

桔妹导读:大数据是这个时代赋予我们的强大引擎,在数字化大潮中 ,借助数据驱动的方法推动业务乘风破浪,几乎是每家公司的核心战略。数据驱动的落脚点是数据,能否将组织或业务运行过程中的信息,进行有效收集并组织成信息流,是数据驱动的基石所在。本文分享了滴滴数据体系建设过程中,MySQL这一类数据源的采集架构和应用实践。
1.
背景

关系模型构建起整个数据分析的基石,关系型数据库作为具体实现、采集MySQL数据接入Hive是很多企业进行数据分析的前提。如何及时、准确的把MySQL数据同步到Hive呢?
一般解决方案是使用类似Sqoop的工具,直连MySQL去Select数据存储到HDFS,然后把HDFS数据Load到Hive中。这种方法简单易操作,但随着业务规模扩大,不足之处也逐步暴露出来:
直连MySQL查询,对于数据库压力较大(如订单表、支付表等),可能直接影响在线业务
数据整体就位时间(尤其大表)不满足下游生产需求
扩展性较差,对于分表、字段增减、变更等的支持较弱
拉取的数据是该时刻的镜像,无法获取中间变化情况
为解决上述问题,我们引入Binlog实时采集 + 离线还原的解决方案,本文将从这两个方面介绍整个数据的接入流程。
2.
整体数据流程

