

桔妹导读:滴滴作为一家网约车交易平台,乘客和司机的体验和安全是其核心壁垒之一。在体验和安全优化过程中,缺少准确而大量的标注样本,是制约模型效果、进而影响业务优化的重要技术难题。在滴滴,我们使用few shot的方法,在治理和安全场景做了大量的探索,形成了一套系统的解决方案。
1.
相关工作

▍1.1 基本理论
小样本学习技术主要研究如何利用少量有监督样本来解决机器学习任务。经常被提起的还有半监督学习,其主要区别在于,半监督学习是解决小样本学习问题的重要手段之一。
小样本学习的综述很多,其中YAQING WANG等人【1】分类标准清晰且合理,故引用此种分类方式。其将小样本学习技术分为三类方式:
数据:利用先验知识来做数据增强,构造更多样本。
模型:利用先验知识来降低机器学习任务的假设空间,模型参数搜索空间减小,所需样本也相对减少;
算法:利用先验知识,改善参数搜索策略。
上述的三种方法,核心就是要解决样本少而模型假设空间大的矛盾,尤其在深度学习场景,模型的参数量巨大。在实际运用中,几种方法可同时使用。下面简要介绍三类方法中的一些常用的技术。
▍1.2 数据增强
数据增强是小样本学习场景最常用的方式之一,其复杂度也相对较低,这里分享下两种方案,包括样本特征增强和弱监督学习。对于样本特征增强,经典案例包括图像识别领域对图像进行翻转、旋转和缩放等;文本增强领域也有类似的方法,如文本分类场景,会对样本进行同义替换、随机插入和随机交换和随机删除等,使用原来训练数据的50%结合文本增强的方法就到达了使用100%训练数据的准确率【2】。这种手动进行样本特征增强的方式,其优点在于构思简单,效果稳定,但其依赖于领域知识进行增强规则设计,且无法穷举所有的可能性,其效果上限较低。
另外一种常用的样本增强方式是,弱监督学习,主要包括半监督学习和主动学习。半监督学习主要解决如何利用少量有标签样本以及大量无标签样本构建模型的问题,常见方法有自学习、协同训练和生成式学习等,篇幅受限,主要讲下常用的自学习,其基本原理是如下图所示:
1)首先利用少量的有监督样本,训练一个初始模型
2)利用初始模型对未打标的样本进行预测,如果模型得分比较低或者高,将其加入初始的训练集,其标签为模型预测标签
3)利用新的训练集,进行模型迭代,重复以上流程,直至模型效果无提升
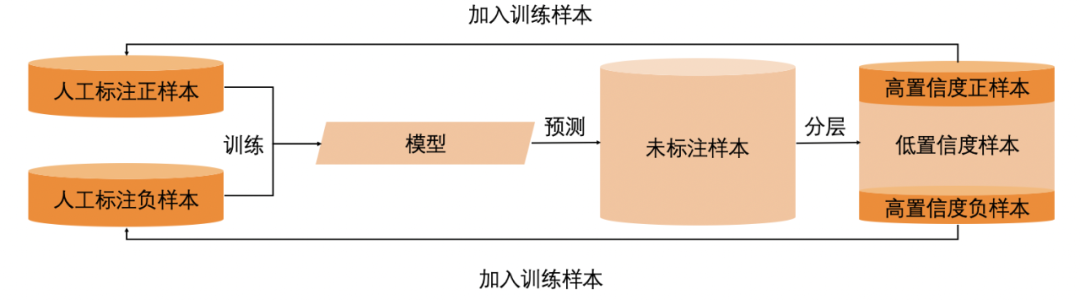
图 1 自学习建模流程
