’的概率;R(s, a)代表在状态s中采取行动a得到的奖励。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dT606imQ-1632838134264)(https://www.shuijiaxian.com/files_image/20230308/133801360329.png)]
该策略的目标是使未来的累积奖励最大化,也就是说,当前状态的 “质量 “可以通过该状态的未来累积奖励来衡量。强化学习引入了一个奖励函数来计算任何特定时间t的奖励。
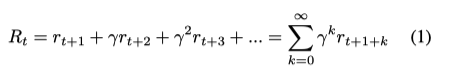
其中γ是折扣系数。由于离当前状态越远,奖励值的不确定性就越大,所以γ通常被用来说明这种不确定性。
此外,价值函数的概念被用来表示一个状态的 “价值”,即对该状态的未来累积奖赏的期望。
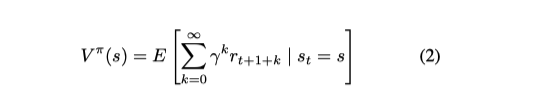
此外,行动(a)-状态(s)价值函数被用来表达以状态和行动为条件的未来累积奖赏。
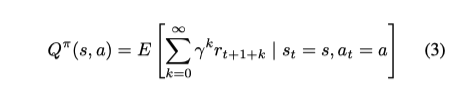
D. 深度强化学习
深度强化学习(DRL)指的是一类结合了深度学习和强化学习的技术。DRL是一种通用的学习方法,”代理 “从环境中获得状态信息,根据自己的策略选择适当的行动,改变环境的状态,然后根据新的环境状态获得奖励或激励,表达行动对代理的有效性。当把DRL应用于渗透测试时,代理就扮演着pentester的角色,并选择最有效的路径以获得最大的奖励。
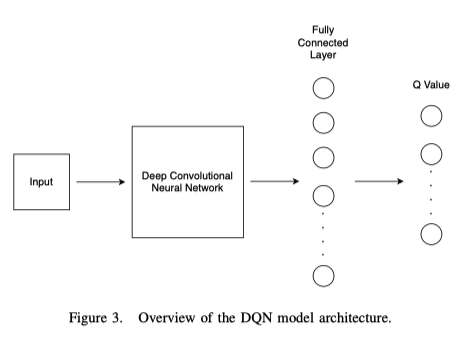
DRL算法主要分为三类:基于价值的函数、基于策略的搜索和基于模型的方法。深度Q-Learning网络(DQN)是Mnih等人, 提出的一种具有代表性的基于价值的方法,它将卷积神经网络(CNN)与传统强化学习中的Q-学习算法相结合,建立了新的DQN模型。DQN模型的输入是一个简化的矩阵,经过3个卷积层和2个完全连接层的非线性转换,最终在输出层为每个动作生成一个Q值。图3显示了DQN模型的结构。
在图4中,展示了DQN的训练过程,它改进了传统的Q-learning算法,以缓解非线性网络的表示函数的不稳定性等问题。例如,DQN使用经验回放来处理转移样本。在每个时间步骤t,由代理与环境交互获得的转移样本被存储在重放缓冲单元中。在训练过程中,随机选择一小批转移样本,并使用随机梯度下降(SGD)算法来更新网络参数θ。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dt3s2JAS-1632838134273)(https://www.shuijiaxian.com/files_image/20230308/1338012405319.png)]
DQN还修改了计算Q值的方式。因此,在DQN中,Q(s, a | θi)代表当前价值网络的输出,它被用来评估当前状态行动的价值函数。Q(s, a | θi )代表目标值网络的输出,而Yi = r + γ * max Q(s’ , a’ | θi )一般被作为目标Q值。
当前价值网络的参数θ是实时更新的。在每N轮迭代之后,当前值网络的参数被复制到目标值网络中。然后通过最小化当前Q值和目标Q值之间的均方误差来更新网络参数。误差函数为:
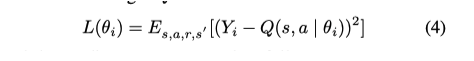
