文章目录
- 应用层概述
- 域名和DNS
- 域名结构
- 域名服务器的分类
- 文件传送协议
- FTP的工作原理
- FTP传输方式
- FTP匿名服务器
- 电子邮件协议
- 电子邮件的组成结构
- SMTP
- MIME
- POP3
- IMAP
- HTTP
- 万维网
- URL
- HTTP概述
- HTTP报文结构
- 请求方法
- 状态码
- 首部行字段
- Cookie和Session
- HTTPS
- 加密方式
- 补充知识
- 证书
应用层概述
应用层是OSI模型中的最高层。它为应用程序的通信提供服务并且规定应用程序在通信时的协议。
应用层协议定义的内容:
- 1、应用程序的报文类型,是请求还是响应?
- 2、各种报文类型的语法,例如各报文中的各个字段及其详细描述
- 3、字段的语义(包含在字段中的信息的含义)
- 4、进程何时发送、如何发送报文,以及对报文进行响应的规则。
应用层的功能:
- 文件的传输、访问和管理
- 电子邮件
- 虚拟终端
- 查询服务和远程作业登录
应用层的重要协议:
- FTP
- SMTP、POP3
- HTTP
- DNS
域名和DNS
用户和因特网上的某个主机进行通信的时候,IP地址是难以记忆的。不要妄图将需要通信的主机IP地址记住,因为不可能只和一台主机进行通信(而且一台主机可能会有多个IP地址)。所以用户更愿意去叫主机的名字。类似于日常生活中,人们不会去特意地记忆和称呼对方的身份证号,而是去叫对方的名字。
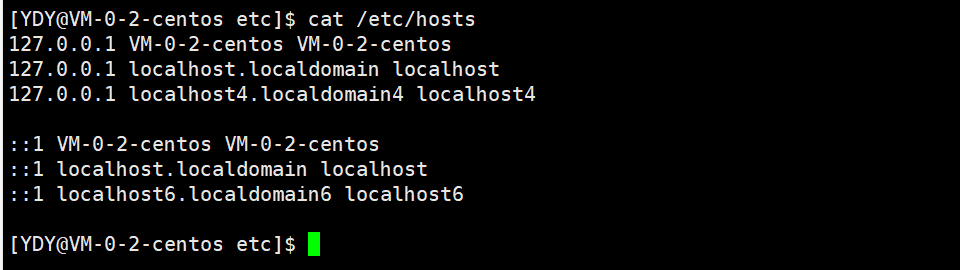
早在21世纪以前,使用一个名为hosts的文件存储着IP地址与主机名的一一对应关系,到现在还依然沿用。
Linux系统中也有hosts文件。可使用命令cat /etc/hosts可以查看
在局域网中,主机名基本上都是不同的。但在整个因特网中可能会出现主机名相同的情况,为了能够在整个因特网中标识唯一一台主机,所以引入了域名。域名是包含了主机名和该主机所属组织机构的一种分层结构的名字。
//一个域名
www.baidu.com
DNS域名系统是互联网的一项服务,它被设计成一个域名和IP地址相互映射的联机分布式数据库系统,采用客户服务器方式。主要作用是将域名解析成IP地址(由域名系统中的域名服务器完成)。
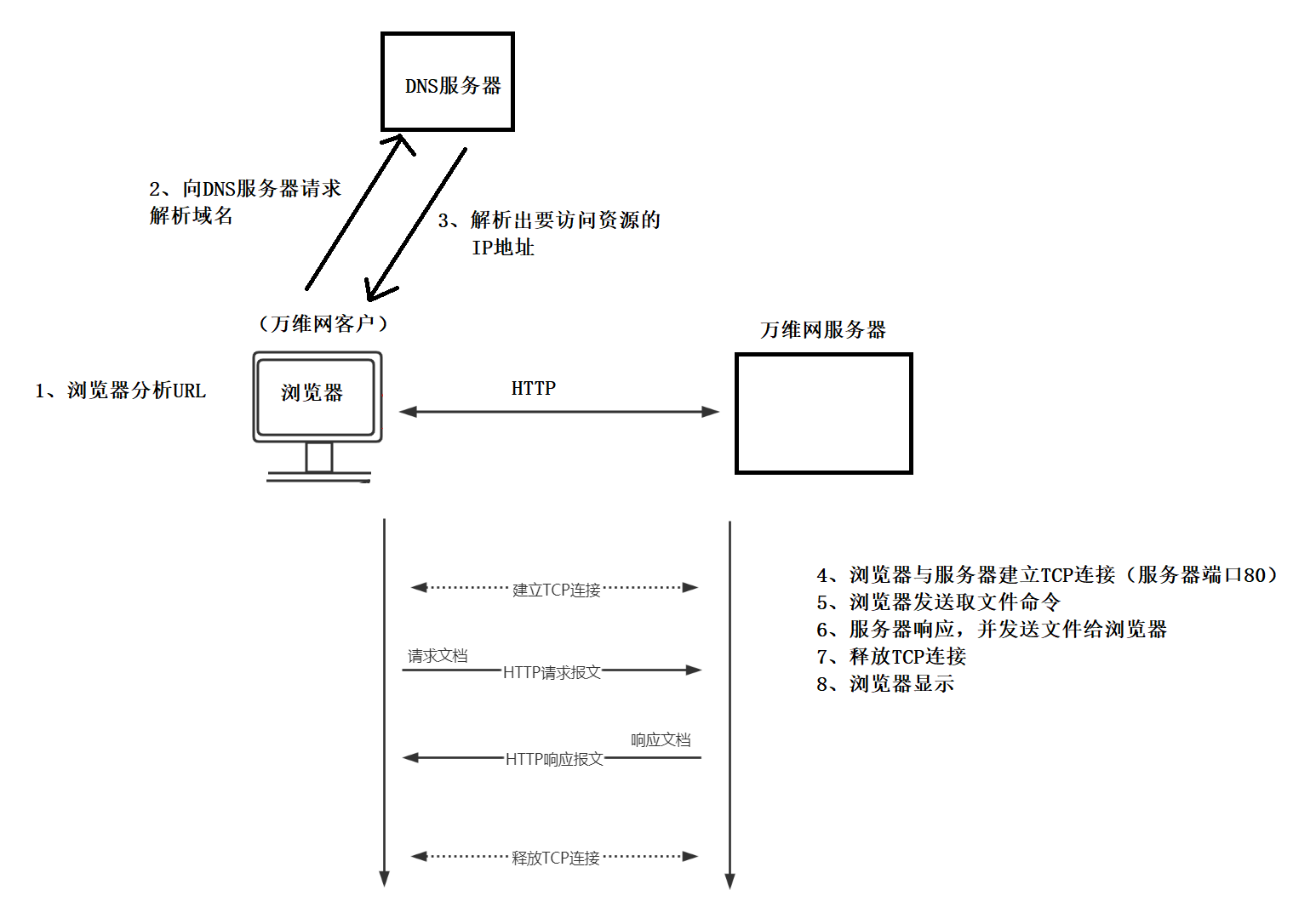
主机通过域名访问的过程
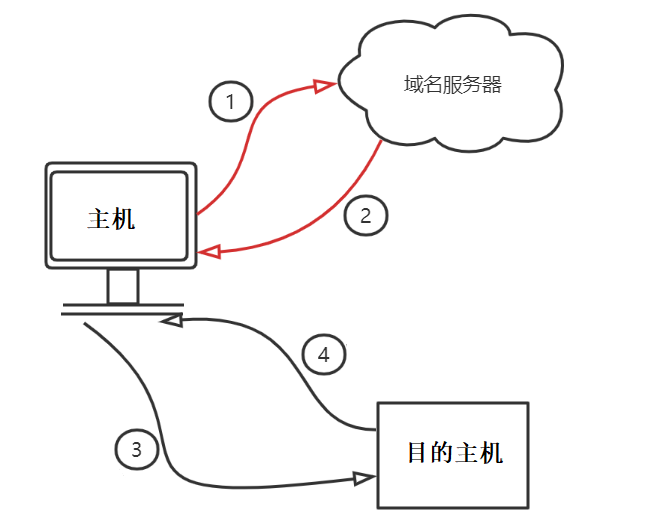
首先是一台主机得到了一个需要访问的域名,其次:
【第一步】:应用进程调用解析程序,成为DNS的一个客户,把该域名放入DNS请求报文,以UDP用户数据报方式发送给域名服务器。
【第二步】:域名服务器查找域名和域名对应的IP地址,并将IP地址放在回答报文中,返回给客户。
【第三步】:应用进程获得目的主机的IP地址,开始进行和目的主机的通信,发送请求报文给目的主机。
【第四步】:目的主机提供服务,发送响应报文给主机。
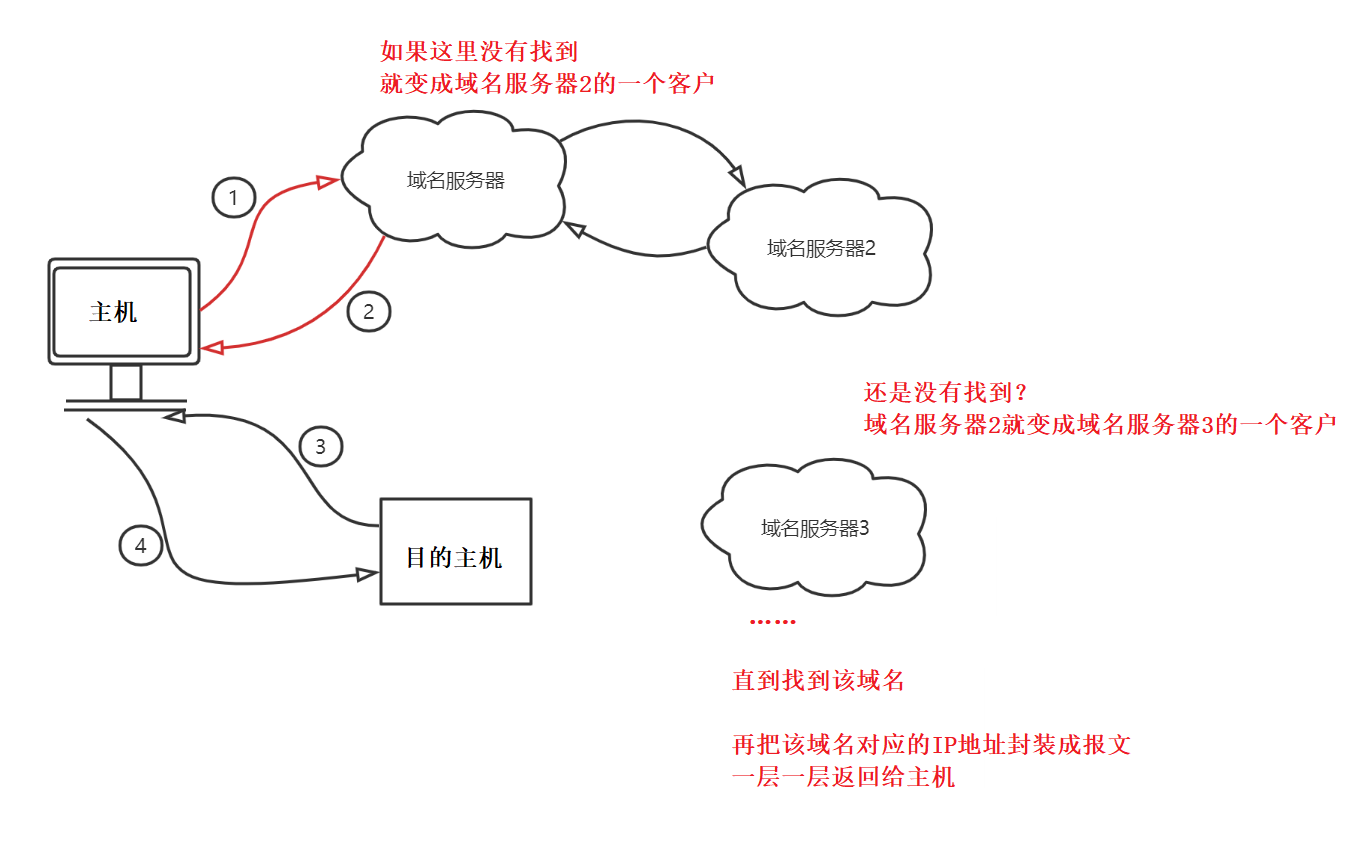
整个因特网不仅仅只有一个域名服务器,如果只使用一个域名服务器,因特网的庞大规模一定会造成域名服务器负荷而无法正常工作,一旦这个域名服务器出现了故障,那么整个网络也就瘫痪了。为什么瘫痪,因为域名服务器瘫痪,我们无法通过域名访问到目的主机。所以要访问的域名有可能没有装入这个域名服务器,就会按照如下的方式去查找:
域名结构
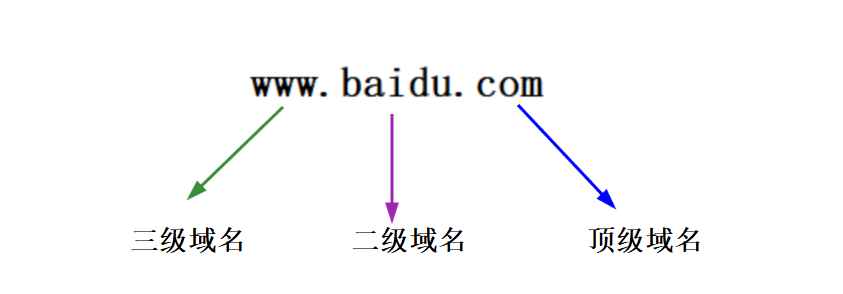
域名内,子域与子域之间使用.分隔。
DNS关于域名的规定:
- 不区分大小写,BAIDU和baidu是等效的
- 域名由英文字母和数字组成,并且每一个标号(分隔的一段)不超过63个字符。
- 标号不能使用标点符号,除了连字符
- - 域名的级别从左到右逐渐增高
- 一个完整域名不少于1个字符且最多不超过255个字符。
【顶级域名】
顶级域名TLD(Top Level Domain)有265个
划分成三大类:
- (1) 国家顶级域名nTLD
据2006年统计,国家顶级域名共有247个
常记为ccTLD(cc 为country-code缩写,表示国家代码)
采用的是ISO3166规定:cn表示中国;us表示美国,uk表示英国……
- (2) 通用顶级域名gTLD
据2006年统计,通用顶级域名共有18个
可自行查阅
- (3) 基础结构域名
基础结构域名只有一个:arpa
用于反向域名解析,所以又称反向域名
【二级域名】
二级域名由各国国家规定,我国规定的二级类域有类别域名和行政域名。
- 类别域名
类别域名共有7个:ac(科研机构)、com(工、商、金融等企业)、edu(中国教育机构)、gov(中国政府机构)、mil(中国国防机构)、net(提供互联网络服务的机构)、org(非营利性的组织)
- 行政域名
适用于我国各省、自治区、直辖市。基本以拼音的缩写表示,例如:gz(贵州省)