主动学习的核心技术点在于在标注资源有限的情况下,如何选择信息含量高的样本进行标注。但通过自学习引入样本的过程,也会有弊端,第一是无法避免引入噪音,因为模型预测的标是”伪标签“,第二,往训练集中加入的样本均为易分类的样本,导致真正难分类的样本的权重相对下降,继而出现测试集上效果较差的情况。因而,自学习会出现增加几轮样本后,效果不增反而下降的情况,所以选择合适的迭代轮次和每次加入的样本量尤为重要。
▍1.3 模型
根据上文所述,模型部分主要通过降低模型参数的搜索空间来降低对样本的需求。多任务学习(Multi-task learning, MTL)是其中典型的技术方案,主要利用拥有大量数据的辅助任务进行参数学习与共享,降低主任务的参数搜索空间。下图是一种最为简单的硬参数共享【3】,如果想要较好的模型效果,其难点在于如何选择相似的辅助任务,第三部分会介绍下,如何结合业务逻辑,选择合理的辅助任务。
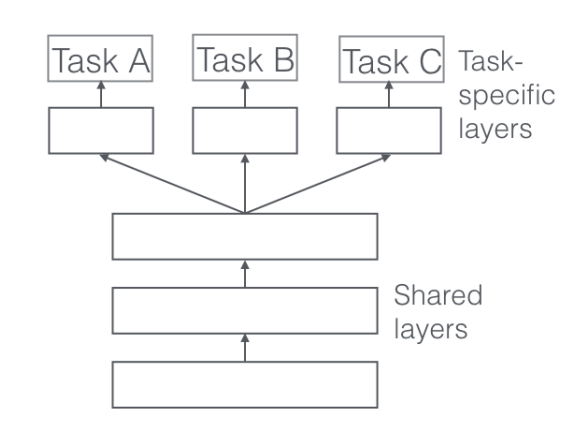
图2 多任务学习硬共享机制
▍1.4 算法
这里的算法特指参数优化算法,在样本有限的情况下,利用经验风险最小化进行参数搜索是不可靠的,故需要利用先验知识,获取相对可靠的参数,其中最常见的方法是利用其他相关的任务进参数初始化,并使用实际任务的数据对参数进行微调(Fine-tune),通常有选择的调整部分参数,来防止小样本学习导致的过度拟合的问题,这要是工业界常用的方式,例如NLP领域Bert+ 任务数据微调以及图像领域使用ImagetNet构建的VGG等模型 + 任务数据微调等方式。
2.
业务场景应用

▍2.1 数据增强
涉性骚扰订单识别中的数据增强应用
在涉性骚扰订单识别中,我们通过case分析发现该类订单中,92%的比例都存在司机言语反抗(如图3所示),因此需要建立识别司机反抗模型。
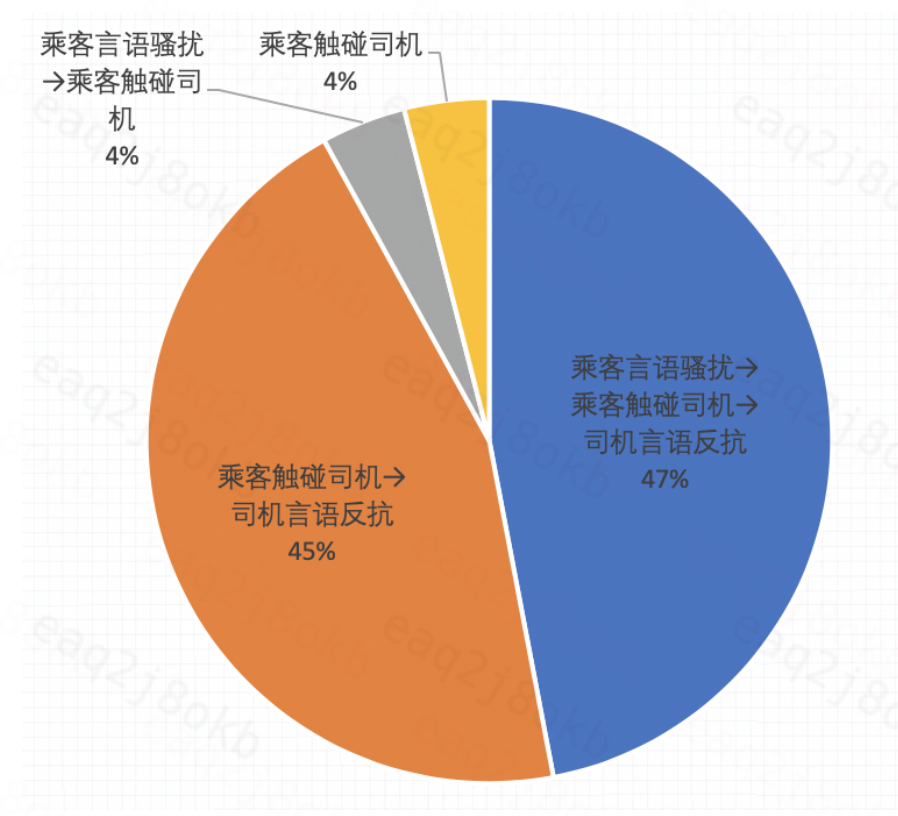
图3 L3R订单分类
因为发生数量较少,训练模型时需要解决正样本稀疏的问题。构建反抗言语识别模型所用的重要特征为行程中语音ASR文本(如图4所示),在分析相关文本时,发现司机反抗言语通常是突然出现的,与上下文没有联系,于是我们可以通过对负样本文本插入反抗关键短句的方式来对样本进行增强。

图4 语音转录文本示例展示
首先从真实发生的订单中提取了852条反抗关键短句,如“你赶快下车”、“不要这样”。
为模拟真实ASR文本环境,增强模型的泛化性,先对关键短句进行增强,以3:3:3:1的比例对短句进行如下操作:
不变;
加字:随机复制一个字,变为“你你别动手动脚”或“你别动动手动脚”;
删字:对字数大于5的关键短句,随机删除一个字,变为“你动手动脚”或“你别动手脚”;
