第一章 大数据概述
GB-->TB-->PB-->EB-->ZB
1、大数据特征:4V
Volume(数量大)、Variety(数据类型多)、Velocity(处理速度快)、Value(价值密度低)
2、大数据的构成:
结构化数据:具有固定的结构,属性划分。通常直接放在数据库表中,数据记录的每一个属性对应数据表的一个字段
半结构化数据:具有一定结构,但又有一定的灵活可变性。如XML、HTML
非结构化数据:无法用统一的结构来划分,如文本文件、图像、视频、声音
3、大数据相关环节:
数据采集、数据存储和管理、数据处理和分析、数据隐私和安全
4、大数据计算模式:
批处理计算(MapReduce、spark)、流计算(flume)、图计算、查询分析计算
5、大数据与云计算、物联网
大数据--云计算:云计算为大数据提供了技术基础,大数据为云计算提供用武之地
云计算--物联网:物联网为云计算提供应用空间,云计算为物联网提供海量数据存储能力
物联网--大数据:大数据为物联网数据分析提供支撑,物联网是大数据的重要来源
第二章 Hadoop概述
1、Hadoop简介:
Hadoop是一个开源的,分布式存储和分布式计算平台,提供可靠的、可扩展的分布式计算,创始人是Doug Cutting。
2、Hadoop特性:
高可靠性:采用多副本冗余存储方式,即使一个副本发生故障,其他副本还可以对外服务
高效性:采用分布式存储和分布式处理两大核心技术,高效地处理PB级别的数据
高可扩展性:高效稳定的运行在廉价的计算机集群上,可以扩展到数以千计的节点
高容错性:采用冗余存储方式,自动将失败的任务重新分配
成本低:采用廉价的计算机集群,成本低,普通用户也可以搭建Hadoop运行环境
成熟的生态圈:拥有成熟的生态圈,囊括大数据处理的方方面面
3、Hadoop核心组件:
- hdfs:将文件切分成指定大小的数据块并以多副本的方式存储在多个机器上
- map/reduce:分布式计算模型,完成海量数据离线处理
- yarn:负责整个集群资源的管理和调度
4、Hadoop生态组件
HDFS、MapReduce、Yarn、Hive、HBase、Pig、Sqoop、Zookeeper、Flume、Kafka、Spark
5、Hadoop的安装:
(1)下载jdk及Hadoop安装文件
(2)配置java环境变量
(3)配置Hadoop:
- 了解Hadoop目录结构
- 配置Hadoop相关环境变量
- 编辑${HADOOP_HOME}/etc/hadoop/hadoop-env.sh,配置JAVA_HOME
- 配置core-site.xml
- 配置hdfs-site.xml
- 格式化系统文件:hdfs namenode -format
- 启动集群,测试验证:start-dfs.sh
第三章 分布式文件系统HDFS
1、基本概念
HDFS:Hadoop Distributed File System
块(Block):HDFS的文件被分成块(默认128M)以副本(通常副本数为3)的形式存储在多个节点上
HDFS中有两类节点:NameNode和DataNode
NameNode是管理节点,存放文件元数据,包括文件与数据块的映射、数据块与节点的映射
DataNode是工作节点,存放数据块
2、HDFS特点
- 数据冗余,硬件易错
- 适合存储大文件,一次写入,多次读取,顺序读取,不适合多用户并发写相同文件
- 适合批量读写,吞吐量高;不适合交互式应用,低延迟很难满足
3、管理策略
- 每个数据块3个副本,分布在两个机架内的三个节点上
- 心跳检测:DataNode定期向NameNode发送心跳信息,汇报自己的健康状况
4、HDFS读写流程
- 读文件流程:文件读取请求-->返回元数据-->读取Blocks
- 写文件流程:文件拆成块-->返回DataNode-->写入Blocks-->流水线复制-->更新元数据
5、Shell访问HDFS
- 启动Hadoop服务:start-dfs.sh hdfs命令:
- hdfs命令:
查看hdfs目录内容(如:根目录):
hadoop fs -ls /
建立目录(-mkdir),建立多级目录,加-p参数:
hadoop fs -mkdir -p /a/b
将本地文件(centos)上传到hdfs,用-put:
hadoop fs -put 1.txt /a/b
查看某一个文本文件内容或某目录下全部文本文件内容(-cat或-text):
hadoop fs -cat /a/b/1.txt
hadoop fs -cat /a/b/*.txt
将hdfs文件下载到本地(centos):
hadoop fs -get /a/b/4.txt .
hdfs之间拷贝(-cp)、移动文件(-mv)
hadoop fs -cp /a/b/1.txt /a
hadoop fs -mv /a/b/2.txt /a
删除目录或文件(-rm,级联删除加-r)
hadoop fs -rm -r /a
6、Java访问HDFS
- 启动Hadoop
- 编程步骤:
- 获取configuration对象
- 得到文件系统的实例对象FileSystem
- 使用FileSystem对象操作文件
第四章 MapReduce
1、MapReduce概述
MapReduce是一个分布式运算程序的编程框架,是Hadoop核心框架之一
2、MapReduce思想
- MapReduce采用“分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各子节点共同完成,接着通过整合各子节点的中间结果,得到最终的结果。
- MapReduce将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce
- MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”