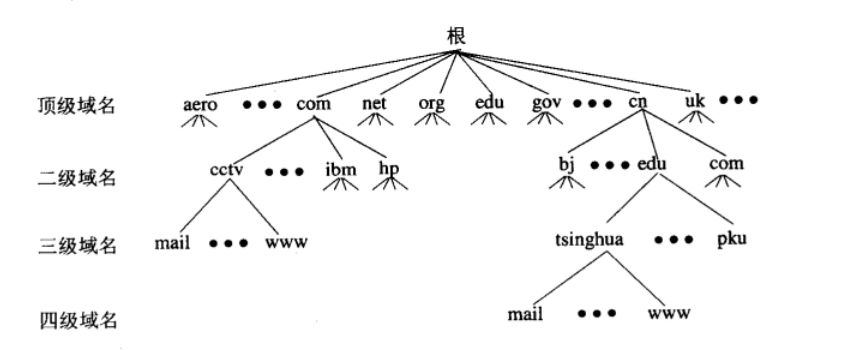
可使用域名树表示域名系统:
域名服务器的分类
DNS服务器的管辖是以区为单位的。一个服务器负责管辖的范围称为区,每一个区设置相应的权限域名服务器。
根据域名服务器提供的作用,可分为以下四类:
-
根域名服务器
根域名服务器是整个DNS系统中最高层次的域名服务器。
本地域名服务器如果要进行域名解析,而自己无法解析(没有装入这个要解析的域名和IP地址的映射关系),首先该本地域名服务器就会把自己当作根域名服务器的一个客户,求助于根域名服务器。目前为止共有13个不同IP地址的根域名服务器,它们是13套装置并且域名有一定的规则。中国有3个根域名服务器,分别在北京、香港和台北。根域名服务器采用了任播技术,可以加快域名解析的过程。
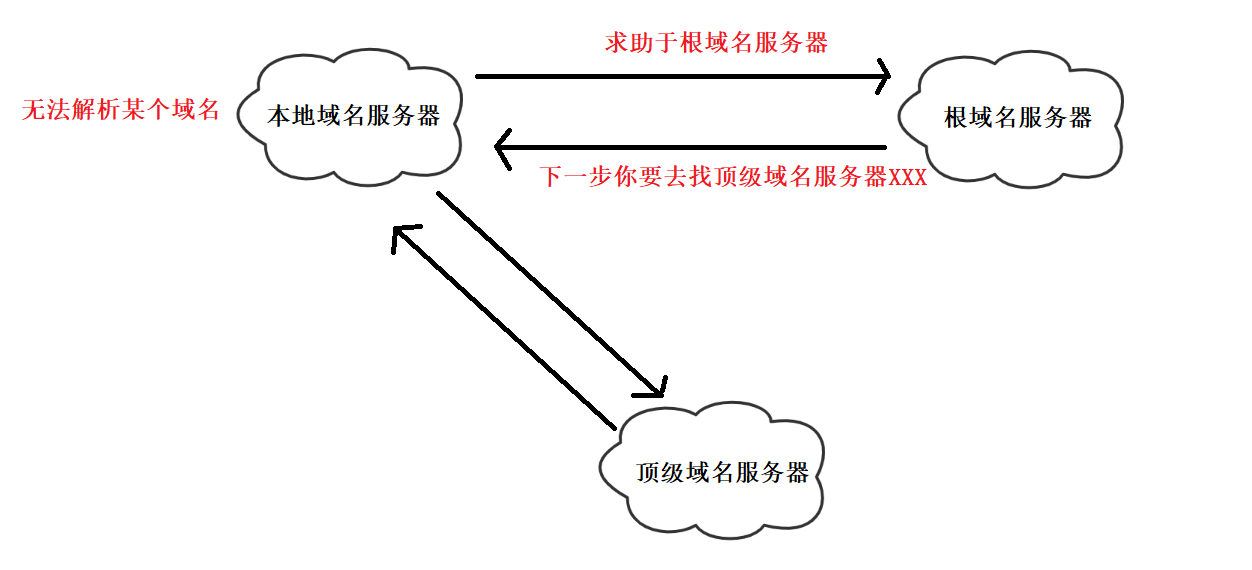
注意:本地域名服务器如果无法解析某个域名,求助于根域名服务器,根域名服务器给出的帮助是:告诉本地域名服务器下一步要去找哪一个顶级域名服务器。
-
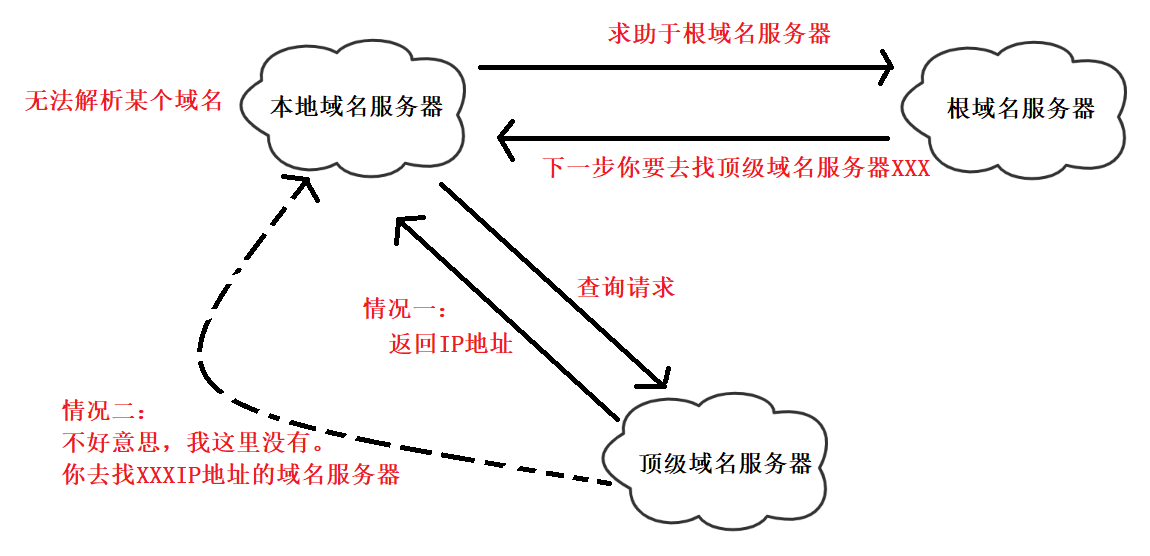
顶级域名服务器
也称TLD域名服务器,负责管理该顶级域名服务器注册的所有二级域名。当收到DNS查询请求,TLD域名服务器就会查找该域名,找到了就发送该域名对应的IP地址回去;如果没有找到,就给出下一步应当去找哪一个域名服务器的IP地址。
-
权限域名服务器
权限域名服务器负责一个区的域名服务器,如果NDS客户求助于权限域名服务器,而权限域名服务器没有查询到,就会告诉客户,下一步应该找的权限域名服务器的IP地址。 -
本地域名服务器
也称为默认域名服务器,进行域名解析时,客户首先就会把请求报文发送给本地域名服务器。
为了提高域名服务器的可靠性,DNS域名服务器会把数据复制到几个域名服务器来保存,其中一个是主域名服务器,另外的是辅助域名服务器。
文件传送协议
文件传送协议提供不同种类主机系统(软、硬件体系结构等都可不同)之间文件的传输能力。
文件传送协议有:
- 基于TCP的文件传送协议FTP(File Transfer Protocol)
- 基于UDP的简单文件传送协议TFTP(Trivial File Transfer Protocol)
它们都是文件共享协议中的一大类,拷贝整个文件,特点:如果要存取某个文件,必须先获得一个本地的文件副本。如果尝试修改文件,只能对文件的副本进行修改,然后再将修改后的文件副本传回原节点。
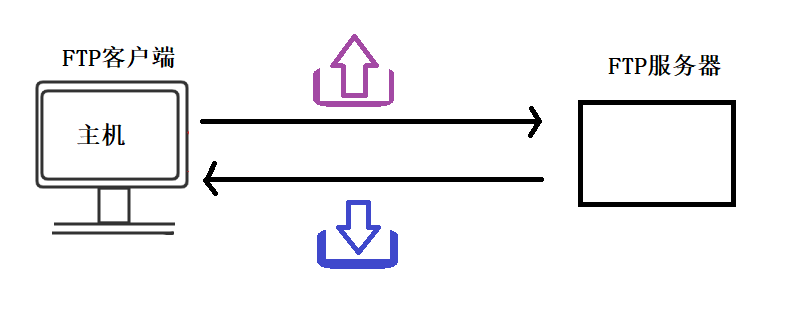
- 从客户端拷贝文件到服务器称为上传
- 从服务器拷贝文件到客户端称为下载
FTP的工作原理
FTP只提供文件传输的一些基本服务,采用客户/服务器工作方式。使用TCP协议 实现可靠传输。
依照FTP协议提供服务,进行文件传送的计算机就是FTP服务器;连接FTP服务器,遵循FTP协议与FTP服务器传送文件的计算机称为FTP客户端。一个FTP服务器可以同时给多个进程提供服务。服务器采用的是多进程版本基于TCP的通信,所以有一个进程,负责接收请求,该进程称为主进程;其他的进程有多个,负责处理请求,称为从属进程。
服务器的主进程工作过程:
- (1)打开孰知端口号(端口号21),使客户进程能够连接
- (2)等待客户进程发出请求
- (3)启动从属进程处理请求。处理完毕后,从属进程终止
- (4)回到等待的状态,继续处理其他客户进程的请求
由于采用多进程版本的TCP通信,所以主进程和从属进程是并发进行的。
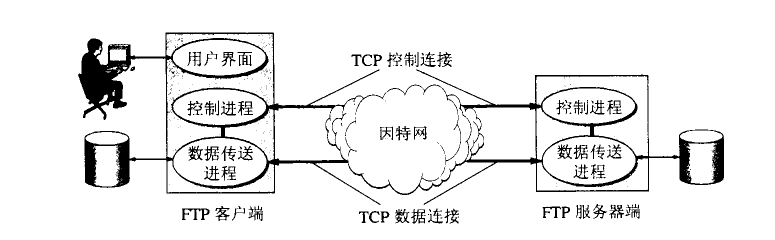
FTP的客户/服务器相较于其他客户/服务器的独特优势就是:文件传输时,客户和服务器之间建立两个并行的TCP连接。

优点在于:使得协议更加简单和易于实现,并且提高了FTP的效率。
注意:
FTP服务器进程使用自己传送数据的熟知端口20和客户进程提供的端口号建立数据连接。事实上,具体是否使用端口20还取决于文件的传输模式。主动的方式使用的是端口20,而被动的方式由FTP服务器和客户端协商决定(端口 >1024 && 端口 < 65535)。
FTP传输方式
- ASCLL传输方式
- 二进制传输方式
FTP匿名服务器
使用FTP时用户必须首先进行登录(用户名 & 密码),在远程主机上获取到相应权限之后,才有资格上传和下载文件。但是互联网上有如此多的FTP主机,不可能要求用户在每一台主机上都有账号。所以引入了匿名服务器,有匿名服务器后用户可以不需要进行登记注册和获取FTP服务器的授权,就能够建立连接,可以从匿名服务器上下载文件。
有了匿名服务器后,我们可以进行匿名登录。登录的用户名是标识符anonymous,密码可以是任意的字符串。
不是所有的FTP主机都能够匿名登录,只有提供了这项服务的FTP主机才支持匿名登录。
电子邮件协议
电子邮件E-mail是应用层的一种异步通信方式,不需要通信双方在场。
收件人和发件人的格式:用户名@邮件服务域名
电子邮件的组成结构
