离群点检测(outlier detection)在很多领域都具有广泛的应用。离群点检测算法也各种各样,各种类型各种算法难以计数。我的研究是提出新的效能更好的离群点检测算法(模型)。
离群点检测整体我认为包含有3部分,分别是:数据集,模型,结果。最近一段时间(一个月左右)将全部关注自己整体逻辑的构建与完善。分别从3点出发,逐步理解和完善通这个架构。
一、数据集
离群点检测所用的数据集一般包含有合成数据集与真实数据集。那么我们从相对初始的数据集开始进行处理,一步步进行介绍。
收集到的数据集或者从网上下载的数据集中,相对粗糙,基本未进行处理。为了方便的进行描述,本节以ODDS官网(http://odds.cs.stonybrook.edu/)数据集中的WBC等数据集为例,进行描述。对数据集的处理我认为基本包含了以下几个重要过程:
a):对数据集中缺失数据的处理;b): 特征编码(如one-hot或者哑编码等)c):正则化、特征缩放、标准化等;d): PCA降维看看数据的样子,重要特征分析;e): 对数据集中的特征进行分析,构建相关系数矩阵,绘制heatmap图;
1.1 数据集中缺失数据的处理
现实生活中,收集到的原始数据一定经常存在缺失值的现象。部分UCI数据集上公开的数据也存在缺失。针对这个现象,在机器学习领域我们一般的操作是,用均值去填补缺失值。换言之,如果矩阵的第i 行第j 列缺失了某个值,那么我们就用第 j 列的平均值去填补这个缺失的值。据我了解,在实际应用中还有用众数、中位数等方式去填补的。但很显然,没人用最大值最小值等极端的值去填补缺失值。
1.2 特征编码
针对现实世界中的各种现象,为了能将其进行计算,我们通常要用到特征编码技术。比如羊,狗等,收集到的数据可能在某一列,它的值是羊狗之类的文字,这种我们无法直接进行计算,需要有某种方式能将其转换成实数。一个很自然的想法是,用1表示羊,用2表示狗,等等。但是,这种方式存在一个问题,什么问题呢?这样子的话,就默认狗比羊大,它们之间这种表示方式的话,就存在了顺序关系,但其实应该是没有顺序关系的。那用什么方式呢?one-hot编码。
one-hot编码是一种很常见的特征编码方式,还以上段中的羊、狗的方式举例说明。因为我们有两个类(羊、狗),那么我们可以用10,01的二进制方式来表示,这样两个样本之间的距离是1,不存在谁比谁更大更好的关系。
除了one-hot编码之外,还有虚拟编码,效果编码、特征散列化、分箱计数等方法。详细的特征编码技术在《精通特征工程》爱丽丝(美国)中有较为详细的描述。但是我觉得其逻辑依旧不是那么完善,可能讲的不是特别清晰。暂时我的任务环节中还没有需要用到特征编码的内容,在这部分进行描述只是为了贯通整个数据集处理的环节。
1.3 特征缩放&标准化等
对数据集进行特征缩放与标准化可太重要了,直接影响到模型的性能。举例来说,如果有一个数据集,第一列是人群的年龄(20~50岁),第二列是人群的收入(2000~8000),那么很显然,如果我们不进行处理的话,如果模型的某一步需要算欧式距离,那么年龄将彻底被收入所主导。
如何进行特征缩放与标准化?在机器学习领域中,常见的方式包含有:max-min归一化,zscore标准化。一般来说,我觉得这两种方式就够用了。具体的公式细节就不一一展开描述了。
总而言之,拿到一个数据集,除了1.1,1.2节的操作之外,1.3节特征标准化基本是必不可少的一个操作。
1.4 PCA降维与特征分析
通过以上三小节对数据集的处理,我们已经基本完成了数据集预处理中的没什么技术含量的工作。下面对数据集开始进行分析。
PCA降维是一种线性降维方式,它通过构建一种新的坐标系,将原始数据投影到新的坐标系下的方式,来保留主成分,从而达到降维的目的。针对PCA,我在另一篇博客中进行了介绍。https://blog.csdn.net/jinhualun911/article/details/117771807?spm=1001.2014.3001.5501。通过对数据集进行降维,我们选取比较重要的一些特征列,去掉不那么重要的特征,从而加快我们模型的训练速度与收敛速度。那么哪些特征比较重要,哪些又不那么重要呢?我们可以利用Matlab中的latent来进行分析,我在博客中也进行了介绍。
