9.使用HDF5和大数据集
到目前为止,在本书中,我们只使用了能够装入机器主存储器的数据集。对于小数据集来说,这是一个合理的假设——我们只需加载每一个单独的图像,对其进行预处理,并允许其通过我们的网络接收。然而,对于大规模的深度学习数据集(例如,ImageNet),我们需要创建一次只访问数据集的一部分(例如,一个小批量)的数据生成器,然后允许该批数据通过网络。
幸运的是,Keras附带了一些方法,允许您使用磁盘上的rawfile路径作为训练过程的输入。您不必将整个数据集存储在内存中——只需为Keras数据生成器提供图像路径,您的图像就会被批量加载并通过网络提供。
然而,这种方法非常低效。驻留在磁盘上的每个映像都需要一个I/O操作,这会给训练管道带来延迟。训练深度学习网络已经够慢了——我们应该尽可能地避免I/O瓶颈。
一个更优雅的解决方案是为你的原始图像生成一个HDF5数据集,就像我们在第三章迁移学习和特征提取中做的那样,只是这次我们存储的是图像本身,而不是提取的特征。HDF5不仅能够存储大量的数据集,而且它对I/O操作进行了优化,特别是从文件中提取批量(称为“切片”)。正如我们将在本书的其余部分看到的,采取额外的步骤,将驻留在磁盘上的原始图像打包成一个hdf5文件,允许我们构建一个深度学习框架,可以用于快速构建数据集,并在此基础上训练深度学习网络。
在本章的剩余部分中,我将演示如何为Kaggle狗对猫比赛[3]构建HDF5数据集。然后,在下一章中,我们将使用这个HDF5数据集来训练具有创新意义的AlexNet架构[6],最终在后续章节的排行榜上获得前25名的名次。
9.1 下载Kaggle: Dogs vs. Cats
要下载Kaggle:狗对猫数据集,你首先需要在kaggle.com上创建一个帐户。从这里,进入狗与猫的主页(http://pyimg.co/xb5lb)。
您需要下载train.zip。不要下载test1.zip。zip中的图像仅用于计算预测并提交给Kaggle评估服务器。因为我们需要类标签来构建我们自己的训练和测试分割,所以我们只需要train.zip。提交您自己的预测结果超出了本书的范围,但是可以很容易地通过在test1.zip中按照sampleSubmission.csv中概述的文件格式编写您的预测来完成。
在train.zip下载完成后,解压它,你会发现一个名为train的目录——这个目录包含了我们实际的图像。标签本身可以通过检查文件名派生出来。我在下面列出了一个文件名的例子:

正如我在Starter Bundle中推荐的那样,我将在这个项目中使用以下数据结构:
请注意,我将如何将包含示例图像的train目录存储在专门用于Kaggle: Dogs vs. Cats比赛的文件夹中。从那里,我有了dogs_vs_cats目录,我们将在这里存储这个项目的代码。
现在我们已经下载了Dogs vs. Cats数据集并检查了目录结构,接下来让我们创建配置文件。
9.2 创建配置文件
现在,您可以忽略实际的Python脚本,因为我们将在下一章中回顾它们,但是看看名为config的目录。在config文件中,你会发现一个名为dogs_vs_cats_config.py的Python文件——我使用这个文件来存储项目的所有相关配置,包括:
- 输入图像的路径。
- 类标签综述。
- 关于培训、验证和测试的信息。
- HDF5数据集的路径。
- 输出模型、图、日志等的路径。
使用Pythonfile而不是JSONfile允许我包含Python代码片段,并使配置文件更有效地工作(一个很好的例子是使用os. conf操作文件路径。路径模块)。我建议你养成在自己的深度学习项目中使用基于python的配置文件的习惯,因为这将大大提高你的工作效率,并允许你通过一个文件来控制项目中的大多数参数。
9.2.1 你的第一个配置文件
# define the paths to the images directory
2 IMAGES_PATH = "../datasets/kaggle_dogs_vs_cats/train"
3
4 # since we do not have validation data or access to the testing
5 # labels we need to take a number of images from the training
6 # data and use them instead
7 NUM_CLASSES = 2
8 NUM_VAL_IMAGES = 1250 * NUM_CLASSES
9 NUM_TEST_IMAGES = 1250 * NUM_CLASSES
10
11 # define the path to the output training, validation, and testing
12 # HDF5 files
13 TRAIN_HDF5 = "../datasets/kaggle_dogs_vs_cats/hdf5/train.hdf5"
14 VAL_HDF5 = "../datasets/kaggle_dogs_vs_cats/hdf5/val.hdf5"
15 TEST_HDF5 = "../datasets/kaggle_dogs_vs_cats/hdf5/test.hdf5"
# path to the output model file
18 MODEL_PATH = "output/alexnet_dogs_vs_cats.model"
# define the path to the dataset mean
21 DATASET_MEAN = "output/dogs_vs_cats_mean.json"
22
23 # define the path to the output directory used for storing plots,
24 # classification reports, etc.
25 OUTPUT_PATH = "output"
在第2行,我定义了包含狗和猫图像的目录的路径——这些是我们将在本章稍后打包到HDF5数据集中的图像。第7-9行定义了类标签的总数(两个:一个用于dog,另一个用于cat)以及验证和测试图像的数量(每个图像2500个)。然后,我们可以在第13-15行分别指定训练、验证和测试分割的输出hdf5文件的路径。
DATASET_MEANfile将用于存储整个(训练)数据集的平均红色、绿色和蓝色像素强度值。当我们训练我们的网络时,我们将从图像中的每个像素中减去平均RGB值(测试和评估也是如此)。这种方法被称为均值减法,是一种数据归一化技术,比将像素强度缩放到[0,1]范围更常用,因为它被证明在大型数据集和更深层次的神经网络上更有效。
9.3 构建数据集
现在我们已经定义了配置文件,让我们继续实际构建我们的HDF5数据集。打开一个新文件,命名为build_dogs_vs_cats.py,插入以下代码:
# import the necessary packages
2 from config import dogs_vs_cats_config as config
3 from sklearn.preprocessing import LabelEncoder
4 from sklearn.model_selection import train_test_split
5 from pyimagesearch.preprocessing import AspectAwarePreprocessor
6 from pyimagesearch.io import HDF5DatasetWriter
7 from imutils import paths
8 import numpy as np
9 import progressbar
10 import json
11 import cv2
12 import os
第2-12行导入所需的Python包。我喜欢将我们的项目配置文件导入为项目中的第一个导入文件(第2行)。这个方法只是一种习惯,所以您可以随意将导入文件放在您喜欢的任何位置。我还将dogs_vs_cats_config重命名为简单的config,以减少编写代码时的冗长。
从这里开始,您在前几章中遇到的其他导入;然而,我想提请您注意第6行上的HDF5DatasetWriter,与我们在第3章中定义的HDF5DatasetWriter完全相同——这个类将用于将磁盘上的原始图像打包成一个单独的序列化文件。
我们还将再次使用progressbar模块,这是一个简单的实用程序库,我喜欢使用它来测量给定任务所花费的大约时间。这个模块与深度学习完全无关,但我再次发现它使用起来很方便,因为对于大型数据集,可能需要几个小时才能将图像数据集打包成HDF5格式。
接下来,让我们抓取Kaggle Dogs vs. Cats数据集中的图像路径:
第18和19行然后编码类标签。对于Kaggle狗对猫项目,我们需要三个部分:训练部分、验证部分和测试部分。
处理数据集分割:

在第23-26行,我们获取输入图像和标签,并使用它们构建训练和测试分割。但是,我们需要在第30-33行上执行另一次分割来创建验证集。验证集(几乎总是)取自训练数据。测试和验证分割的大小由NUM_TEST_IMAGES和NUM_VAL_IMAGES控制,它们都在我们的配置文件中定义。
现在我们有了我们的训练,测试和验证分割,让我们创建一个简单的列表,它将允许我们循环它们,并有效地将每个数据集中的图像写入我们的hdf5文件:
# 构建一个列表,将训练、验证和测试36 #的图像路径与其对应的标签和输出HDF5 37 #文件配对
datasets = [
("train", trainPaths, trainLabels, config.TRAIN_HDF5),
("val", valPaths, valLabels, config.VAL_HDF5),
("test", testPaths, testLabels, config.TEST_HDF5)]
# 初始化图像预处理器和RGB通道
aap = AspectAwarePreprocessor.AspectAwarePreprocessor(256, 256)
(R, G, B) = ([], [], [])
在第38行,我们定义了一个数据集列表,其中包括训练、验证和测试变量。列表中的每一项都是一个4元组,包括:1。拆分的名称(例如,培训、测试或验证)。2. 分割的各自映像路径。3.拆分的标签。4. 分割的输出hdf5文件的路径。
然后,在写入HDF5之前,我们在第45行初始化AspectAwarePreprocessor,该行用于将图像大小调整为256 × 256像素(牢记图像的宽高比)。我们还将初始化第46行上的三个列表——R、G和B,用于存储每个通道的平均像素强度。
最后,我们准备构建我们的HDF5数据集:

在第49行,我们开始对数据集列表中的每个4元组值进行循环。对于每个数据分割,我们在第52行实例化HDF5DatasetWriter。这里输出数据集的尺寸是(len(paths), 256,256,3),这意味着有len(paths)总图像,每个图像的宽度为256像素,高度为256像素,以及3个通道。
第54-58行然后初始化我们的进度条,这样我们就可以很容易地监视数据集生成的过程。同样,这个代码块(以及progressbar函数调用的其余部分)完全是可选的,所以如果您愿意,可以随意将它们注释掉。
我们检查69号线,看看我们是否在检查列车数据分割,如果是这样,我们计算红、绿、蓝通道(70号线)的平均值,并在71-73号线更新它们各自的列表。计算RGB通道的平均值只对训练集进行,如果我们希望应用均值减法归一化,这是一个要求。
第76行将相应的图像和标签添加到我们的HDF5DatasetWriter。数据分割中的所有图像被序列化到HDF5数据集之后,我们在第81行关闭写入器。
最后一步是将RGB平均值序列化到磁盘:

第86行构造了一个Python字典,其中包含训练集中所有图像的平均RGB值。请记住,每个单独的R、G和B包含数据集中每个图像的通道的平均值。计算这个列表的平均值可以得到列表中所有图像的平均像素强度值。然后,在第87-88行,将这个字典以JSON格式序列化到磁盘。
从我的输出中可以看到,每个训练、测试和验证分割都创建了一个hdf5文件。训练拆分生成耗时最长,因为拆分包含的数据最多(2m39秒)。测试和验证分拆花费的时间大大减少(≈20秒),因为这些分拆中数据较少。
看到这些文件大小,你可能会有点惊讶。原始的Kaggle dog vs. Cats图像存储在磁盘上只有595MB -为什么.hdf5文件这么大?火车。hdf5文件单独是31.45GB而测试。hdf5和val.hdf5文件几乎是4GB。为什么?
好吧,请记住,原始图像文件格式,如JPEG和PNG应用数据压缩算法,以保持较小的图像文件大小。然而,我们已经有效地删除了任何类型的压缩,并将图像存储为原始NumPy数组(即位图)。这种压缩的缺乏极大地增加了我们的存储成本,但也有助于加快我们的训练时间,因为我们不必浪费处理器时间解码图像-我们可以直接从HDF5数据集访问图像,预处理它,并通过我们的网络传递它。
让我们看看我们的RGB meanfile:

在这里,我们可以看到红色通道在数据集中所有图像的平均像素强度为124.96。蓝色通道的平均值为106.13,绿色通道的平均值为115.97。我们将构建一个新的图像预处理程序,通过在将输入图像通过我们的网络之前减去这些RGB平均值来对图像进行归一化。这种均值标准化有助于将数据“集中”在零均值附近。通常,这种标准化使我们的网络学习更快,这也是为什么我们在更大、更有挑战性的数据集上使用这种类型的标准化(而不是[0,1]缩放)。
9.4 总结
在本章中,我们学习了如何将原始图像序列化到适合于训练深度神经网络的HDF5数据集。我们将原始图像序列化到hdf5文件中,而不是简单地在训练时访问磁盘上的图像路径的小批量,原因是I/O延迟——对于磁盘上的每个图像,我们都必须执行一个I/O操作来读取图像。这种微妙的优化看起来没什么大不了的,但I/O延迟在深度学习管道中是一个巨大的问题——训练过程已经够慢了,如果我们让我们的网络难以访问我们的数据,我们只能进一步在自己的脚上砸自己的脚。
相反,如果我们将所有图像序列化到一个高效打包的hdf5文件,我们可以利用非常快速的数组片提取我们的小批量,从而大大减少I/O延迟,帮助加快训练过程。当你使用Keras库并处理一个太大的数据集时,请确保你首先考虑将你的数据集序列化为HDF5格式——正如我们将在下一章中发现的那样,它使训练你的网络更容易(和更有效)的任务。
10.在Kaggle竞赛中:狗与猫
在前一章中,我们学习了如何使用HDF5和大到无法装入内存的数据集。为此,我们定义了一个Python实用程序脚本,该脚本可用于获取图像的输入数据集,并将其序列化为一个高效的HDF5数据集。在HDF5数据集中表示图像数据集可以避免I/O延迟问题,从而加快训练过程。
例如,如果我们定义一个数据集生成器,它顺序地从磁盘加载图像,我们将需要N次读取操作,每一次读取图像一次。然而,通过将我们的图像数据集放入HDF5数据集,我们可以使用单个读取来加载批量图像。这一操作极大地减少了I/O调用的数量,并允许我们处理非常大的图像数据集。
在本章中,我们将扩展我们的工作,并学习如何定义适用于使用Keras训练卷积神经网络的HDF5数据集的图像生成器。这个生成器将打开HDF5数据集,生成要训练的网络所需的图像批和相关的训练标签,并继续这样做,直到我们的模型达到足够低的损耗/高精度。
为了完成这一过程,我们将首先探索三种新的用于提高分类精度的图像预处理程序——均值减法、patch提取和裁剪(也称为10- cutting或oversampling)。一旦我们定义了新的预处理器集,我们将继续定义实际的HDF5数据集生成器。
在此基础上,我们将实现Krizhevsky等人2012年论文《ImageNet Classification with Deep Convolutional Neural Networks[6]》中的AlexNet架构。AlexNet的这个实现将会在Kaggle狗对猫的挑战上进行训练。给定训练后的模型,我们将评估其在测试集上的性能,然后使用过采样方法进一步提高分类精度。正如我们的结果所显示的那样,我们的网络架构+裁剪方法将使我们在Kaggle dog vs. Cats挑战赛的排行榜上获得前25名的位置。
10.1 额外的图像预处理器
- 均值减法预处理程序,用于从输入图像中减去整个数据集的平均红、绿、蓝像素强度(这是一种数据规范化的形式)。
- 一种用于训练时从图像中随机提取M × N个像素区域的patch预处理器。
- 一个在测试时用于采样输入图像的五个区域(四个角+中心区域)以及它们相应的水平翻转(总共10个作物)的过采样预处理器。
使用过采样,我们可以通过CNN传递10个作物,然后对10个预测进行平均,从而提高分类精度。
10.1.1 均值化处理
让我们从平均预处理器开始。在第9章中,我们学习了如何将一个图像数据集转换为HDF5格式——这种转换的一部分涉及到计算整个数据集中所有图像的平均红、绿、蓝像素强度。现在我们有了这些平均值,我们将从输入图像中对这些值进行像素级的减法,作为数据规范化的一种形式。给定一个输入图像I和它的R, G, B通道,我们可以通过以下方法进行均值减法:
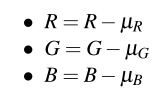
其中,图像数据集转换为HDF5格式时,计算µR,µG,µB。图10.1包含了从输入图像中减去平均RGB值的可视化——注意如何以像素的方式进行减法。


第15行使用cv2。split函数将我们的输入图像分割成各自的RGB组件。请记住,OpenCV以BGR顺序而不是RGB ([38], http://pyimg.co/ppao)表示图像,因此我们的返回元组的签名是(B, G, R)而不是(R, G,我们还将确保这些通道是浮点点数据类型,因为OpenCV图像通常表示为无符号8位整数(在这种情况下,我们不能有负值,并将执行模运算)。
第17-20行执行均值减法本身,从输入图像的RGB通道中减去各自的均值RGB值。然后,第23行将归一化的通道合并在一起,并将结果图像返回给调用函数。
10.1.2 Patch Preprocessing
PatchPreprocessor在训练过程中负责对图像的M × N个区域进行随机采样。当我们的输入图像的空间维度大于CNN的预期时,我们会应用patch预处理——这是一种帮助减少过拟合的常见技术,因此,也是一种正则化形式。在训练过程中,我们不是使用整个图像,而是裁剪其中的随机部分,并将其传递给网络(见图10.2中的作物预处理示例)。

应用这种裁剪意味着网络永远不会看到完全相同的图像(除非是随机发生的),类似于数据增强。正如你在前一章中所知道的,我们构建了一个Kaggle狗与猫的图像HDF5数据集,每个图像是256 × 256像素。然而,我们将在本章后面实现的AlexNet架构只能接受大小为227 × 227像素的图像。
那么,我们该怎么办?应用一个SimplePreprocessor将我们的每个256 × 256像素的大小调整为227 × 227?不,这将是一种浪费,特别是因为这是一个很好的机会来执行数据增强,在训练期间从256 × 256图像中随机剪切出227 × 227区域——事实上,这一过程正是Krizhevsky等人在ImageNet数据集上训练AlexNet的方法。
和其他图像预处理一样,PatchPreprocessor也会在pyimagesearch的预处理子模块中进行排序:

提取大小自的随机补丁。宽度x自我。使用scikit-learn库中的extract_patches_2d函数可以轻松实现高度。给定一个输入图像,该函数随机从图像中提取一个patch。这里我们提供了max_patches=1,这表明我们只需要输入图像中的一个随机patch。
PatchPreprocessor类看起来并不多,但它实际上是一种非常有效的方法,可以通过应用另一层数据增强来避免过拟合。在训练AlexNet时,我们将使用PatchPreprocessor。下一个预处理器CropPreprocessor将用于评估我们训练好的网络。
10.1.3 作物处理
//截止到2022.1.24日晚上23:53
截止到P109页
接下来,我们需要定义一个CropPreprocessor,负责计算用于过采样的10个作物。在我们的CNN的评估阶段,我们将裁剪输入图像的四个角+中心区域,然后对它们进行相应的水平翻转,为每个输入图像总共10个样本(图10.3)。

这十个样本将通过CNN,然后概率平均。采用这种过度抽样方法,分类准确率会提高1- 2%(在某些情况下甚至更高)。

第6行定义了CropPreprocessor的构造函数。唯一必需的参数是每个裁剪区域的目标宽度和高度。我们还可以选择指定是否应用horizontalflip(默认值为True)以及OpenCV将用于调整大小的插值算法。这些参数都存储在类中,以便在预处理方法中使用。
预处理方法只需要一个参数——我们将要应用过采样的图像。我们在第21行获取输入图像的宽度和高度,然后允许我们计算第22-26行上四个角(分别是左上、右上、右下、左下)的(x, y)坐标。然后在第29行和第30行计算图像的中心裁剪,然后在第31行添加到坐标列表中。
现在我们准备提取每一种作物:
截止到P111页
//2022.1.26日上午10:39阅读笔记

在第35行,我们循环遍历矩形作物的起始和结束(x, y)坐标。第36行通过NumPy数组切片提取作物,然后在第37行调整大小,以确保满足目标宽度和高度的尺寸。作物被添加到作物列表中。
在计算水平镜子的情况下,我们可以翻转5种原始作物中的每一种,总共留下10种作物:

然后将作物数组返回给第48行上的调用函数。使用MeanPreprocessor进行归一化,使用CropPreprocessor进行过采样,我们将能够获得比其他可能更高的分类精度。
10.2 HDF5数据集生成器
在我们能够实现AlexNet架构并在Kaggle dog vs. Cats数据集上训练它之前,我们首先需要定义一个类,负责从我们的HDF5数据集生成一批图像和标签。第9章讨论了如何将磁盘上的一组图像转换为HDF5数据集——但是我们如何将它们重新取出来呢?
以前,我们所有的图像数据集都可以加载到内存中,所以我们可以依赖Keras生成器工具来生成我们的图像和相应的标签。但是,由于我们的数据集太大了,无法装入内存,所以我们需要自己实现这个生成器。
//2022.1.26日上午截止到P112页
//2022.1.26日晚上21:36开始阅读

以上为自己设置的数据生成器。
在第7行,我们定义了HDF5DatasetGenerator的构造函数。这个类接受许多参数,其中两个是必需的,其余是可选的。我已详细说明了每一个论点如下:
•dbPath: HDF5数据集的路径,该数据集存储图像和相应的类标签。•batchSize:培训我们的网络时,小批量产量的大小。•预处理:我们将要应用的图像预处理列表(例如,MeanPreprocessor, ImageToArrayPreprocessor,等等)。•aug:默认为None,我们也可以提供一个Keras ImageDataGenerator来直接在HDF5DatasetGenerator中应用数据增强。•binarize:通常我们会在HDF5数据集中存储类标签作为单个整数;然而,正如我们所知,如果我们应用分类交叉熵或二进制交叉熵作为我们的损失函数,我们首先需要将标签二进制化为一个热编码的向量——这个开关指示是否需要进行这种二值化(默认为True)。•class:数据集中唯一的类标签的数量。这个值需要在二值化阶段准确地构造我们的一个热编码向量。
这些变量存储在第12-16行,因此我们可以从类的其余部分访问它们。第20行打开一个指向HDF5 datasetfile的文件指针。第21行创建一个方便的变量,用于访问数据集中的数据点总数。
接下来,我们需要定义一个生成器函数,顾名思义,它负责在训练网络时向Keras .fit_generator函数生成批量图像和类标签:
# 定义生成器函数
def generator(self, passes=np.inf):
# 初始化epoch变量
epoches = 0
# 持续循环
while epoches < passes:
for i in np.arange(0, self.numImages, self.batchSize):
# 循环HDF5数据集
# 从HDF5数据集中提取图片和标签
images = self.db["images"][i: i + self.batchSize]
labels = self.db["labels"][i: i + self.batchSize]
第23行定义了生成器函数,它可以接受一个可选参数。把passes值看作epoch的总数——在大多数情况下,我们不希望我们的生成器关心epoch的总数;我们的训练方法(固定次数,提前停赛等)应该对此负责。但是,在某些情况下,将这些信息提供给生成器通常是有帮助的。
在第29行,我们开始循环所需的epoch的数量——默认情况下,这个循环将无限期地运行,直到:1。Keras达到培训终止标准。2. 我们明确地停止训练过程(即ctrl + c)。
第31行开始在数据集中的每一批数据点上循环。我们从HDF5数据集的第33行和第34行提取大小为batchSize的图像和标签。
# 查看是否需要使用图片预处理进行处理
if self.preprocessors is not None:
# 初始化预处理程序的图片列表
procImages = []
# 循环图片
for image in images:
# 应用每一个预处理程序到每一个图像中
for p in self.preprocessors:
image = p.preprocess(image)
# 更新预处理列表
procImages.append(image)
# 更新图片数组为预处理之后的数组
images = np.array(procImages)
例如,我们的第一个预处理器可以通过SimplePreprocessor类将图像大小调整为固定大小。然后我们可以通过MeanPreprocessor执行均值减法。在此之后,我们需要使用ImageToArrayPreprocessor将图像转换为与keras兼容的数组。至此,应该清楚了为什么我们用预处理方法定义所有的预处理类——它允许我们在数据生成器内将预处理程序链接在一起。然后在第58行将预处理后的图像转换回NumPy数组。
假设我们提供了一个aug的实例,一个用于数据增强的ImageDataGenerator类,我们还想对图像应用数据增强:
诚然,实现HDF5DatasetGenerator可能“感觉”不像我们在做任何深度学习。毕竟,这不是一个负责从文件中生成批量数据的类吗?从技术上讲,是的,这是正确的。然而,请记住,实际的深度学习不仅仅是定义一个模型架构,初始化一个优化器,并将其应用到一个数据集。
实际上,我们需要额外的工具来帮助我们提高处理数据集的能力,特别是那些太大而无法装入内存的数据集。正如我们将在本书的其余部分看到的那样,我们的HDF5DatasetGenerator将会有很多次用得上——当您开始创建自己的深度学习应用程序/实验时,您将会感到非常幸运,因为它在您的工具箱中。
10.3 实现AlexNet架构
现在让我们继续实现Krizhevsky等人的开创性AlexNet架构。AlexNet架构的总结见表10.1。
注意我们的输入图像被假设为227 × 227 × 3像素——这实际上是AlexNet的正确输入大小。如第9章所述,在最初的出版物中,Krizhevsky等人报道了输入空间维度为224 × 224 × 3;然而,由于我们知道224 × 224不可能通过平铺一个11 × 1的内核来实现,所以我们假设出版物中可能有一个打印错误,而224 × 224实际上应该是227 × 227。
AlexNet的第一个块应用了96,11 × 11内核,stride为4 × 4,接着是RELU激活和最大池化,池大小为3 × 3, stride为2 × 2,结果输出体积为55 × 55。
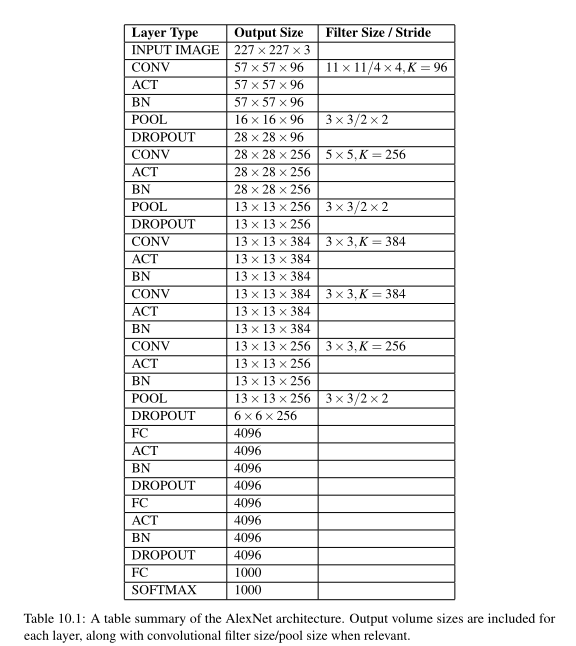
然后我们应用第二个CONV => RELU => POOL层,这一次使用256个5 × 5的过滤器和1 × 1的步幅。在使用max pooling(池大小为3 × 3,步幅为2 × 2)后,我们得到了13 × 13的体积。
接下来,我们应用(CONV => RELU) * 3 => POOL。前两个CONV层学习384个3 × 3个滤波器,而最后一个CONV层学习256个3 × 3个滤波器。
在另一个最大池操作之后,我们到达了两个FC层,每个层有4096个节点,中间有RELU激活。网络中的最后一层是我们的softmax分类器。
当AlexNet首次被引入时,我们还没有像批处理归一化这样的技术——在我们的实现中,我们将在激活后包括批处理归一化,这是使用卷积神经网络的大多数图像分类任务的标准。我们还将在每次POOL操作后包含非常少量的dropout,以进一步帮助减少过拟合。
第2-11行导入我们需要的Keras类——在本书的前几章中,我们已经使用了所有这些层,所以我将跳过对每一个层的显式描述。我唯一想让你们注意的是第10行,我们在这里导入了l2函数——这个方法将负责将l2权值衰减应用到网络中的权值层。
第15行定义了AlexNet的构建方法。就像本书前面的所有例子一样,构建方法是构建实际网络体系结构并将其返回给调用函数所必需的。这个方法接受四个参数:输入图像的宽度、高度和深度,然后是数据集中类标签的总数。一个可选参数,reg,控制我们将应用到网络的L2正则化的数量。对于更大、更深层次的网络,应用正则化对于减少过拟合,同时提高验证和测试集的准确性至关重要。
10.4 训练AlexNet关于Kaggle:狗对猫

