day1 AI面试刷题
- 1、简述机器学习项目的一般流程
- 2、哪些机器学习算法需要做特征归一化,哪些不需要?为什么?
- 3、One-hot的作用是什么?为什么不直接使用数字作为表示?
- 4、什么是数据不平衡?如何解决?
- 5、请比较欧氏距离与曼哈顿距离
1、简述机器学习项目的一般流程
机器学习项目的流程
- 数据获取(爬虫,第三方,自产)
- 数据分析与清洗(观察样本数据特征,数据类型;洗去样本异常值,去除或填补缺失值)
- 特征工程(筛选重要特征,或融合产生新的、更重要的特征)
- 建模(训练模型,选择合适的模型,注意分类,聚类还是回归模型)
- 得出结果并进行打分(使用模型产出结果,并打分,评估模型好坏,若模型问题,则回到4,若特征问题,回到3)
- 分析报告,可视化,得出结论
参考答案:
机器学习一般包括解决方案的制定,数据的准备与预处理,数据集的划分,模型的开发,和模型部署五个阶段。
解决方案的制定: 就是要分析战略目标,挖掘要通过机器学习技术解决的业务问题,然后制定解决方案(匹配问题与可能的解决方案)来解决这些问题。
数据的准备与预处理: 数据是任何机器学习项目的基石,数据的好坏直接决定了机器学习项目最终能否达到预期。在这一阶段,主要完成的工作有,
数据的收集,
数据的探索性分析(例如可视化分析),
数据的标注,
数据的选择(比如剔除不符合业务目标的数据),
数据的预处理(包括:数据格式化,数据清洗,数据匿名化,数据采样等)
数据转化/特征工程(例如:数值缩放,特征挖掘,特征组合,特征聚类等)
数据集的划分: 在这一阶段,要将准备好的数据划分为训练集,验证集和测试集,分别用于模型的训练,调优和性能测试。
模型的开发: 模型的开发主要包括:
模型训练(开发/选择/实现机器学习算法,并用数据和算法来训练模型),
模型的验证与测试,
模型性能提升(例如采用更好的算法来训练模型,或者采用集成框架)
模型的部署: 就是要将上一阶段开发好的模型部署到产品线上。此阶段需要考虑和解决的问题主要有:
模型预测的负载(批量预测还是实时预测?),
模型部署终端的环境(比如网络服务器端,还是移动端),
如何监控模型的线上表现,
如何进行模型的持续训练和改进等
2、哪些机器学习算法需要做特征归一化,哪些不需要?为什么?
归一化是对样本的数字进行处理,避免不同特征值差距过大而造成值权重较高,归一化使不同特征值分布更紧密,即将样本不同特征的不同权重处理为相同的权重,此外加快梯度下降求解的速率。那么,对数值敏感(如计算欧氏距离)的机器学习算法则需要该特征归一化,比如:逻辑归回,线性回归,SVM,KNN,神经网络等。而概率模型则不用,如树形结构的算法:如决策树、随机森林等,他们只在乎特征占整体样本的分布以及条件概率,与具体数值无关。
参考答案:
特征归一化是将所有特征都统一到一个大致相同的数值区间内,通常为 [0, 1]。常用的特征归一化方法有:
-
Min-Max Scaling
对原始数据进行线性变换,使结果映射到 [0, 1] 的范围,实现对数据的等比例缩放。
X n o r m = X − X m i n X m a x − X m i n begin{aligned} X_{norm}=frac{X-X_{min}}{X_{max}-X_{min}} end{aligned} Xnorm=Xmax−XminX−Xmin
其中 X m i n , X m a x X_{min}, X_{max} Xmin,Xmax 分别为数据的最小值和最大值 -
Z-Score Normalization
将原始数据映射到均值为0,标准差为1的分布上。
X n o r m = X − μ σ begin{aligned} X_{norm}=frac{X-mu}{sigma} end{aligned} Xnorm=σX−μ
其中 μ mu μ 为原始特征的均值,而 σ sigma σ 为原始特征的标准差。
在采用基于梯度更新的学习方法(包括线性回归,逻辑归回,支持向量机,神经网络等)对模型求解的过程中,未归一化的数值特征在学习时,梯度下降较为抖动,模型难以收敛(通常需要较长时间模型才能收敛);而归一化之后的数值特征则可以使梯度下降较为稳定,进而减少梯度计算的次数,也更容易收敛。下图中,左边为特征未归一化时,模型的收敛过程;而右边是经过特征归一化之后模型的收敛过程。其中 J ( θ ) J(theta) J(θ) 表示损失函数,图中的圈代表损失函数的等值线; θ 1 , θ 2 theta_1, theta_2 θ1,θ2 分别是模型的两个参数, x 1 , x 2 x_1, x_2 x1,x2 是这两个模型参数对应的特征值。
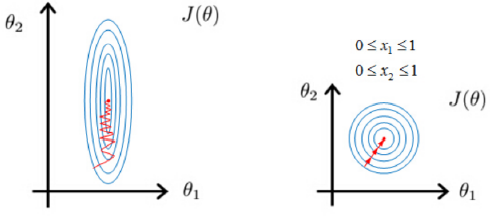
(椭圆变成圆)
3、One-hot的作用是什么?为什么不直接使用数字作为表示?