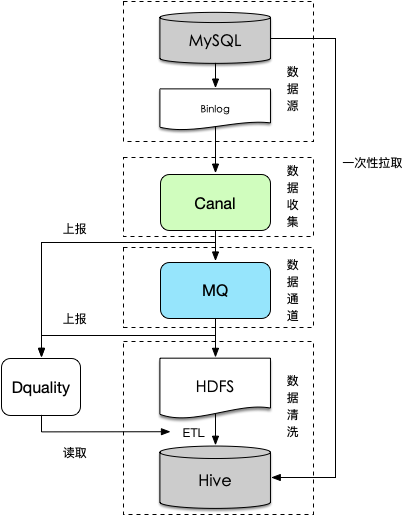
整体数据流程如上图所示,数据收集部分使用定制化Canal组件(基于阿里开源项目)收集binlog日志并做格式转换,然后通过消息队列传输并落地到HDFS,最后对HDFS上的binlog进行清洗还原入库。
如果是增量接入,上述操作就完成了一次入库流程。针对全量接入或者回溯历史数据,因为缺少历史binlog日志(发起采集时才开始收集)无法还原历史数据,此时需要借助离线一次性拉取,流程如下:
按照上述流程采集binlog日志增量入HDFS
使用离线一次性拉取一份历史全量数据,按字段还原到Hive作为基点(即第一个接入周期的数据)
使用前一个接入周期的全量数据和本周期的增量binlog做merge形成该周期内的数据。
相比一般解决方案,其优点比较明显,主要表现在:
基于Binlog日志的数据还原,与在线业务解耦
采集通过分布式队列实时传递,还原操作在集群上实现,及时性及可扩展性强
Binlog日志包括了增、删、改等明细动作,支持定制化的ETL
3.
Binlog
 MySQL Binlog是二进制格式的日志文件,用来记录数据库的数据更新或者潜在更新(比如DELETE语句执行删除而实际并没有符合条件的数据),主要用于数据库的主从复制以及增量恢复。
MySQL Binlog是二进制格式的日志文件,用来记录数据库的数据更新或者潜在更新(比如DELETE语句执行删除而实际并没有符合条件的数据),主要用于数据库的主从复制以及增量恢复。
一共有两种类型二进制记录方式:
Statement模式:每一条会修改数据的sql都会被记录在binlog中,如inserts, updates, deletes。
Row模式: 每一行的具体变更事件都会被记录在binlog中。
Mixed模式是以上两种level的混合使用,默认使用Statement模式,根据具体场景自动切换到Row模式,Row(Mixed)模式从MySQL 5.1版本起可用。
滴滴的MySQL Binlog使用Row模式,记录了每次对数据进行增删改查时,一行数据在变更前后的值,同时无论单列是否被改动,都会记录一行数据的完整信息。
4.
Canal
 Canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。滴滴内部版本在开源基础上新增了同步到MQ、消息上报功能以及容灾机制。
Canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB)。滴滴内部版本在开源基础上新增了同步到MQ、消息上报功能以及容灾机制。
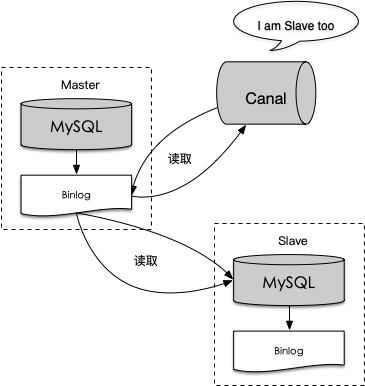
Canal主要运作方式如下:
canal模拟mysql slave的交互协议,伪装自己为mysql slave,向master发送dump协议
mysql master收到dump请求,开始推送binary log到canal
canal解析binary log对象,并将解析的结果编码成JSON格式的文本串
把解析后的文本串发送到消息队列并上报发送情况(如Kafka、DDMQ)
格式化后的单条记录新增消息示例如下:
{
"binlog": "25521@mysql-bin.000070",
"time": 1450236307000,
"canalTime": 1450236308279,
"db": "TestCanal",
"table": "g_order_010",
"event": "u",
"columns": [
{"n": "order_id", "t": "bigint(20)", "v": "126", "null": false, "updated": false},
{"n": "driver_id", "t": "bigint(20)", "v": "123456", "null": false, "updated": false},
{ "n": "passenger_id", "t": "bigint(20)", "v": "654321", "null": false, "updated": false},
{"n": "current_lng", "t": "decimal(10,6)", "v": "39.021400", "null": false, "updated": false},
{"n": "current_lat", "t": "decimal(10,6)", "v": "120.423300", "null": false, "updated": false},
{ "n": "starting_lng", "t": "decimal(10,6)", "v": "38.128000", "null": false, "updated": false},