1.5 数据集中的相关系数矩阵
分析了数据集中哪些特征比较重要,哪些不重要,对于一般的任务而言已经够用了。但我还想分析的稍微再深入一些,即,数据集中特征之间有没有什么关系。例如,体重与运动量这两个特征一般而言可能存在明显的负相关性,受教育水平与工资收入一般存在正相关性。但有的特征之间,可能并没有我刚举得那两个例子那么明显,那么我们可以用相关系数矩阵,来描述数据集中特征与特征之间的相关性。
以WBC数据集(用X表示该数据集)为例,在Matlab中只需要一行代码:
A= corrcoef(X);
就可以得到相关系数矩阵,其中A是一个对称的矩阵,即第1个特征与第2个特征的相关性,与第2个特征与第1个特征的相关性是一样的。我们把相关系数矩阵用heatmap(热图)的方式画出来看看,更加的可视化一些,方便我们理解。
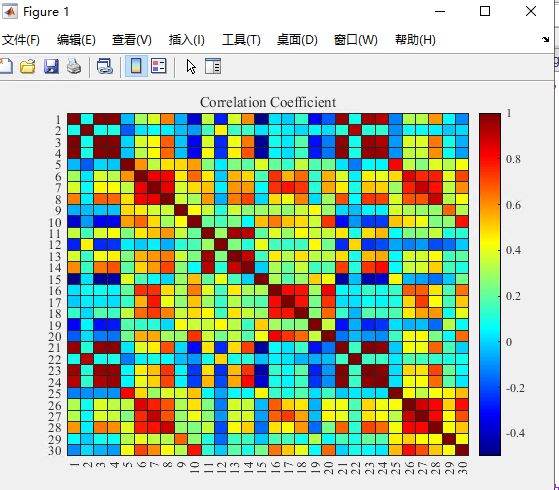
图1.wbc数据集的相关系数矩阵
从图1中我们可以发现,所有特征都与第一个特征存在着强烈的明显的,正相关,也就是说,第一个特征值增大,其余特征值一定增大。本来想去看看那个特征表示的是啥的,不过好像没找到。后面再说吧。
1.6 小结
针对数据集处理这部分,在我的认知范围内已经基本上概括完了。前3小结没什么技术含量,基本都是些在糙活,后面两部分比较有趣,对数据集进行了分析。通过数据集这一大节,我们已经基本掌握了整个离群点检测的源头部分,对数据集也有了一个较为清晰的认知。后面的内容将是正菜与硬菜。
二、算法(模型)
根据维基百科的定义,算法的定义是:一个被定义好的、计算机可施行之指示的有限步骤或次序。算法的特征被高德纳归纳为:输入(一个算法必须有0个或以上的输入量)、输出(一个算法应有一个或以上输出量,输出量是算法计算的结果)、明确性(算法的描述应无歧义,通常要求实际运行的结果是确定的)、有限性(算法必须在有限个步骤内完成任务)、有效性(能够实现,算法中描述的操作都是可以通过已经实现的基本运算执行有限次而实现)。
根据我的理解,算法就是解决问题的方法。我研究的问题是离群点检测,算法就是检测出数据集中的离群点的方法。经典的如KNN、LOF、IForest等,都是其中的优秀代表。
算法这一大节,我们把目前的主流的离群点检测方法进行分类,并大概的进行描述。
离群点检测其实可以归类为“类极度不平衡数据中的单分类问题”。也就是说,离群点检测所针对的数据集包含有两类,正常类与异常类,其中异常类所占比例很少,通常不高于5%。为什么叫做单分类问题呢?因为在离群点检测领域中,我们一般不太会用非此即彼的方式来判定某个对象归属于哪一个类,而是给待检测数据集中每个对象一个离群值,表示该对象是离群点的概率的大小,通常离群值越高,该对象越有可能是离群点,因此,可以将离群点检测归属于单分类问题。
离群点检测方法从有无监督层面来说,包含有两种,半监督与无监督方式。实际生活中,要得到样本的标签是很困难的一件事情,需要花费较多的人力物力。因此,很显然,我们更乐意于用无监督的方式来进行离群点检测。我所研究的就可归属于无监督方法。
在无监督领域中,我们将现有的,领域内的经典方法进行了如下分类:
表1.离群点检测算法分类
| 算法类型 | 算法名称(简称) |
| 基于模型的 | AE; IForest;OC-SVM; link-based; |
| 基于密度的 | LOF; COF; LOCI; RDF; INFLO; LoOP; DWOF; GBP+DLC;RDOS |
| 基于距离的 | KNN; ORCA; Cell-based; VDBLP; DOLPHIN; MIRO; |
具体的算法就不一一介绍了。因为我之前主要关注于的点就在于模型,这一部分已经有了一些了解,现在欠缺的是算法的代码实现。因此后期的时间,我一定是要关注于代码实现的。其实没有哪一种算法能够在所有种类的数据集中都表现良好,一定要根据实际情况去进行取舍。这不是本博文关注的重点。因此对具体的算法就不进行介绍了。后面我打算把自己复现的代码公布到CSDN与Github中,这是我的一个很重要的工作。
三、结果
经过上述数据集、模型两节内容,我们会得到数据集中每个对象的一个离群值(OF),或者说离群因子,即表示该对象是离群点的可能性大小。那么如何评价我们的算法的优劣与否呢?