拼接:对字数小于等于7的两个关键短句,进行拼接,如“你别动,坐好了”。
最后抽取120万负样本的ASR文本作为训练样本,对其中40万个文本随机插入增强后的关键短句作为正样本(有0.1的概率随机插入两次关键短句)。
得到训练所需的正负样本后,对文本特征进行噪音清洗、分词等流程,然后训练TextCNN模型。如表1所示,对比未使用数据增强、通过增加L4R订单作为正样本的扩充方案的模型,使用数据增强的模型效果更好。
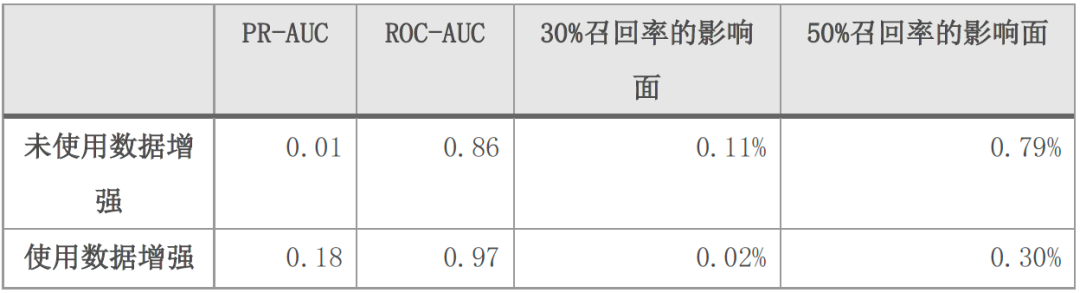 表1 不同数据处理方式效果对比
表1 不同数据处理方式效果对比
半监督学习在费用投诉司乘判责中的应用
业务特点:平台上每天都有少量乘客关于费用相关的投诉,包括但不限于:绕路导致费用增加、未乘车需要支付费用、下车后司机未结束计费导致费用增加等等,为了对这些投诉进行合理的处理,平台建立了司乘判责体系,使用判责结果对犯错的司机加以管控,对体验受损的乘客给予补偿。为了使司乘判责体系更加智能化,机器判责在其中占据最重要的位置,而机器判责能力的建设,与专家标注样本息息相关。一般情况下,司乘判责模型的单次迭代需要5k-1w的专家标注样本,这些样本的获取是昂贵且长周期的。
技术选型:为了在有限专家标注样本的基础上使得模型效果最大化,我们在实际应用中引入了self-training方法。self-training是半监督学习中最常用的方法之一,以其简单易实现且效果好的特点被广泛应用于实际业务场景中,其执行流程2.2节中已有介绍,此处不再赘述。
效果对比:下图5是self-traning迭代3轮后,在费用投诉司机判责模型中的相对于原始样本训练Xgboost模型时logloss的变化对比,可以看到,使用self-training方法扩充后的样本集训练出的模型在测试集上的logloss比使用原始样本直接训练模型在测试集上的logloss低20%+,验证了使用self-training扩充样本能够对模型效果带来提升。
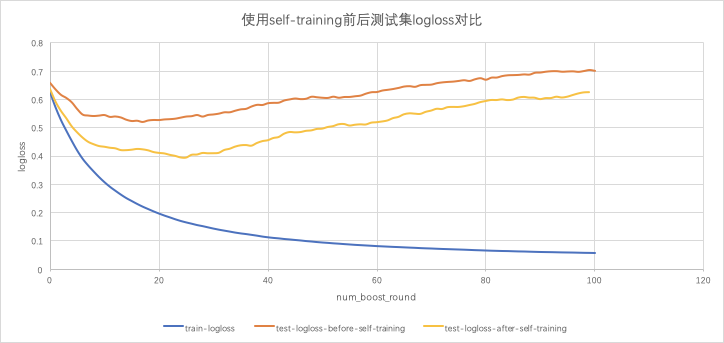 图5 不同数据集模型Loss对比
图5 不同数据集模型Loss对比
▍2.2 模型
下面以绕路拦截中的多任务学习为例,介绍我们在该方向的探索
业务特点:拦截指的是当出现费用异常问题时,希望能够在乘客投诉前,尽快识别费用异常行为(如绕路、未坐车多收附加费、未及时结束计费等),平台主动干预提升乘客体验。因此,就需要我们的策略模型,能够准确地识别出投诉&有责的订单,并及时作出有效的拦截。
