CBAM(Convolutional Block Attention Module)一种轻量的注意力模块,可以在空间和通道上进行注意力机制,沿着通道和空间两个维度推断出注意力权重系数,然后再与feature map相乘,CBAM的结构如下: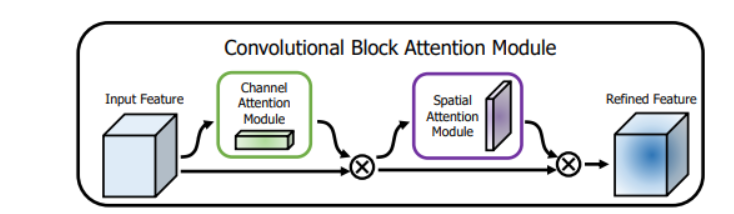
包含两个模块:通道注意力模块和空间注意力模块,两个注意力模块采用串联的方式。
1.通道注意力模块
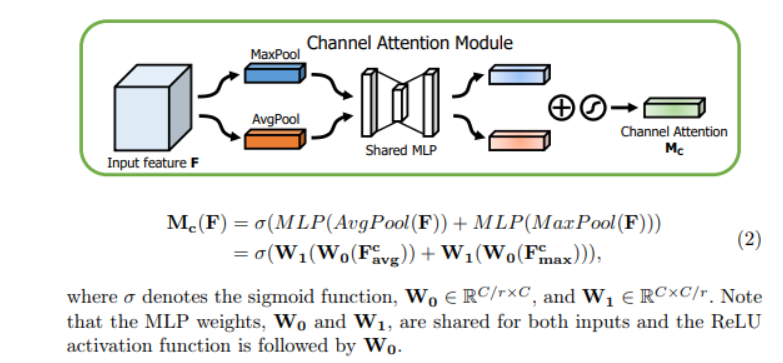
通道注意力是关注哪个通道上的特征是有意义的,输入feature map是H x W x C,先分别进行一个全局平均池化和全局最大池化得到两个1 x 1 x C的feature map , 然后将这两个feature map分别送入两层的全连接神经网络,对于这两个feature map,这个两层的全连接神经网络是共享参数的,然后,再将得到的两个feature map相加,然后再通过Sigmoid函数得到0~1之间的权重系数,然后权重系数再与输入feature map相乘,得到最终输出feature map。
2. 空间注意力模块
通道注意力输出之后,再引入空间注意力模块,关注空间中哪部分的特征有意义,
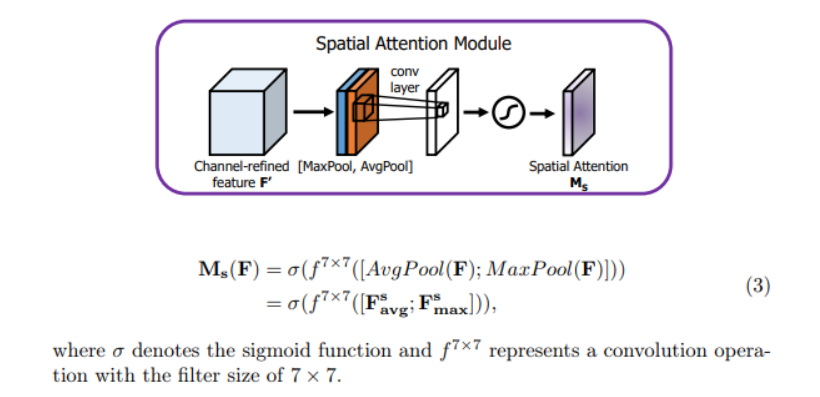
输入feature map为 H x W x C,分别进行一个通道维度的最大池化和平均池化得到两个H x W x 1的feature map,然后将这两个feature map在通道维度拼接起来,现在feature map H x W x 2,然后再经过一个卷积层,降为1个通道,卷积核采用7x7,同时保持H W 不变,输出feature map为H x W x 1,然后再通过Sigmoid函数生成空间权重系数,然后再与输入feature map相乘得到最终feature map。
关于通道注意力模块和空间注意力模块组合方式,作者通过实验证明先通道注意力模块再空间注意力模块的方式效果会更好。
3.code
class channelAttention(nn.Module):
def __init__(self , in_planes , ration = 16):
super(channelAttention, self).__init__()
'''
AdaptiveAvgPool2d():自适应平均池化
不需要自己设置kernelsize stride等
只需给出输出尺寸即可
'''
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 通道数不变,H*W变为1*1
self.max_pool = nn.AdaptiveMaxPool2d(1) #
self.fc1 = nn.Conv2d(in_planes , in_planes // 16 , 1 , bias = False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes//16 , in_planes ,1, bias = False)
self.sigmoid = nn.Sigmoid()
def forward(self , x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
#print(avg_out.shape)
#两层神经网络共享
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
print(avg_out.shape)
print(max_out.shape)
out = avg_out + max_out
print(out.shape)
return self.sigmoid(out)
''''
空间注意力模块
先分别进行一个通道维度的最大池化和平均池化得到两个H x W x 1,
然后两个描述拼接在一起,然后经过一个7*7的卷积层,激活函数为sigmoid,得到权重Ms
'''
class spatialAttention(nn.Module):
def __init__(self , kernel_size = 7):
super(spatialAttention, self).__init__()
assert kernel_size in (3 , 7 ), " kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
# avg 和 max 两个描述,叠加 共两个通道。
self.conv1 = nn.Conv2d(2 , 1 , kernel_size , padding = padding , bias = False)#保持卷积前后H、W不变
self.sigmoid = nn.Sigmoid()
def forward(self , x):
# egg:input: 1 , 3 * 2 * 2
avg_out :
avg_out = torch.mean(x , dim = 1 , keepdim = True)#通道维度的平均池化
# 注意 torch.max(x ,dim = 1) 返回最大值和所在索引,是两个值
keepdim = True 保持维度不变(求max的这个维度变为1),不然这个维度没有了
max_out ,_ = torch.max(x , dim =1 ,keepdim=True)#通道维度的最大池化
print(avg_out.shape)
print(max_out.shape)
x = torch.cat([avg_out , max_out] , dim =1)
print(x.shape)
x = self.conv1(x)
return self.sigmoid(x)
最后
以上就是精明火龙果最近收集整理的关于CBAM 通道注意力 & 空间注意力机制的全部内容,更多相关CBAM内容请搜索靠谱客的其他文章。








发表评论 取消回复