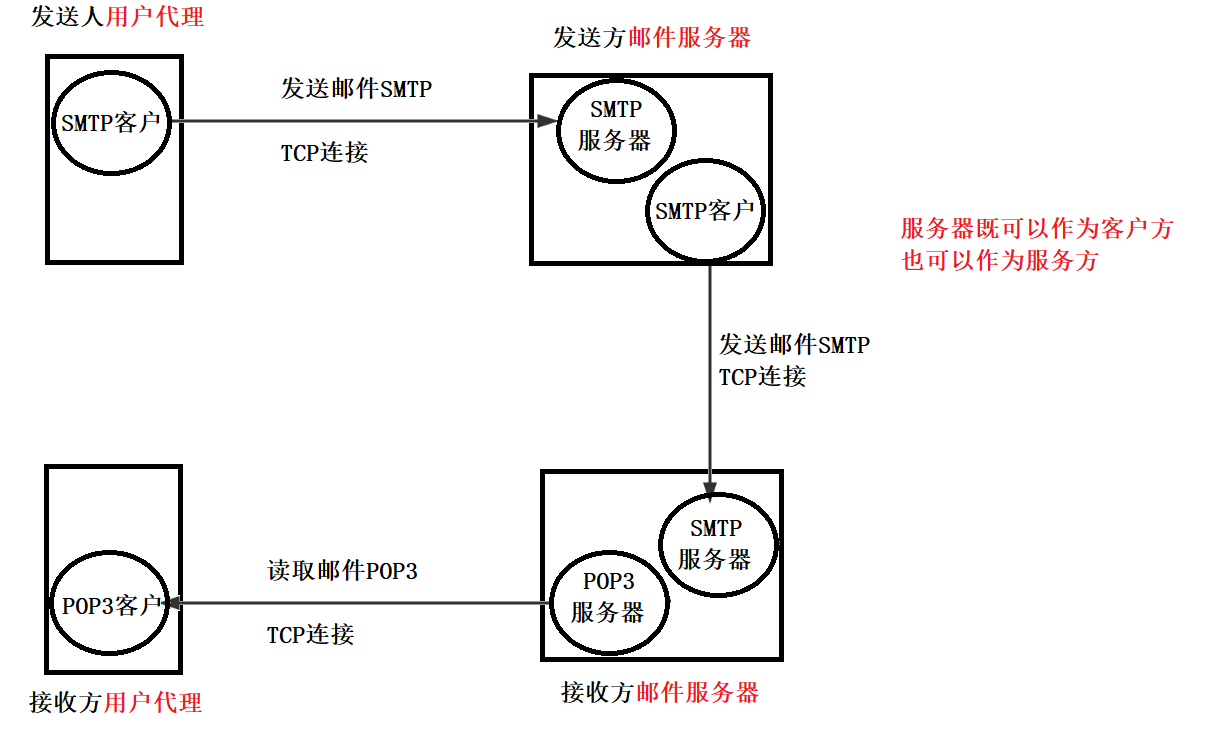
用户代理:用户与email系统的接口。
发送人用户代理的功能:编写;展示;处理;通信。
SMTP服务器的功能:发送&接收邮件;回报发送结果。
其中的协议
- SMTP:邮件发送协议,客户端推送邮件到SMTP服务器
- POP3:邮件接收协议,向SMTP服务器拉取邮件。
电子邮件支持异步通信:发送邮件服务器会把邮件发送到接收方邮件服务器,接收方邮件服务器可以选择接收并删除、接收并保存,如果选择接收并保存,就可以等接收方用户需要时,接收方用户再去请求读取邮件。
SMTP
简单电子邮件传送协议SMTP(Simple Mail Transfer Protocol)属于TCP/IP协议族,它规定了两个相互通信的SMTP进程之间如何交换信息,并且帮助SMTP客户找到下一个目的地。
遵循SMTP协议负责发送邮件的进程就是SMTP客户;遵循SMTP协议负责接收邮件的进程就是SMTP服务器。当然,SMTP服务器也可作为SMTP客户。
采用客户/服务器工作方式、使用TCP协议 实现可靠传输。SMTP服务器进程使用孰知端口25。
【SMTP通信三阶段】
- (1)建立连接
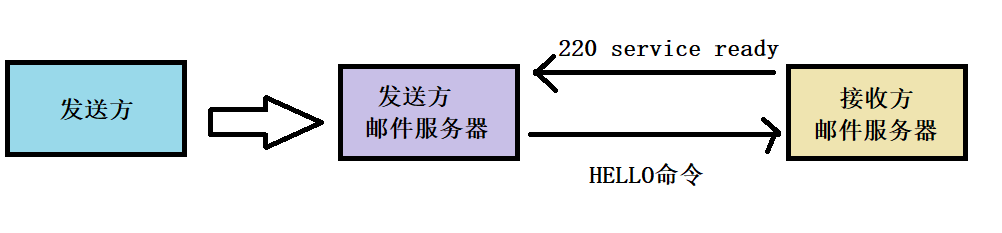
接收方邮件服务器如果有能力接收邮件,就会“确认”,确认回复的是250 OK。如果现在没有能力接收邮件,就会给发送邮件服务器回复421 Service not available。 - (2)邮件传送
邮件传送的细节这里不做介绍。 - (3)释放连接
邮件发完之后,SMTP客户发送QUIT命令,SMTP如果返回221,就表示同意释放TCP连接
【SMTP的特点】
SMTP是简单电子邮件传输协议,有一些缺点比较明显:
- 1、不能发送可执行文件或者二进制对象
- 2、仅仅只能发送7位以内的ASCLL码,并且只能传送英语。
- 3、SMTP服务器会拒绝超过一定长度的邮件。
然而日常生活中,用户基本上不会发送7位以内的ASCLL码并且发送的邮件长度也是不固定的,所以针对SMTP协议的这些缺点,扩充了MIME。
MIME
多用途网际邮件扩充MIME是对SMTP的扩充,定义了传送非ASCLL码的规则。不要混淆了,它没有打破SMTP只能发送7位以内的ASCLL码的规则。
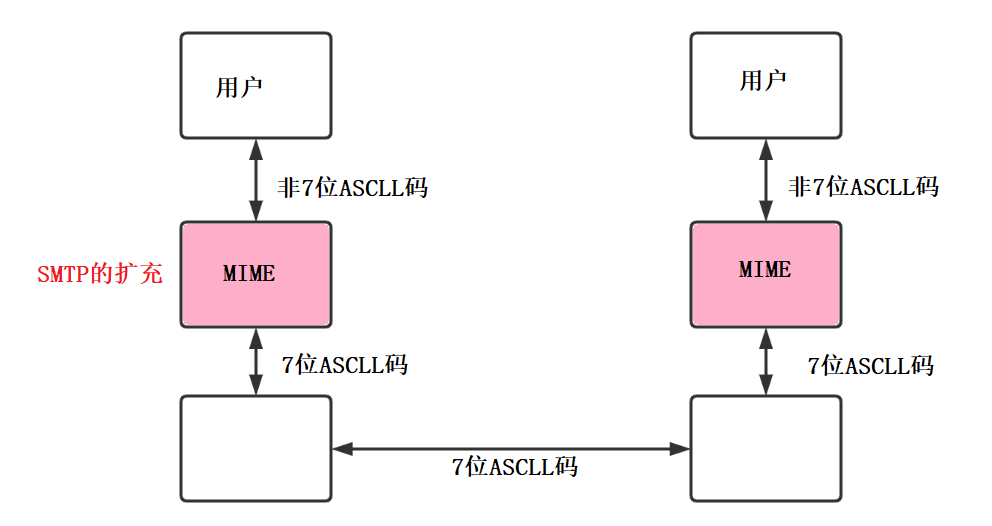
新增:
1、新增了5个首部字段:MIME版本/内容描述/内容标识/内容传送编码/内部内容
2、定义了邮件内容格式,对多媒体邮件进行了标准化
3、定义了传送编码,可对任意格式内容转换。
MIME使得电子邮件系统可以支持声音、图像、视频、多种国家语言等等,让电子邮件的传送内容变得丰富多彩。
POP3
POP3是简单的邮局读取协议(Post Office Protocol)。
通信的方式采用拉取(pull)。
属于TCP/IP协议族、通过TCP端口110建立连接。
IMAP
互联网信息访问协议IMAP,是一种优于POP3并且也比POP3更复杂的新协议。当用户打开IMAP服务器的邮箱时,可以看到邮箱的首部,通过邮箱首部的内容(比如:邮件标题,发送方名字等)再决定是否下载。
属于TCP/IP协议族、通过TCP端口143建立连接。
| 电子邮件协议 | TCP连接端口 |
|---|---|
| SMTP | 25 |
| POP3 | 110 |
| IMAP | 143 |
HTTP
万维网
万维网WWW(World Wide Web )是一个规模庞大,联机式的信息存储所,是无数文档的集合,简称Web。这里的文档就是我们所说的页面。

页面都是一些超文本信息,可用于描述文本、图片、视频等多媒体信息,而这些多媒体信息称为超媒体。
Web上的信息由彼此相联的文档组成,相联的方式就是超链接(有时也称链接),可以实现从一个站点跳转到另一个站点。例如,这就是一个超链接点击此处可跳转
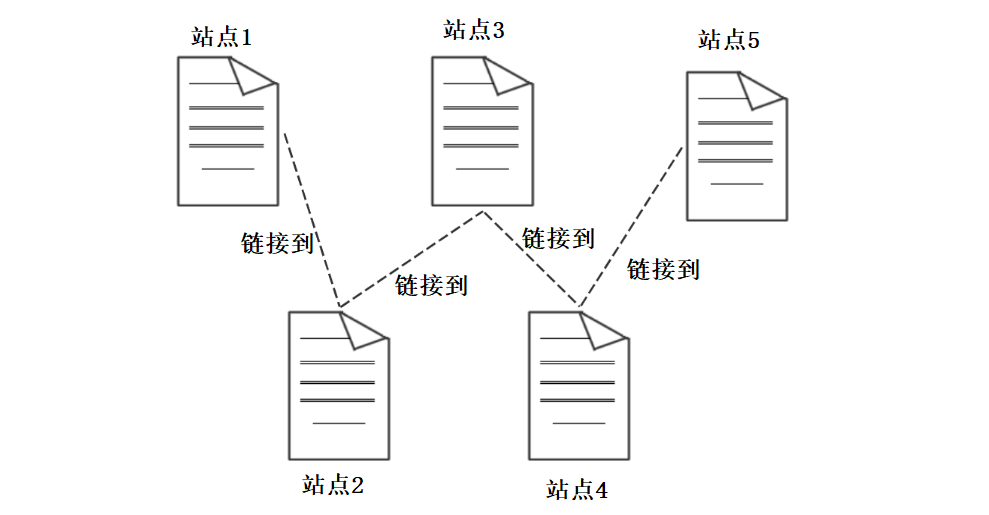
这些文档有可能相互分隔在千里之外,但必须连接在因特网上。整个因特网上的万维网文档是如此之多,它是如何精准地从一个站点跳转到另一个站点的?需要在因特网上唯一的标识一个万维网文档,所以引入了统一资源定位符URL。
URL
URL是统一资源定位符,就是我们俗说的“网址”。它用来在互联网上唯一的标识某个资源的地址,这里的资源指因特网上任何可以被访问的对象。
URL的一般格式:

- 最常用的协议是http协议,其次是FTP协议。
- 主机部分可以是域名,也可以是该资源所在主机的IP地址。
- 使用http协议,默认端口是80,通常可以省略。
- 路径也可以省略的,如果省略了路径,那么URL定位的资源就是某个主页。
- URL的字符串不区分大小写
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现。比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.
