来源 | 夕小瑶的卖萌屋作者 | 卖萌酱众所周知,与CV、NLP不同,搜索、广告、推荐领域的学术界paper在很多问题上喜欢各玩各的,缺乏一个统一可比的benchmark。
就推荐/广告中核心的CTR预估问题来讲,从传统的LR、FM到Wide&Deep、DeepFM、DCN、DFN等花里胡哨的模型,看似模型结构越来越fancy,但真实效果来说,我觉得每个CTR从业者往往都心知肚明:
这么nb的模型,放在我的业务场景里怎么就没了效果捏?
关注CTR问题的小伙伴,可能会对2020年华为发表在CIKM'21的一篇论文有印象:
论文标题:
Open Benchmarking for Click-Through Rate Prediction
论文链接:
https://arxiv.org/pdf/2009.05794.pdf
论文对2007-2020年提出的若干CTR模型做了统一的评测。
然而,
一直到几个月前,这个benchmark才刚刚开源。。。尽管开源行为非常低调,但还是被卖萌酱抓到了,贴上repo链接:
https://github.com/huawei-noah/benchmark/tree/main/FuxiCTR
关于这个CTR Benchmark,下面贴上知乎大佬@失落的萨特 对此的评价[1]:
有些实践经验的小伙伴都知道,迭代了几轮之后的搜索推荐排序模型,模型结构的优化空间是非常小的。很多论文提出的idea,也就在toy dataset上面跑跑,拿到大公司的核心业务场景上,基本没什么用。排除作者恶意灌水之类的问题,原因可能是:
搜索推荐是个工业场景,对比CV NLP,核心的数据和系统相对闭源,public dataset的特征,样本,数据背后对应的问题,对于大公司核心业务场景来说都太简单了。在这样简单的数据/任务上做的提升,可能是没办法迁移到复杂的真实系统中。
各个公司发的文章有时候也没办法真正相互借鉴,因为大家的数据和系统还是不同的,系统的完善程度,复杂度,数据的规模,特征的复杂度,系统和用户交互的真实情况,仍然存在很大的差异。说白了公司里面一些小场景做的提升,拿到大场景上就未必有效了,更别提放到其他公司,其他系统,其他数据上。每篇paper都号称吊打SOTA,可惜其实没几篇是真正的SOTA。
大公司的算法工程师忙着处理数据和迭代系统,大家的日常工作就不是在一个相对固定的环境上冥思苦想,刷分打榜。等工作拿到业务效果,要发paper,PR时候才随便找个公开数据集跑跑,跑出来的实验结论可想而知。综上,其实现在搜推广的research community,面临各说各话,关公战秦琼的窘境,真实有效的方法不多。当然可能其他深度学习领域也是类似的。说回这篇FuxiCTR,做了一个CTR模型的benchmark,在Criteo, Avazu两个数据集上,对比了最近几年经常提到的一些模型。因为是benchmark类的文章,实验做的还是比较严谨的,下面是实验结果:
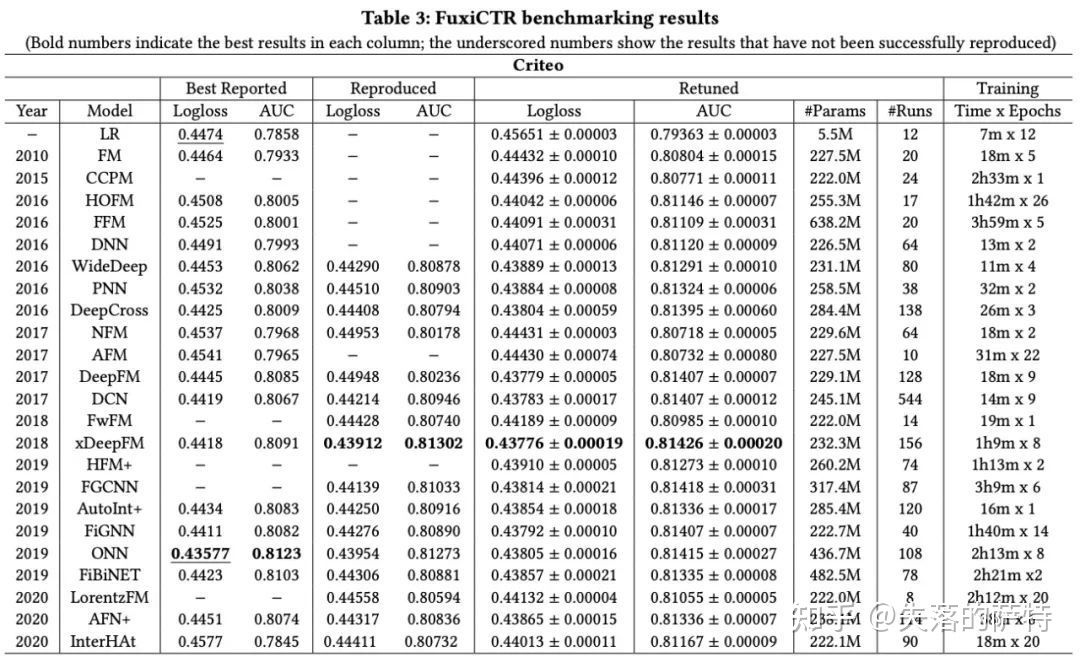
几点个人看法:
两个数据集上,SOTA对比DNN大概0.3%, 0.4% CTR AUC的提升。提升幅度终于有点和工作中对的上了=。=,现在一些paper,随便改改网络连接就report几个点的AUC提升,嗯,还沉迷在做科幻作家的状态。
两个数据集对比大公司核心业务场景的数据,还是toy dataset。二三十个特征,几千万的样本,做explicit feature interaction的模型收敛快,可能会占点便宜。但真实的搜推场景往往是数据源源不断,模型越来越大的,在增量训练的情况下,0.3~0.4%相对DNN的优势都不见得保持住。
对于这么小的数据集,要做0.3%~0.4% CTR AUC的提升其实有很多其他办法,比如做做特征工程,DNN加大加宽,增量训练,ODL,跨场景正样本迁移等等。
在上面这些都做过几轮优化的情况下,模型的baseline已经很强了,文中提到的0.3%~0.4%的结构优化提升,可能会收敛到0.1%~0.2%,甚至根本不存在。
总结下,还是希望看到更多FuxiCTR这样的工作,让整个RS/IR community能多点共识,论文和工作能少点割裂。
参考资料
[1]读paper--FuxiCTR: https://zhuanlan.zhihu.com/p/404814833


最后
以上就是忐忑八宝粥最近收集整理的关于华为开源CTR Benchmark,学术界SOTAs的照妖镜?的全部内容,更多相关华为开源CTR内容请搜索靠谱客的其他文章。








发表评论 取消回复