而梯度的计算方法如下:
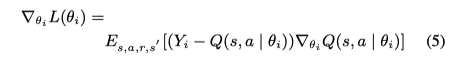
0x03 框架结构
该框架有三个主要部分:
-
训练数据生成: 建立DQN算法所需的训练数据作为输入
-
DQN模块: 使用DQN算法进行训练,然后使用训练好的模型来自动化的给出渗透测试建议
-
渗透工具: 封装用于在真实系统上进行渗透测试操作的外部工具
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RnRXk84A-1632838134277)(https://www.shuijiaxian.com/files_image/20230308/1338011489325.png)]
A. Training Data
使用深度学习的关键是要有训练数据。此文创建训练数据以提供给DQN模型的方法包括三个步骤。
-
使用Shodan来收集网络信息,为现实的网络环境建模
-
使用MulVAL来创建对应于该网络环境的攻击树
-
对数据进行预处理,以使其适合用于DQN模型
1)主机数据集。为了建立训练数据,此处首先使用Shodan来收集真实网络设备的信息(Shodan API将返回包括实际IP地址、使用的端口和协议、已知漏洞等真实网络服务器的相关数据。)。图6显示了通过Shodan收集的原始数据的一个例子(敏感信息,如IP地址,等信息)。

对于每个不同的服务,此处会创建一个单独的服务数据集文件,其中包含所有关于运行该服务的特定网络主机的相关信息。为了保护隐私,在展示所收集的数据的时候,此处只保留开放的端口或服务名称等信息。表1显示了一些网络服务器配置文件的例子。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TABtFVB7-1632838134280)(https://www.shuijiaxian.com/files_image/20230308/1338013245029.png)]
- 漏洞数据集。除了主机数据集之外,此处还创建了一个漏洞数据集文件。对于一组已知的漏洞,漏洞数据集包括CVE和微软的漏洞识别号,以及CVSS评分的类型、基础分和可利用性评分部分。为了包括我们所需要的所有相关信息,我们将国家漏洞数据库(NVD)和微软(MS)数据库的信息结合起来,创建一个新的数据集。表2显示了构建的漏洞数据集中的一些项目。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3uzaC6FL-1632838134281)(https://www.shuijiaxian.com/files_image/20230308/1338018374431.png)]
3)DQN数据集。DQN数据集是深度Q-Learning网络的训练数据集,包括Shodan收集的主机数据集和漏洞数据集。为了生成DQN算法所需的数据集,首先需要为一组给定的网络拓扑结构创建攻击树。
为此,此处创建了一系列的网络拓扑模板,用主机数据集的实际数据来填充。图7显示了一个网络服务器漏洞配置的例子模板。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IFXP3tjR-1632838134282)(https://www.shuijiaxian.com/files_image/20230308/1338016589933.png)]