然而,在拦截场景中,我们的样本空间正负样本比极度不均衡。如图6所示,拦截的生效空间是大盘订单,拦截的目标是投诉中的司机有责订单,虽然我们能获得大量的投诉样本,但投诉占大盘比例小,从而导致投诉&有责的正样本量极少(以绕路拦截为例,投诉中有责比例1/5,而投诉占大盘比例1/2500)。
若以大盘订单为建模空间,以投诉&有责为正样本(以下简称事实任务),由于正样本量稀少,该任务的建模效果差;而以投诉订单为建模空间,以投诉&有责为正样本(以下简称判责任务),以此建模在大盘上生效又会导致样本偏差,难以识别非投诉样本。
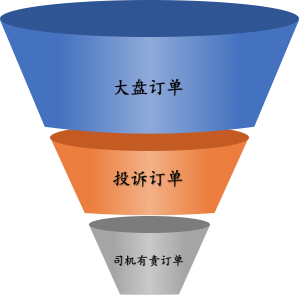
图 6 拦截场景漏斗
技术选型:结合拦截实际的业务特点,可以通过多任务学习的方式,解决正样本量小的问题。由于投诉样本无需标注、正样本量级大,以大盘订单为建模空间,以投诉为正样本的任务(以下简称投诉任务)与事实任务有着强相关性,因此可以通过投诉任务来辅助事实任务的学习,如图7所示。分别学习投诉任务与事实任务,2个任务共享embedding层和部分隐藏层,同时2个任务分别保留各自独立的隐层,最终分别输出结果。投诉任务有大量的正负样本,能够辅助事实任务学习到一些知识,降低事实任务的模型参数搜索空间,从而保证事实任务能够得到更好的学习,也就解决了事实任务正样本少和样本偏差的问题。
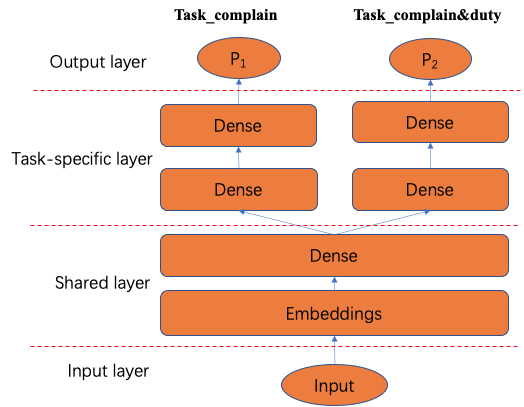
图7 绕路拦截多任务模型结构
效果对比:根据上述方法,在绕路拦截场景上,采用esmm的多任务模型结构,利用辅助任务模型建模。如图8和图9的实验结果可知,在roc曲线中,MTL模型roc-auc明显优于线上xgb模型;在pr曲线中,2个模型的prc-auc基本持平,但在策略生效点处,MTL模型的准召相较于XGB模型也有较大的提升。多任务学习的方式能够有效地学习到投诉任务的特点,更好地辅助事实任务学习,最终该方案的模型已在绕路场景上使用。同时,拦截上许多场景存在相似的情况,因此多任务学习的方案也可以在许多场景上复用。
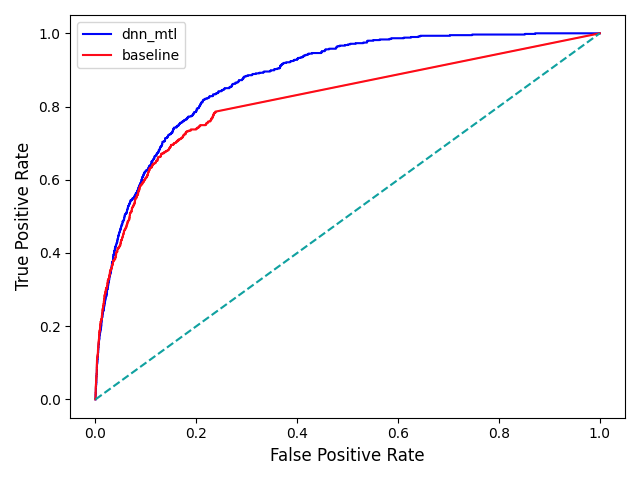
图8 Baseline与MTL模型的ROC曲线
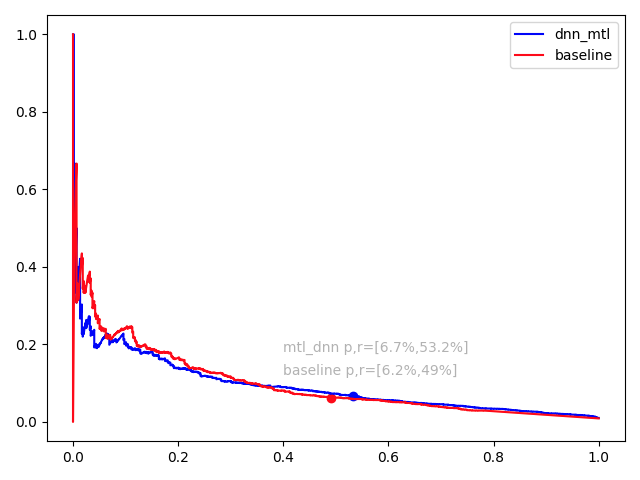
图9 Baseline与MTL模型的PR曲线
结论:对于样本量小引起的模型效果不佳问题,我们也能从业务、数据的角度去看问题,通过业务理解和有效地数据分析,发现任务之间的相关性,选择适当的任务来辅助主任务的学习,利用其他的知识来帮助主任务学习地更充分,解决小样本问题,提升模型的性能。