3、MapReduce编程
打包执行命令:hadoop jar wc.jar WordCount /input /output
第五章 资源调度框架Yarn
1、设计思路:是一个纯粹的资源管理调度框架,而不是一个计算框架
2、核心组件:
ResourceManager:负责集群资源的统一管理和调度,整个集群只有一个
NodeManager:集群中有很多个,负责单节点资源管理和使用
ApplicationMaster:每个应用一个,负责应用程序管理
-
第六章 HIVE简介
1、数据仓库:
- 数据仓库:面向主题的、集成的、稳定的、随时间变化的数据集合
- 数据仓库系统的构成:数据仓库、仓库管理和分析工具
- 传统数据仓库无法满足快速增长的海量数据的存储要求、无法有效处理不同类型的数据、计算和处理能力不足
2、Hive优点
- 解决了传统关系数据库在大数据处理上的瓶颈。适合大数据的批量处理
- 充分利用集群的CPU计算资源、存储资源,实现并行计算
- hive支持SQL语法,免去编写MR程序的过程,减少了开发成本
- 具有良好的扩展性,扩展功能方便
3、Hive缺点
- Hive的HQL表达能力有限:有些复杂运算用HQL不易表达
- Hive效率低
4、Hive常用命令
进入终端:hive
不进入终端:hive -e “hql命令”
5、表操作
(1)创建表:
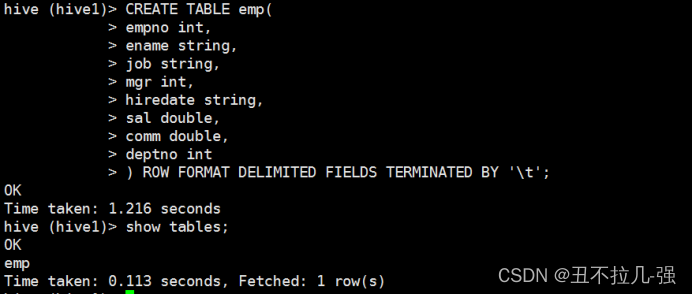
该命令较复杂,可以存到hql文件中,以hive -f的形式执行:
vim emp.sql
hive -f emp.sql
以第一个表为模板建立第二个:
create table emp1 like emp;
(2)查看表结构:
describe emp;或describe formatted emp;
(3)修改表:
alter table emp rename to emp1;
(4)删除表:
drop table 表名
(5)加载数据:
load data [local] inpath ‘filepath’ [overwrite] into table tablename;
(6)用查询结果创建一个表:
create table emp1 as select * from emp;
(7)导出数据
insert overwrite local directory ‘filepath’
row format delimited fields terminated by ‘t’
select * from emp;
第七章 分布式数据库HBase简介
1、Hbase概述
Hbase是一个构建在HDFS上、分布式、面向列的开源数据库。主要用于存储海量数据,提供准实时查询
2、Hbase特点
(1)大:一个表可以有上百亿行,上百万列
(2)面向列:面向列族的存储和权限控制,列独立检索
(3)稀疏:对于为空(NULL)的列,并不占用空间
(4)数据多版本
(5)无模式
(6)数据类型单一:Hbase中的数据都是字符串,没有类型
3、与关系数据库对比
(1)数据类型:关系数据库使用关系数据类型,Hbase则采用更加简单的数据模型
(2)数列操作:关系数据库会涉及复杂的多表连接。Hbase只有简单的插入删除等操作
(3)存储模式:关系数据库是基于行模式存储的。Hbase是基于列存储的,每个列族都由几个文件保存,不同列族的文件是分离的
(4)数据索引:关系数据库通常可以针对不同列构建复杂的多个索引,以提高数据访问性能。Hbase只有一个索引--行建。
(5)数据维护:关系数据库,更新操作会用最新的当前值去替换记录中原来的旧值。而在Hbase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新版本。
(6)可伸缩性:关系数据库很难实现横向扩展,纵向扩展的空间也比较有限
4、Hbase数据模型
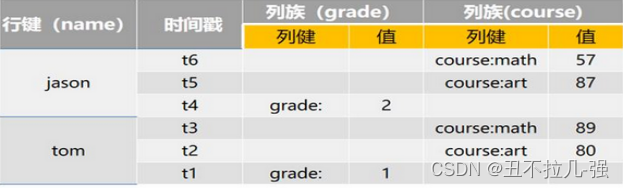
(1)ROW Key:行的主键,标识一行数据,也称行键,用来检索记录的主键
(2)Hbase表中数据访问的方式:
通过单个Row Key访问
通过Row Key的Range
(3)全表扫描:Row Key行键可以是任意字符串
5、Hbase的安装与使用
(1)安装Zookeeper:
配置环境变量和相关配置文件:
启动:zkServer.sh start
状态:zkServer.sh status
停止:zkServer.sh stop
验证zk启动是否成功,看有无QuorumPeerMain
(2)安装Hbase:
配置环境变量和相关配置文件,启动:先启动zookeeper、hdfs,start-hbase.sh
启动后多两个进程:HMaser、HRegionServer
第八章 NoSQL数据库
1、NoSQL简介
NoSQL数据库的特点:灵活的可扩展性、灵活的数据类型、与云计算机密耦合
2、兴起原因
(1)关系数据库无法满足海量数据的管理要求、无法满足数据高并发的需求、无法满足可扩展性和高可用性的需求
(2)关系数据库的关键特性包括完善的事务机制和高效的查询机制,MongoDB、Redis等是针对在线业务,两者都抛弃了关系模型。
3、NoSql安装与操作
(1)Redis键值数据库:
下载安装、配置环境变量
(2)MongoDB文档数据库:
下载、配置环境变量,并source ~/.bash_profile
第九章 离线处理辅助系统Sqoop
1、Sqoop的使用
基于Hadoop与RDBMS间的数据传输工具,是Apache顶级项目
Sqoop=Sql+Hadoop
sqoop通过Map任务来传输数据,不需要Reducer
2、操作和常用命令
下载、解压、配置环境变量并source
(1)mysql导入hdfs(需要启动hdfs和yarn)