从这个例子我们可以知道,vulExists来自Shodan,它显示目标是一个存在CAN-2002-0392漏洞的网络服务器。vulProperty来自Vulnerability dataset,显示CAN-2002-0392的类型是远程利用,它可以引起权限升级的效果。这个详细的网络拓扑信息被MulVAL用来生成与该拓扑结构相对应的攻击树。本文后面的图8和图9分别显示了一个网络拓扑结构的例子,以及为该拓扑结构生成的攻击树。
接下来,攻击树必须被转换为转移矩阵。Yousefi等人首次提出了一种将攻击树转换为传输矩阵的方法,但它并不适合渗透测试,因为在渗透测试过程中,除了漏洞之外,其他步骤,如文件访问、命令执行等也很重要。为此,本文提出了一种改进的方法,将攻击树转换为简化的转移矩阵。第一步,我们将攻击树中的所有节点映射为矩阵形式,其中包括漏洞的CVSS评分信息,以及其他行动(如访问文件)的一些预先设定的分数。在下一步,使用深度优先搜索(DFS)算法来简化这个矩阵,而不是直接将其输入DQN算法。核心思想是,完整的转移矩阵显示了所有可能的动作,但如果我们只选择那些可以用来达到攻击目标的动作,它就可以被简化。
Q: 只有攻击行为相互关联,攻击链才能够成立,作者就是利用这一点来对矩阵进行简化
因此,我们使用DFS算法找到所有可能到达目标的路径,然后创建一个简化的矩阵,其中包括 (i)第一列中的起始节点的分数;(ii)中间列中的中间步骤的总分数;(iii)最后一列中的目标节点的分数。这些分数将被进一步用作DQN算法中的奖励分数。
B. DQN
在我们的框架中,DQN被用来通过DQN模型的连续训练来确定最可行的攻击路径。该模型的输入是上述的简化矩阵,对于激活函数,我们使用了softmax函数。DQN模型的输出是最佳攻击路径。在学习过程中,DQN模型一个agent就代表一个攻击者,目标环境由简化的攻击矩阵来模拟。攻击者可以在攻击矩阵中从一个节点移动到另一个节点,直到到达最终目标—目标服务器。
利用DQN模型中使用的每个漏洞所对应的奖励是由我们根据通用漏洞评分系统(CVSS)的组成部分所确定的漏洞得分来计算的。
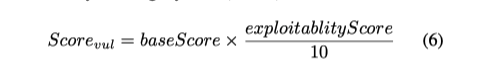
在CVSS中,基础分反映了漏洞本身的危害性,而可利用性分则反映了利用该特定漏洞的可行性。因此,我们使用最高值为10的可利用性分数来权衡基本分数的重要性,考虑使用某个漏洞的可行性。
C. Penetration Tools
为了使自动渗透测试框架能够用于对真实系统进行攻击,它需要与实际的网络环境进行交互,例如运行命令、利用漏洞等等的能力。在这个阶段,我们决定利用现有的渗透测试工具,如M etasploit,而不是建立我们自己的工具,此处与CyPROM采取的方法类似。
虽然这一功能的实现仍在进行中,但我们会在不久的将来将其与框架的其他部分一起发布。我们的方法是为渗透测试工具创建一个封装器,这样,如上所述训练的DQN模型的结果可以用来向这些渗透工具发送命令,这些工具将对真实的目标系统进行操作。这些行动的结果作为反馈被接收,并被用来决定如何进行特定的攻击路径。
IV. EXPERIMENTAL RESULTS
A. Experiment Scenario