转义的规则:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
所以用户浏览页面的方法有两种:
- 1、在浏览器的地址窗口输入要跳转到的页面的URL。
- 2、点击页面的超链接
HTTP概述
Web之所以能够完成这样宏大的一项工作,离不开它背后的各种协议,这些协议被称为Web协议族。HTTP协议就是Web协议族中的一个典型代表,HTTP协议定义了浏览器(万维网客户进程)怎样向万维网请求万维网文档,以及服务器怎样把文档传送给浏览器。
HTTP采用了TCP作为运输层协议,但HTTP协议本身是无连接的(通信双方在交换HTTP报文之前不需要建立HTTP连接)。
HTTP/1.1使用了持续连接:服务器在发送响应后仍然在一段时间内保持着这条连接。
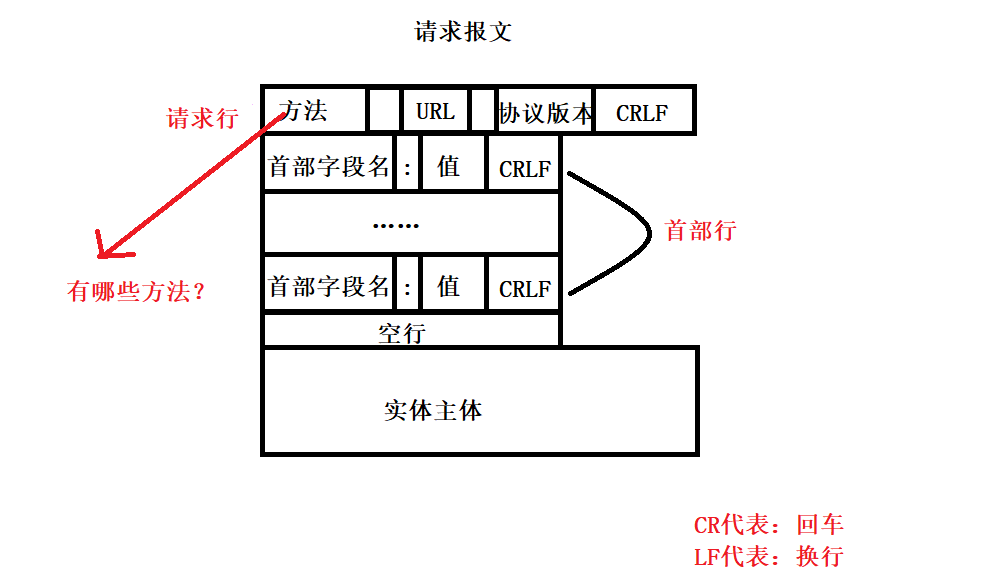
HTTP报文结构
HTTP的两类报文:
- 请求报文。客户->服务器
- 响应报文。服务器->客户
HTTP报文是面向文本的,所以在HTTP报文中的每一个字段都是一些ASCII码串。
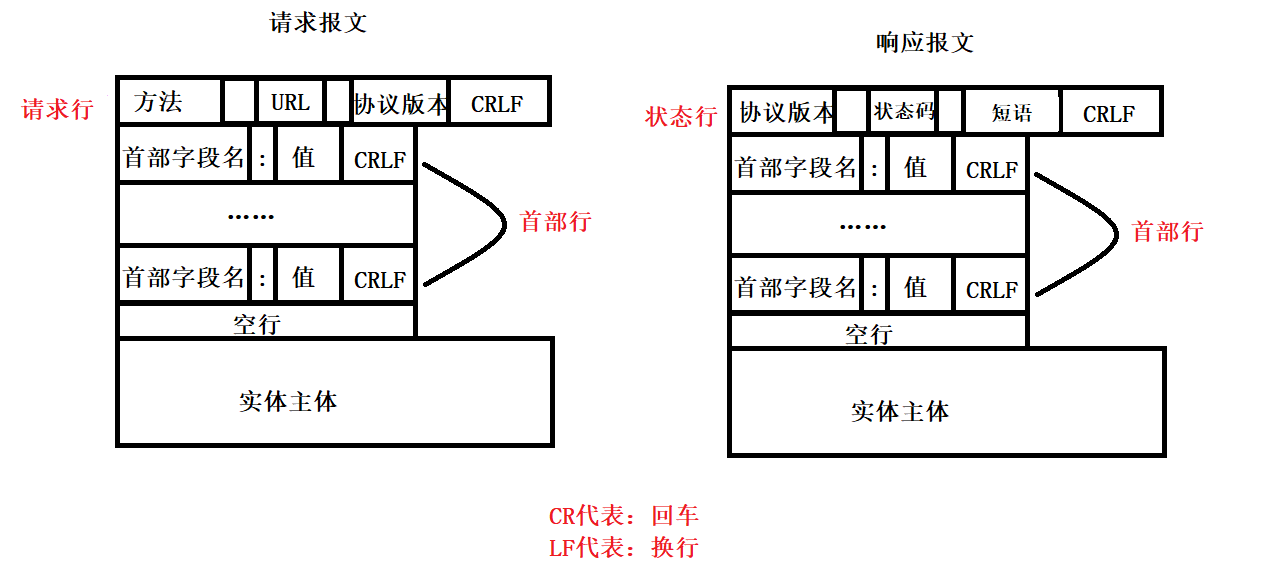
- 开始行
用于区分该报文是请求报文还是响应报文。请求报文内的开始行称为请求行, 响应报文内的开始行称为状态行。请求行和状态行都分成了三个部分,中间以空格为间隔。 - 首部行
首部行采用了键值对的形式首部字段名 : 值。
以上就是报文的报头部分,报头和实体主体之间使用一行空行分隔。其中响应报文的状态行内的短语,用于描述状态码的。例如我们常见的404 Not found,404是状态码,而Not found就是状态码描述。
现在我们模拟实现一个http服务器。并且能够查看一个实际的请求报文。
Sock.hpp的代码我放在了server.cc的后面
//server.cc文件
#include <iostream>
#include <cstring>
#include <cstdlib>
#include "sock.hpp"
#include <pthread.h>
#include <unistd.h>
void UsePage();
void *HandleRequest(void *arg);
//命令格式:./server server_port
int main(int argc, char *argv[])
{
if (argc != 2)
{
UsePage();
return 1;
}
uint16_t port = atoi(argv[1]);
int listen_sockfd = Sock::GetSock();
Sock::Bind(listen_sockfd, port);
Sock::Listen(listen_sockfd);
std::cout << "server ready……" << std::endl;
while (true)
{
int new_sock = Sock::Accept(listen_sockfd);
if (new_sock > 0)
{
//创建一个从属线程,处理客户请求
int *pram = new int(new_sock);
pthread_t pid;
pthread_create(&pid, nullptr, HandleRequest, pram);
}
}
return 0;
}
void UsePage()
{
std::cout << "命令格式:./server server_port" << std::endl;
}
void *HandleRequest(void *arg)
{
int sockfd = *(int *)arg;
delete (int *)arg;
pthread_detach(pthread_self());
//接收客户端请求
char buffer[1024 * 10];
memset(buffer, 0, sizeof(buffer));
ssize_t s = recv(sockfd, buffer, sizeof(buffer), 0);
//成功读取到请求报文,可以构建一个响应报文给客户
if (s > 0)
{
buffer[s] = 0;
std::cout << buffer; //查看http的请求格式
//开始构建响应报文
std::string response = "http/1.0 200 OKn";
response += "Content-Type : text/plainn"; // text/plain,表示正文是普通文本
response += "n"; //空行
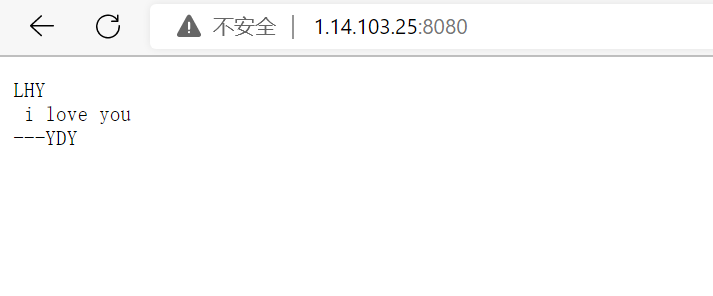
response += "LHY n i love youn---YDYn";
//发送响应报文
send(sockfd, response.c_str(), response.size(), 0);
}
//完成后,关闭用于处理请求的套接字文件描述符
close(sockfd);
return nullptr;
}
//Sock.hpp文件
#pragma once
#include <iostream>
#include <cstdlib>
#include <string>
#include <cstring>
#include <unistd.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
using namespace std;
class Sock
{
public:
static int GetSock()
{
int fd = socket(AF_INET, SOCK_STREAM, 0); // TCP创建流式套接字
if (fd < 0)
{
std::cout << "create socket failed" << std::endl;
exit(1); //没必要执行下去,直接终止程序
}
std::cout << "create socket success" << std::endl;
return fd;