(2)hdfs导出mysql

(3)mysql导出hive

(4)hive导出到mysql
主要步骤为将hive中的数据导出到本地,本地上传hdfs,最后将hdfs中的导入到mysql
3、Sqoop job的使用
将常用的Sqoop脚本定义成作业,方便其他人调用

第十章 数据可视化
1、Windows下进行web开发项目
(1)下载并解压Tomcat8
(2)打开eclipse 切换至java ee项目
(3)编码区下方,选择server选项卡,点击No servers。。。那行链接开始添加服务器,选择Tomcat8,server就设置好了。
(4)File-New-Dynamic Web Project,工程名任意(别用汉字),next。。。-完成。
(5)数据库驱动jar包拷贝至工程目录-WebContent-WEB-INF-lib下,编写页面、代码等
(6)部署工程到服务器:点击建好的server,选择add and remove,在对话框中选择左边的工程,点击add按钮,加到右边(部署到服务器上),完成。
(7)右击启动服务器
(8)打开浏览器,输入地址http://localhost:8080/echarts/页面名字,分别查看网页效果。
第十一章 spark
1、spark概述
基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。
2、spark特点:
运行速度快、容易使用、通用性、运行模式多样
3、Scala简介
Scala是Spark的主要编程语言,Spark还支持Java、Python、R作为编程语言。
Scala是一门现代的多范式编程语言,运行于Java平台(JVM,Java 虚拟机),并兼容现有的Java程序;
4、Spark与Map/Reduce对比
Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比Hadoop MapReduce更灵活;
Spark提供了内存计算,可将中间结果放到内存中,对于迭代运算效率更高;
Spark基于DAG(有向无环图)的任务调度执行机制,要优于Hadoop MapReduce的迭代执行机制;
第十二章 流计算框架
1、流数据特征
数据快速持续到达,潜在大小也许是无穷无尽的;
数据来源众多,格式复杂;
数据量大,但是不十分关注存储,一旦经过处理,要么被丢弃,要么被归档存储;
注重数据的整体价值,不过分关注个别数据;
数据顺序颠倒,或者不完整,系统无法控制将要处理的新到达的数据元素的顺序。
2、流计算应用
流计算是针对流数据的实时计算,可以应用在多种场景中,如Web服务、机器翻译、广告投放、自然语言处理、气候模拟预测等。流计算适合于需要处理持续到达的流数据、对数据处理有较高实时性要求的场景。
3、常用流计算框架
现今常用的流计算框架有三个:Storm、Spark Streaming和Flink,它们都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点。
第十三章 数据采集与预处理
1、概述
(1)数据分析过程:数据采集与预处理、数据存储与管理、数据处理与分析、数据可视化
2、Flume简介
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3、Kafka简介
Kafka是由LinkedIn公司开发的一种高吞吐量的分布式消息订阅分发系统,用户通过Kafka系统可以发布大量的消息,也能实时订阅和消费消息。
最后
以上就是痴情悟空最近收集整理的关于大数据计算框架复习第一章 大数据概述第二章 Hadoop概述第三章 分布式文件系统HDFS第四章 MapReduce第五章 资源调度框架Yarn 第六章 HIVE简介第七章 分布式数据库HBase简介第八章 NoSQL数据库第九章 离线处理辅助系统Sqoop第十章 数据可视化第十一章 spark第十二章 流计算框架第十三章 数据采集与预处理的全部内容,更多相关大数据计算框架复习第一章内容请搜索靠谱客的其他文章。








发表评论 取消回复