{ "n": "starting_lat", "t": "decimal(10,6)", "v": "121.445000", "null": false, "updated": false},
{ "n": "dest_name", "t": "varchar(100)", "v": "Renmin University", "origin_val": "知春路", "null": false, "updated": true}
],
"keys": ["order_id"]
}{
"binlog": "25521@mysql-bin.000070",
"time": 1450236307000,
"canalTime": 1450236308279,
"db": "TestCanal",
"table": "g_order_010",
"event": "u",
"columns": [
{"n": "order_id", "t": "bigint(20)", "v": "126", "null": false, "updated": false},
{"n": "driver_id", "t": "bigint(20)", "v": "123456", "null": false, "updated": false},
{ "n": "passenger_id", "t": "bigint(20)", "v": "654321", "null": false, "updated": false},
{"n": "current_lng", "t": "decimal(10,6)", "v": "39.021400", "null": false, "updated": false},
{"n": "current_lat", "t": "decimal(10,6)", "v": "120.423300", "null": false, "updated": false},
{ "n": "starting_lng", "t": "decimal(10,6)", "v": "38.128000", "null": false, "updated": false},
{ "n": "starting_lat", "t": "decimal(10,6)", "v": "121.445000", "null": false, "updated": false},
{ "n": "dest_name", "t": "varchar(100)", "v": "Renmin University", "origin_val": "知春路", "null": false, "updated": true}
],
"keys": ["order_id"]
}
为保障整个Binlog链路中数据完整性,我们引入了Dquality服务。Dquality是数据通道中非常重要的一个环节,记录着整个数据通道每一个流程的数据信息,如某一段时间内的数据总和等。Dquality主要包含以下功能:
为数据回溯提供元数据支持
校验数据丢失与延迟情况
校验数据完整性
简单流程为数据链路上的各发送方在成功传递数据后,把投递结果以及时间信息发送到Dquality,Dquality统一汇总,分析判定每个时间段内数据是否完成及时准确传输,并把分析结果存储下来。下游数据使用方通过接口从Dquality查询该结果。
以Binlog链路为例,在Binlog流程中有两个环节Canal->MQ、MQ->HDFS,上报数据发送情况到Dquality。下游ETL环节使用Dquality接口查询数据就位情况,比如对于小时粒度任务,查询该小时的0分0秒到59分59秒之间的数据是否已经完成写入,如果已经完成写入,那么ETL任务就可以启动执行。
基于此,天或小时采集周期内的数据是固定的(幂等),以该时间段内的数据作为清洗基础,无论什么时候执行其结果不会改变。但在Canal上报环节,目前无法有效判定较小数据量场景和同步异常场景,一定程度上影响数据就位时间。
5.
一次性拉取&初始化
 Binlog从发起采集的一刻起才会在整个链路上存在,即以增量的方式传递,那么对于历史数据如何获取?实际场景中包括全量接入或增量历史数据回溯。
Binlog从发起采集的一刻起才会在整个链路上存在,即以增量的方式传递,那么对于历史数据如何获取?实际场景中包括全量接入或增量历史数据回溯。
目前实现方式为通过DataX工具直连MySQL离线库,拉取一份截至到当前时间的全量数据,然后按列还原到Hive表的首个分区中。
全量采集场景下,下个分区的数据基于上个分区的数据和当前周期内的增量Binlog日志merge,即可产生该分区内的数据。
上面介绍了基于Binlog数据接入的整体流程,下面列举两个实际解决的业务问题。
6.
场景一:数据飘移的支持
 在实际业务中,存在很多类似的两种case,其采集周期存在一定的不确定性。