一个很自然的,也是我经常用的方法是,TOP-n法。什么是TOP-n呢?模型的输出,是每一个对象的离群值,那么我们肯定希望,数据集中真正的离群点,一定是算法所判定的,或者给的离群值最高的那些对象。换言之,我们把离群值进行从大到小排序,最大的前n个对象(n是要人工输入的,是数据集中真正离群点的个数),我们判定为离群点。然后,将算法判定的离群点,与数据集中真正的离群点进行比较,得到混淆矩阵,就可以计算出准确率、检测率、误报率、AUC值等。
本节的主要内容是对算法的各种评价指标进行详细的描述。
分类任务中最常用的两种性能度量方式:
3.1 错误率与精度
错误率是指分类错误的样本数占样本总数的比例。精度则是分类正确的样本数占样本总数的比例。
除了这两种方式之外,还有其他的一些度量方式,我们一一进行介绍。
3.2 查准率、查全率、F1
| 真实情况 | 预测结果 | |
| 正例 | 反例 | |
| 正例 | TP | FN |
| 反例 | FP | TN |
查准率P与查全率R与F1分别定义为:
P=(TP) / (TP+FP);
R=(TP) / (TP+FN);
F1=(2*TP) / (样例总数+TP-TN);
简单的解释一下我的理解,查准率的意思就是指,算法判定的正确的离群点占所判定的离群点的比例。查全率是指,算法判定的离群点占数据集中真正离群点的比例。相对而言,我的任务需求由于是用的TOP-n的方式,所以用查全率的指标更能充分的评价算法性能。
3.3 ROC与AUC
ROC是曲线,AUC是ROC曲线下的面积。对于ROC,AUC我之前一直有一个疑惑,到底是怎么来评价的,一直没理解透,后来才明白,原来我之前用的方式都是top-n的方式,但是ROC是用的阈值法。即算法给了每个对象一个离群值,我原来用的是选取前n个最大的判定为离群点,ROC不是这样的,ROC是将这个离群值排序完成之后进行滑动,从而得到的。具体的描述如下:
由于模型的输出是判定的数据集中对象是离群点的概率,是一个实数,那么可以给一个阈值,如果对象的离群值大于设定的阈值,那么我们就将其判定为离群点(如0.5)。滑动的方式类似于某个截断点,该截断点之前的值我们判定为离群点,之后的我们判定为正常对象。在不同任务场景中,可以根据需求来设置这个截断点。如果更重视查准率,就靠前进行截断;如果更重视查全率,就靠后进行截断。
ROC全称是“受试者工作特征”。ROC的纵轴是“真正例率”,横轴是“假正例率”。定义方式如下:
TPR=(TP) / (TP+FN);
FPR=(FP) / (TN+FP);
可以发现,TPR与3.2节中的查全率相同。FPR表示的意思是,预测的正例中,判定错误的正例占总的反例的比例。稍微有点拗。
根据模型的输出的离群值,每次往后移动,那么每往后移一次,就能得到一个TPR与FPR的值,将其描画出来,就可以得到ROC曲线,再通过计算ROC下的面积,就可以得到AUC值。AUC值越逼近于1,算法的性能越好。若A算法的AUC值大于B算法的AUC值,那么就可以说A算法的性能要优于B算法。
总结
时隔两三天,在写这一小节。科研真是一条漫长,孤单,迷茫的旅程。对离群点检测,满打满算已经研究了有4个年头了,实际上的研究时间也有3年了。时常觉得自己还是一个懵懵懂懂的少年,对这个领域还是有许多不懂的地方。这个方向太大了,我又陷入了自我怀疑的阶段。有时候人真的很奇怪,有时候很相信自己,有时候又很怀疑自己。加油吧,小杜。总会熬出头的。
对技术上也做个总结吧。离群点检测我认为属于单分类,是将一个数据集中那些与大多数正常对象不太一样的,让人觉得可能是另外一种生成机制所造成的那些对象,检测判定为离群点的过程。离群点在现实生活中,有很多很多的应用,许多场景也需要。前人们提出了很多算法,来解决这个问题。但是时代一直在发展变化,传统的算法也有很多缺陷,例如对那些混杂在正常对象范围内的异常点就会很难区分,也有那些在密集簇,或者维度比较高的时候,有的算法的检测效果就不太好。我们要做的,就是要针对前人们所提的方法的缺陷,来做出自己的改进(or 提出自己的新的见解),来提高算法的检测效率。
路漫漫其修远兮,吾将上下而求索。
未来的路还很长,一定要努力,加油,时间成本一定要花费在上面,就一定会有一些好的结果。如果只有空想,不去做,不去看论文,不去写论文,不去投论文,那是万万不可的。要想中论文,一定是要多写,多投,多中。只有被拒稿拒的多了,方能知道论文该注意哪些内容,我们应该怎么去写论文。记住,一定要多做实验,多写代码,多看论文,多写论文,多投。没有一刻的时间是用来浪费的,在自己青春最美好的时候,争取多做出一些有意义的事情,以前浪费的时间太多了,以后要加油,努力,做好自己能做的每一件事情。
更加努力!
最后
以上就是傲娇云朵最近收集整理的关于从全局到局部审视离群点检测(Outlier Detection)的全部内容,更多相关从全局到局部审视离群点检测(Outlier内容请搜索靠谱客的其他文章。








发表评论 取消回复