One-hot独热编码是用来做数据预处理的,来处理离散型数据的,比如某样本某特征为language,表示为编程语言,有三个值Python,Java,C++。因为机器无法处理该字符串,所以应转化为数值型。
直接使用数字表示会引起人为误差,如假设某一样本只有一个分类特征,三种分类值,用非one-hot表示为1,2,3,那么用one-hot表示为[1,0,0],[0,1,0]和[0,0,1],后者三个分类之间的距离都相等为根号2,而前者根号5,根号14和根号10,出现了不相等而引起的误差。
参考答案:
One-hot 主要用来编码类别特征,即采用哑变量(dummy variable)对类别进行编码。它的作用是避免因将类别用数字作为表示而给函数带来抖动。直接使用数字会将人工误差而导致的假设引入到类别特征中,比如类别之间的大小关系,以及差异关系等等。
4、什么是数据不平衡?如何解决?
数据不平衡问题指的是某一类标签的数量比例过小,比如银行借贷信用信息,超过还款日期的人数相对于正常还款人数过于少而造成样本不均衡。
从样本角度考虑:
有两种方法,过采样和欠采样。
过采样:对较小类别进行一些过采样,随机重复一些数据,使其与类别数量较多的样本数量相当,带方法会造成过拟合。
欠采样:随机剔除类别数量多的样本,使其与类别数量少的样本相当,该方法会丢失部分重要数据信息。
从评价标准考虑:
对于均衡的样本,一般使用准确率来评价模型好快。但对于该不平衡模型则失去意义,使用PR曲线,同时考虑精准率和召回率。
阈值调整:
不对数据进行处理,将阈值调整到正例/负例
参考-阈值调整CSDN
参考答案:
数据不平衡主要指的是在有监督机器学习任务中,样本标签值得分布不均匀。这使得模型更倾向于将结果预测为样本标签分布较多的值,从而导致少数样本的预测性能下降。绝大多数常见的机器学习算法对于不平衡数据集都不能很好的工作。
解决方法:
- 重新采样训练集
a. 欠采样 - 通过减少丰富类的大小来平衡数据集
b. 过采样 - 增加稀有样本,通过使用重复、自举或合成少数类 - 改进损失函数
a. 在代价函数增大对稀有类别分类错误的惩罚权重
5、请比较欧氏距离与曼哈顿距离
欧式距离是计算两点间的直线距离,而曼哈顿距离式计算两点间的轴线距离。


参考答案:
欧氏距离,即欧几里得距离,表示两个空间点之间的直线距离。
d
=
(
∑
k
=
1
n
∣
a
k
−
b
k
∣
2
)
1
2
d=(sum_{k=1}^n|a_k-b_k|^2)^{frac{1}{2}}
d=(k=1∑n∣ak−bk∣2)21
曼哈顿距离,即所有维度距离绝对值之和。
d
=
∑
k
=
1
n
∣
a
k
−
b
k
∣
d = sum_{k=1}^n|a_k-b_k|
d=k=1∑n∣ak−bk∣
基于地图,导航等应用中,欧氏距离表现得理想化和现实上的距离相差较大;而曼哈顿距离就较为合适;另外欧氏距离根据各个维度上的距离自动地给每个维度计算了一个“贡献权重”,这个权重会因为各个维度上距离的变化而动态的发生变化;而曼哈顿距离的每个维度对最终的距离都有相同的贡献权重。
修改时间:
2022.1.10
最后
以上就是开心摩托最近收集整理的关于day1 AI面试刷题1、简述机器学习项目的一般流程2、哪些机器学习算法需要做特征归一化,哪些不需要?为什么?3、One-hot的作用是什么?为什么不直接使用数字作为表示?4、什么是数据不平衡?如何解决?5、请比较欧氏距离与曼哈顿距离的全部内容,更多相关day1内容请搜索靠谱客的其他文章。








发表评论 取消回复