引言
经典的卷积神经网络(ConvNet)VGG [31]在图像识别中取得了巨大的成功,其简单的架构由conv、ReLU和池化的堆栈组成。随着Inception [33,34,32,19]、ResNet [12]和DenseNet [17]的出现,许多研究兴趣转向了设计良好的架构,使得模型越来越复杂。一些最近的架构基于自动[44,29,23]或手动[28]架构搜索,或搜索的复合缩放策略[35]。
尽管许多复杂的ConvNet比简单的ConvNet具有更高的精度,但缺点也很明显
- 复杂的多分支设计(例如,ResNet中的跳跃连接和Inception中的分支级联)使得模型难以实现和定制,减慢了推理速度,降低了内存利用率
- 一些组件(例如,Xception [3]和MobileNets [16,30]中的深度卷积和ShuffleNet [24,41]中的通道重排)增加了存储器访问成本,并且缺乏对各种设备的支持。由于影响推理速度的因素太多,浮点运算(FLOPs)的数量并不能精确地反映实际速度。
由于多分支结构的优点都是用于训练,而缺点是不希望用于推理,因此我们提出通过结构重新参数化来解耦训练时多分支结构和推理时普通结构,即通过变换其参数将结构从一种转换到另一种.具体而言,网络结构与一组参数相耦合,Conv层由4阶核张量表示。如果某个结构的参数可以转换成另一个结构耦合的另一组参数,我们就可以用后者等价地替换前者,从而改变整个网络架构
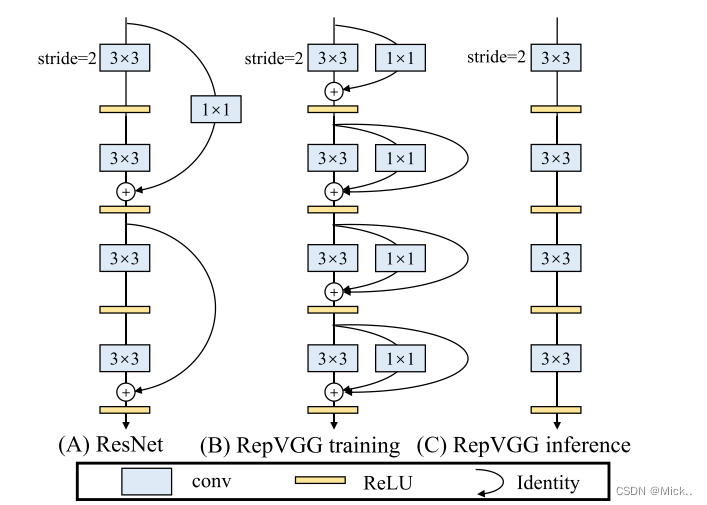
相关工作
从单路径到多分支
在VGG [31]将ImageNet分类的前1位准确率提高到70%以上之后,在使ConvNet复杂化以获得高性能方面出现了许多创新,例如:当代的GoogleNet [33]和后来的Inception模型[34,32,19]采用了精心设计的多分支体系结构,ResNet [12]提出了简化的两分支体系结构,而DenseNet [17]通过将低层与许多高层连接起来使拓扑结构更加复杂。神经结构搜索(NAS)[44,29,23,35]和手工设计空间设计[28]可以生成具有更高性能的ConvNet,但代价是大量的计算资源或人力。
方法
快速,节省内存,灵活
许多最近的多分支体系结构的理论FLOPs比VGG低,但运行速度可能不会更快。有两个重要因素对速度有相当大的影响,但flop没有考虑到:内存访问成本(MAC)和并行度。
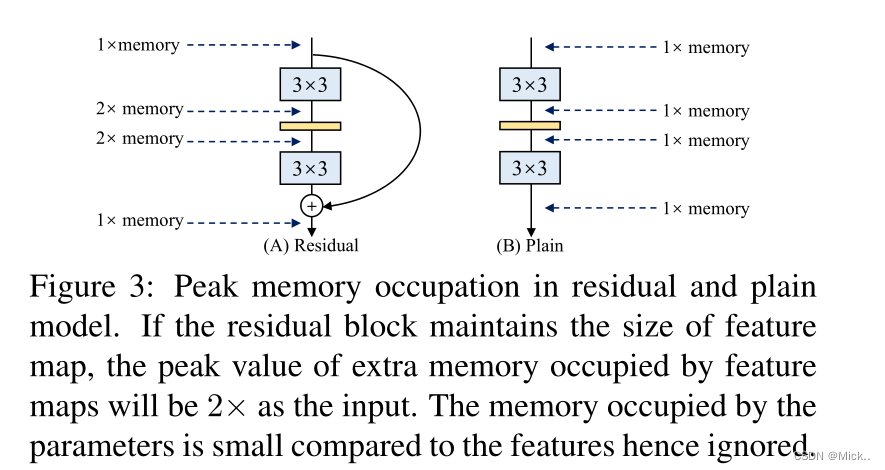
结构重参数化
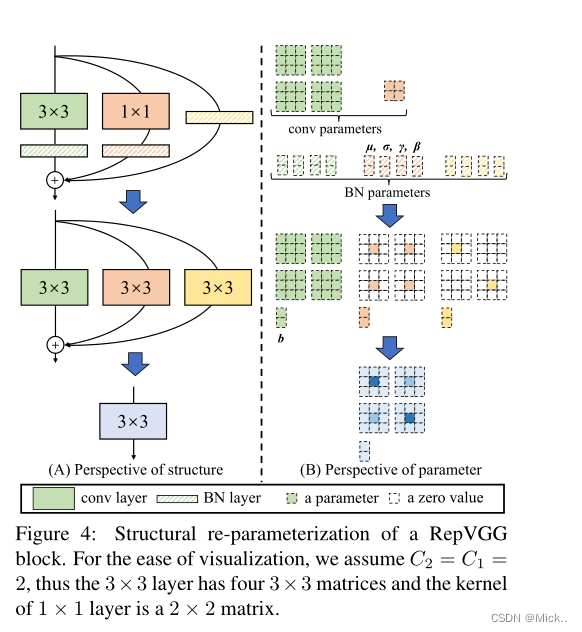
上图展现了各个算子的融合过程
总结:单一的简单模型性能较差,多分支模型性能好、但是效率比较低。作者的想法是模型在多分支的情况下进行训练,然后在测试的时候转换为单一的简单模型。
Conv2d+BN融合实验
from collections import OrderedDict
import numpy as np
import torch
import torch.nn as nn
def main():
torch.random.manual_seed(0)
f1 = torch.randn(1, 2, 3, 3)
module = nn.Sequential(OrderedDict(
conv=nn.Conv2d(in_channels=2, out_channels=2, kernel_size=3, stride=1, padding=1, bias=False),
bn=nn.BatchNorm2d(num_features=2)
))
module.eval()
with torch.no_grad():
output1 = module(f1)
print(output1)
# fuse conv + bn
kernel = module.conv.weight
running_mean = module.bn.running_mean
running_var = module.bn.running_var
gamma = module.bn.weight
beta = module.bn.bias
eps = module.bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1) # [ch] -> [ch, 1, 1, 1]
kernel = kernel * t
bias = beta - running_mean * gamma / std
fused_conv = nn.Conv2d(in_channels=2, out_channels=2, kernel_size=3, stride=1, padding=1, bias=True)
fused_conv.load_state_dict(OrderedDict(weight=kernel, bias=bias))
with torch.no_grad():
output2 = fused_conv(f1)
print(output2)
# np.testing.assert_allclose(output1.numpy(), output2.numpy(), rtol=1e-03, atol=1e-05)
# print("convert module has been tested, and the result looks good!")
if __name__ == '__main__':
main()
RepVGG
import time
import torch.nn as nn
import numpy as np
import torch
def conv_bn(in_channels, out_channels, kernel_size, stride, padding, groups=1):
result = nn.Sequential()
result.add_module('conv', nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