图8显示了在实验中采用的网络拓扑结构模型。该模型代表了一个小型的公司网络,包括一个网络服务器、一个文件服务器和一个工作站。文件服务器和工作站在一个子网中,通过一个路由器连接到一个防火墙。网络服务器在另一个子网中,通过防火墙与互联网连接。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4y9PgDYK-1632838134284)(https://www.shuijiaxian.com/files_image/20230308/1338015031137.png)]
从攻击的角度来看,他们对攻击方法做了以下假设。
-
攻击者从互联网开始,可以通过HTTP和HTTPS协议访问Web服务器。
-
文件服务器和网络服务器可以通过NFS、FTP等文件协议相互连接。
-
文件服务器和工作站可以通过NFS、Samba等文件协议相互连接。
-
文件服务器和工作站可以通过HTTP和HTTPS协议访问互联网。
为了确定实际的协议细节,他们使用Shodan收集的数据来初始化网络服务器和文件服务器的漏洞、开放端口、产品和协议等信息。至于工作站,则认为它没有运行任何服务,而只是使用各种传输协议。表3显示了这些主机的网络信息配置的例子。
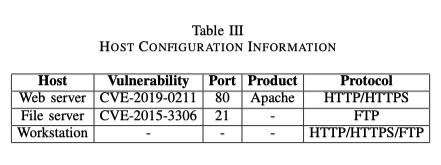
漏洞数据集被用来给每个漏洞附加详细信息,包括其类型和影响(如利用该漏洞可以实现的权限级别)。对于每个不同的漏洞类型,攻击树算法将产生不同的攻击路径。在表4中,给出了一些在此处场景中遇到的漏洞类型的例子。

Q: 这里其实作者应该是把问题进行简化了,分析问题都是站在假设 Shodan 已经将所有的信息都收集完毕了的基础之上,重点是在攻击路径的选取上面做工作。
B. DQN Dataset Generation
根据前面讨论的网络拓扑结构和配置信息,MulVAL被用来生成相应的攻击树。图9显示了为示例场景生成的攻击树的主要部分,每个节点都被标记了关于如何利用某个漏洞的简短描述。在这个例子中,攻击者从互联网开始,由位于图中顶部中心的节点26代表。攻击者的目标是在位于图中左上方的节点1所代表的工作站上执行代码。我们假设攻击者可以沿着箭头的方向移动,直到达到攻击目标。
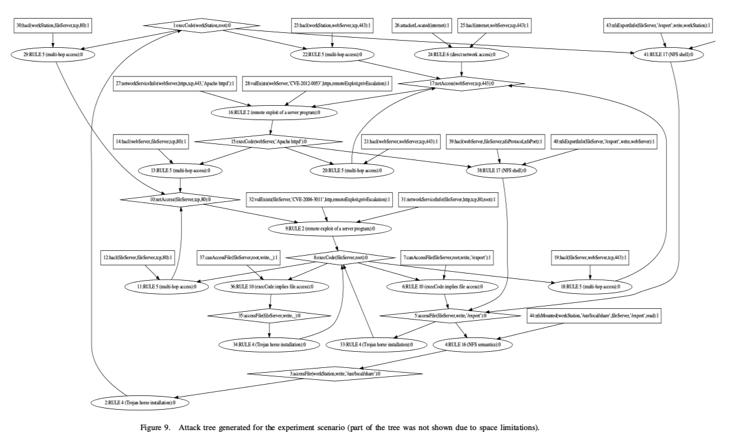
为了建立DQN算法所需的转移矩阵,需要给每个节点分配一个奖励分数,如下所示。
1)起始节点(此处例子中的节点26)的奖励值是0.01,目标节点(此处例子中的节点1)的奖励分数是100。
2)对于每一个利用漏洞的节点(如此处例子中的节点16,利用节点28的CVE-2012-0053漏洞),我们使用公式6中定义的Score vul值作为奖励分数。
3)对于每一个执行代码或访问文件的节点(在此处例子中用execCode和accessFile表示),此处设定一个1.5分的奖励分数,因为在渗透测试过程中,这种行为是很重要的(目标节点1不在此规则之内)。
4)对于树上的任何其他节点,此处的奖励分数为0,如果两个节点之间没有路径,奖励分数为-1。
C. DQN Training Results
上述简化矩阵成为DQN模型的输入,然后进行训练以确定所有可能路径的总回报。对于本文提出的网络拓扑结构,他们在训练模板中使用了具有不同漏洞的Shodan数据,从而创造了总共2000个不同的攻击树作为训练数据,以及1000个不同的攻击树作为验证数据。为验证起见,他们确定简化矩阵中的最佳路径是选择最高奖励时的最小步骤数。表5中提供了最佳攻击路径的模型准确度和平均步骤数。从这些结果中可以看出,对于这个网络拓扑结构样本,该模型在找到最可行的路径方面有很好的表现。
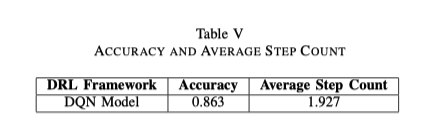