在第26行,我们从磁盘加载了序列化的RGB方法——这是我们的训练数据集上每个Red、Green和Blue通道的方法。这些值稍后将被传递到一个MeanPreprocessor中进行均值减法规范化。
第29行实例化了一个SimplePreprocessor,用于将输入图像的大小调整到227 × 227像素。这个预处理器将用于验证数据生成器,因为我们的输入图像是256 × 256像素;然而,AlexNet只打算处理227 × 227的图像(这就是为什么我们需要在验证过程中调整图像的大小)。
第30行实例化了一个PatchPreprocessor——这个预处理器将在训练期间从256 × 256输入图像中随机取样227 × 227个区域,作为第二种形式的数据增强。
然后,我们在第31行使用各自的Red、Green和Blue平均值初始化MeanPreprocessor。最后,ImageToArrayPreprocessor(第32行)用于将图像转换为与keras兼容的数组。
# initialize the training and validation dataset generators
35 trainGen = HDF5DatasetGenerator(config.TRAIN_HDF5, 128, aug=aug,
36 preprocessors=[pp, mp, iap], classes=2)
37 valGen = HDF5DatasetGenerator(config.VAL_HDF5, 128,
38 preprocessors=[sp, mp, iap], classes=2)
第35和36行创建我们的训练数据集生成器。在这里,我们提供了训练hdf5文件的路径,表明我们应该使用128张图像的批处理大小、数据增强和三个预处理处理器:patch、mean和image to array。
第37和38行负责实例化测试生成器。这一次,我们将提供验证hdf5文件的路径,使用128个批处理大小,不增加数据,使用一个简单的预处理器而不是补丁预处理器(因为数据增加并不应用于验证数据)。

然后,我们在第43行和第44行上初始化AlexNet,表示每个输入图像的宽度为227像素,高度为227像素,3个通道,数据集本身将有两个类(一个用于狗,另一个用于猫)。我们还将应用0.0002的小正则化惩罚来帮助克服过拟合,并提高我们的模型对测试集的泛化能力。
我们将使用二元交叉熵而不是分类交叉熵(第45和46行),因为这只是一个两类分类问题。我们还将在第51行上定义TrainingMonitor回调,这样我们就可以在网络训练时监视它的性能。

为了使用我们的HDF5DatasetGenerator在Kaggle dog vs. Cats数据集上训练AlexNet,我们需要使用模型的fit_generator方法。首先,我们传入train .generator(), HDF5生成器用于构造小批量的训练数据(第55行)。为了确定每个epoch的批处理数量,我们将训练集中的图像总数除以批处理大小(第56行)。我们在第57行和第58行对验证数据执行同样的操作。最后,我们将指出AlexNet将被训练为75个时代。
10.5 评价AlexNet
//截止到P122页
//2022.1.27下午14:49开始阅读
第2-12行导入所需的Python包。第2行为dog vs. Cats挑战导入了Python配置文件。我们还将在第3-6行导入图像预处理程序,包括ImageToArrayPreprocessor、SimplePreprocessor、MeanPreprocessor和CropPreprocessor。HDF5DatasetGenerator是必需的,因此我们可以访问我们的数据集的测试集,并使用我们的预训练模型获得对该数据的预测。
现在我们的导入已经完成,让我们从磁盘加载RGB意思,初始化我们的图像预预处理,并加载预训练的AlexNet网络:

在我们应用oversampling和10- cutting之前,我们先用原始的测试图像作为我们网络的输入,在测试集上获得一个基线:
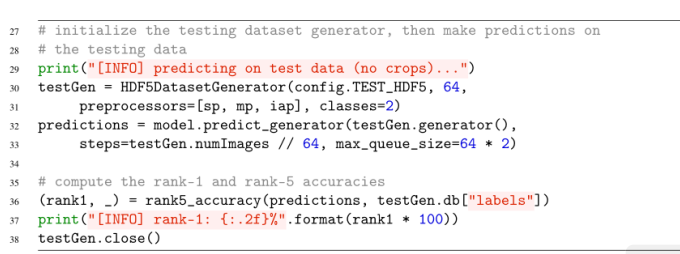
第30和31行初始化HDF5DatasetGenerator以访问64个映像的批量测试数据集。因为我们要获得基线,所以我们将只使用SimplePreprocessor将256 × 256输入图像的大小调整为227 × 227像素,然后是均值归一化和将批处理转换为与keras兼容的图像数组。然后,第32和33行使用生成器对数据集计算AlexNet。
根据我们的预测,我们可以在测试集上计算我们的准确性(第36-38行)。请注意,这里我们只关心rank1的准确性,这是因为dog vs. Cats是一个2类数据集——计算2类数据集的rank-5的准确性通常会报告100%的分类准确性。
现在我们有了标准评估技术的基线,让我们继续讨论过采样:

在第42行和第43行,我们重新初始化HDF5DatasetGenerator,这一次指示它只使用MeanPreprocessor—我们将在管道的后面应用过采样和Keras-array转换。如果我们想让评估的进度显示在屏幕上,第47-50行还将初始化progressbar小部件到屏幕上。
鉴于重新实例化的testGen,我们现在准备应用10-crop技术:
# loop over a single pass of the test data
53 for (i, (images, labels)) in enumerate(testGen.generator(passes=1)):
54 # loop over each of the individual images
55 for image in images:
56 # apply the crop preprocessor to the image to generate 10
57 # separate crops, then convert them from images to arrays
58 crops = cp.preprocess(image)
59 crops = np.array([iap.preprocess(c) for c in crops],
60 dtype="float32")
61
62 # make predictions on the crops and then average them
63 # together to obtain the final prediction
64 pred = model.predict(crops)
65 predictions.append(pred.mean(axis=0))
66
67 # update the progress bar
68 pbar.update(i)
在第53行,我们开始循环测试生成器中的每一批图像。通常情况下,HDF5DatasetGenerator被设置为永远循环,直到我们明确地告诉它停止(通常通过Keras在训练时设置最大迭代次数);然而,由于我们现在正在进行评估,我们可以提供passes=1来表示测试数据只需要循环一次。
然后,对于图像批处理中的每一幅图像(第55行),我们在第58行上应用10-crop预处理程序,将图像转换为10幅227 × 227图像的数组。这227 × 227个作物是从原来的256 × 256批次中提取的,根据:左上角•右上角•右下角•左下角•对应的水平翻转
最后模块得到过采样的准确性:
# compute the rank-1 accuracy
71 pbar.finish()
72 print("[INFO] predicting on test data (with crops)...")
73 (rank1, _) = rank5_accuracy(predictions, testGen.db["labels"])
74 print("[INFO] rank-1: {:.2f}%".format(rank1 * 100))
75 testGen.close()
结果表明,在测试集上,我们达到了92.60%的准确率。然而,通过应用10作物过采样方法,我们能够将分类精度提高到94.00%,提高1.4%,这都是通过简单地将输入图像中的多个作物取平均值来实现的。这个简单、不复杂的技巧是在评估你的人际关系时获得额外几个百分点的简单方法。
10.6 如何在Kaggle竞赛:dogs vs cats比赛中获得前5名
答案是迁移学习,特别是通过特征提取的迁移学习。虽然ImageNet数据集包含1000个对象类别,但其中很大一部分包括了狗和猫。因此,在ImageNet上训练的网络不仅可以告诉你一张图片是一只狗还是一只猫,还可以告诉你这个动物的具体品种。鉴于在ImageNet上训练过的网络必须能够区分这种细粒度的动物,很自然地可以假设,从预先训练过的网络中提取的特征很可能会在Kaggle狗对猫排行榜上占据榜首。
为了验证这个假设,让我们首先从预先训练的ResNet架构中提取特征,然后在这些特征的基础上训练一个Logistic回归分类器。
10.6.1 使用ResNet提取特征
//截止到P128页
2022.1.27日晚上18:21截止
import sys
import os
sys.path.append(os.path.abspath('..'))
# 导入需要的库
from keras.applications import ResNet50
from keras.applications import imagenet_utils
from keras.preprocessing.image import img_to_array
from keras.preprocessing.image import load_img
from sklearn.preprocessing import LabelEncoder
from pyimagesearch.io import HDF5DatasetWriter
from imutils import paths
import numpy as np
import progressbar
import argparse
import random
import os
# 创建命令行参数
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True, help="path to input dataset")
ap.add_argument("-o", "--output", required=True, help="path to output HDF5 file")
ap.add_argument("-b", "--batch-size", type=int, default=32, help="batch size of images to be passed through network")
ap.add_argument("-s", "--buffer-size", type=int, default=1000, help="size of feature extraction buffer")
args = vars(ap.parse_args())
# 存储batch_size到变量中
bs = args["batch_size"]
# 抓取我们将描述的图像列表,然后随机打乱他们的排序,以方便训练和测试分割通过数组切片
print("[INFO] loading images...")
imagePaths = list(paths.list_images(args["dataset"]))
random.shuffle(imagePaths)
# 从图像路径中提取类标签,然后对类标签进行编码
labels = [p.split(os.path.sep)[-2] for p in imagePaths]
le = LabelEncoder()
labels = le.fit_transform(labels)
# 加载ResNet网络
print("[INFO] loading network...")
model = ResNet50(weights="imagenet", include_top=False) # 去掉网络最后的FC层
# 初始化HDF5数据集写入器,然后存储类标签在数据集中
dataset = HDF5DatasetWriter.HDF5DatasetWriter((len(imagePaths), 2048), args["output"],
dataKey="features", bufSize=args["buffer_size"])
dataset.storeClassLabels(le.classes_)
# 初始化进度条
widgets = ["Extracting Features: ", progressbar.Percentage(), " ", progressbar.Bar(), " ", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval=len(imagePaths), widgets=widgets).start()
# 循环图像在构造的数组中,按照每次bs个数据进行循环
for i in np.arange(0, len(imagePaths), bs):
# 得到当前批次的路径,和类标签,并创建当前的保存图片数组
batchPaths = imagePaths[i:i + bs]
batchLabels = labels[i:i + bs]
batchImages = []
# 循环当前批量中的图片对象
for (j, imagePath) in enumerate(batchPaths):
# 使用Keras库保证提取的图片大小为特定的224 * 224
image = load_img(imagePath, target_size=(224, 224))
# 将图片转换为像素数组
image = img_to_array(image)
# 预处理图像:扩展维度;
image = np.expand_dims(image, axis=0)
# 从ImageNet数据集减去平均RGB像素强度
image = imagenet_utils.preprocess_input(image)
# 增加图片到batchImages数组中
batchImages.append(image)
# 将图片传入到cnn中,然后将输出作为实际的特征
batchImages = np.vstack(batchImages)
features = model.predict(batchImages, batch_size=bs)
# 重塑特征,使每个图像由' maxpooling2d '输出的一个扁平的特征向量表示
# 这里的第一维为batch_size的大小
features = features.reshape((features.shape[0], 2048))
# 增加特征和标签到hdf5格式文件中
dataset.add(features, batchLabels)
# 在progressBar中更新i
pbar.update(i)
# 关闭数据集
dataset.close()
pbar.finish()
10.7 总结
在本章中,我们深入研究了Kaggle Dogs vs. Cats数据集,并研究了在该数据集上获得> 90%分类精度的方法:1. 从零开始训练AlexNet。2. 应用ResNet迁移学习。
AlexNet架构是Krizhevsky等人在2012年[6]首次介绍的开创性作品。使用我们的AlexNet实现,我们达到了94%的分类精度。这是一个非常可观的准确性,特别是对于一个从零开始训练的网络。进一步的准确性可以通过以下方法获得:
- 获取更多的训练数据。
- 应用更积极的数据增强。
- 深化网络。
然而,我们获得的94%还不足以进入排行榜前25名,更不用说前5名了。因此,为了获得前5名,我们依赖于通过特征提取的迁移学习,具体来说,是在ImageNet数据集上训练的ResNet50架构。由于ImageNet包含了许多狗和猫的例子,应用一个预先训练的网络来完成这项任务是一个自然的,简单的方法,以确保我们以较少的努力获得更高的准确性。正如我们的结果所显示的,我们能够获得98.69%的分类准确率,高到足以在Kaggle狗对猫排行榜上获得第二名。
11. GoogLeNet
截止到2022.1.27晚上22:51
截止到P133页
//2022.1.28日上午9:45开始阅读
在本章中,我们将研究由Szegedy等人在2014年的论文《深度卷积[17]》中介绍的GoogLeNet架构。这篇论文之所以重要,有两个原因。首先,与AlexNet和VGGNet相比,模型架构很小(权重本身≈28MB)。作者能够通过删除全连接层,而不是使用全局平均池,在网络架构大小上获得如此显著的下降(同时仍然增加了整个网络的深度)。CNN中的大部分权重都可以在密集的FC层中找到——如果这些层可以被移除,那么内存节省将是巨大的。
其次,Szegedy等人的论文在构建整体宏观体系结构时,利用了网络或微体系结构中的网络。到目前为止,我们只看到了一个网络的输出直接输入到下一个网络的顺序神经网络。现在我们将看到微架构,在架构的其余部分中使用的小构建块,其中一层的输出可以分成许多不同的路径,然后再重新连接。
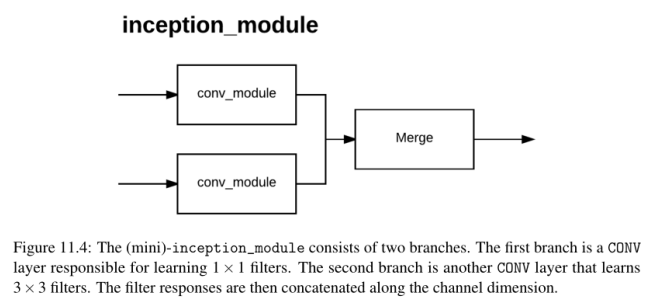
具体来说,Szegedy等人将Inception模块贡献给了深度学习社区,这是一个适合卷积神经网络的构建块,使其能够学习使用了多个不同大小过滤器的CONV层,将模块转变为一个多级特征提取器。
诸如《盗梦空间》之类的微架构启发了其他重要的变体,包括ResNet[24]中的剩余模块和SqueezeNet[32]中的Fire模块。我们将在本章后面讨论Inception模块(及其变体)。一旦我们检查了Inception模块并确保我们知道它是如何工作的,然后我们将实现一个名为“MiniGoogLeNet”的较小版本的googlet——我们将在cifa10数据集上训练这个架构,并获得比我们之前任何一章更高的准确性。
从那里,我们将移动到更困难的cs231n微型ImageNet挑战[4]。这个挑战是为斯坦福大学cs231n卷积神经网络视觉识别课程[39]的学生提供的,作为他们期末项目的一部分。这意味着让他们体验到在现代架构上进行大规模深度学习所面临的挑战,而不需要像处理整个ImageNet数据集那样费时费力。
通过在Tiny ImageNet上从头开始训练GoogLeNet,我们将演示如何获得在Tiny ImageNet排行榜上的排名。在下一章中,我们将使用从从零开始训练的ResNet模型中获得最高的排名。
11.1 Inception模块(及其变体)
现代最先进的卷积神经网络利用了微架构,也称为网络内网络模块,最初由Lin等人提出。我个人更喜欢术语微体系结构,因为它更好地将这些模块描述为总体宏观体系结构上下文中的构建块(即,您实际构建和训练的内容)。
微架构是由深度学习实践者设计的小构件,用于使网络学习(1)更快(2)更有效,同时增加网络深度。这些微架构构建块与常规的层类型如CONV、POOL等一起堆叠,形成整体的宏观架构。
Inception模块的中的思想:
- 在给定的CONV层中,很难决定你需要学习的过滤器的大小。它们应该是5 × 5的过滤器吗?那么3 × 3滤镜呢?我们应该使用1 × 1过滤器学习局部特征吗?相反,为什么不把它们全部学习,让模型来决定呢?在Inception模块中,我们学习了所有三个5 × 5,3 × 3和1 × 1滤波器(并行计算它们),沿着通道尺寸连接得到的特征映射。GoogLeNet架构中的下一层(可能是另一个Inception模块)接收这些连接的、混合的过滤器,并执行相同的过程。总的来说,这个过程使得GoogLeNet既可以通过较小的卷积来学习局部特征,也可以通过较大的卷积来学习抽象特征——我们不必牺牲较小的特征以牺牲抽象水平。
- 通过学习多个过滤器的大小,我们可以将该模块转换为一个多级特征提取器。5 × 5滤波器有更大的接受容量,可以学习更抽象的特征。根据定义,1 × 1滤波器是局部的。3 × 3过滤器是两者之间的一种平衡。
11.1.1 Inception
特别要注意Inception模块如何从输入层分支到四个不同的路径。Inception模块中的第一个分支只是从输入中学习一系列1 × 1的局部特性。
第二批首先应用1 × 1卷积,不仅作为学习局部特征的一种形式,而是作为降维。根据定义,更大的卷积(即3 × 3和5 × 5)需要执行更多的计算。因此,如果我们可以通过应用1 × 1卷积来降低这些较大滤波器的输入的维数,我们就可以减少我们的网络所需的计算量。因此,在第二分支的1 × 1 CONV中学习到的滤波器数量总是小于随后直接学习到的3 × 3个滤波器的数量。
第三个分支与第二个分支应用相同的逻辑,只是这次的目标是学习5 × 5个滤波器。我们再次通过1 × 1卷积降低维数,然后将输出输入5 × 5滤波器。
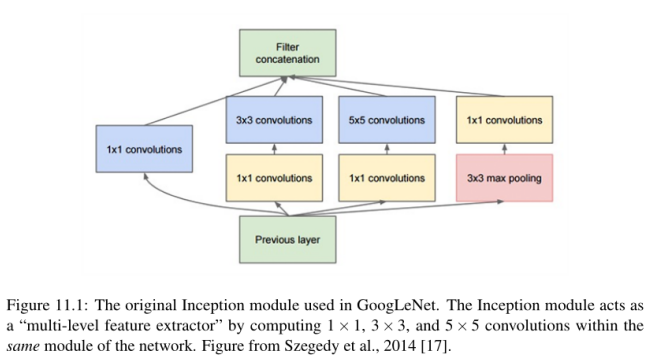
Inception模块的第四个也是最后一个分支以1 × 1的步幅执行3 × 3最大池-这个分支通常被称为池投影分支。历史证明,模型执行池有能力获得更高的精度,但现在我们知道通过Springenberg等人的作品在他们一份2014年的论文,追求简单性:所有卷积网络[41],这未必是真的,而池层可以使用CONV替换层减少体积大小。
在Szegedy等人的例子中,添加这个POOL层只是因为他们认为cnn需要它们来合理地执行。然后将POOL的输出输入另一组1 × 1的卷积来学习局部特征。
最后,Inception模块的所有四个分支汇聚在一起,它们沿着通道维度连接在一起。在实现期间(通过零填充)需要特别注意,以确保每个分支的输出具有相同的卷大小,从而允许将输出连接起来。然后Inception模块的输出被送入网络中的下一层。在实践中,在执行池操作以减小卷大小之前,我们经常将多个Inception模块堆叠在一起。
11.1.2 Miniception
当然,最初的Inception模块是为GoogLeNet设计的,这样它可以在ImageNet数据集上训练(假设每个输入图像是224 × 224 × 3),并获得最先进的精度。对于需要较少网络参数的较小数据集(图像空间维度较小),我们可以简化Inception模块。
我最初是在@ericjang11 (https://twitter.com/ericjang11)和@pluskid (https://twitter.com/pluskid)的推文中意识到“Miniception”模块的,他们在训练cifar10数据集时漂亮地看到了《盗梦空间》的一个更小的变体(图11.2;感谢@ericjang11和@pluskid)。
在做了一些研究之后,我们发现这张图来自于Zhang等人2017年发表的《理解深度学习需要重新思考泛化[42]》。图的最上面一行描述了在他们的MiniGoogLeNet实现中使用的三个模块:
左:一个卷积模块,负责执行卷积、批量归一化和激活。
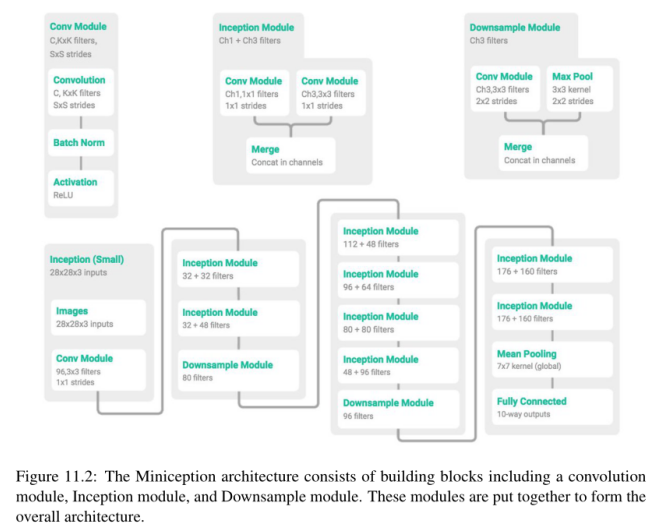
中间:Miniception模块执行两组卷积,一组用于1 × 1滤波器,另一组用于3 × 3滤波器,然后将结果连接起来。在3 × 3过滤器之前没有进行降维,因为(1)输入体积将会更小(因为我们将使用CIFAR-10数据集)和(2)以减少网络中的参数数量。
右图:一个下采样模块,它应用卷积和最大池化来降低维数,然后通过滤波器维数连接。
然后使用这些构建块在最下面一行构建MiniGoogLeNet架构。在这里您会注意到,作者将批处理规范化置于激活之前(大概是因为Szegedy等人也这么做了),而不是现在在实现cnn时推荐的方法。
在本书中,我坚持原作者的工作的实现,将批处理规范化放在激活之前,以便复制结果。在您自己的实验中,可以考虑交换这个顺序。
在下一节中,我们将实现MiniGoogLeNet架构,并将其应用到CIFAR-10数据集。从那里,我们将准备好实现完整的Inception模块,并解决cs231n Tiny ImageNet挑战。
11.2 MiniGoogLeNet on CIFAR-10
在本节中,我们将使用Miniception模块实现MiniGoogLeNet架构。然后,我们将在CIFAR-10数据集上训练MiniGoogLeNet。正如我们的结果所显示的,该架构将在CIFAR-10上获得> 90%的精度,远远好于我们之前的所有尝试。
11.2.1 实现MiniGoogLeNet
第2-13行导入所需的Python包。我们需要使用Model类(第11行),而不是导入Sequential类,其中一层的输出直接提供给下一层。使用Model而不是Sequential将允许我们创建一个带有分隔和分叉的网络图,就像Inception模块中那样。您还没有看到的另一个导入是第12行中的concatenate函数。顾名思义,这个函数接受一组输入,并沿着给定的轴(在本例中是通道维度)将它们连接起来。

conv_module函数负责应用卷积,然后是批量归一化,最后是激活。该方法的参数如下:
x:函数的输入层。K:数字过滤我们的CONV层将要学习。•kX和kY:将要学习的每个Kfilters的大小。•stride: CONV层的stride。chanDim:通道维度,由“通道最后”或“通道先”的顺序派生而来。填充:用于CONV层的填充类型。
在第19行,我们创建了卷积层。Conv2D的实际参数与以前的架构(如AlexNet和VGGNet)中的示例相同,但这里的变化是我们如何向给定层提供输入。
因为我们使用的是Model而不是Sequential来定义网络架构,所以我们不能调用Model。添加,因为这意味着一个层的输出将顺序地进入下一层。相反,我们在函数调用末尾的圆括号中提供输入层,它被称为Functional API。模型中的每个层实例都可以在一个张量上调用,并返回一个张量。因此,在对象被实例化后,我们可以通过将其作为函数调用来为给定的层提供输入。
然后,将Conv2D层的输出传递到第20行上的BatchNormalization层。BatchNormalization的输出然后经过ReLU激活(第21行)。如果我们要构造一个图形来帮助我们可视化conv_module,它将看起来像图11.3。

MiniGoogLeNet架构的conv_module。这个模块不包含分支,是一个简单的CONV => BN => ACT。
首先应用卷积,然后是批量归一化,然后是激活。请注意,该模块没有执行任何分支。这将随着下面的inception_module的定义而改变:

我们的Mininception模块将执行两组卷积——1×1 CONV和3×3 CONV。这两组卷积将并行执行,所得到的特性将跨越通道维度连接起来。
行30和31使用方便conv_module我们定义学习numK1x1filters(1×1)。32和33行然后再应用conv_module学习numK3x3filters(3×3)。通过使用conv_module函数我们可以重用代码,没有膨胀MiniGoogLeNet类插入许多块CONV = > BN = > RELU块——这堆积通过conv_module简单地处理。
注意,1 × 1和3 × 3 Conv2D类的输入都是x,层的输入。当使用顺序类时,这种类型的层结构是不可能的。但是,通过使用Model类,我们现在可以让多个层接受相同的输入。一旦我们有了conv_1x1和conv_3x3,我们就把它们在通道维上连接起来。
要形象化“Mini”-Inception模块,请看图11.4。我们的1 × 1和3 × 3 CONV层接受一个给定的输入并应用它们各自的卷积。然后将两个卷积的输出连接起来(第33行)。我们被允许连接图层输出,因为两个卷积的输出体积大小是相同的,因为padding="same"。
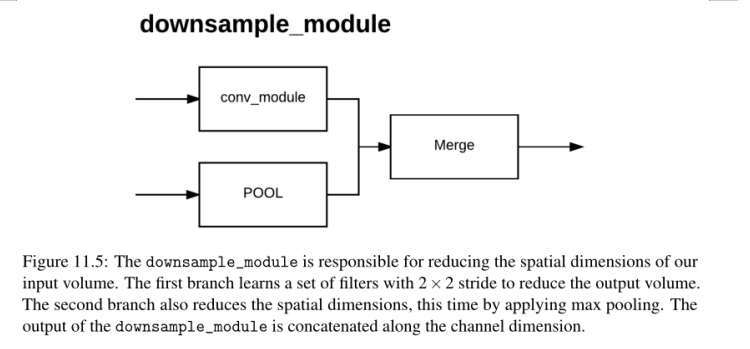
接下来是downsample_module,顾名思义,它负责减小输入量的空间维度:

这种方法需要我们传入一个输入x,我们的卷积层将学习的数字过滤器K,以及用于批处理归一化和通道连接的chanDim。
downsample_module的第一个分支学习了一组K, 3 × 3滤波器,使用2 × 2的步幅,从而减少了输出体积大小(第43和44行)。我们在第45行(第二个分支)上应用max pooling,同样使用3 × 3的窗口大小和2 × 2的stride来减少体积大小。然后将conv_3x3和池输出连接起来(第46行)并返回给调用函数。

第一个Inception模块(行70)学习了1 × 1和3 × 3 CONV层的32个滤波器。当连接时,该模块输出一个K = 32 + 32 = 64滤波器的音量。
第二个Inception模块(第71行)学习32,1 × 1滤波器和48,3 × 3滤波器。再次,当串联起来时,我们看到输出音量大小是K = 32 + 48 = 80。下采样模块减少了我们的输入体积大小,但保持相同数量的过滤器学习为80。
接下来,在应用下样例之前,让我们将四个Inception模块叠加在一起,让googlet学习更深入、更丰富的特性:

注意,在一些层中,我们学习的1 × 1过滤器比3 × 3过滤器多,而其他Inception模块学习的3 × 3过滤器比1 × 1过滤器多。这种交替模式是有意为之的,经过Szegedy等人的多次实验证明了这一点。当我们在本章后面实现更深层的GoogLeNet变体时,我们也会看到这种模式。
继续我们对Zhang等人的图11.2的实现,我们现在将应用另外两个初始模块,后面是一个全局池和dropout:
# two Inception modules followed by global POOL and dropout
82 x = MiniGoogLeNet.inception_module(x, 176, 160, chanDim)
83 x = MiniGoogLeNet.inception_module(x, 176, 160, chanDim)
84 x = AveragePooling2D((7, 7))(x)
85 x = Dropout(0.5)(x)
83行后的输出体积大小为7 × 7 × 336。应用7 × 7的平均池化可以将体积大小减少到1 × 1 × 336,从而减轻了应用许多密集的全连接层的需要——相反,我们只是对卷积的空间输出进行平均。在第85行,Dropout以50%的概率被应用,以帮助减少过拟合。
最后,根据我们想要学习的类的数量,加入我们的softmax分类器:

实际的Model在第93行被实例化,在那里我们传递输入、层(x,包括内置的分支)和网络的可选名称。构造的体系结构返回给第96行上的调用函数。
11.2.2 训练和评价MiniGoogLeNet在CIFAR-10数据集上

第2行和第3行配置了matplotlib,这样我们就可以将图形和绘图保存到后台的磁盘上。然后,在第6-15行导入其余所需的包。第7行导入了我们的MiniGoogLeNet实现。
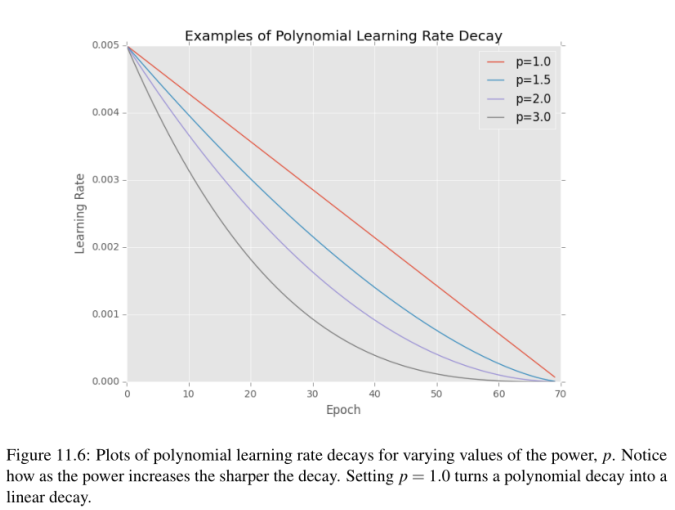
还要注意我们是如何在第10行中导入LearningRateScheduler类的,这意味着我们将为优化器在训练网络时定义一个特定的学习速率。具体来说,我们将定义一个多项式衰减学习速率计划。多项式学习速率调度器将遵循如下公式:
其中,α0是初始学习率,e是当前历元数,emax是我们要执行的最大历元数,p是多项式的幂。应用这个方程可以得到当前时期的学习率α。
给定最大的epoch数,学习速率将衰减到零。这个学习速率调度器还可以通过将功率设置为1.0来实现线性化——这是经常做的——实际上,我们在这个例子中将要做的就是这样。在图11.6中,我包含了一些使用最多70个epoch、初始学习速率为5e - 3和变化幂次的多项式学习速率调度示例。注意,随着功率的增加,学习速度下降得越快。使用1.0的幂将曲线变成线性衰减。
def poly_decay(epoch):
# 初始化最大epochs, 基础学习率,和幂p
maxEpochs = NUM_EPOCHS
baseLR = INIT_LR
power = 1.0
# 基于多项式衰减计算新的学习率
alpha = baseLR * (1 - (epoch / maxEpochs)) ** p
return alpha
根据我们在Starter Bundle第16章中对学习速率调度程序的讨论,您知道学习速率调度函数只能接受一个参数,即当前epoch。然后,我们初始化网络允许训练的maxEpochs(这样我们可以将学习速率衰减到零)、基本学习速率以及多项式的幂。
基于多项式衰减计算新的学习率在第30行处理—这个方程的输出将根据所提供的参数与我们的图精确匹配。新的学习率返回给第33行上的调用函数,以便优化器可以更新它的内部学习率。同样,关于学习速率调度器的更多信息,请参阅Starter Bundle的第16章。
# 训练网络
print("[INFO] compiling model...")
opt = SGD(lr=INIT_LR, momentum=0.9)
model = MiniGoogLeNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
# 训练网络
print("[INFO] training network...")
model.fit_generator(aug.flow(trainX, trainY, batch_size=64),
validation_data=(testX, testY), steps_per_epoch=len(trainX) // 64,
epochs=NUM_EPOCHS, callbacks=callbacks, verbose=1)
# 像磁盘中保存训练好的Model
print("[INFO] serializing network...")
model.save(args["model"])
第75行使用INIT_LR初始学习速率初始化SGD优化器。一旦训练开始,这个学习速率将通过LearningRateScheduler更新。MiniGoogLeNet架构本身将接受宽度为32像素、高度为32像素、深度为3个通道以及总共10个类标签的输入图像。第82-84行使用小型批处理大小64开始训练过程,总共训练NUM_EPOCHS。培训完成后,第88行将我们的模型序列化到磁盘。
11.2.3 MiniGooLeNet:实验1
在实践者Bundle的这一点上,理解实际的思维模式、过程和您需要执行的实验集,以获得给定数据集上的高精度模型,这对您来说变得非常重要。
在这个bundle和Starter bundle的前几章中,您只是刚刚接触了一些内容—仅仅查看一段代码、理解它的功能、执行它并查看输出就足够了。这是理解深度学习的一个很好的起点。
然而,既然我们正在处理更高级的架构和具有挑战性的问题,您就需要理解执行实验、检查结果、然后更新参数背后的过程。在本章中,我将对这种科学方法进行简要介绍以及下一章ResNet。如果您有兴趣掌握执行实验的能力,检查结果,并对下一个最佳行动方案做出明智的假设,那么请参阅ImageNet Bundle中更高级的课程。
在我第一次使用GoogLeNet的实验中,我用SGD优化器以1e−3的初始学习速率开始。然后,学习速率在70个时期内线性衰减。为什么70时代?两个原因:
- 先验知识。在阅读了数百篇深度学习论文、博客文章、教程,更不用说进行自己的实验之后,你会开始注意到一些数据集的模式。以我为例,我从我职业生涯中使用CIFAR10数据集进行的以前的实验中知道,训练CIFAR10通常需要50-100个时期。网络结构越深(有足够的正则化),随着学习速率的降低,通常我们可以训练我们的网络更长的时间。因此,我选择了70个epoch作为我的第一个实验。在实验运行完成后,我可以检查学习情节,并决定是否应该使用更多/更少的epoch(结果是,70个epoch是正确的)。
- 避免过度拟合。其次,我们从本书之前的实验中知道,在使用CIFAR-10时,我们最终会过拟合。这是不可避免的;即使有强大的正则化和数据扩充,它仍然会发生。因此,我决定选取70个epoch,而不是冒险选取80-100个epoch,因为过度拟合的影响会变得更加明显。
11.2.4 MiniGoogLeNet :实验2
在我们的第二个MiniGoogLeNet实验中,我将最初的SGD学习速率1e−3换成了更大的1e−2。这个学习速率在70个时期内呈线性衰减。我再次培训了这个网络,并收集了结果:
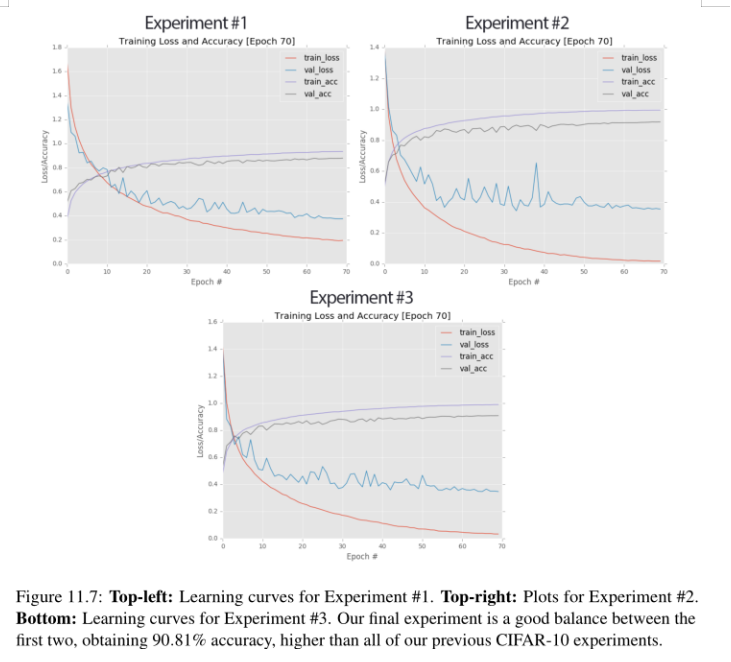
在第70个阶段结束时,我们在验证集上获得了91.79%的准确性(图11.7,右上),肯定比我们之前的实验好——但我们还不应该太兴奋。看看训练曲线的损失,我们可以看到它在60后完全降到了零。此外,训练曲线的分类精度在100%完全饱和。
虽然我们提高了验证的准确性,但这样做是以过度拟合为代价的——验证损失和训练损失之间的差距在过去20世纪是巨大的。相反,我们最好以5e−3的学习率重新训练我们的网络,这正好落在1e−2和1e−3的中间位置。我们可能会获得稍微少一点的验证精度,但理想情况下,我们能够减少过拟合的影响。
值得注意的是,如果您发现您的网络对训练集有完全的饱和损失(0.0)和准确性(100%),请一定要密切关注您的验证曲线。如果您看到验证图和训练图之间有很大的差距,那么肯定是过拟合。回到您的实验中,使用参数,引入更多的规则化,并调整学习速率。在这个实验中显示的饱和度表明这个模型不能很好地推广。
11.2.5 MiniGoogLeNet:实验3
在这个实验中,我将我的学习速率调整为5e−3。使用SGD优化器和线性学习速率衰减对MiniGoogLeNet进行了70个epoch的训练:
从输出结果可以看出,我们在验证集上获得了90.81%的分类精度(图11.7,底部),比之前的实验要低,但比第一次实验要高。我们确实在这个实验中过度拟合了(大约一个数量级),但在使用CIFAR-10时,我们可以接受这是不可避免的。
更重要的是,我们将训练损失和准确度饱和度保持在尽可能低的水平——训练损失没有完全降至零,训练准确度没有达到100%。我们还可以看到,即使在后来的时代,训练和验证准确性之间也保持着合理的差距。
在这一点上,我认为这个实验是一个初步的成功(需要注意的是,还需要做更多的实验来减少过拟合)——我们已经成功地在CIFAR-10上训练了MiniGoogLeNet,达到了我们> 90%分类的目标,超过了之前在CIFAR-10上的所有实验。
本实验的未来修订应考虑采用攻击性正则化。具体来说,我们在这里没有使用任何类型的权重正则化。应用L2重量衰减将有助于对抗我们的过拟合(我们下一节的实验将演示)。
接下来,用这个实验作为基线。我们知道存在过拟合,我们希望在提高分类精度的同时减少过拟合。在ResNet的下一章中,我们将看到如何实现这两个目标。
现在我们已经探索了MiniGoogLeNet应用于cifa10,让我们继续cs231n Tiny ImageNet挑战中更困难的分类任务,在那里我们将实现一个更深入的googlet变体,类似于Szgedy等人在他们的原始论文中使用的架构。
11.3 微型ImageNet挑战
微型ImageNet视觉识别挑战(如图11.8所示)是cs231n斯坦福课程“卷积神经网络视觉识别”[39]的一部分。作为他们最终项目的一部分,学生可以通过从零开始训练CNN或通过微调进行迁移学习来竞争分类(通过特征提取进行迁移学习是不允许的)。
Tiny ImageNet数据集实际上是完整ImageNet数据集的一个子集(这就是为什么不能使用特征提取,因为它会给网络一个不公平的优势),包含200个不同的类,包括从埃及猫到排球到柠檬的所有东西。假设有200个类,随机猜测我们期望正确的概率是1/200 = 0.5%;因此,我们的CNN需要获得至少0.5%的数据来证明它已经在各自的班级中学习了有区别的潜在模式。
每个类包括500个训练图像、50个验证图像和50个测试图像。Groundtruth标签只提供给训练和验证图像。因为我们不能访问Tiny ImageNet评估服务器,所以我们将使用一部分训练集来形成我们自己的测试集,这样我们就可以评估我们的分类算法的性能。
ImageNet Bundle的读者会发现(在这里我们讨论了如何从头开始在完整的ImageNet数据集上训练深度卷积神经网络),ImageNet大尺度视觉识别挑战(ILSVRC)中的图像具有不同的宽度和高度。因此,每当我们使用ILSVRC时,我们首先需要将数据集中所有图像的大小调整为固定的宽度和高度,然后才能训练我们的网络。为了帮助学生严格专注于深度学习和图像分类组件(而不是陷入图像处理细节),Tiny ImageNet数据集中的所有图像都被调整为64 × 64像素,并在中心裁剪。
在某些方面,调整图像大小使Tiny ImageNet比它的大哥ILSVRC更具挑战性。在ILSVRC中,我们可以自由地应用任何类型的调整大小、裁剪等操作。然而,使用Tiny ImageNet,许多图像已经被我们丢弃了。正如我们将发现的那样,在Tiny ImageNet上获得一个合理的rank-1和rank-5的准确性并不像人们想象的那么容易,这使得它成为一个伟大的,有洞察力的数据集,为初出苗头的深度学习实践者学习和实践。
在接下来的几节中,您将学习如何获取Tiny ImageNet数据集,理解其结构,并创建用于训练、验证和测试图像的hdf5文件。
11.3.1 Downloading Tiny ImageNet