groups=groups, bias=False))
result.add_module('bn', nn.BatchNorm2d(num_features=out_channels))
return result
class RepVGGBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3,
stride=1, padding=1, dilation=1, groups=1, padding_mode='zeros', deploy=False):
super(RepVGGBlock, self).__init__()
self.deploy = deploy
self.groups = groups
self.in_channels = in_channels
self.nonlinearity = nn.ReLU()
if deploy:
self.rbr_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups,
bias=True, padding_mode=padding_mode)
else:
self.rbr_identity = nn.BatchNorm2d(num_features=in_channels)
if out_channels == in_channels and stride == 1 else None
self.rbr_dense = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, groups=groups)
self.rbr_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=stride, padding=0, groups=groups)
def forward(self, inputs):
if hasattr(self, 'rbr_reparam'):
return self.nonlinearity(self.rbr_reparam(inputs))
if self.rbr_identity is None:
id_out = 0
else:
id_out = self.rbr_identity(inputs)
return self.nonlinearity(self.rbr_dense(inputs) + self.rbr_1x1(inputs) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'rbr_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.rbr_reparam = nn.Conv2d(in_channels=self.rbr_dense.conv.in_channels,
out_channels=self.rbr_dense.conv.out_channels,
kernel_size=self.rbr_dense.conv.kernel_size, stride=self.rbr_dense.conv.stride,
padding=self.rbr_dense.conv.padding, dilation=self.rbr_dense.conv.dilation,
groups=self.rbr_dense.conv.groups, bias=True)
self.rbr_reparam.weight.data = kernel
self.rbr_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_dense')
self.__delattr__('rbr_1x1')
if hasattr(self, 'rbr_identity'):
self.__delattr__('rbr_identity')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
self.deploy = True
def main():
f1 = torch.randn(1, 64, 64, 64)
block = RepVGGBlock(in_channels=64, out_channels=64)
block.eval()
with torch.no_grad():
output1 = block(f1)
start_time = time.time()
for _ in range(100):
block(f1)
print(f"consume time: {time.time() - start_time}")
# re-parameterization
block.switch_to_deploy()
output2 = block(f1)
start_time = time.time()
for _ in range(100):
block(f1)
print(f"consume time: {time.time() - start_time}")
np.testing.assert_allclose(output1.numpy(), output2.numpy(), rtol=1e-03, atol=1e-05)
print("convert module has been tested, and the result looks good!")
if __name__ == '__main__':
main()
参考文献
DingXiaoH/RepVGG: RepVGG: Making VGG-style ConvNets Great Again (github.com)
RepVGG网络简介_太阳花的小绿豆的博客-CSDN博客_repvgg网络简介
最后
以上就是真实高山最近收集整理的关于RepVGG:让VGG风格的ConvNet再次伟大起来引言相关工作方法的全部内容,更多相关RepVGG:让VGG风格内容请搜索靠谱客的其他文章。








发表评论 取消回复