}
static void Bind(int sockfd, uint16_t port)
{
//描述要绑定的套接字地址
struct sockaddr_in server;
server.sin_family = AF_INET;
server.sin_port = htons(port);
server.sin_addr.s_addr = INADDR_ANY;
if (bind(sockfd, (struct sockaddr *)&server, sizeof(server)) < 0)
{
std::cout << " server bind socket address failed" << std::endl;
exit(2);
}
std::cout << "bind socket success" << std::endl;
}
static void Listen(int listen_sockfd)
{
if (listen(listen_sockfd, 5) < 0)
{
std::cout << "server listen client failed" << std::endl;
exit(3);
}
std::cout << "listen success" << std::endl;
}
static int Accept(int listen_sockfd)
{
//输出型参数,用于获取客户套接字地址
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int new_fd = accept(listen_sockfd, (struct sockaddr *)&peer, &len);
if (new_fd < 0)
{
//创建新的套接字,并取出请求队列中的队头套接字地址连接失败,则返回-1
return -1;
}
std::cout << "get a new link" << std::endl;
return new_fd;
}
//客户请求连接服务器
static int Connect(int sockfd, std::string ip, uint16_t port)
{
//描述服务器的套接字地址
struct sockaddr_in server;
server.sin_family = AF_INET;
server.sin_port = htons(port);
server.sin_addr.s_addr = inet_addr(ip.c_str());
if (connect(sockfd, (struct sockaddr *)&server, sizeof(server)) < 0)
{
std::cout << "client connect server failed" << std::endl;
}
}
};
有了http服务器,那么http客户端呢?http的客户进程就是浏览器!!!
所以要测试,直接在浏览器的地址窗口输入:运行服务端进程的公网IP:服务端进程绑定的端口号,例如:1.14.103.25:8080
这里需要注意的是,运行我们模拟的http服务端进程时,要开放你绑定的端口。如何开放端口请自行查阅。
我们就可以在服务器上看到浏览器发送的请求报文:

http请求报文的结构果然一一对应
浏览器显示内容:
请求方法
在上面的代码测试中,会发现服务器一次不止接收到一个请求报文,而是多个。日常工作中,http服务器一次接收到的报文也不止一个,那么它如何做到精确读取到一个完整的报文?
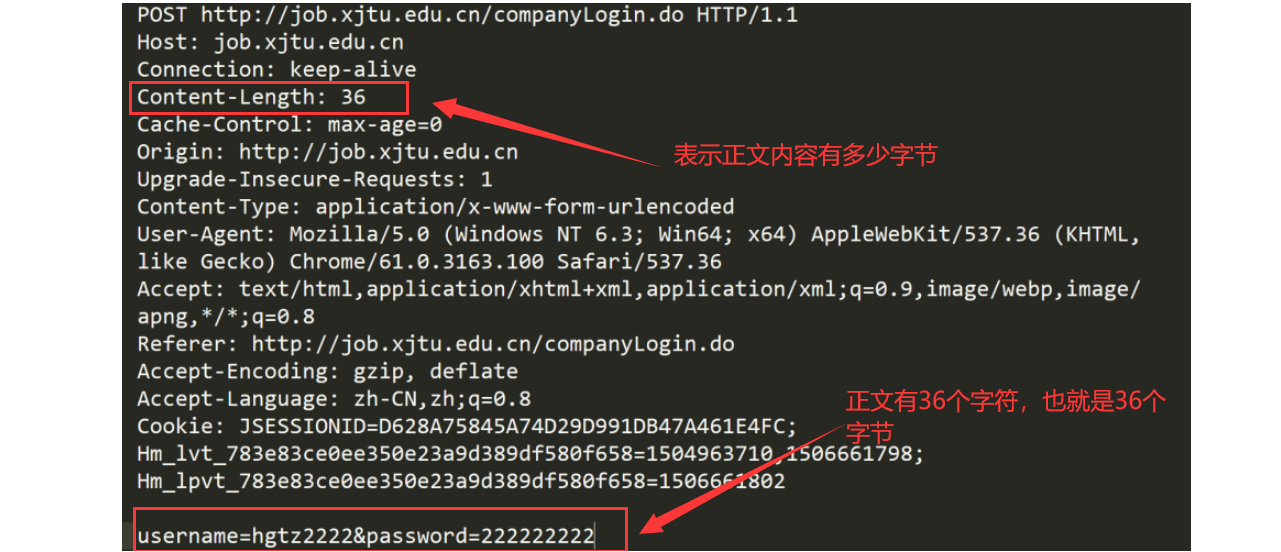
- 报头的读取:判断是否读取到空行,读取到空行代表报文部分到此为止。
- 正文(实体主体)的读取:如果有正文内容,首部行会包含一个字段
Content-Length,表示该报文的正文有多少个字节,按照这个字段给的值读取字节数,就可以做到精确地读取正文了。
| 方法 | 说明 | 支持的HTTP版本 |
|---|---|---|
| GET | 获取资源 | 1.0 、1.1 |
| POST | 传输实体主体 | 1.0 、1.1 |
| HEAD | 获取报文首部 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINE | 断开连接关系 | 1.0 |
其中最常用的是GET、POST,其次是HEAD。
为了测试GET和POST请求,我们将改写上面的代码。
在改写之前,我们需要补充一些预备知识。
浏览器发给服务器:请求报文的请求行的第二部分(URL),是Web目录。
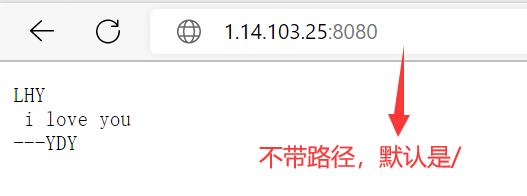
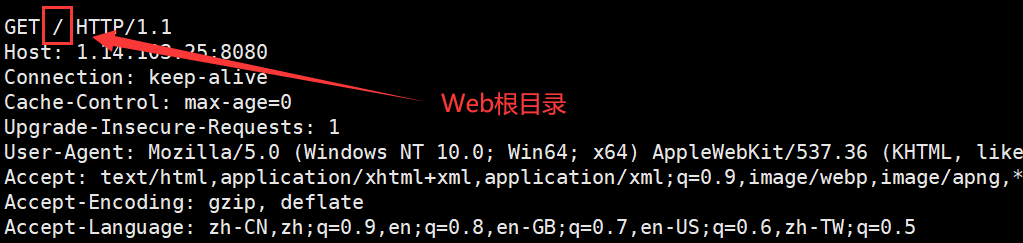
http请求的/是Web根目录,如果请求/,意味着要访问该网站的首页。
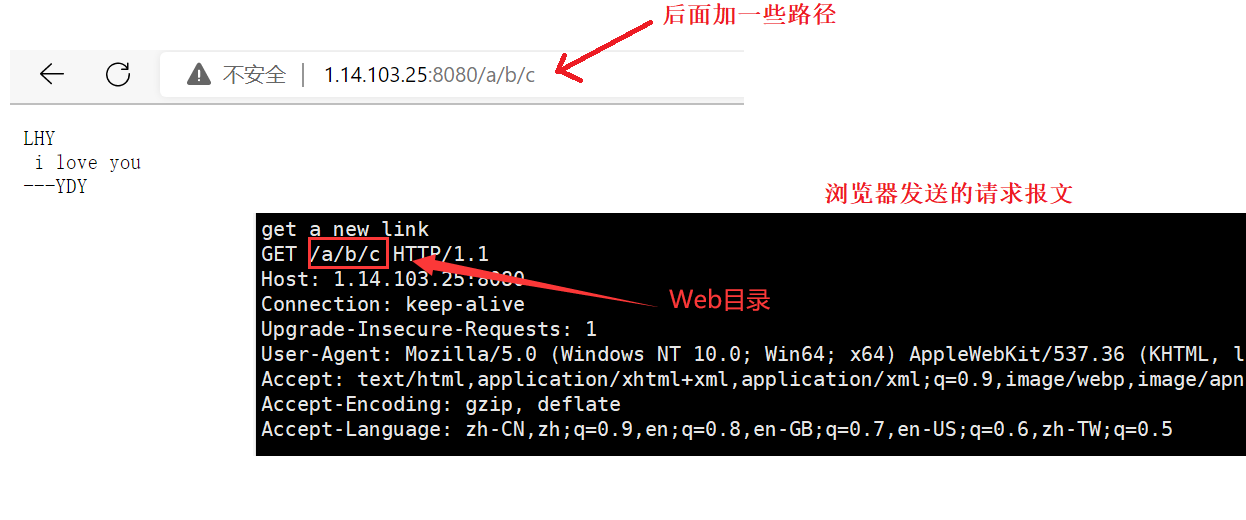
而我们一般要请求的不是首页,而是具体的某个资源。
现在我们给浏览器响应一个实体主体内容是文件的报文。并且引入一些HTML,控制浏览器给我们模拟的服务器发送GET、POST方法,方便查看这两种方法出现的现象和总结。

其中Sock.hpp,代码在文章前部分已经给出。
//http.cc
#include <iostream>
#include <cstring>
#include <cstdlib>
#include "sock.hpp"
#include <pthread.h>
#include <unistd.h>
#include <fstream>
#include <sys/stat.h>
#define WWWROOT "./WebRoot/"
#define HOME_PAGE "index.html"
void UsePage();
void *HandleRequest(void *arg);
//命令格式:./server server_port
int main(int argc, char *argv[])
{
if (argc != 2)
{
UsePage();