图10显示了DQN模型在总共100次训练迭代过程中对实验场景中的一条攻击路径的平均奖励变化。我们可以注意到,奖励在一开始是很小的,然后在大约30次迭代后逐渐上升。大约60次迭代后,奖励变得稳定,这意味着DQN模型已经找到了最优路径。在这种情况下,该路径由 “26→24→17→16→15→13→10→9→8→6→5→4→3→2→1 “的步骤序列给出(参见图9)。这条路径不仅充分利用了网络服务器和文件服务器的漏洞,而且还采用了简单的攻击方法,便于通过渗透测试工具使用。
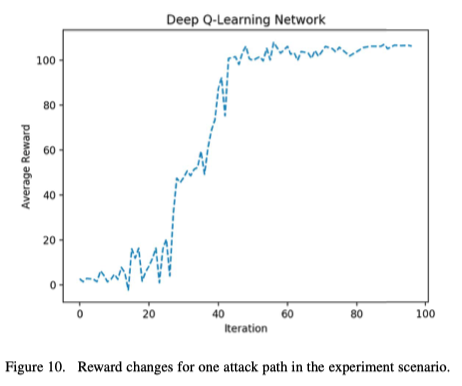
图10. 实验场景中一个攻击路径的奖励变化。
D. Discussion
虽然DQN算法在使用几个样本网络拓扑结构时似乎收敛得比较快,但我们认为还需要做更多的工作来确定在具有不同属性的大量场景中DQN模型的正确参数选择。
虽然本文设计的框架是用于实际系统的自动渗透测试,但到目前为止,他们只对通用网络拓扑模型进行了训练。作为下一步,他们考虑将扫描特定的实际网络拓扑结构的结果作为训练模型反馈给DQN算法,这样它就可以评估该拓扑结构的特殊性,并为该拓扑结构提出最佳攻击路径。
DQN算法确定的最可行的攻击路径上的每个节点都包含有效进行该步骤攻击所需的所有信息。因此,路径和节点信息可以用来驱动渗透测试工具的执行,如M etasploit,以进行该攻击。例如,知道节点28代表CVE-2012-0053漏洞,该框架可以向M etasploit发送一个命令,并使用内部模块msf exploit来利用网络服务器的漏洞。我们计划在III-C节中提到的渗透工具模块中利用这一点。
此框架的意义:
-
用于攻击培训活动,例如建议攻击路径,然后受训者可以在网络范围内按照指导性学习方法自己进行实验
-
自动化的方式进行现实的攻击(完成了渗透工具模块之后)。这将降低组织防御培训活动的成本,因为不再需要白帽黑客的支持来进行这种攻击。重复开展采用现实攻击方法的培训活动,将使参与者的防御技能得到明显的提高。
V. CONCLUSION
这篇文章提出了一个自动渗透测试框架,该框架基于深度强化学习技术,特别是深度Q-Learning网络(DQN)。他们的方法创新性地将Shodan搜索引擎与各种漏洞数据集结合起来,收集真实的主机和漏洞数据,用于构建真实的训练和验证场景。然后,攻击树方法被用来为每个训练场景生成攻击信息,然后对其进行处理并用于训练DQN模型。训练使用主要基于CVSS评分信息分配给每个节点的奖励分数,以确定给定网络场景中最可行的攻击路径。
他们的实验用真实的主机和漏洞数据填充给定的网络拓扑,构建了2000个训练场景和1000个验证场景。即使是少量的训练数据,DQN在确定最佳攻击路径方面也能达到0.86的准确率,并在其他情况下提供了符合我们预期的可行攻击路径。
未来工作:
-
计划用更多的网络拓扑结构来扩展训练数据集,从而提高DQN模型的通用性和稳定性。
-
考虑将网络服务扫描功能整合到框架中,这样就可以将真实的目标环境信息自动提供给DQN模型,从而使实际网络拓扑结构的结果更加准确。
最后
以上就是土豪冬日最近收集整理的关于记一次自动化渗透测试的学习研究Automated Penetration Testing Using Deep Reinforcement Learning的全部内容,更多相关记一次自动化渗透测试的学习研究Automated内容请搜索靠谱客的其他文章。








发表评论 取消回复