Tiny ImageNet数据集中的目录结构。
在测试目录中是测试图片——我们将忽略这些图片,因为我们无法访问cs231n评估服务器(下载中故意省略了标签,以确保没有人可以在挑战中“作弊”)。
然后,我们有了train目录,其中包含以字母n开头,后跟一系列数字的奇怪名称的子目录。这些子目录是WordNet [43] id,简称为“synonym set”或“synsets”。每个WordNet ID映射到一个特定的单词/对象。给定WordNet子目录中的每个图像都包含该对象的示例。
我们可以通过解析单词来查找人类可读的WordNet ID标签。txtfile,它只是一个标签分开的文件,WordNet ID在第一列,人类可读的单词/对象在第二列。wnids。txtfile列出了ImageNet数据集中的200个WordNet id(每行一个)。
最后,val目录存储我们的验证集。在val目录中,你会发现一个images子目录和一个名为val_annotations.txt的文件。val_annotations.txt为val目录中的每个图像提供WordNet id。
因此,在我们开始在Tiny ImageNet上训练GoogLeNet之前,我们首先需要编写一个脚本来解析这些文件,并将它们转换成HDF5格式。请记住,作为一个深度学习从业者不是要实现卷积神经网络并从头开始训练它们。深度学习从业者需要使用编程技能构建能够解析数据的简单脚本。
你拥有的通用编程技能越多,你就能成为更好的深度学习从业者——当其他深度学习研究人员正在努力组织磁盘上的文件或理解数据集的结构时,你已经将你的整个数据集转换为适合训练CNN的格式。
在下一节中,我将教你如何定义你的项目配置文件,并创建一个简单的Python脚本,将Tiny ImageNet数据集转换为HDF5表示。
11.3.3 建设一个Tiny ImageNet数据集

我们将创建一个配置模块,用于存储tiny_imagenet_config.py配置。然后我们有build_tiny_imagenet.py脚本,它负责获取Tiny ImageNet并将其转换为HDF5。train.py脚本将在Tiny ImageNet的HDF5版本上训练GoogLeNet。最后,我们将使用rank.py来计算测试集的rank-1和rank-5的精度。
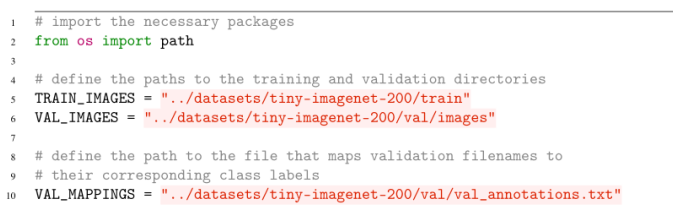
第5行和第6行分别定义了Tiny ImageNet训练和验证图像的路径。然后,我们定义到验证文件映射的路径,这使我们能够将验证文件名映射到实际的类标签(例如,WordNet id)。

考虑到我们没有访问测试标签,我们需要取一部分训练数据,并使用它来验证(因为我们的训练数据确实有标签与每个图像相关联):
本节的目的是将Tiny ImageNet转换为HDF5,因此我们需要提供训练、验证和测试HDF5文件的路径:

当将图像写入磁盘时,我们将需要计算训练集的RGB均值,使我们能够执行均值归一化—当我们有均值后,它们将需要以JSONfile的形式序列化到磁盘:
# define the path to the dataset mean
29 DATASET_MEAN = "output/tiny-image-net-200-mean.json"
最后,我们将定义输出模型和训练日志/图的路径:
# define the path to the output directory used for storing plots,
32 # classification reports, etc.
33 OUTPUT_PATH = "output"
34 MODEL_PATH = path.sep.join([OUTPUT_PATH,
35 "checkpoints/epoch_70.hdf5"])
36 FIG_PATH = path.sep.join([OUTPUT_PATH,
37 "deepergooglenet_tinyimagenet.png"])
38 JSON_PATH = path.sep.join([OUTPUT_PATH,
39 "deepergooglenet_tinyimagenet.json"])
正如您所看到的,这个配置文件非常简单。我们主要是定义图像/标签映射和输出文件的输入目录的路径。然而,花点时间创建这个配置文件可以让我们在实际构建Tiny ImageNet并将其转换为HDF5时更加轻松。
第2-11行导入所需的Python包。在第2行,我们导入了新编码的配置文件,这样我们就可以访问其中的变量了。我们将使用LabelEncoder将WordNet id编码为整数。我们将使用train_test_split函数来构造我们的训练和测试split。我们将使用HDF5DatasetWriter类实际写入原始图像到各自的HDF5数据集。
让我们继续抓取训练图像的路径,提取类标签,并对它们进行编码:
# grab the paths to the training images, then extract the training
14 # class labels and encode them
15 trainPaths = list(paths.list_images(config.TRAIN_IMAGES))
16 trainLabels = [p.split(os.path.sep)[-3] for p in trainPaths]
17 le = LabelEncoder()
18 trainLabels = le.fit_transform(trainLabels)
在第15行,我们获取TRAIN_IMAGES目录中所有图像路径的列表。这个列表中的每个路径都有这样的模式:

因此,要提取WordNet ID(即类标签),我们只需在路径分隔符上进行拆分并获取第三个条目(Python的索引为0,因此我们在这里提供了一个值2)。一旦我们有了所有的trainLabels,我们就可以启动LabelEncoder并将所有的标签转换为唯一的整数(第17和18行)。
由于我们没有测试分割,我们需要从训练集中抽取一组图像来组成一个:
# perform stratified sampling from the training set to construct a
21 # a testing set
22 split = train_test_split(trainPaths, trainLabels,
23 test_size=config.NUM_TEST_IMAGES, stratify=trainLabels,
24 random_state=42)
25 (trainPaths, testPaths, trainLabels, testLabels) = split
这里我们提供了trainPaths和trainLabels,以及NUM_TEST_IMAGES的test_size,这是每个类50张图片(总共有10,000张图片)。我们的测试集是从我们的训练集中采样的,在训练集中我们已经有了图像的类别标签,使我们能够在准备好时评估我们的神经网络的性能;但是,我们还没有解析验证标签。
解析和编码验证标签是在以下代码块中处理的:
# load the validation filename => class from file and then use these
# mappings to build the validation paths and label lists
M = open(config.VAL_MAPPINGS).read().strip().split("n")
M = [r.split("t")[:2] for r in M]
valPaths = [os.path.sep.join([config.VAL_IMAGES, m[0]]) for m in M]
valLabels = le.transform([m[1] for m in M])
在第29行,我们加载了VAL_MAPPINGSfile的全部内容(即,将验证映像文件名称映射到它们各自的WordNet ID的选项卡单独文件)。对于M中的每一行,我们将其分成两列——imagefilename和WordNet ID(第30行)。根据到验证图像(VAL_IMAGES)的路径以及M中的文件名,我们可以构造到验证文件的路径(第31行)。类似地,我们可以将WordNet ID字符串转换为第32行中唯一的类标签整数,方法是循环遍历每行中的WordNet ID并应用标签编码器。
对于那些很难理解这段代码的读者,我建议在这里停下来,花点时间执行每一行代码并研究每个变量的内容。我们在这里大量使用了Python列表推导式,这是一种用很少的代码构建列表的自然、简洁的方法。同样,这个代码块与深度学习无关——它只是解析文件,这是一个通用的编程问题。花几分钟时间,确保您理解了如何解析val_annotations。Txtfile使用这个代码块。
现在,我们有了训练、验证和测试图像的路径,我们可以定义一个数据集元组,我们将循环遍历,并分别将图像和相关的类标签写入HDF5:
# construct a list pairing the training, validation, and testing
35 # image paths along with their corresponding labels and output HDF5
36 # files
37 datasets = [
38 ("train", trainPaths, trainLabels, config.TRAIN_HDF5),
39 ("val", valPaths, valLabels, config.VAL_HDF5),
40 ("test", testPaths, testLabels, config.TEST_HDF5)]
# initialize the lists of RGB channel averages
43 (R, G, B) = ([], [], [])
# loop over the dataset tuples
46 for (dType, paths, labels, outputPath) in datasets:
47 # create HDF5 writer
48 print("[INFO] building {}...".format(outputPath))
49 writer = HDF5DatasetWriter((len(paths), 64, 64, 3), outputPath)
50
51 # initialize the progress bar
52 widgets = ["Building Dataset: ", progressbar.Percentage(), " ",
53 progressbar.Bar(), " ", progressbar.ETA()]
54 pbar = progressbar.ProgressBar(maxval=len(paths),
55 widgets=widgets).start()
截止到P154页
2022.1.28日下午17:27
//2022.1.29上午9:41开始阅读
在第46行,我们遍历数据集列表中的数据集类型(dType)、路径、标签和outputPath。对于每一个输出hdf5文件,我们将创建一个HDF5DatasetWriter存储一组len(paths)图像,每个图像是64 × 64 × 3的RGB图像(第49行)。第52-55行简单地初始化了一个进度条,这样我们就可以很容易地看到数据集创建的过程。
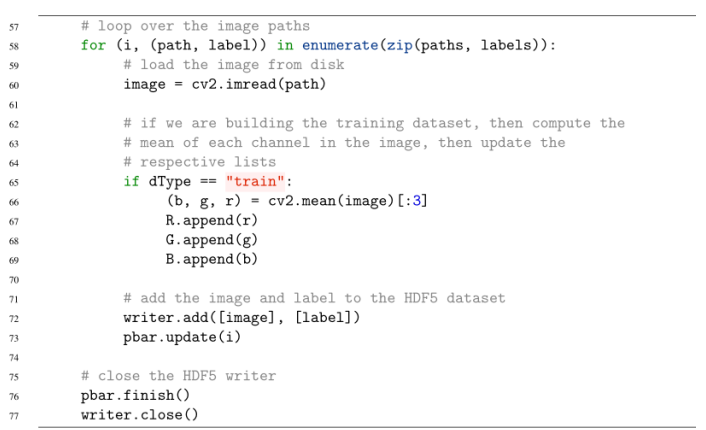
对于每个映像,我们从磁盘第60行加载它。如果图像是训练图像,我们需要计算图像的RGB平均值并更新相应的列表(第66-69行)。第72行添加图像(已经是64 × 64 × 3)和标签到HDF5数据集,而第77行关闭数据集。
11.4 DeeperGoogLeNet在Tiny ImageNet数据集上的测试
现在我们有了Tiny ImageNet数据集的HDF5表示,我们准备对它进行googlet训练——但不是像前一节那样使用MiniGoogLeNet,我们将使用一个更深入的变体,更接近于Szegedy等人的实现。这个更深层次的变化将使用原始的Inception模块,如本章前面的图11.1所示,这将帮助您理解原始的体系结构,并在将来自己实现它。
首先,我们将学习如何实现这个更深层次的网络架构。然后,我们将在Tiny ImageNet数据集上训练deeppergooglet,并根据秩1和秩5的准确性评估结果。
11.4.1 实现DeeperGoogLeNet
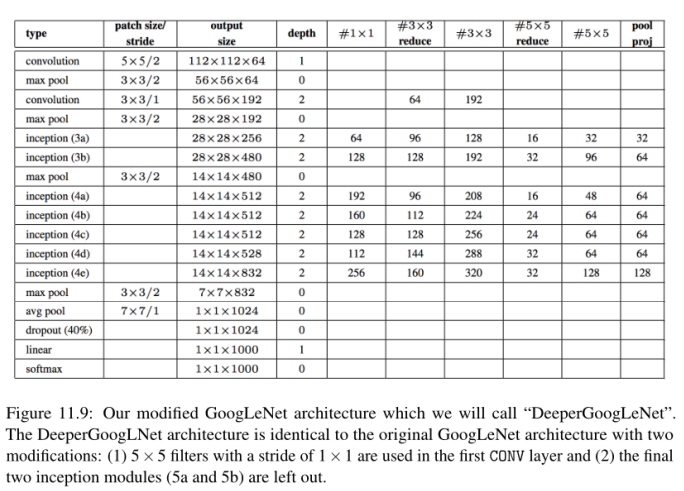
我在图11.9中提供了一个图(从Szegedy等人复制和修改的),详细描述了我们的deeppergooglet架构。在完整的ImageNet数据集上训练网络时,我们的实现和Szegedy等人使用的完整的GoogLeNet架构之间只有两个主要的区别:
- 在第一个CONV层中使用步幅为2 × 2的7 × 7滤波器,而在第一个CONV层中使用步幅为1 × 1的5 × 5滤波器。我们使用这些是因为我们的GoogLeNet实现只能接受64 × 64 × 3的输入图像,而原始的实现构建为接受224 × 224 × 3的图像。如果我们在2 × 2步幅上应用7 × 7的滤波器,我们会很快地降低输入维度。
- 我们的实现稍微浅一些,只有两个较少的Inception模块——在最初的Szegedy等人的论文中,在平均池操作之前添加了两个更多的Inception模块。这个GoogLeNet的实现将是足够的,我们在Tiny ImageNet上表现良好,并声称在cs231n Tiny ImageNet排行榜上的一个位置。如果读者有兴趣在整个ImageNet数据集上从头开始训练完整的GoogLeNet架构(从而复制Szegedy等人实验的性能),请参阅ImageNet Bundle的第7章。
为了方便起见(并确保我们的代码不会变得臃肿),让我们定义一个conv_module函数,该函数将负责接受输入层,执行CONV => BN => RELU,然后返回输出。通常情况下,我更倾向于将BN放在RELU之后,但由于我们复制了Szegedy等人的原始工作,所以让我们坚持在激活之前进行批量标准化。conv_module的实现如下所示:
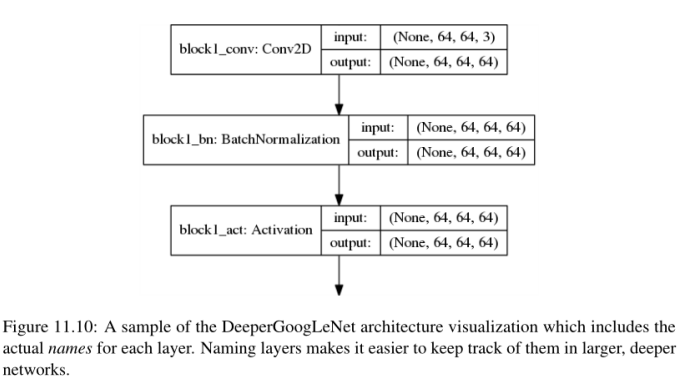
接下来,让我们定义一下inception_module, Szgedy等人在他们最初的出版物中详细描述了这个模块,如图11.1所示:
Inception模块的第二个分支首先通过1 × 1卷积执行降维,然后用3 × 3卷积进行扩展——我们分别称之为num3x3Reduce和num3x3变量。
# define the second branch of the Inception module which
48 # consists of 1x1 and 3x3 convolutions
49 second = DeeperGoogLeNet.conv_module(x, num3x3Reduce, 1, 1,
50 (1, 1), chanDim, reg=reg, name=stage + "_second1")
51 second = DeeperGoogLeNet.conv_module(second, num3x3, 3, 3,
52 (1, 1), chanDim, reg=reg, name=stage + "_second2")
这里我们可以看到,第一个conv_module对输入应用了1 × 1卷积。这些1 × 1卷积的输出随后被传递到第二个conv_module,该模块执行一系列3 × 3卷积。1 × 1的卷积数总是小于3 × 3的卷积数,是一种降维形式。
# define the third branch of the Inception module which
55 # are our 1x1 and 5x5 convolutions
56 third = DeeperGoogLeNet.conv_module(x, num5x5Reduce, 1, 1,
57 (1, 1), chanDim, reg=reg, name=stage + "_third1")
58 third = DeeperGoogLeNet.conv_module(third, num5x5, 5, 5,
59 (1, 1), chanDim, reg=reg, name=stage + "_third2")
在第56和57行,我们学习了num5x5Reduce内核,每个内核的大小都是1 × 1,这是基于对inception_module的输入。然后,1 × 1卷积的输出被传递到第二个conv_module,该模块随后学习一个大小为5 × 5的num5x5滤波器。同样,这个分支中的1 × 1卷积的数量总是小于5 × 5滤波器的数量。
Inception模块的第四个也是最后一个分支通常被称为池投影。在这里,我们应用max pooling,然后是一系列1 × 1的卷积:
# define the fourth branch of the Inception module which
62 # is the POOL projection
63 fourth = MaxPooling2D((3, 3), strides=(1, 1),
64 padding="same", name=stage + "_pool")(x)
65 fourth = DeeperGoogLeNet.conv_module(fourth, num1x1Proj,
66 1, 1, (1, 1), chanDim, reg=reg, name=stage + "_fourth")
这一分支的基本原理部分是科学的,部分是道听途说。2014年,大多数(如果不是全部的话)卷积神经网络在ImageNet数据集上获得了最先进的性能,它们都应用了最大池。因此,我们认为CNN应该使用max pooling。虽然GoogLeNet确实在Inception模块之外应用了最大池,但Szegedy等人决定将池投影分支作为另一种形式的最大池。
得到的图形如图11.11所示。在这个可视化图中,我们可以看到Inception模块是如何构造四个分支的。第一个分支负责学习局部的1 × 1特征。第二个分支通过1 × 1卷积进行降维,然后学习3 × 3的更大的滤波器尺寸。第三个分支的行为类似于第二个分支,只学习5 × 5个滤波器,而不是3 × 3个滤波器。最后,第四个分支应用max pooling。
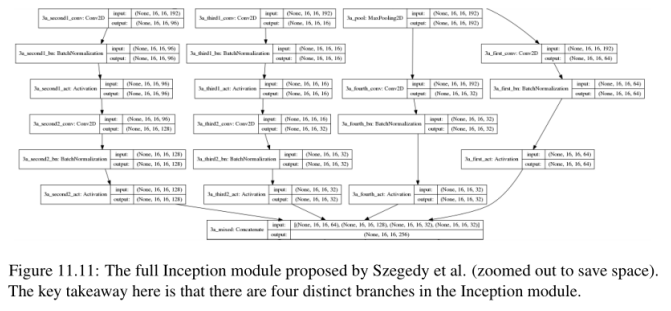
通过学习所有三个1 × 1,3 × 3和5 × 5滤波器,Inception模块可以同时学习通用(5 × 5和3 × 3)和局部(1 × 1)特征。实际的优化过程将自动决定如何评估这些分支和层,本质上给我们提供了一个“通用”模块,该模块将在给定的时间学习最佳的特性集(局部、小卷积)或更高级别的抽象特性(大卷积)。因此Inception模块的输出是256,这是来自每个分支的所有64 + 128 + 32 + 32 = 256过滤器的连接。
现在已经定义了inception_module,我们可以创建负责构建完整的deeppergooglet架构的构建方法:
我们的构建方法将接受图像的空间输入维度,包括宽度、高度和深度。我们还将提供网络要学习的类标签的数量,以及一个用于L2权值衰减的可选正则化术语。第77-86行根据Keras中的“channel last”或“channelsfirst”配置正确设置inputShape和chanDim。
# define the model input, followed by a sequence of CONV =>
89 # POOL => (CONV * 2) => POOL layers
90 inputs = Input(shape=inputShape)
91 x = DeeperGoogLeNet.conv_module(inputs, 64, 5, 5, (1, 1),
92 chanDim, reg=reg, name="block1")
93 x = MaxPooling2D((3, 3), strides=(2, 2), padding="same",
94 name="pool1")(x)
95 x = DeeperGoogLeNet.conv_module(x, 64, 1, 1, (1, 1),
96 chanDim, reg=reg, name="block2")
97 x = DeeperGoogLeNet.conv_module(x, 192, 3, 3, (1, 1),
98 chanDim, reg=reg, name="block3")
99 x = MaxPooling2D((3, 3), strides=(2, 2), padding="same",
100 name="pool2")(x)
第一个CONV层学习64个5 × 5滤波器,步长为1 × 1。然后我们应用max pooling,窗口大小为3 × 3, stride为2 × 2,以减少输入的体积大小。行95-98负责执行减少和扩展。首先,学习64个1 × 1滤波器(第95和96行)。然后,在第97行和第98行学习192个3 × 3滤波器。这个过程非常类似于Inception模块(将在网络的后面几层中应用),只是没有分支因素。最后,在第99行和第100行执行另一个max池。
接下来,让我们应用两个Inception模块(3a和3b),然后是一个最大池:
# apply two Inception modules followed by a POOL
103 x = DeeperGoogLeNet.inception_module(x, 64, 96, 128, 16,
104 32, 32, chanDim, "3a", reg=reg)
105 x = DeeperGoogLeNet.inception_module(x, 128, 128, 192, 32,
106 96, 64, chanDim, "3b", reg=reg)
107 x = MaxPooling2D((3, 3), strides=(2, 2), padding="same",
108 name="pool3")(x)
查看这段代码,您可能想知道我们如何决定每个CONV层的数字过滤器。答案是,这个网络中的所有参数值都直接来自于Szegedy等人在GoogLeNet上的原始论文,在该论文中,作者进行了一系列的实验来调整参数。在每种情况下,你都会注意到所有Inception模块的一个共同模式:
- 我们在Inception模块的第一个分支中学习到的1 × 1过滤器的数量将小于或等于3 × 3(第二个)和5 × 5(第三个)分支中的1 × 1过滤器。
- 1 × 1滤波器的数量总是小于它们输入的3 × 3和5 × 5卷积。
- 我们在3 × 3分支中学习到的过滤器数量将比5 × 5分支多,这有助于减小网络的规模,并提高训练/评估的速度。
- 池投影滤波器的数量总是小于1 × 1局部特征的第一个分支。
- 无论分支类型如何,过滤器的数量都会随着网络的深入而增加(或至少保持不变)。
虽然在实现这个网络时肯定有更多的参数需要跟踪,但我们仍然遵循与以前的cnn相同的一般经验规则——网络越深,卷的大小越小;因此,我们学会补偿的滤波器越多。
这个网络继续变得更深入,学习更丰富的特性,因为我们现在在应用POOL之前将5个Inception模块(4a-4e)相互叠加在一起:
# apply five Inception modules followed by POOL
111 x = DeeperGoogLeNet.inception_module(x, 192, 96, 208, 16,
112 48, 64, chanDim, "4a", reg=reg)
113 x = DeeperGoogLeNet.inception_module(x, 160, 112, 224, 24,
114 64, 64, chanDim, "4b", reg=reg)
115 x = DeeperGoogLeNet.inception_module(x, 128, 128, 256, 24,
116 64, 64, chanDim, "4c", reg=reg)
117 x = DeeperGoogLeNet.inception_module(x, 112, 144, 288, 32,
118 64, 64, chanDim, "4d", reg=reg)
119 x = DeeperGoogLeNet.inception_module(x, 256, 160, 320, 32,
120 128, 128, chanDim, "4e", reg=reg)
121 x = MaxPooling2D((3, 3), strides=(2, 2), padding="same",
122 name="pool4")(x)
在第121行和122行最后一个POOL之后,我们的卷大小是4 x 4 x类。为了避免使用计算开销很大的全连接层(更不用提大幅增加的网络大小了),我们使用4 × 4内核的平均池,将体积大小减少到1 × 1 ×类:
# apply a POOL layer (average) followed by dropout
125 x = AveragePooling2D((4, 4), name="pool5")(x)
126 x = Dropout(0.4, name="do")(x)
127
128 # softmax classifier
129 x = Flatten(name="flatten")(x)
130 x = Dense(classes, kernel_regularizer=l2(reg),
131 name="labels")(x)
132 x = Activation("softmax", name="softmax")(x)
133
134 # create the model
135 model = Model(inputs, x, name="googlenet")
136
137 # return the constructed network architecture
138 return model
然后以40%的概率进行退学。通常情况下,我们会使用50%的辍学率,但同样,我们只是遵循最初的实现。
第130行和第131行创建稠密层,表示我们希望学习的类的总数。然后在第132行完全连接层之后应用softmax分类器。最后,根据输入和实际计算网络图x构建实际模型。这个模型返回给第138行上的调用函数。
11.4.2 训练DeeperGoogLeNet网络在Tiny ImageNet数据集上
现在我们的DeeperGoogLeNet架构已经实现,我们需要创建一个Python脚本来在Tiny ImageNet上训练网络。我们还需要创建第二个Python脚本,它将负责通过计算秩1和秩5的精确度来评估测试集上的模型。
一旦我们完成了这两个任务,我将分享我在为本章收集结果时进行的三个实验。这些实验将形成一个“案例研究”,使您能够学习如何运行一个实验,研究结果,并对如何调优超参数进行有根据的猜测,以便在下次实验中获得性能更好的网络。
11.4.3 创建训练脚本