return 1;
}
uint16_t port = atoi(argv[1]);
int listen_sockfd = Sock::GetSock();
Sock::Bind(listen_sockfd, port);
Sock::Listen(listen_sockfd);
std::cout << "server ready……" << std::endl;
while (true)
{
int new_sock = Sock::Accept(listen_sockfd);
if (new_sock > 0)
{
//创建一个从属线程,处理客户请求
int *pram = new int(new_sock);
pthread_t pid;
pthread_create(&pid, nullptr, HandleRequest, pram);
}
}
return 0;
}
void UsePage()
{
std::cout << "命令格式:./server server_port" << std::endl;
}
void *HandleRequest(void *arg)
{
int sockfd = *(int *)arg;
delete (int *)arg;
pthread_detach(pthread_self());
//接收客户端请求
char buffer[1024 * 10];
memset(buffer, 0, sizeof(buffer));
ssize_t s = recv(sockfd, buffer, sizeof(buffer), 0);
//成功读取到请求报文,可以构建一个响应报文给客户
if (s > 0)
{
buffer[s] = 0;
std::cout << buffer; //查看http的请求格式
//将要打开的文件描述一下,便于后续操作
std::string html_file = WWWROOT;
html_file += HOME_PAGE;
std::ifstream in(html_file);
if (!in.is_open()) //打开文件失败
{
//构建响应报文
std::string http_response = "http/1.0 404 NOT FOUNDn"; //状态行
http_response += "Content-Type: text/html; charset = utf8n";
http_response += "n"; //空行
http_response += "<html><p>The resource you want to access does not exist</p></html>";
//发送响应报文
send(sockfd,http_response.c_str(), http_response.size(), 0);
}
else //打开文件成功
{
//构建响应报文
// 1、获取要打开文件的字节数,这个信息在获取到st中
// 用于增加报头中的字段Content-Length
struct stat st;
stat(html_file.c_str(), &st);
// 2、构建响应报文的报头
std::string http_response = "http/1.0 200 OKn"; //状态行
http_response += "Content-Type: text/html; charset = utf8n";
http_response += "Content-Length: ";
http_response += std::to_string(st.st_size);
http_response += "n";
http_response += "n"; //空行
// 3、获取实体主体
std::string content;
std::string line;
while (std::getline(in, line))
{
content += line;
}
// 4、将实体主体加入响应报文
http_response += content;
in.close();
//发送响应报文
send(sockfd,http_response.c_str(), http_response.size(), 0);
}
}
//完成后,关闭用于处理请求的套接字文件描述符
close(sockfd);
return nullptr;
}
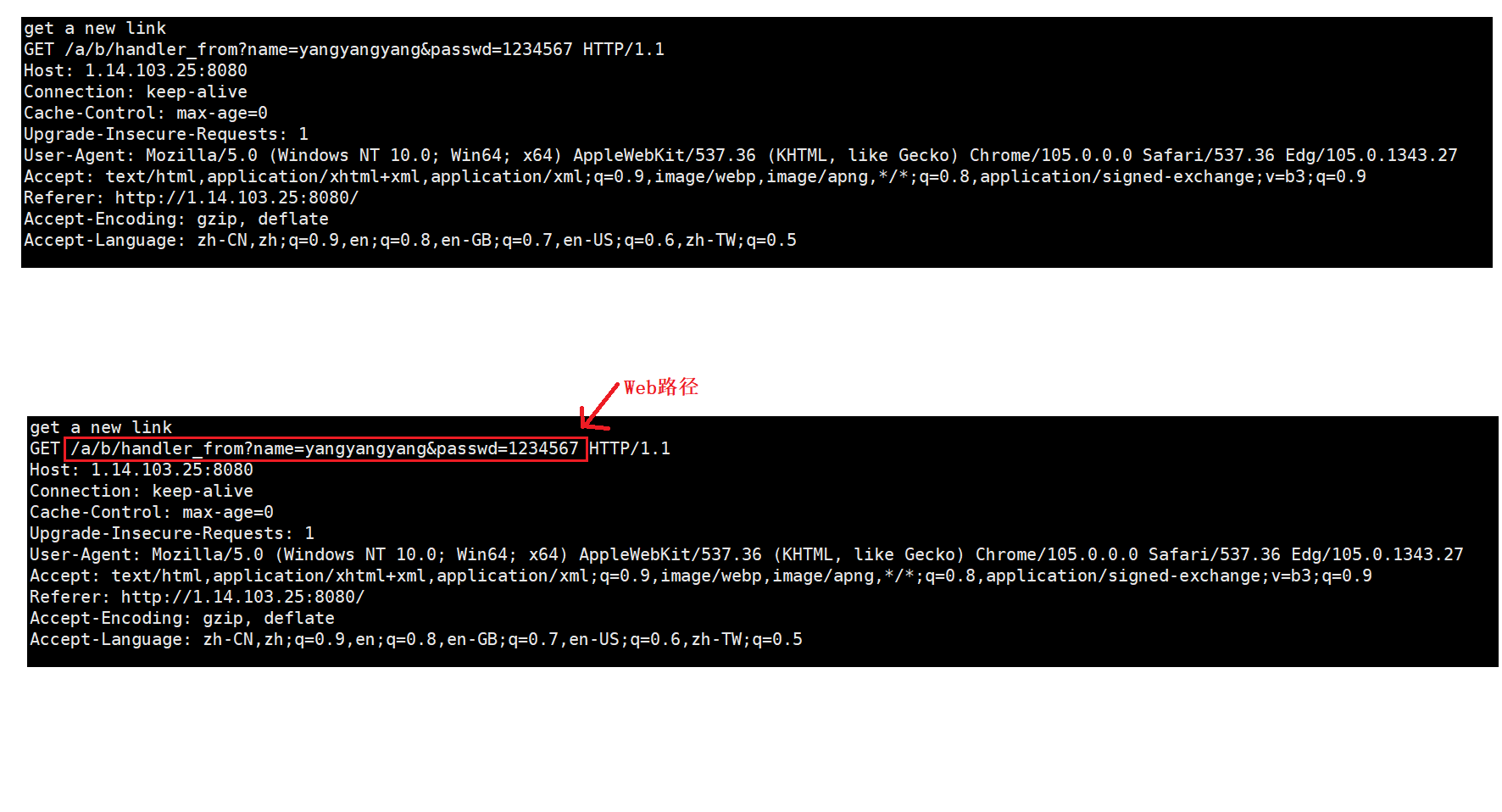
【浏览器请求GET方法时的现象】
浏览器提交表单时,浏览器的变化:
提交表单,服务器接收到的请求报文:

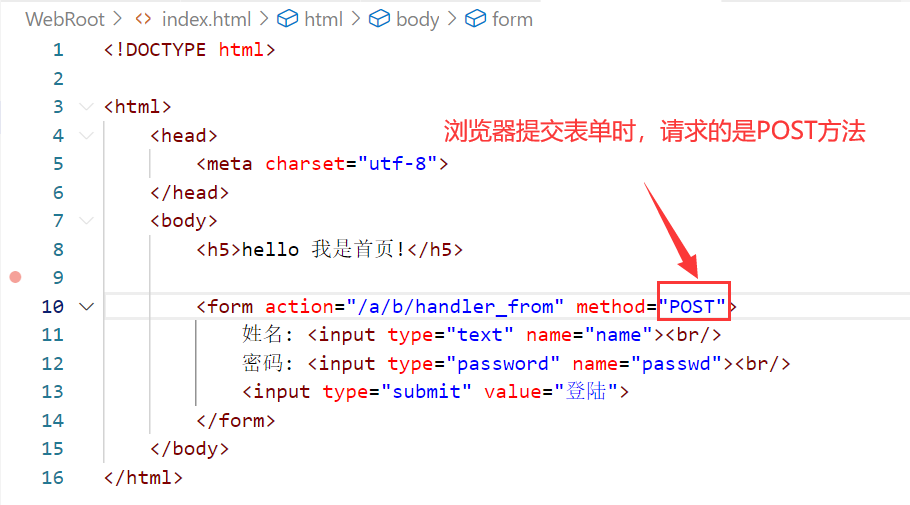
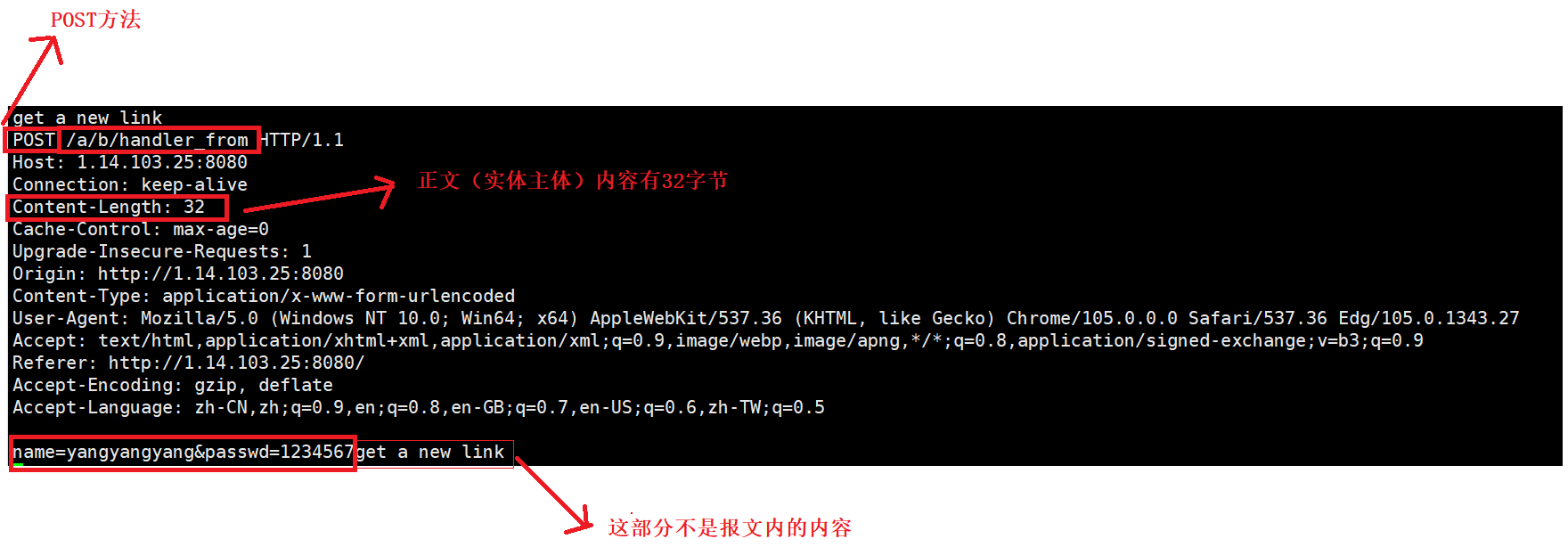
【浏览器请求POST方法的现象】
浏览器提交表单时,浏览器的变化:
提交表单,服务器接收到的请求报文:

【GET、POST方法的总结】
总结一(概念):
- GET方法,作用是获取资源(下载),是最常用的获取资源方法;默认获取所有的网页,都是GET方法。如果GET需要提交参数,通过URL进行参数拼接,从而提交给服务端。
- POST方法,作用是推送资源(上传),是最常用的提交参数方法;如果GET需要提交参数,不通过URL的参数拼接,而是直接通过正文(实体主体)提交。不要忘记首部行的字段
Content-Length。
总结二(区别):
- 参数提交的位置不同,POST方法比较私密(私密 != 安全),不会回显到浏览器的URL输入框;GET方法不私密,会把重要的信息回显到浏览器的URL输入框。
- GET通过URL传参,URL有大小限制,不同的浏览器可能会有不同的限制;POST方法由实体主体传参,无大小限制。
状态码
| 状态码 | 类别 | 原因短语(描述状态码) |
|---|---|---|
| 1XXX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XXX | Success(成功状态码) | 请求正常处理完毕 |