在实际业务中,存在很多类似的两种case,其采集周期存在一定的不确定性。
case 1:订单的Binlog日志中,当订单事件的更新时间在59分59秒左右时,数据有可能会落在下一个小时的分区,以至于当前小时数据没有统计到该条订单,同时下一个小时分区的数据也没有打上相应的事件标签。
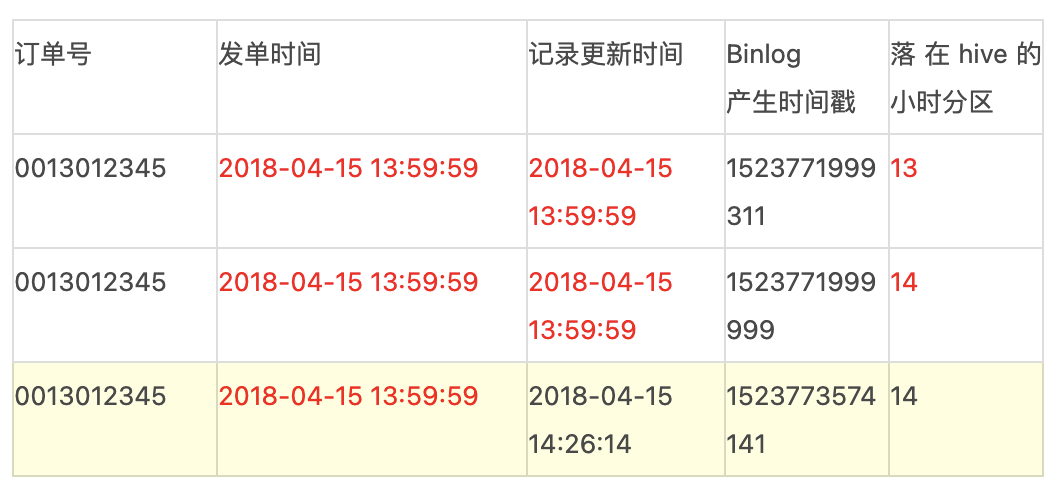
case 2:支付结算系统,当天所有交易记录会在次日凌晨后结算完成,按照默认采集逻辑,当天的记录落在次日的变更内,无法有效支持当天核算。
以上两个case的常规解决方案可能是把下个小时的数据也囊括到本采集周期内,但会导致数据就位时间延迟一个小时,扩散到数据下游,时间会更长,可能不满足实际需求。采集平台提供数据漂移的功能,即按需配置偏移量。比如小时粒度默认为00:00 - 59:59之间的数据,配置5min的偏移,那么数据区间为00:00 - 04:59(次小时),多出来的部分可以有效解决数据漂移功能,同时为及时性提供了有效支撑。
该功能在专快订单、财务应付应收以及国际化部分都有应用。但需要注意的是,下个采集周期内也包含了这部分实际发生在该区间内的数据。
7.
场景二:分库分表的支持
 业务发展,不可避免会有分库分表的诉求,其规则也可能多种多样,如table_{城市区号},table_{连续数字},table_{日期},如果逐个抽取并聚合,上下游的成本巨大。因此我们需要在数据规范层面,数据链路上保障能自动化收集这类数据。
业务发展,不可避免会有分库分表的诉求,其规则也可能多种多样,如table_{城市区号},table_{连续数字},table_{日期},如果逐个抽取并聚合,上下游的成本巨大。因此我们需要在数据规范层面,数据链路上保障能自动化收集这类数据。
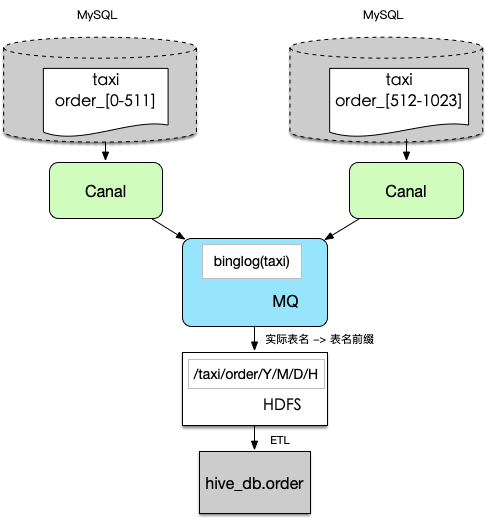
1. 统一MySQL使用规范,明确分库分表的命名规则,做到规则内自动化识别,同时完成全量元数据信息的收集,非规范化的命名规则无法自动化支持。
2. 默认情况下一个库的数据会收集到一个topic内,如果有分库存在也可以一并收集到一个topic内,保证逻辑上分库分表的数据物理上收集到一起。
3. 按照/{db}/{table}/{year}/{month}/{day}/{hour}的路径结构(其中日期由Binlog时间格式化生成)落地到HDFS上,一个逻辑表的数据存储在一起。
4. ETL处理阶段,取出上述路径下的Binlog日志,还原到Hive中。
为用户更好使用分库分表数据以及获取中间变化过程,ETL阶段额外再Hive表中写入三个字段:
system_rule_etl_update_field | 记录更新时间,更新晚的对应该字段的值更大,前十位是时间戳信息 |
system_rule_etl_delete_flag | 标识本条记录是否在上游数据库中被删除,0-正常记录,1-删除记录 |
system_rule_etl_uniq_key | 全局主键,由mysql库名+表名+主键拼接而成 |
8.
总结
 作为数据建设的基础,数据平台提供的基于Binlog的MySQL入Hive服务,覆盖公司内部各个业务线,日1.9w+同步任务,近50T数据同步量,实时层面毫秒级别延迟,实现了及时、准确、定制化的同步需求。但在个性化ETL、性能优化、内容建设等方面还存在未解决的问题,后续我们会在这些方面重点发力,更好的助力业务发展。
作为数据建设的基础,数据平台提供的基于Binlog的MySQL入Hive服务,覆盖公司内部各个业务线,日1.9w+同步任务,近50T数据同步量,实时层面毫秒级别延迟,实现了及时、准确、定制化的同步需求。但在个性化ETL、性能优化、内容建设等方面还存在未解决的问题,后续我们会在这些方面重点发力,更好的助力业务发展。
团队内推
▬
滴滴数据平台与应用部(DT),致力于打造准确、稳定、高效、易用的数据中台体系,从而赋能业务发展。我们不仅拥有稳定优质的大数据算力,完善的数据产品矩阵和业界领先的算法策略。也同时深入业务,为业务的快速发展提供准确、敏捷的数据服务支撑。除了提供数据资产、数据产品、数据应用相结合的体系化解决方案之外,我们也勇往直前,持续探索数据智能应用场景!欢迎大家加入我们,一起创造数据价值!
团队正在热招高级/资深数据研发工程师岗位。欢迎有兴趣的小伙伴加入,可以投递简历至diditech@didiglobal.com,请将邮件主题命名为 姓名-投递岗位-投递团队。

扫一扫了解更多
本文作者
▬

延伸阅读
▬



内容编辑 | Teeo
联系我们 | DiDiTech@didiglobal.com
最后
以上就是苗条薯片最近收集整理的关于滴滴基于Binlog的采集架构与实践的全部内容,更多相关滴滴基于Binlog内容请搜索靠谱客的其他文章。








发表评论 取消回复