我们将使用ctrl + c方法来训练我们的网络,这意味着我们将开始训练过程,监控训练是如何进行的,然后停止脚本,如果过度拟合/停滞发生,调整任何超参数,并重新开始训练。首先,我们需要——检查点开关,这是到输出目录的路径,该目录将存储DeeperGoogLeNet模型的各个检查点。如果我们重新开始培训,那么我们需要提供一个特定的——我们重新开始培训的模型的路径。类似地,我们还需要提供—start-epoch来获取我们重新开始训练的epoch的整数值。
对数据集进行增强:
# construct the training image generator for data augmentation
32 aug = ImageDataGenerator(rotation_range=18, zoom_range=0.15,
33 width_shift_range=0.2, height_shift_range=0.2, shear_range=0.15,
34 horizontal_flip=True, fill_mode="nearest")
35
36 # load the RGB means for the training set
37 means = json.loads(open(config.DATASET_MEAN).read())
培训和验证生成器都将适用:一个简单的预处理器,以确保图像的大小调整为64 × 64像素(这已经是应该的,但我们将在这里包含它作为完整性的问题)。2. 均值减法来归一化数据。3.一个图像到keras兼容的阵列转换器。
我们选择训练我们的网络的确切时间将取决于我们的损失/准确性图看起来如何。我们将做出明智的决定,更新学习速率或应用基于模型性能的早期停止。
11.4.4 创建评估脚本
11.4.5 DeeperGoogLeNet 实验
在下面的章节中,我已经包含了我在Tiny ImageNet上训练deepergooglet时进行的四个独立实验的结果。每次实验后,我都会评估结果,然后就如何更新超参数和网络架构做出明智的决定,以提高准确性。
像这样的案例研究对于刚开始深度学习的你特别有帮助。它们不仅证明了深度学习是一个需要许多实验的迭代过程,而且还表明了你应该注意哪些参数以及如何更新它们。
最后,值得注意的是,其中一些实验需要对代码进行更改。deep googlenet.py和train.py的实现都是我最终获得了最佳精度的实现。如果您想复制我的(不太准确的)结果,我将注意我在早期实验中所做的更改。
实验1
考虑到这是我第一次在Tiny ImageNet挑战中训练一个网络,我不确定在这个数据集上给定的架构的最佳深度应该是什么。虽然我知道Tiny ImageNet将是一个具有挑战性的分类任务,但我不认为Inception模块4a-4e是必需的,所以我从上面的deepergooglet实现中删除了它们,导致了一个本质上更浅的网络架构。
我决定使用SGD来训练deepergooglet,初始学习率为1e−2,动量项为0.9(没有使用Nesterov加速度)。我总是在我的第一个实验中使用SGD。根据我在第7章中的指导原则和经验法则,你应该首先尝试SGD来获得一个基线,然后如果需要的话,使用更高级的优化方法。
我开始使用以下命令进行训练:

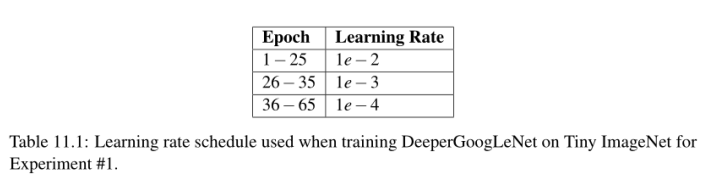
然后使用表11.1中详细的学习速率计划。这个表表明,在第25纪元之后,我停止训练,将学习速率降低到1e - 3,然后继续训练10个纪元:

第35期之后,我再次停止训练,把学习速度降低到1e - 4,然后继续训练30多个时期:

至少可以这么说,多训练30个小时是过分的;然而,我想了解过度拟合的水平,以期待在原始学习率下降后的大量时代(因为这是我第一次使用GoogLeNet + Tiny ImageNet)。您可以在图11.12(左上)中看到训练和验证的损失/准确性随时间的变化。
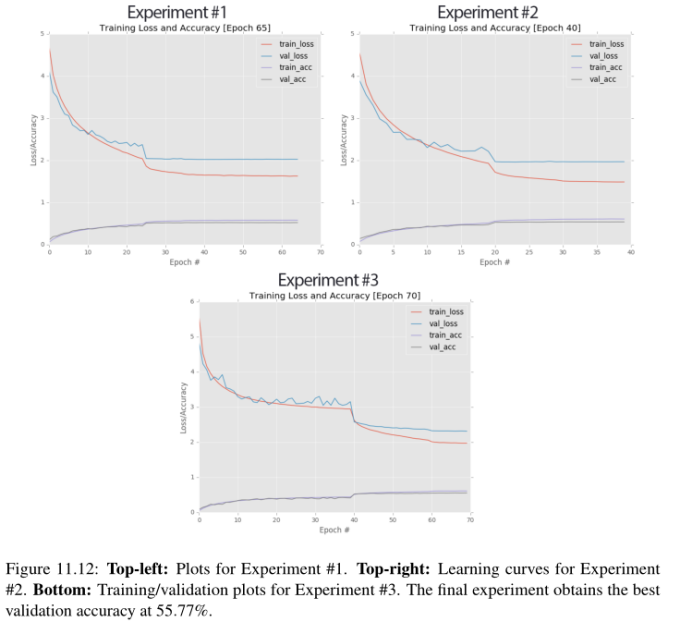
大约从第15纪元开始,在训练和验证损失方面出现了分歧。到第25纪元时,散度变得越来越重要,所以我把学习速率降低了一个数量级;结果是准确性的一个很好的跳跃和损失的减少。问题是,在这之后,训练和验证学习基本上都停滞了。即使在35历元时将学习速率降低到1e−4,也不会带来额外的准确性提升。
在40时代的末期,学习完全停滞了。如果我不想在很长一段时间内看到低学习率的影响,我就会在第45纪元之后停止训练。在本例中,我让网络一直训练到epoch 65(损失/准确性没有变化),在那里我停止训练并检查结果,注意到网络在验证集上获得了52.25%的第1位精度。然而,考虑到我们的网络性能在降低学习速率后迅速趋于稳定,我认为显然还有更多的工作要做。
DeeperGoogLeNet: 实验2
在我的第二个实验deeppergooglenet + Tiny ImageNet,我决定为Adam切换SGD优化器。之所以做出这个决定,是因为我不相信网络架构需要更深入(到目前为止)。使用Adam优化器时,默认初始学习速率为1e−3。然后我使用表11.2(左)中的学习率计划来降低学习率。
下图11.12(右上)显示了学习曲线。这张图看起来与上面左上角的图非常相似。我们一开始很强大,但是验证损失在第10阶段后迅速发散,迫使我在第20阶段降低学习速率(否则就会有过拟合的风险)。一旦学习速度降低,学习就停滞了,我无法提高准确率,甚至第二次降低学习速度。但是,在第40纪元结束时,我注意到我的验证损失比之前的实验要低,我的准确性更高了。
通过将SGD换成Adam,我能够将验证准确性提高到54.20%的排名1,增加了近2%。然而,我仍然有学习停滞的问题,一旦开始的学习率降低。
DeeperGoogLeNet: Experiment #3
由于学习停滞,我假设网络不够深入,无法在Tiny ImageNet数据集中建模底层模式。因此,我决定启用Inception模块4a-4e,创建一个更深入的网络架构,能够学习更深入、更有区别的特性。使用初始学习率为1e−3的Adam优化器来训练网络。L2的质量衰减项在0.0002。然后根据表11.2(右)对deeppergooglenet进行训练。
您可以看到图11.12(下图)中的图表。您马上就会注意到,使用更深入的网络架构使我能够训练更长的时间,而不会有停滞或严重过拟合的风险。在第70个阶段结束时,我在验证集中获得了55.77%的第1级精度。
//截止到2022.1.29日晚上18:33
截止到P169页
//2022.1.29日晚上22:23开始阅读
此时,我决定是时候对deeppergooglet的测试集进行评估了:

评估脚本报告的1级准确度为54.38%,或者错误率为1−0.5438 = 0.4562。有趣的是,我们排名第五的准确率是78.96%,这对于这一挑战来说是相当令人印象深刻的。看看下面的Tiny ImageNet排行榜(http://pyimg.co/h5q0o),我们可以看到这个错误率足以让我们获得第7名的位置,这是爬到排行榜顶端的一个很好的开始(图11.13)。
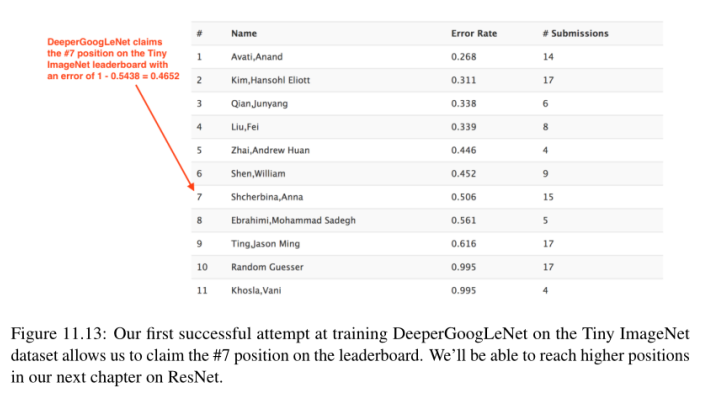
在Tiny ImageNet排行榜上的1-4位是通过对已经在完整的ImageNet数据集上训练过的网络进行微调的转移学习实现的。由于我们是从零开始训练我们的网络,我们更关心的是获得第5位,即无需迁移学习就能获得的最高位置。在ResNet的下一章中,我们将会发现,我们可以很容易地获得这个位置。有关cs231n学生用来实现错误率的技术的更多信息,请参阅Stanford cs231n项目页面[4]。
对于有兴趣进一步提高deeppergooglenet准确性的读者,我建议进行以下实验:将conv_module改为CONV => RELU => BN,而不是原来的CONV => BN => RELU排序。2. 尝试使用elu而不是relu,这可能会导致精度略微提高0.5 - 1%。
11.5 总结
在这一章中,我们回顾了Szgedy等人的工作。[17]介绍了现在著名的Inception模块。Inception模块是微架构的一个例子,它是适合于网络整体宏观架构的构建块。目前最先进的卷积神经网络倾向于使用某种形式的微架构。
然后我们应用Inception模块来创建googlet的两个变体:
- 一个用于CIFAR-10。2. 另一个是更具挑战性的Tiny ImageNet。
在CIFAR-10上进行训练时,我们获得了迄今为止的最佳准确率为90.81%(较之前84%的最佳准确率有所提高)。
在具有挑战性的Tiny ImageNet数据集上,我们达到了54.38%的排名1和78.96%的排名5,使我们在Tiny ImageNet排行榜上排名第7。我们的目标是在排行榜上爬到第5位(当从零开始训练一个网络时获得的最高位置,所有更高的位置应用微调在ImageNet数据集预先训练的网络上,给予他们不公平的优势)。为了达到我们的第5个目标,我们需要使用ResNet架构,在下一章中详细介绍。
//截止到2022.1.30日晚上18:20
上述实验代码详见本人github地址:
GitHub - TheWangYang/Code_For_Deep_Learning_for_Computer_Vision_with_Python: A code repository for Deep Learning for Computer Vision with Python.
最后
以上就是大方导师最近收集整理的关于《Deep Learning for Computer Vision withPython》阅读笔记-PractitionerBundle(第9 - 11章)9.使用HDF5和大数据集10.在Kaggle竞赛中:狗与猫11. GoogLeNet的全部内容,更多相关《Deep内容请搜索靠谱客的其他文章。








发表评论 取消回复