▍2.3 算法
下面以交通事故早发现fine-tune优化为例,介绍我们在该方向的探索
业务特点:在安全领域中,滴滴的标注样本是非常稀疏且昂贵的,举个例子,一个涉性正样本,背后就是一起性骚扰,一次重伤交通事故样本,背后有可能就是一条人命。一方面,滴滴在安全领域已构建了相应的订单风险识别策略,一旦检测到订单出现险情,会有安全专家及时介入提供帮助,为司乘的出行保驾护航,而另一方面,在如此昂贵且规模很小的数据集的情况下,如何构建更加精准的识别策略,是一项重要而又艰巨的挑战。
与此同时,滴滴的数据里有数量庞大、信息丰富的弱样本(言语骚扰/轻微人伤事故),以交通事故为例,轻微人伤事故在轨迹声音等各种异常表现上和重伤事故具有一定的相似性,但直接加入模型训练对应的业务效果是下降的,因此,如何高效地利用这些样本,使得这些样本的价值最大程度地体现在策略效果中,成为此类策略设计的关键环节之一。
对比业内的各种弱样本应用方法,我们发现这个场景恰好与 使用海量源领域数据对网络底层参数进行预训练,学习源领域和目标领域通用的信息,然后用目标领域的样本对接近具体任务层的网络参数进行fine-tune 的场景非常类似,于是我们将对应的数据以两种方式进行了迁移应用,并对比了两种方式带来的效果提升。
效果对比:
实验1: DNN模型
Baseline:全部人伤事故作为正样本,无事故订单作为负样本,
fine-tune:重伤事故作为正样本,无事故订单作为负样本,在基础模型的网络参数基础上更新最后两层的网络参数。
安全策略的评估指标为一定影响面下的召回率。
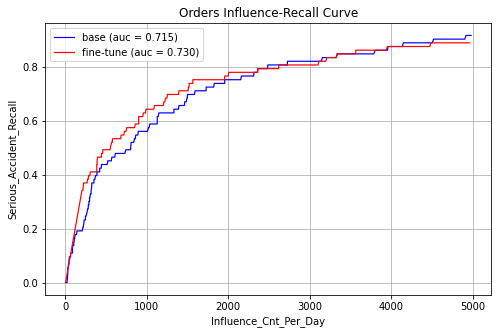
图10 基础DNN模型和fine-tune后模型影响面-召回率曲线
从整体auc上来看,使用人伤样本做预训练,重伤样本微调,对模型评估集上的auc有一定的提效果,尤其是在影响面较小的情况下。
实验2:XGBoost模型
XGBoost的迁移主要是增量学习
Baseline:全部人伤事故作为正样本,训练基础的XGBoost树模型,
fine-tune:在baseline模型的基础上,使用重伤事故作为正样本,微调叶子节点权重。
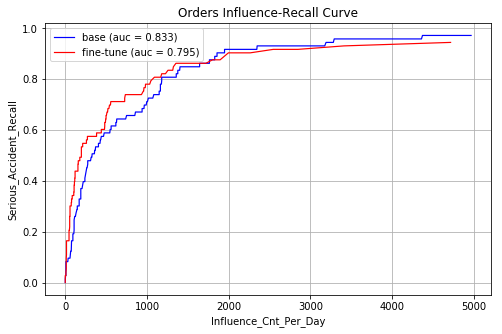
图11 基础xgboost模型和fine-tune后模型影响面-召回率曲线
从图中可以看出,迁移之后可以显著改善头部case的排序性能。
结论:在影响面较小的情况下,Fine-tune能够有效改善头部Case的召回率,正好符合业务的诉求,即在较低的影响面情况下,召回重伤Case,故我们将该方法推广开来,在多个安全场景和基本的识别元能力建设上均落地应用,并取得一定收益。