| 3XXX | Rdirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XXX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XXX | Server Error(服务器错误状态码 | 服务器处理请求出错 |
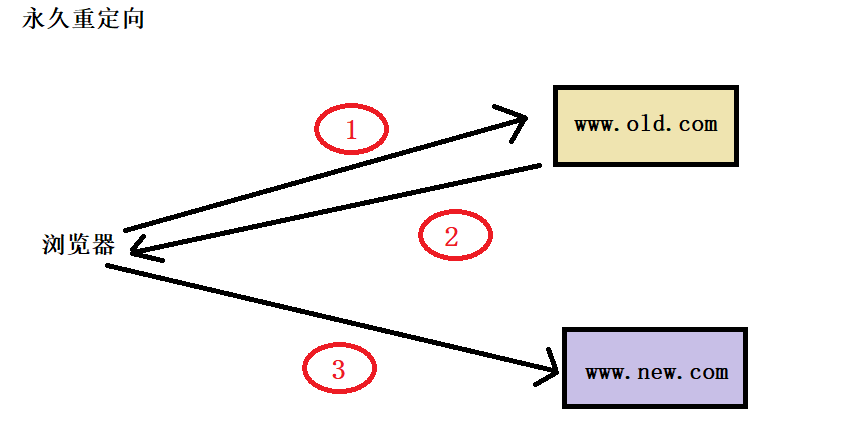
重点提及3XXX。

如果响应报文的状态码是3XXX,那么响应报文的首部行就会有一个字段Location,这个字段包含重定向到哪一个文档的URL。重定向是浏览器支持的,使用的浏览器必须能够识别301、302、307状态码。
#include <iostream>
#include <cstring>
#include <cstdlib>
#include "sock.hpp"
#include <pthread.h>
#include <unistd.h>
#include <fstream>
#include <sys/stat.h>
#define WWWROOT "./WebRoot/"
#define HOME_PAGE "index.html"
void UsePage();
void *HandleRequest(void *arg);
//命令格式:./server server_port
int main(int argc, char *argv[])
{
if (argc != 2)
{
UsePage();
return 1;
}
uint16_t port = atoi(argv[1]);
int listen_sockfd = Sock::GetSock();
Sock::Bind(listen_sockfd, port);
Sock::Listen(listen_sockfd);
std::cout << "server ready……" << std::endl;
while (true)
{
int new_sock = Sock::Accept(listen_sockfd);
if (new_sock > 0)
{
//创建一个从属线程,处理客户请求
int *pram = new int(new_sock);
pthread_t pid;
pthread_create(&pid, nullptr, HandleRequest, pram);
}
}
return 0;
}
void UsePage()
{
std::cout << "命令格式:./server server_port" << std::endl;
}
void *HandleRequest(void *arg)
{
int sockfd = *(int *)arg;
delete (int *)arg;
pthread_detach(pthread_self());
//接收客户端请求
char buffer[1024 * 10];
memset(buffer, 0, sizeof(buffer));
ssize_t s = recv(sockfd, buffer, sizeof(buffer), 0);
//成功读取到请求报文,可以构建一个响应报文给客户
if (s > 0)
{
buffer[s] = 0;
std::cout << buffer; //查看http的请求格式
//构建响应报文
std::string response = "http/1.1 301 Permanently movedn";
response += "Location: https://www.qq.com/n";
response += "n";
send(sockfd, response.c_str(), response.size(), 0);
}
//完成后,关闭用于处理请求的套接字文件描述符
close(sockfd);
return nullptr;
}
上面发送的响应报文就是:
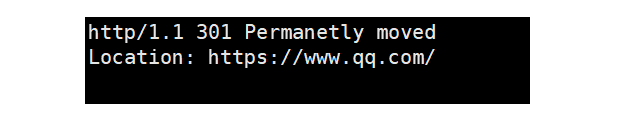
当我们运行服务器,然后在浏览器的URL输入框中输入IP地址:端口号,就会跳转到https://www.qq.com/这个网站。
首部行字段
上面解释了部分首部行字段,这里给出较为常见首部行字段的清单:
Content-Type:数据类型Content-Length:(正文)实体主体的字节数Location:配合3XXX状态码使用,告诉客户端接下来要去哪里访问Host:客户端告诉服务器,它所请求的资源在哪一台主机上的哪一个端口User-Agent:声明请求用户的操作系统、浏览器的版本信息Referer:表明当前页面是从哪一个页面跳转过来的Cookie:用于在客户端存储少量信息。Connect:表明使用的连接方式是持续连接还是短链接。
Cookie和Session
HTTP协议是无状态的(HTTP服务器是无状态服务器),HTTP服务器会把每一次客户请求作为与之前任何请求都无关的独立事务,不需要记住曾经访问过的某个客户信息。无状态简化了HTTP服务器的设计,使得它更为容易支持大量并发的HTTP客户请求。
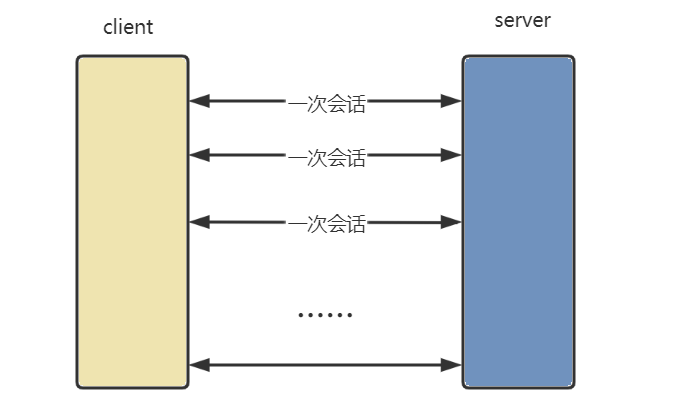
当我们进行各种页面跳转的时候,本质是浏览器进行各种请求。http协议本身是无状态的,但我们发现网站是“认识我”的,这提高了用户访问网站或者平台的体验。这项工作并不是http协议本身要解决的,但http可以提供一些技术支持,来保证网站具有“会话保持”的功能。
这个工作由Cookie完成。
- 对于浏览器:
Cookie是存储在用户主机的文本文件,记录了一段时间内某用户的私密信息。 - 对于http
一旦该网站对应有Cookie,在发起任何请求的时候,都会在request中携带Cookie信息。
响应报文的首部行可以包含一个字段Set-Cookie,将Cookie信息设置进浏览器的Cookie文本文件。
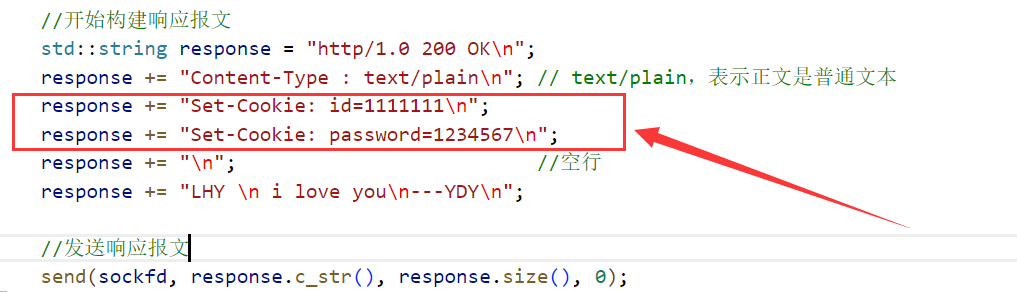
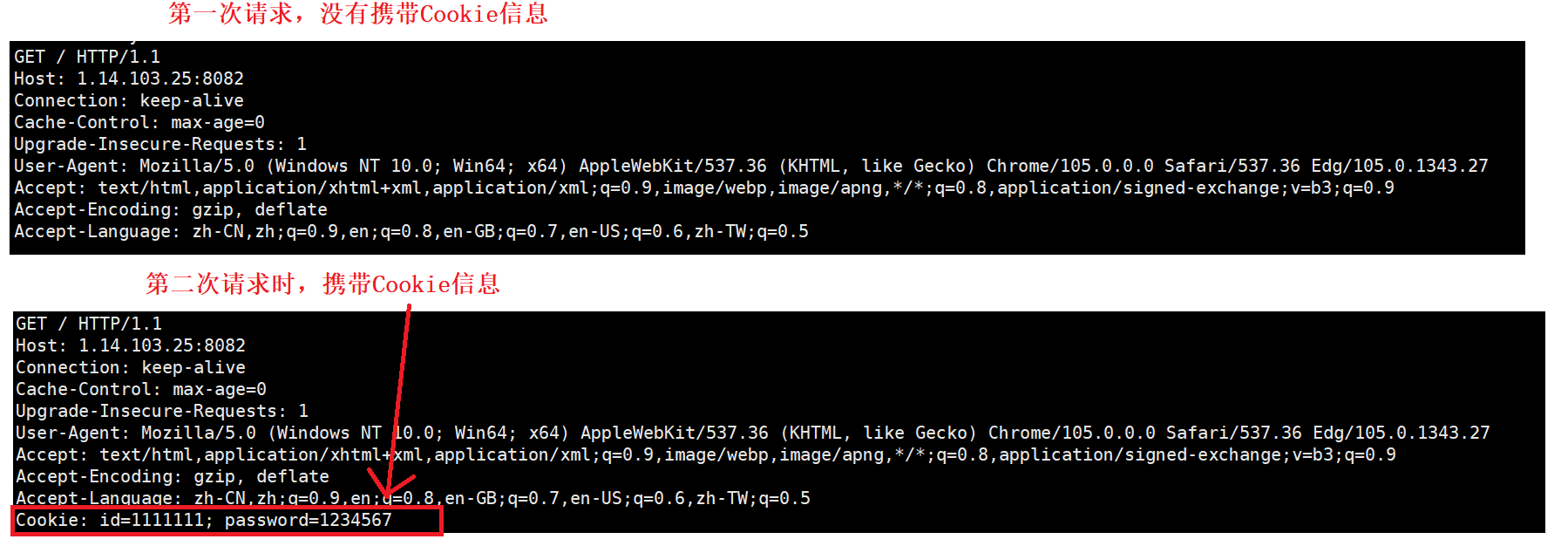
多次请求:
第一次浏览器请求的时候,没有Cookie信息,所以请求时没有携带Cookie信息。
第一次请求后,服务器将Cookie信息设置进浏览器的Cookie文件。
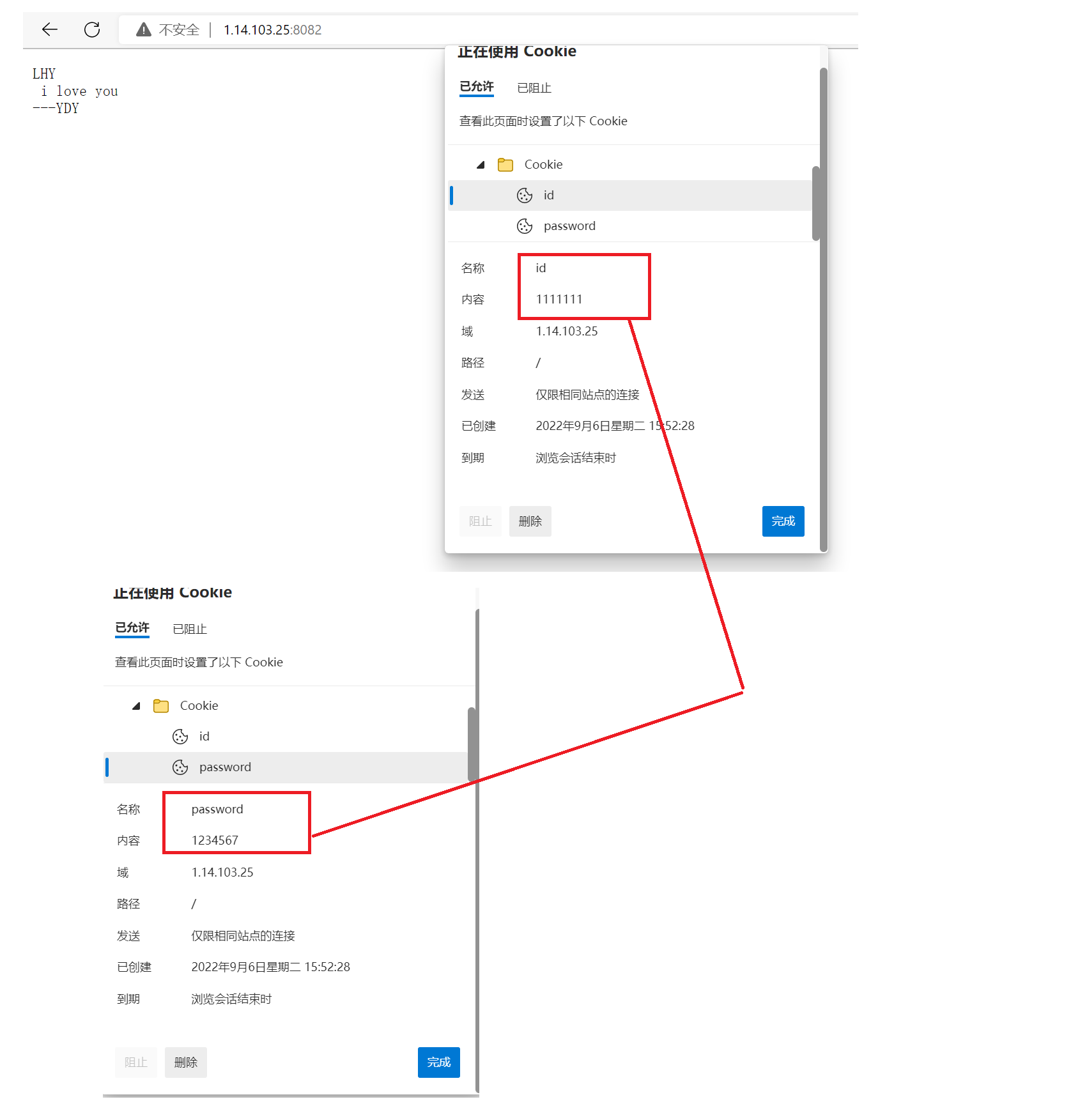
后续请求的时候,浏览器有Cookie信息了,请求的时候就把Cookie信息携带上
单纯地使用Cookie是有安全隐患的,如果被人盗取了Cookie文件:
1、盗取者可以我的身份进行认证访问特定的资源。
2、如果保存的是我们的用户名和信息,那么情况就更加糟糕。
所以Cookie一般和Session配套使用,Session是保存在服务器上的文本文件。
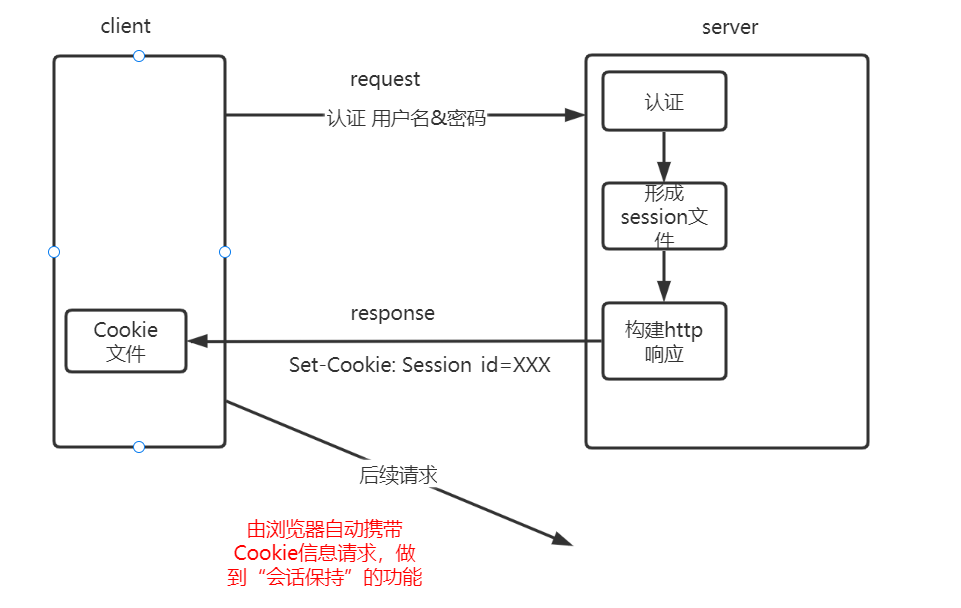
每当有一个用户认证的时候服务器就会生成一个唯一的Session文件,用户保存一段时间内用户的私密信息。然后服务器将Session文件的id等设置进用户的Cookie文件。
虽然这样避免了Cookie明文地保存用户的私密信息,但还是有被盗取的风险,虽然没有办法避免被盗取,但现在已经衍生出了许多应对的办法。例如,认证的时候,可以检查IP归属地,如果不在用户经常登录的IP归属地,就禁止登录访问/要求重新认证。
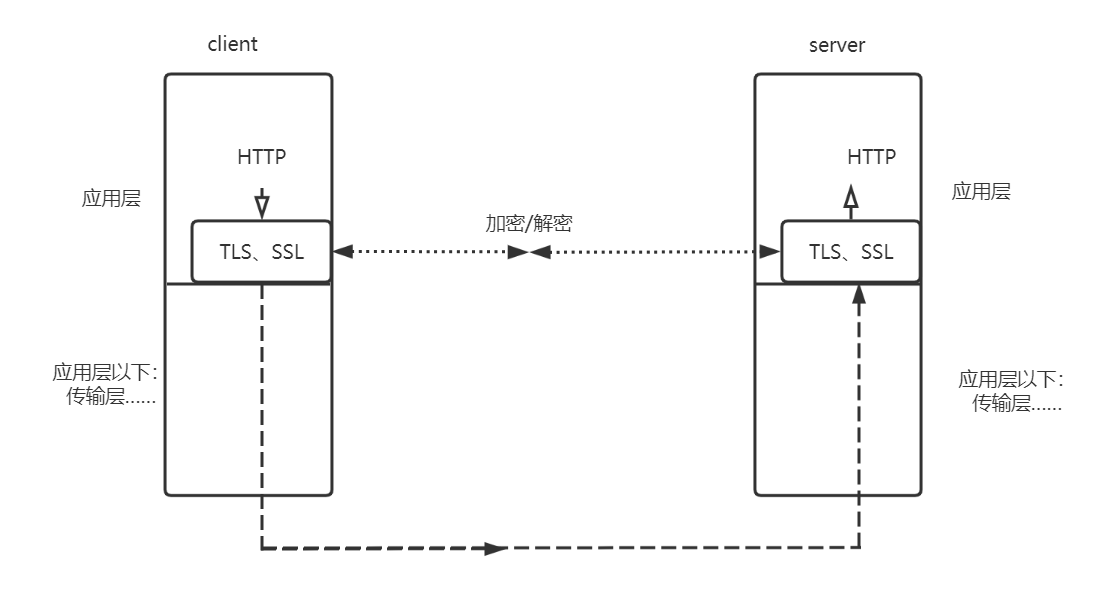
HTTPS
HTTPS是HTTP+TLS/SSL的结合。数据在网络中总是要进行加密的,而TLS/SSL是http数据的加密解密层。
加密方式
有两种加密的方式:
- (1)对称加密。
对称加密,只有一个密钥M,使用M对数据加密,也用M解密得到数据。
做个假设:data是传送的数据。
加密:result = data ^ M;
解密:data = result ^ M;
这不是具体过程,仅仅作为一个抽象的理解。
- (2)非对称加密。
非对称加密,使用一对密钥:公钥和私钥。
如果使用公钥对数据加密,那么就用私钥解密;如果使用私钥对数据加密,那么就用公钥解密。一般而言,公钥对于全世界是公开的,而私钥必须自己私有保存。
如何选择加密算法?
假设单纯使用对称加密:
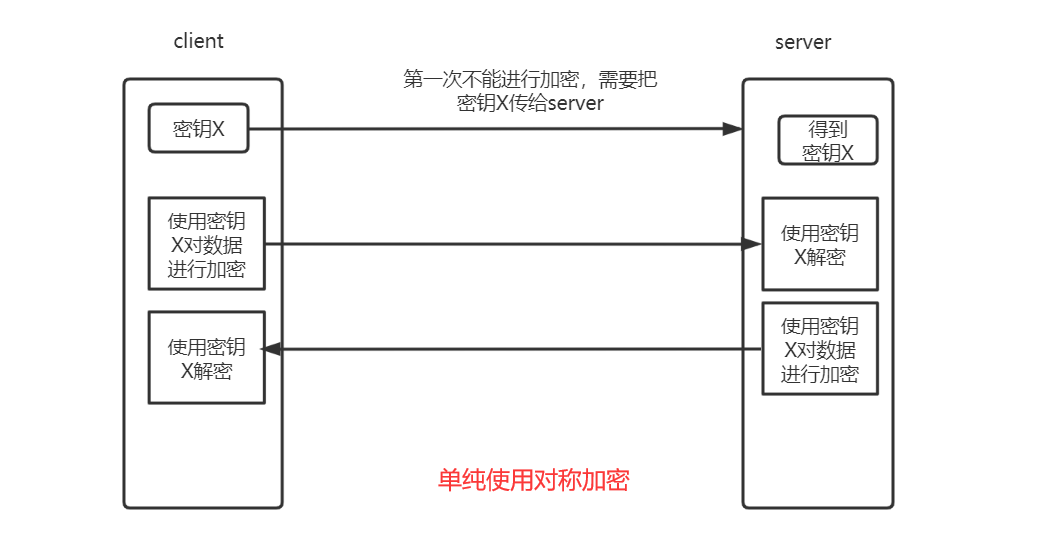
这并不是安全的,因为在将密钥传给对方的时候,密钥此时是数据并且没有被加密,盗取者能够拿到密钥,并使用密钥对数据解密,那么后续的加密工作就毫无作用。
假设单纯使用非对称加密:
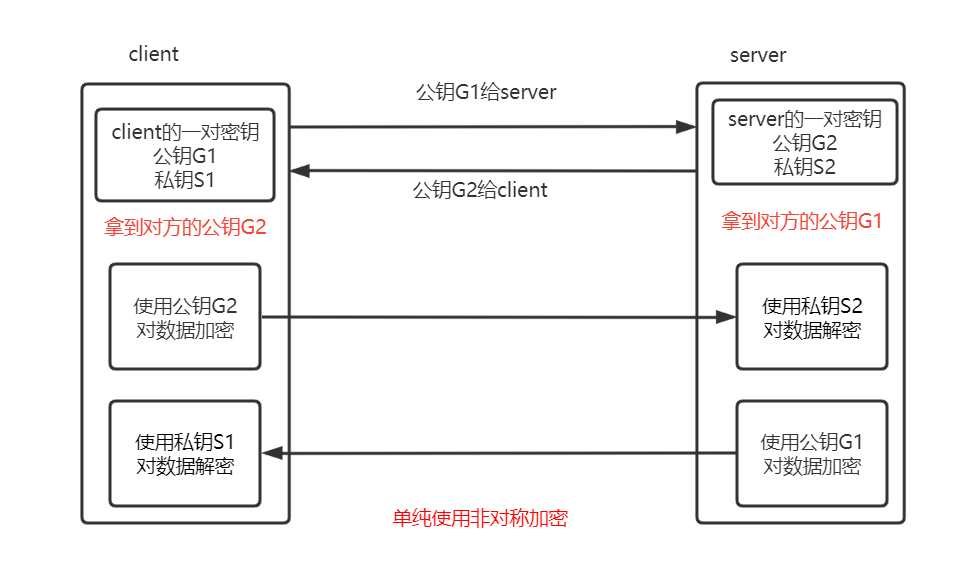
在将公钥传给对方的时候,公钥此时是数据并且没有被加密,盗取者能够拿到公钥,但我们并不使用公钥解密,所以没有多大关系。这种方式数据被盗取的风险就远小于单纯使用对称加密的方式,但是它相对于前者要消耗了太多的时间。
一种结合了上述优点的加密算法:对称加密 + 非对称加密。
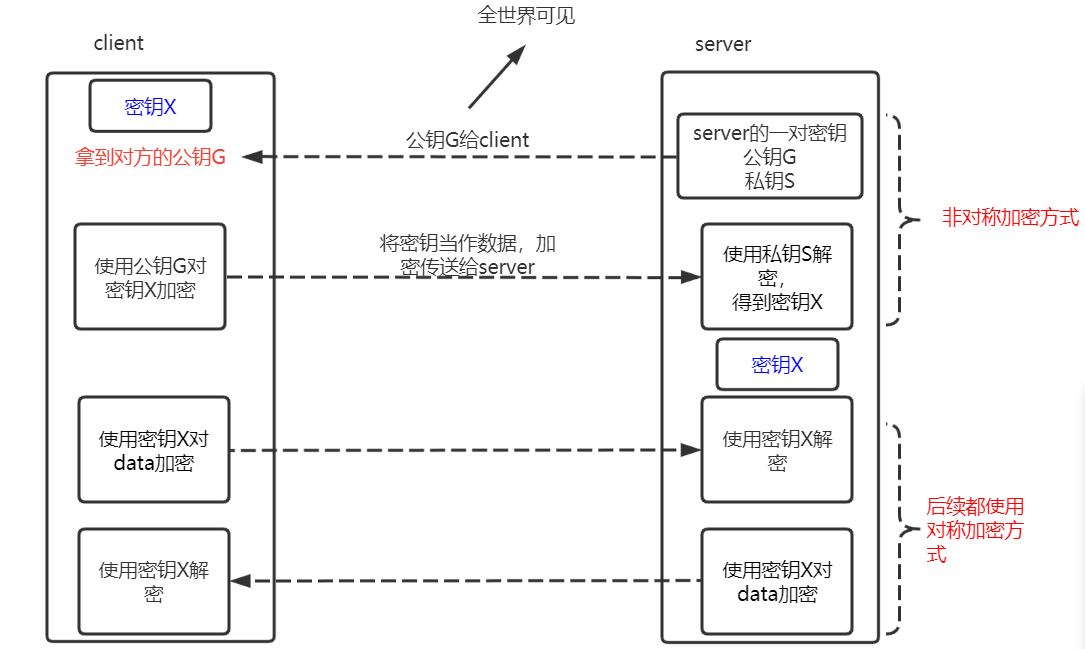
只需要一对公钥+私钥,其目的是将密钥加密传给对方。后续只需要这一个密钥就可以安全地传送数据了。
注意:
安全的含义指,即使盗取者拿到了加密后的内容,也没有办法拿到里面的数据。
补充知识
如何防止文本在传输的过程中数据被篡改?以及识别到文本内容是否被篡改。
对文本加密过程:
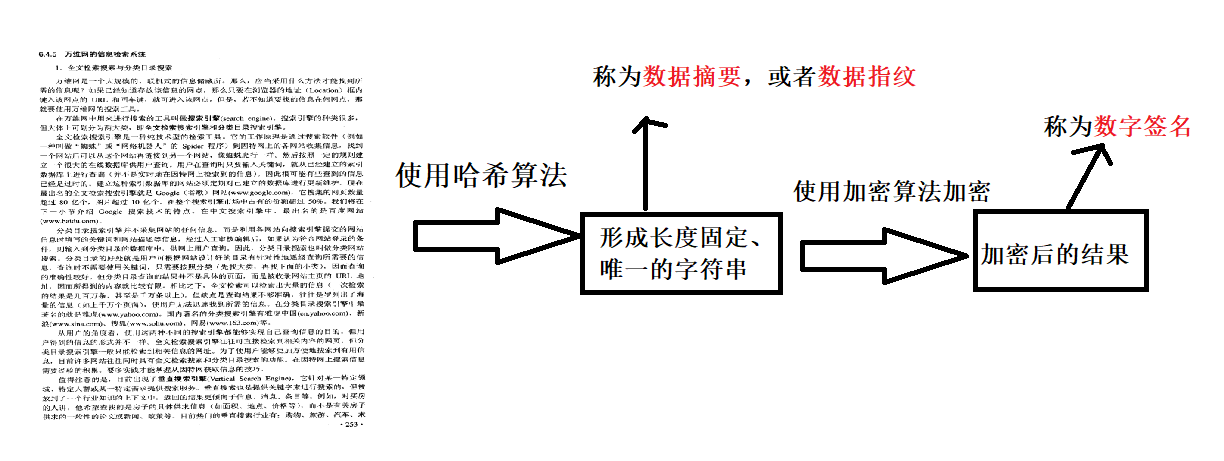
不同的文本,哪怕只是一些标点符号不同,形成的Hash结果都会不同。
识别文本内容是否被篡改:
收到文本方的校验
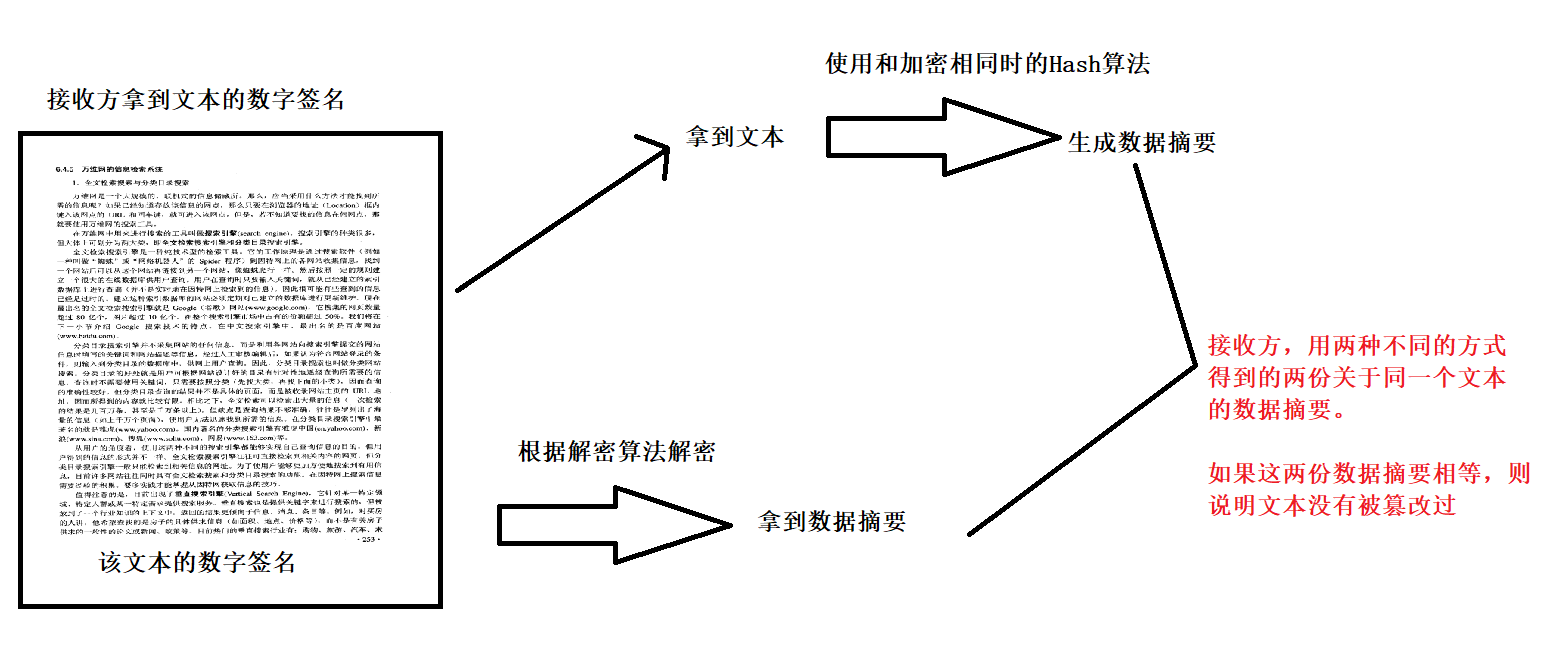
证书
采用上述的对称加密+非对称加密的方式仍然是不安全的,因为可能会有中间人获取到数据。中间人就是哪些试图在别人进行网络通信中截取数据的“人”。
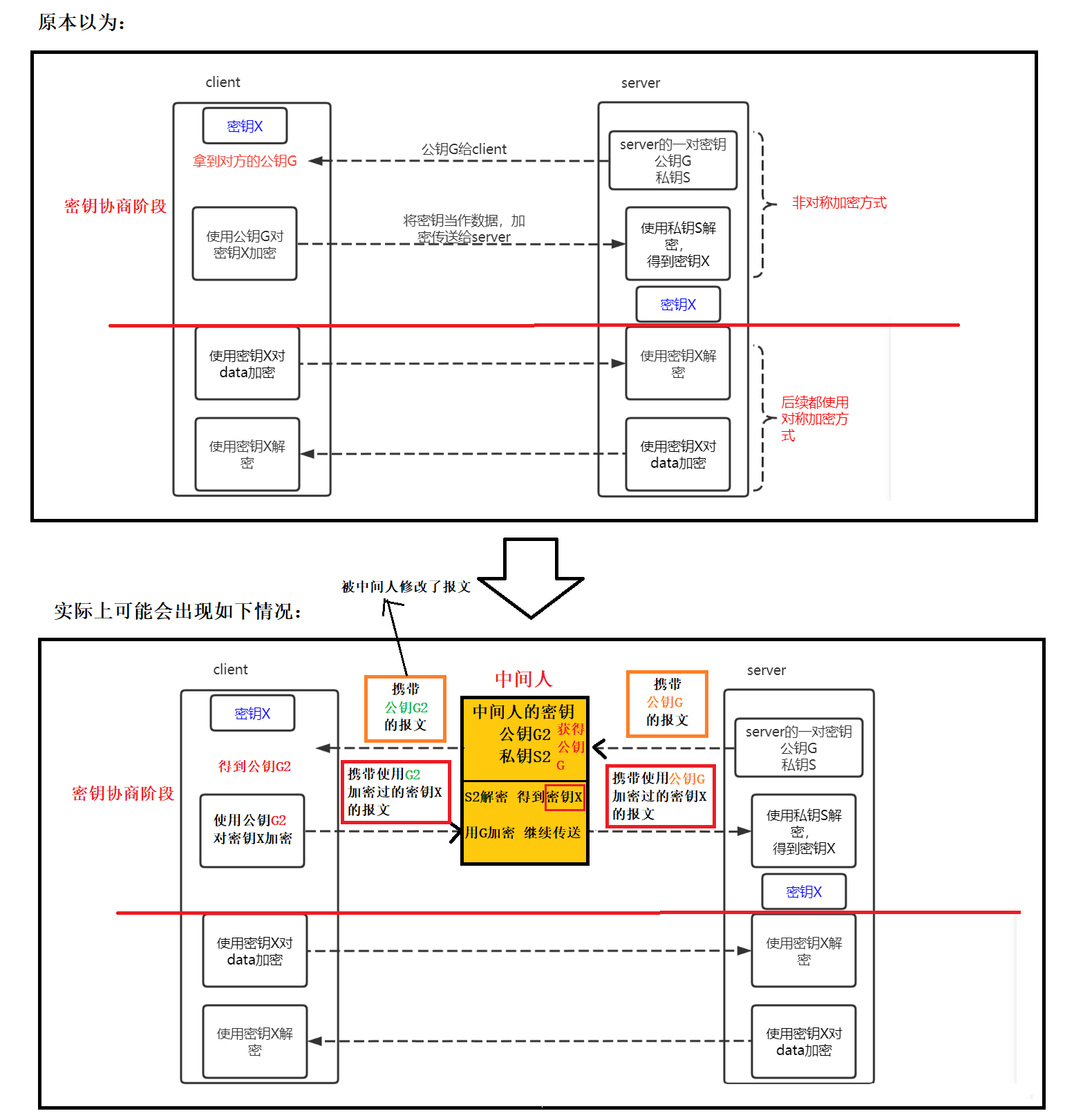
在密钥协商阶段,其中一方server将自己的公钥放在报文内,试图传送给另一方client。这个过程报文内的数据是没有被加密的,所以中间人可以截取到报文,拿到公钥G并将原本要发送的公钥G,修改成了中间人自己的公钥G2, 这样client拿到的就是公钥G2而且它对此并不知情。client方拿到公钥G2后就开始使用公钥G2对密钥进行加密,然后把含有加密后的密钥的报文发送给另一方server。这个过程中,中间人就可能会将该报文截取,并用中间人自己的私钥S2对数据解密,拿到client方的密钥。中间人再用之前截取到的公钥G对密钥重新加密,并重新封装成报文发送给server方,server方对此也并不知情。密钥都被中间人拿到了!!! 那么数据就不安全了。
上面情况的本质就是:client无法判定发来的密钥协商报文是不是从合法的服务方发来的,也无法判定发来的密钥协商报文有没有被其他人修改过。
针对这种可能出现的问题引入了证书。
证书由名叫“CA”的机构负责签发、认证和管理,所以人们也将证书称为CA证书。
证书的流程:

-
第一步:服务方向CA机构申请证书。
-
第二部:CA机构根据服务方的基本信息创建一个证书。例如,域名、公钥等。
创建证书的过程如下:
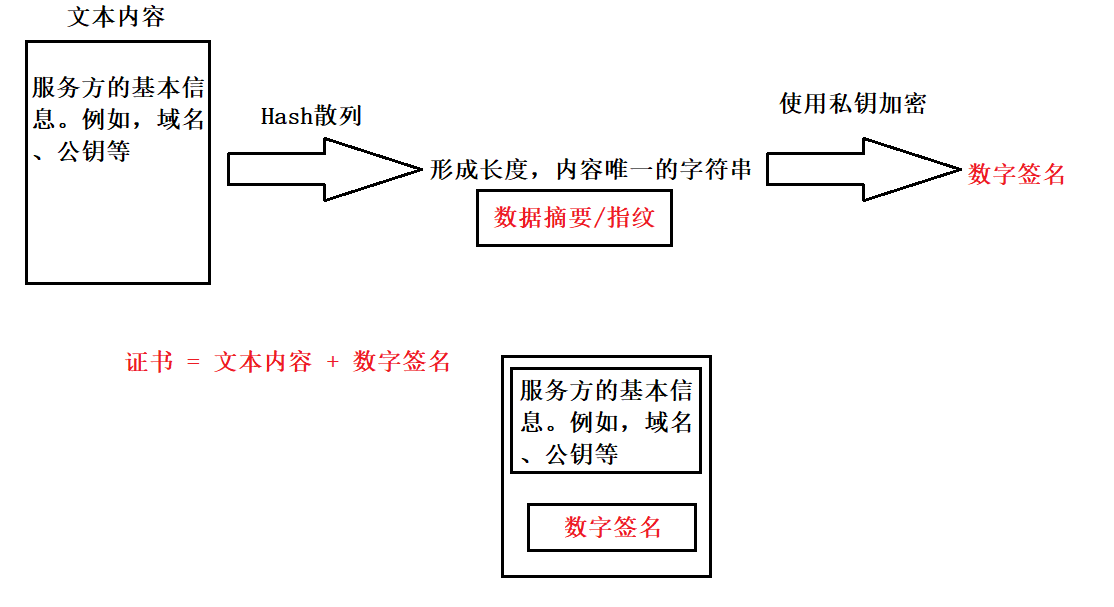
CA机构有自己的公钥和私钥,使用CA自己的私钥对数据摘要加密形成数字签名。CA的私钥只有它自己知道,换而言之,整个世界上只有CA能够重新形成对应的数字签名。 -
第三步:将生成的证书颁发给申请的服务方。
证书能够保证数据的安全的原理:
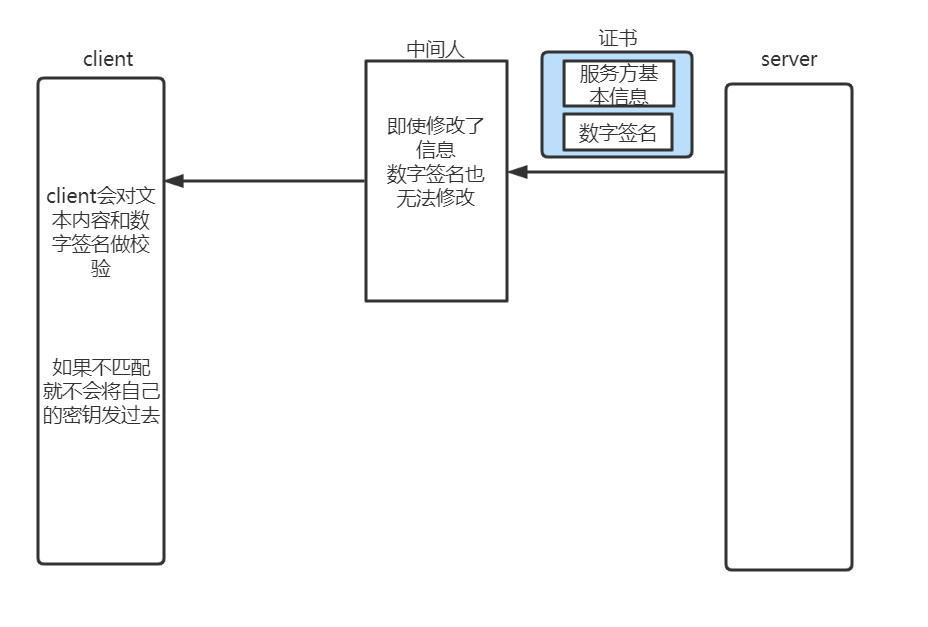
client能够对数字签名解密,是因为它有CA的公钥(数字签名用CA的私钥加密,而解密用CA的公钥)。
1、CA的公钥一般是内置的。
2、访问网址的时候,浏览器会提示用户进行安装。
最后
以上就是强健歌曲最近收集整理的关于深入浅出计算机网络OSI模型之应用层(此文重点剖析http协议)应用层概述域名和DNS域名结构域名服务器的分类文件传送协议电子邮件协议HTTPHTTPS的全部内容,更多相关深入浅出计算机网络OSI模型之应用层(此文重点剖析http协议)应用层概述域名和DNS域名结构域名服务器内容请搜索靠谱客的其他文章。








发表评论 取消回复