3.
总结

在滴滴复杂的治理业务场景中,对样本的需求量极大,标注的成本很高。通过对现有的小样本学习方法的探索,我们在自己的业务场景上试验并落地了多种算法,在支撑我们拿到了一定的业务收益的同时,也降低了一部分标注的成本,希望能给同样遇到样本匮乏问题的读者一些借鉴。
本文作者
▬







Reference
1. Wang, Yaqing, Quanming Yao, James T. Kwok, and Lionel M. Ni. "Generalizing from a few examples: A survey on few-shot learning." ACM Computing Surveys (CSUR) 53, no. 3 (2020): 1-34.
2. Wei, Jason, and Kai Zou. "Eda: Easy data augmentation techniques for boosting performance on text classification tasks." arXiv preprint arXiv:1901.11196 (2019).
3. Ruder, Sebastian. "An overview of multi-task learning in deep neural networks." arXiv preprint arXiv:1706.05098 (2017).
团队招聘
▬
滴滴MPT-生态引擎算法团队隶属于滴滴网约车公司,致力于构建滴滴的安全体验和服务纠纷治理算法体系,通过建设行程前中后的安全预防、纠纷治理算法能力,赋能滴滴网约车安全和治理业务,建立可持续健康发展的出行生态。在这里你将有机会创造“世界级”技术价值,与滴滴共同成长,加入我们,用技术的力量一起解决出行中的不美好。
团队目前热招算法工程师中,欢迎有兴趣的小伙伴加入,可投递简历至 diditech@didiglobal.com,邮件请邮件主题请命名为「姓名-投递岗位-投递团队」。

扫码了解更多岗位
延伸阅读
▬



内容编辑 | Hokka联系我们 | DiDiTech@didiglobal.com
最后
以上就是诚心小虾米最近收集整理的关于小样本学习在滴滴治理和安全场景应用本文作者▬Reference的全部内容,更多相关小样本学习在滴滴治理和安全场景应用本文作者▬Reference内容请搜索靠谱客的其他文章。








发表评论 取消回复